POET: Endlessly Generating Increasingly Complex and Diverse Learning Environments and their Solutions through the Paired Open-Ended Trailblazer
Jeff Clune and Kenneth O. Stanley were co-senior authors.
We are interested in open-endedness at Uber AI Labs because it offers the potential for generating a diverse and ever-expanding curriculum for machine learning entirely on its own. Having vast amounts of data often fuels success in machine learning, and we are thus working to create algorithms that generate their own training data in limitless quantities.
In the normal practice of machine learning, the researcher identifies a particular problem (for example, a classification problem like ImageNet or a video game like Montezuma’s Revenge) and then focuses on finding or designing an algorithm to achieve top performance. Sometimes, however, we do not just want to solve known problems, because unknown problems are also important. These might be edge cases (e.g., in safety applications) that are critical to expose (and solve), but they also might be essential stepping stones whose solutions can help make progress on even more challenging problems. Consequently, we are exploring algorithms that continually invent both problems and solutions of increasing complexity and diversity.
One of the most compelling reasons to generate both problems and solutions is that it is the only realistic approach to solving a range of prohibitively difficult challenges. To understand why, consider the essential role of the curriculum in education. The reason there is a curriculum is that it is too hard to learn advanced skills or concepts without first mastering foundational skills beforehand. This principle applies not just to students in classrooms, but also to learning algorithms: as results in this project (revealed shortly) will show, tasks that are difficult or impossible to learn directly become tractable if they are instead the end of a sequence of stepping stone tasks—in effect, a curriculum.
However, while a curriculum may be essential for some tasks in principle, in practice we face the problem that we do not know the right curriculum for any given task, and we also do not know the whole range of tasks that can be learned if only they are attacked at the right time and in the right order. In fact, as will also be shown shortly, often the best curriculum is counter-intuitive or even backwards (i.e., learning harder tasks can lead to better solutions to simpler ones). As a result, while curricula are often designed explicitly by hand, the full gamut of what is possible may only be revealed by letting the curriculum itself emerge at the same time as the learners follow it.
Open-endedness offers the benefit of self-generated curricula and many others: at its best it can continue to generate new tasks in a radiating tree of challenges indefinitely, along with agents that can solve this expanding set of increasingly diverse and complex challenges.
One of the original inspirations for research into open-endedness is natural evolution, which invents astronomical complexity for near-eternity. Evolution is in effect an open-ended process that in a single run created all forms of life on Earth, and the process is still going on. Notably, the one real instance where human-level intelligence has been produced comes from this process. While the field of evolutionary computation is inspired by open-endedness, no evolutionary algorithm comes close to nature in this regard, and instead more closely resemble conventional machine learning algorithms in converging (at best) to the global optimum, rather than producing a tree of life that diverges across the space of possible life forms (or, more abstractly, a set of challenges, like reaching leaves high up in trees, and their solution, like giraffes and caterpillars).
While historic research on open-endedness mostly focuses on creating artificial worlds (which are often associated with the field of artificial life), for example, Tierra, Avida, Evosphere, and Chromaria, recent advances in deep neuroevolution have made open-endedness practical and relevant to machine learning. In contrast to conventional evolutionary algorithms (such as genetic algorithms and evolution strategies, etc.), which can be categorized as black box optimization, modern neuroevolution algorithms inspired by the concept of open-endedness are more focused on divergence and discovering stepping stones (for example, novelty search, novelty search with local competition, MAP-Elites, minimal criterion coevolution, Innovation Engines, and CMOEA). Interestingly, a recent breakthrough from our lab called Go-Explore that achieved record-breaking performance playing Montezuma’s Revenge and Pitfall is also inspired by these ideas. The minimal criterion coevolution (MCC) algorithm in particular is notable for highlighting the potential for generating new environments in a coevolutionary dynamic, though it does not take the step of optimizing solutions explicitly within their environments. Additionally, the Innovation Engine introduced the idea of goal switching between different tasks by transferring agents from one environment to another if they are better, which catalyzes progress by harnessing an expanding set of stepping stones to further innovation.
