Montezuma’s Revenge Solved by Go-Explore, a New Algorithm for Hard-Exploration Problems (Sets Records on Pitfall, Too)
Kenneth O. Stanley and Jeff Clune were co-senior authors.
In deep reinforcement learning (RL), solving the Atari games Montezuma’s Revenge and Pitfall has been a grand challenge. These games represent a broad class of challenging, real-world problems called “hard-exploration problems,” where an agent has to learn complex tasks with very infrequent or deceptive feedback.
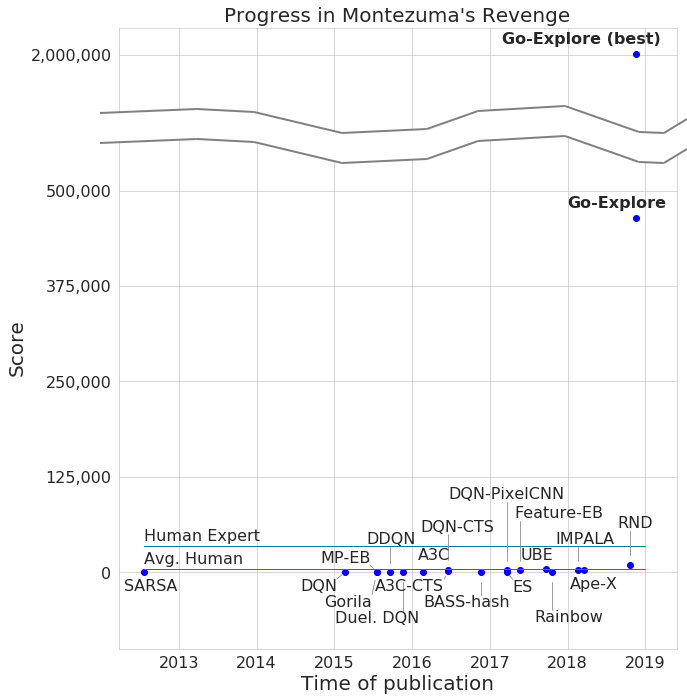
The state-of-the-art algorithm on Montezuma’s Revenge gets an average score of 11,347, a max score of 17,500, and solved the first level at one point in one of ten tries. Surprisingly, despite considerable research effort, so far no algorithm has obtained a score greater than 0 on Pitfall.
Today we introduce Go-Explore, a new family of algorithms capable of achieving scores over 2,000,000 on Montezuma’s Revenge and scoring over 400,000 on average! Go-Explore reliably solves the entire game, meaning all three unique levels, and then generalizes to the nearly-identical subsequent levels (which only differ in the timing of events and the score on the screen). We have even seen it reach level 159!
On Pitfall, Go-Explore achieves an average score of over 21,000, far surpassing average human performance and scoring above zero for the first time for any learning algorithm. To do so, it traverses 40 rooms, requiring it to swing on ropes over water, jump over crocodiles, trap doors, and moving barrels, climb ladders, and navigate other hazards.
All told, Go-Explore advances the state of the art on Montezuma’s Revenge and Pitfall by two orders of magnitude and 21,000 points, respectively. It does not use human demonstrations, but also beats the state-of-the-art performance on Montezuma’s Revenge of imitation learning algorithms that are given the solution in the form of human demonstrations.
Go-Explore can benefit from human domain knowledge (without the onerous requirement of having a human solve the entire task to provide a demonstration), and the above results use it. The domain knowledge is minimal and easily obtained from pixels, highlighting the profound ability of Go-Explore to harness minimal a priori knowledge. However, even without any domain knowledge, Go-Explore scores over 35,000 points on Montezuma’s Revenge, which is more than three times the state of the art.
Go-Explore differs radically from other deep RL algorithms. We think it could enable rapid progress in a variety of important, challenging problems, especially robotics. We therefore expect it to help teams at Uber and elsewhere increasingly harness the benefits of artificial intelligence.
Update: We encourage you to read the new section below titled “Update on the Issue of Stochasticity” to understand how our results relate to other variations of the benchmark.
Update 2: We have now released a paper on Go-Explore as well as source code.
The challenge of exploration
Problems with infrequent rewards are hard because random actions are unlikely to ever produce reward, making it impossible to learn. Montezuma’s Revenge is one such “sparse reward problem.” Even harder is when the rewards are deceptive, meaning that maximizing rewards in the short term teaches an agent the wrong thing to do with respect to achieving a much higher score overall. Pitfall is deceptive in this way, because many actions lead to small negative rewards (like hitting an enemy), so most algorithms learn not to move at all and as a result never learn to collect hard-to-get treasures. Many challenging real-world problems are both sparse and deceptive.
Ordinary RL algorithms usually fail to get out of the first room of Montezuma’s Revenge (scoring 400 or lower) and score 0 or lower on Pitfall. To try to solve such challenges, researchers add bonuses for exploration, often called intrinsic motivation (IM), to agents, which rewards them for reaching new states (situations or locations). Despite IM algorithms being specifically designed to tackle sparse reward problems, they still struggle with Montezuma’s Revenge and Pitfall. The best rarely solve level 1 of Montezuma’s Revenge and fail completely on Pitfall, receiving a score of zero.
We hypothesize that a major weakness of current IM algorithms is detachment, wherein the algorithms forget about promising areas they have visited, meaning they do not return to them to see if they lead to new states. As an example, imagine an agent between the entrances to two mazes. It may by chance start exploring the West maze and IM may drive it to learn to traverse, say, 50 percent of it. Because current algorithms sprinkle in randomness (either in actions or parameters) to try new behaviors to find explicit or intrinsic rewards, by chance the agent may at some point begin exploring the East maze, where it will also encounter a lot of intrinsic reward. After completely exploring the East maze, it has no explicit memory of the promising exploration frontier it abandoned in the West maze. It likely would have no implicit memory of this frontier either due to the well-studied problem of catastrophic forgetting in AI. Worse, the path leading to the frontier in the West maze has already been explored, so no (or little) intrinsic motivation remains to rediscover it. We thus say the algorithm has detached from the frontier of states that provide intrinsic motivation. As a result, exploration can stall when areas close to where the current agent visits have already been explored. This problem would be remedied if the agent returned to previously discovered promising areas for exploration.

Go-Explore

Go-Explore separates learning into two steps: exploration and robustification.
Phase 1: Explore until solved. Go-Explore builds up an archive of interestingly different game states (which we call “cells”) and trajectories that lead to them, as follows:
Repeat until solved:
- Choose a cell from the archive probabilistically (optionally prefer promising ones, e.g. newer cells)
- Go back to that cell
- Explore from that cell (e.g. randomly for n steps)
- For all cells visited (including new cells), if the new trajectory is better (e.g. higher score), swap it in as the trajectory to reach that cell
By explicitly storing a variety of stepping stones in an archive, Go-Explore remembers and returns to promising areas for exploration (unlike what tends to happen when training policies with intrinsic motivation). Additionally, by first returning to cells before exploring from them (preferring distant, hard-to-reach cells), Go-Explore avoids over-exploring easily reached states (e.g. near the starting point) and instead focuses on expanding its sphere of knowledge. Finally, because Go-Explore tries to visit all reachable states, it is less susceptible to deceptive reward functions. These ideas will be recognizable to those familiar with quality diversity algorithms, and we discuss below how Go-Explore represents a new type of quality diversity algorithm.
Phase 2: Robustify (if necessary). If the solutions found are not robust to noise (as is the case with our Atari trajectories), robustify them into a deep neural network with an imitation learning algorithm.
Cell representations
To be tractable in high-dimensional state spaces like Atari, Go-Explore needs a lower-dimensional cell representation with which to form its archive. Thus, the cell representation should conflate states that are similar enough to not be worth exploring separately (and not conflate states that are meaningfully different). Importantly, we show that game-specific domain knowledge is not required to create such a representation. We found that what is perhaps the most naive possible cell representation worked pretty well: simply downsampling the current game frame.

Returning to cells
Returning to a cell (before exploring) can be achieved in three ways, depending on the constraints of the environment. In order of efficiency:
- In a resettable environment, one can simply reset the environment state to that of the cell
- In a deterministic environment, one can replay the trajectory to the cell
- In a stochastic environment, one can train a goal-conditioned policy [1, 10] that learns to reliably return to a cell
While most interesting problems are stochastic, a key insight behind Go-Explore is that we can first solve the problem, and then deal with making the solution more robust later (if necessary). In particular, in contrast with the usual view of determinism as a stumbling block to producing agents that are robust and high-performing, it can be made an ally by harnessing the fact that simulators can nearly all be made both deterministic and resettable (by saving and restoring the simulator state), and can later be made stochastic to create a more robust policy (including adding domain randomization). These observations are especially relevant for robotics tasks, where training is often done in simulation before policies are transferred to the real world.