Released today, the Paired Open-Ended Trailblazer (POET), combines these ideas to push this line of research explicitly towards generating new tasks, optimizing solutions for them, and transferring agents between tasks to enable otherwise unobtainable advances. To demonstrate the approach, we apply POET to creating and solving bipedal walking environments (adapted from the BipedalWalker environments in OpenAI Gym, which are popularized in a series of blog posts and papers by David Ha), wherein each environment Ei is paired with a neural network-controlled agent Ai that tries to learn to navigate through that environment. Figure 1, below, depicts an example environment and agent:


As illustrated in Figure 2, below, POET begins with a trivial environment E0 paired with a randomly-initialized agent A0, and then grows and maintains a population of one-to-one paired environments and agents. Over the course of the process, POET aims to achieve two goals: (1) evolve the population of environments towards diversity and complexity; and (2) optimize agents to solve their paired environments. During a single such run, POET generates a diverse range of complex and challenging environments, as well as their solutions. Below we demonstrate a couple interesting environments and solutions that POET found:
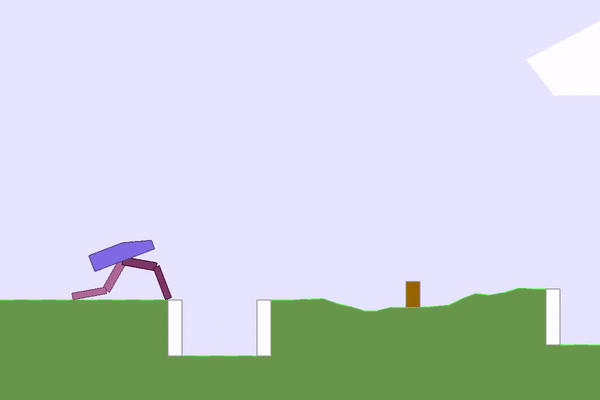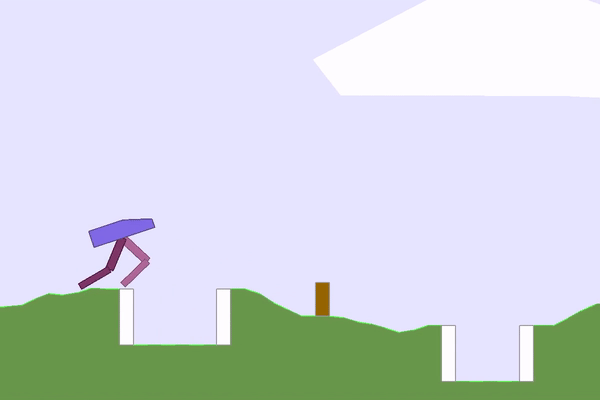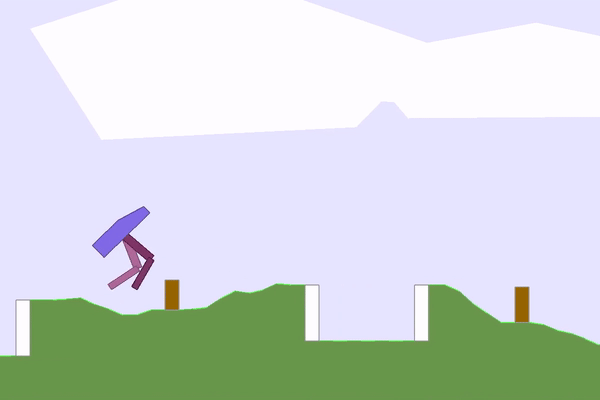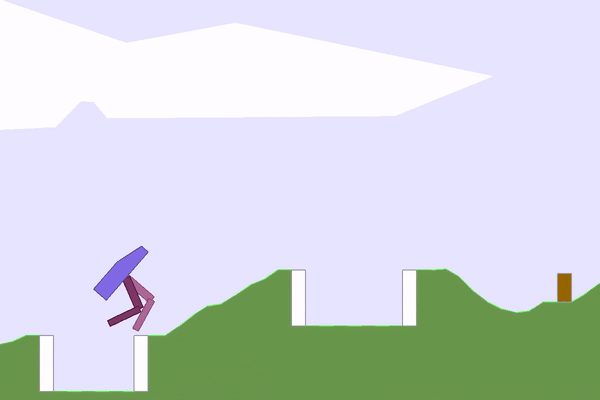 |  |
Figure 3: A sample of interesting environments and solutions that POET found.