Atari is resettable, so for efficiency reasons we return to previously visited cells by loading the game state. On Montezuma’s Revenge, this optimization allows us to solve the first level 45 times faster than by replaying trajectories. However, such access to the emulator is not required for Go-Explore to work; it just makes it faster.
In this work, after the agent returns to a cell it explores simply by taking random actions (with a high probability of repeating the previous action). Note that such exploration does not require a neural network or other controller, and all of the exploration in the experiments that follow do not use one (although neural networks are used for robustification). That entirely random exploration works so well highlights the surprising power of simply returning to interesting cells.
Exploration phase results
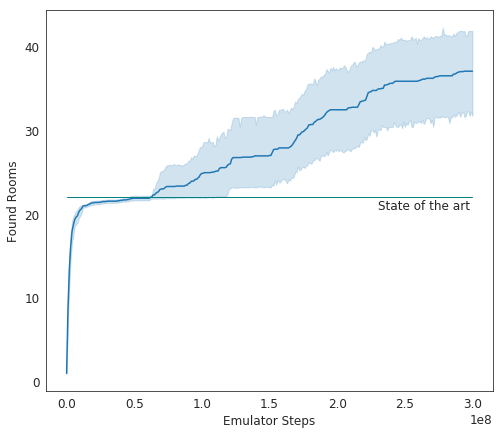
With the downsampled image cell representation, on Montezuma’s Revenge Go-Explore reaches an average of 37 rooms and solves level 1 (which contains 24 rooms, not all of which need to be visited) 65 percent of the time. The previous state of the art [3] explored 22 rooms on average.
Robustification
Our current version of Go-Explore exploits determinism to find solutions (high-performing trajectories) faster. Such trajectories are brittle: they will not generalize to even slightly different states, including those created by the classic way of making Atari a bit stochastic, which is to force the agent to do nothing a random number of times up to 30 before starting the game.
Go-Explore solves this brittleness problem with imitation learning, a type of algorithm that can learn a robust model-free policy from demonstrations. Typically such algorithms use human demonstrations [2, 5, 6, 9], but the Phase 1 of Go-Explore can automatically generate such demonstrations (and many of them if more are helpful).
Any reliable imitation learning algorithm would work. For this initial work we chose Salimans & Chen’s “backward” algorithm because it is open source and was shown to solve Montezuma’s Revenge when provided a human-generated demonstration.
We found it somewhat unreliable in learning from a single demonstration. However, because Go-Explore can produce plenty of demonstrations, we modified the backward algorithm to simultaneously learn from multiple demonstrations (in this case, 4, and in the later experiments with domain knowledge 10). We also added a random number of no-ops (do nothing commands) to the starting condition to make the policy robust to this type of stochasticity.
Results with robust deep neural network policies
All attempts to produce robust policies from the trajectories that solve level 1 of Montezuma’s Revenge worked. The mean score is 35,410, which is more than 3 times the previous state of the art of 11,347 and slightly beats the average for human experts [5] of 34,900!

Adding domain knowledge
The ability of an algorithm to integrate easy-to-provide domain knowledge can be an important asset. Go-Explore provides the opportunity to leverage domain knowledge in the cell representation (though the final neural network still plays directly from pixels only). In particular, we tested a domain-knowledge version of Go-Explore on Montezuma’s Revenge, wherein cells were defined as unique combinations of the x-y position of the agent, the current room, the current level, and the current number of keys held. We wrote simple code to extract this information directly from pixels.
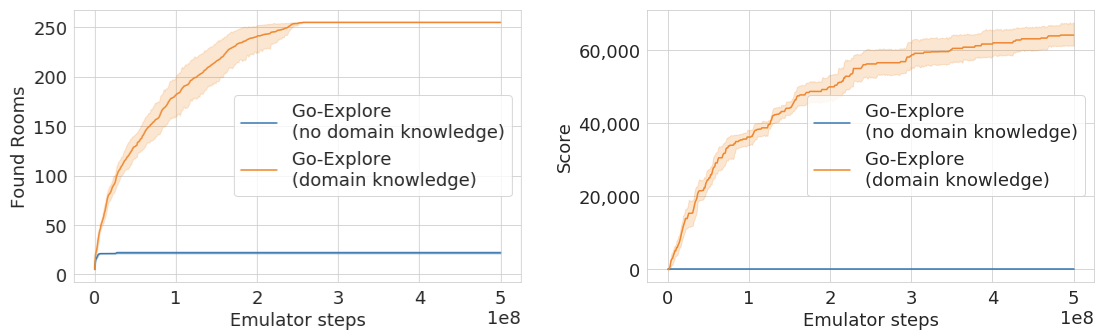
With this improved state representation, Phase 1 of Go-Explore finds a staggering 238 rooms, solves over 9 levels on average, and does so in half the number of emulator steps vs. the downscaled image cell representation.

Robustified results
Robustifying the trajectories found with the domain knowledge version of Go-Explore produces deep neural network policies that reliably solve the first 3 levels of Montezuma’s Revenge (and are robust to random numbers of initial no-ops). Because in this game all levels beyond level 3 are nearly identical (as described above), Go-Explore has solved the entire game!
In fact, our agents generalize beyond their initial trajectories, on average solving 29 levels and achieving a score of 469,209! This shatters the state of the art on Montezuma’s Revenge both for traditional RL algorithms and imitation learning algorithms that were given the solution in the form of a human demonstration. Incredibly, some of Go-Explore’s neural networks achieve scores over 2 million and reach level 159! To fully see what these agents could do, we had to increase the time OpenAI’s Gym allows agents to play the game. Go-Explore’s max score is substantially higher than the human world record of 1,219,200, achieving even the strictest definition of “superhuman performance.”

The full video of this record-breaking run is 53 minutes even when sped up 4x. The agent does not die, but instead runs into the (already vastly increased) time limit.
Pitfall
Pitfall also requires significant exploration and is harder than Montezuma’s Revenge because its rewards are sparser (only 32 positive rewards scattered over 255 rooms) and many actions yield small negative rewards that dissuade RL algorithms from exploring the environment. To date, no RL algorithm we are aware of has collected even a single positive reward in this game (without being given human demonstrations).
In contrast, Go-Explore with minimal domain knowledge (position on the screen and room number, both of which we obtain from pixels) is able to visit all 255 rooms and collects over 60,000 points in the exploration phase of the algorithm. Without domain knowledge (i.e. the downscaled pixel representation) Go-Explore finds an impressive 22 rooms, but does not find any reward. We believe the downscaled pixel representation underperforms on Pitfall because the game contains many different states that have identical pixel representations (i.e. identical looking rooms in different locations in the game). Differentiating these states without domain knowledge will probably require a state representation that takes previous states into account, or other techniques we plan to investigate.
From the trajectories collected in the exploration phase, we are able to reliably robustify trajectories that collect more than 21,000 points, substantially outperforming both the state of the art and average human performance. Longer, higher-scoring trajectories proved difficult to robustify, possibly because different behaviors may be required for visually indistinguishable states. We believe this problem is solvable with additional research into techniques that help the agent disambiguate such states.

A robust, deep neural network policy that sets the AI record on Pitfall, scoring more than 21,000 points (not counting the 2,000 points given at the start).
Three key insights
We believe Go-Explore performs so well on hard-exploration problems because of three key principles:
- Remember good exploration stepping stones (interestingly different states visited so far)
- First return to a state, then explore
- First solve a problem, then robustify (if necessary)
These principles do not exist in most RL algorithms, but it would be interesting to weave them in. As discussed above, contemporary RL algorithms do not do number 1. Number 2 is important because current RL algorithms explore by randomly perturbing the parameters or actions of the current policy in the hope of exploring new areas of the environment, which is ineffective when most changes break or substantially change a policy such that it cannot first return to hard-to-reach states before further exploring from them. This problem becomes worse the longer, more complex, and more precise the sequence of actions required to reach a state is. Go-Explore solves this problem by first returning to a state and then exploring from there. Doing so enables deep exploration that can find a solution to the problem, which can then be robustified to produce a reliable policy (principle number 3).
The idea of preserving and exploring from stepping-stones in an archive comes from the quality diversity (QD) family of algorithms (like MAP-elites [4, 8] and novelty search with local competition), and Go-Explore is an enhanced QD algorithm based on MAP-Elites. However, previous QD algorithms focus on exploring the space of behaviors by randomly perturbing the current archive of policies (in effect departing from a stepping stone in policy space rather than in state space), as opposed to explicitly exploring state space by departing to explore anew from precisely where in state space a previous exploration left off. In effect, Go-Explore offers significantly more controlled exploration of state space than other QD methods by ensuring that the scope of exploration is cumulative through state space as each new exploratory trajectory departs from the endpoint of a previous one.