To evolve the population of environments, POET first decides which environments in the current population are eligible to reproduce through a score threshold that the paired agent has to satisfy. This requirement prevents spending computational resources on problems that are currently too difficult. Next, eligible environments mutate (are copied and slightly changed) to generate candidate child environments, whose paired agents are initialized to be the same as the agent from the parent environment. Finally, POET evaluates the candidate children environments, filters the candidates by a minimal criterion, ranks them by novelty, and admits the top candidates into the population. In this work, the minimal criterion is a lower and upper bound for the paired agent’s fitness score that filters out environments that are either too simple or too complicated for the current population of agents. Novelty provides a pressure to produce more diverse environments (challenges)—it is a quantitative measure of how different the candidate environment is from previously accepted environments. Given that computational resources are ultimately limited, once a cap on the number of environments is reached, before admitting any new environments, POET removes the oldest environments.
In these experiments, agents are optimized to maximize reward in environments with a recent variant of evolution strategies (ES), but any reinforcement learning or black box optimization algorithm could work in its place. Most of the time, agents are optimized to improve within the environment they are paired with. Importantly, POET also periodically performs transfer experiments to explore whether an agent optimized in one environment might serve as a stepping stone to better performance in a different environment. That way, by testing transfers to other active environments, POET harnesses the diversity of its multiple agent-environment pairs to its full potential, i.e., without missing any opportunities to gain an advantage from existing stepping stones. There are two types of transfer attempts (Figure 4): direct transfer, wherein agents from the originating environment are directly evaluated in the target environment, and proposal transfer, where agents take one ES optimization step in the target environment (in case a bit of optimization is needed to adapt useful skills from a source environment to the target environment). Existing paired agents in the target environments are replaced if a transfer is better.

Observing open-ended discovery
Transfer can yield surprising stories of unlikely stepping stones producing important evolutionary advances. In one example, the original environment is simply flat ground and its paired agent learns to move forward without fully standing up (Figure 5, top-left graphic). This gait represents a local optimum, because more efficient gaits are possible if the agent stands up. At iteration 400, this environment generates a child environment with some stumps. The initial child agent inherits the low-knee walking gait from its parent environment such that it can move forward in the stumpy environment, but it often stumbles because of the stumps it had not encountered before (Figure 5, top-right graphic). Eventually, the agent in the child environment learns to stand up and jump over the stumps (Figure 5, middle-right graphic). Then, in a demonstration of the serendipitous potential of transfer, that skill is transferred back to the parent environment (Figure 5, middle-left graphic) at iteration 1,175. Now the agent in the original flat environment is one that stands up straight, and in this way the search process has escaped the low-knee local optimum. This new upright policy then specializes for its new, flat environment to produce an even faster gait. By running optimization for a long time on the original low-knee gait in the flat environment without allowing transfers, we confirmed that this much more efficient upright gait would never have been found without transfer (i.e., search was indeed stuck on a local optima).
| Parent Environment, Iteration 400 | Child Environment, Iteration 400 | |
 |  | |
| Parent Environment, Iteration 1175 | Child Environment, Iteration 1175 | |
 |  | |
| Parent Environment, Iteration 2300 | Parent Environment, Iteration 2300 | |
 |  |
Figure 5. An example of the benefit of transfer in innovation.
By creating new environments through mutating older environments, POET is, in effect, building multiple, overlapping curricula. The minimal criterion that environments be reasonably solvable from current stepping stones means that curricula are built gradually, and the novelty pressure encourages a diverse set of challenges, all of which happens in the same run. The ability to generate such solutions continually in a single run is interesting in its own right, but its importance is magnified if the hypothesis is correct that the skills thereby gained could not be learned directly from scratch. Perhaps even more interesting is the insight that the proper curriculum itself to find these advanced skills could not be easily conceived by humans in advance. In other words, what if we cannot reach the skills learned by POET by incrementally guiding a learner through a human-designed series of increasingly difficult tasks aimed at the final target environment? This hypothesis means that POET or something like it is necessary to find both the solutions and the curricula that lead to them.
We validated this hypothesis by collecting difficult environments generated and solved by POET, and then devising simple incremental curricula aimed at re-achieving the same endpoints from scratch. Each simple curriculum reflects an intuitive view of how a good curriculum should be built—by gradually increasing difficulty—but it doesn’t work! In fact, none of the attempts to recreate behaviors found in the more challenging environments found by POET in this way come even close, as shown in Figure 6.
Each rose plot in Figure 6 is one set of experiments in which the red pentagon indicates an environment that POET created and solved. The five vertices of each pentagon indicate roughness and the lower- and upper-bounds for the range of the gap and stump widths. With the red pentagon as the target, the five blue pentagons indicate the closest-to-target environments that five independent runs of the direct-path curriculum-based control algorithm (which uses the same ES optimization algorithm) can solve. The curriculum starts at the simple, flat environment and whenever the problem is sufficiently solved (according to the same criteria in POET), the environment is changed slightly to move it more toward the target environment (with the amount of environmental change the same as in POET). Clearly, not only does the control algorithm fail to solve many of the environments that POET created and solved, but also the ranges of environments that the control algorithm can solve are much narrower than those solved by POET (meaning POET agents can handle a wider diversity of challenges within an environment), both of which demonstrate the advantage of POET over straightforward curriculum-building.

Conclusions and future work
Thanks to its divergence and focus on collecting and leveraging stepping-stones, POET achieves a breadth of skilled behaviors that may be unreachable in any conventional way. Moreover, POET invents its own challenges instead of requiring humans to create them. Furthermore, many challenges and the skill sets to solve them are discovered in a single run, instead of relying on the random initializations and idiosyncrasies of different runs to produce interesting diversity. In principle, with a more sophisticated encoding for the environment space, POET could continue inventing new challenges and their solutions for vast stretches of time, or even indefinitely. Open-endedness is fascinating not just for its practical benefits in terms of producing solutions to hard problems and the set of skills needed to solve them, but also for its propensity for creativity and its ability to surprise us. Because of this tendency for surprise, observing the output of POET is often fun, as we hope some of the videos in this article convey. POET also does not depend on the learning algorithm used for optimization, so it can be combined with whatever RL (or other) approach is preferred.
Ultimately we envision moving beyond the 2D obstacle courses in this initial proof of concept to open-ended discovery in a breadth of interesting domains. For example, while parkour has been explored in 3D on obstacle courses designed by humans, POET could invent radical new courses and solutions to them at the same time. POET could similarly produce fascinating new kinds of soft robots for unique challenges it invents that only soft robots can solve. At a more practical level, it could generate simulated test courses for autonomous driving that both expose unique edge cases and demonstrate solutions to them. Even more exotic applications are conceivable, like inventing new proteins or chemical processes that perform novel functions that solve problems in a variety of application areas. Given any problem space with the potential for diverse variations, POET can blaze a trail through it.
We hope others will join us in exploring the potential of POET-based exploration. For that purpose, we provide an accompanying research article with technical details and have open sourced the code for POET.
Rui Wang
Rui Wang is a senior research scientist with Uber AI. He is passionate about advancing the state of the art of machine learning and AI, and connecting cutting-edge advances to the broader business and products at Uber. His recent work at Uber was published on leading international conferences in machine learning and AI (ICML, IJCAI, GECCO, etc.), won a Best Paper Award at GECCO 2019, and was covered by technology media such as Science, Wired, VentureBeat, and Quanta Magazine.
Kenneth O. Stanley
Before joining Uber AI Labs full time, Ken was an associate professor of computer science at the University of Central Florida (he is currently on leave). He is a leader in neuroevolution (combining neural networks with evolutionary techniques), where he helped invent prominent algorithms such as NEAT, CPPNs, HyperNEAT, and novelty search. His ideas have also reached a broader audience through the recent popular science book, Why Greatness Cannot Be Planned: The Myth of the Objective.
Jeff Clune
Jeff Clune is the former Loy and Edith Harris Associate Professor in Computer Science at the University of Wyoming, a Senior Research Manager and founding member of Uber AI Labs, and currently a Research Team Leader at OpenAI. Jeff focuses on robotics and training neural networks via deep learning and deep reinforcement learning. He has also researched open questions in evolutionary biology using computational models of evolution, including studying the evolutionary origins of modularity, hierarchy, and evolvability. Prior to becoming a professor, he was a Research Scientist at Cornell University, received a PhD in computer science and an MA in philosophy from Michigan State University, and received a BA in philosophy from the University of Michigan. More about Jeff’s research can be found at JeffClune.com
Joel Lehman
Joel Lehman was previously an assistant professor at the IT University of Copenhagen, and researches neural networks, evolutionary algorithms, and reinforcement learning.