It is remarkable that the current version of Go-Explore works by taking entirely random actions during exploration (without any neural network!) and that it is effective even when applied on a very simple discretization of the state space. Its success despite such surprisingly simplistic exploration strongly suggests that remembering and exploring from good stepping stones is a key to effective exploration, and that doing so even with otherwise naive exploration helps the search more than contemporary deep RL methods for finding new states and representing those states. Go-Explore could be even more powerful by combining it with effective, learned representations and by replacing the current random exploration with more intelligent exploration policies. We are pursuing both of those avenues.
Go-Explore also demonstrates how exploration and dealing with environmental stochasticity are problems that can be solved separately by first performing exploration in a deterministic environment and then robustifying relevant solutions. The reliance on having access to a deterministic environment may initially seem like a drawback of Go-Explore. However, we emphasize that deterministic environments are available in many popular RL domains, including videos games, robotic simulators, or even learned world models. Once a brittle solution is found, or especially a diverse set of brittle solutions, a robust solution can then be produced in simulation. If the ultimate goal is a policy for the real world (e.g. in robotics), one can then use any of the many available techniques for transferring the robust policy from simulation to the real world [4, 7, 11]. In addition, we plan to demonstrate that it is possible to substitute loading deterministic states with a goal-conditioned policy that learns to deal with stochastic environments from the start. Such an algorithm would still benefit from the three key principles of Go-Explore.
Some might object that, while this method already works in the high-dimensional domain of Atari-from-pixels, it cannot scale to truly high-dimensional domains like simulations of the real world. We believe the method could work there, but it will have to marry a more intelligent cell representation of interestingly different states (e.g. learned, compressed representations of the world) with intelligent (instead of random) exploration. Interestingly, the more conflation one does (mapping more states to the same cell), the more one needs intelligent exploration to reach such qualitatively different cells. Additionally, learning to explore intelligently from any given cell would allow the efficient reuse of skills required for exploration (e.g., walking).
Related work
Go-Explore is reminiscent of earlier work that separates exploration and exploitation. However, Go-Explore further decomposes exploration intro three elements: Accumulate stepping-stones (interestingly different states), return to promising stepping-stones, and explore from them in search of additional stepping-stones (i.e. principles #1 and #2 above). The impressive results Go-Explore achieves by slotting in very simple algorithms for each element shows the value of this decomposition. Another difference vs. all current RL algorithms, as mentioned above when comparing to QD algorithms, is that Go-Explore does not try to get to new or high-performing states by perturbing policies that recently got to novel states, but instead first returns to a state without any perturbation, then explores from it.
The aspect of Go-Explore of first finding a solution and then robustifying around it has precedent in Guided Policy Search. However, this method requires a non-deceptive, non-sparse, differentiable loss function to find solutions, meaning it cannot be applied directly to problems where rewards are discrete, sparse, and/or deceptive, as both Atari and many real-world problems are. Further, Guided Policy Search requires having a differentiable model of the world or learning a set of local models, which to be tractable requires the full state of the system to be observable during training time.
Conclusion
Overall, Go-Explore is an exciting new family of algorithms for solving hard-exploration reinforcement learning problems, meaning those with sparse and/or deceptive rewards. It opens up a large number of new research directions, including experimenting with different archives, different methods for choosing which cells to return to, different cell representations, different exploration methods, and different robustification methods, such as different imitation learning algorithms. We are also excited to see which types of domains Go-Explore excels at and when it fails. It feels to us like a new playground of possibilities in which to explore, and we hope you’ll join us in investigating this terrain.
To enable the community to benefit from Go-Explore and help investigate its potential, source code and a full paper describing Go-Explore are available.
Author’s note, December 3, 2018: update on the issue of stochasticity
We have received many messages in response to our blog article, and we appreciate the feedback from the community. We will address as many issues as we can in our forthcoming paper, but wanted to more quickly update our post with our thoughts on one key issue: stochasticity, including so called “sticky actions.”
A stochastic problem is one in which there is some amount of randomness (e.g., due to wind). We want robots and software that can handle stochastic problem domains. However, our work raises a question that few (including us) had deeply considered before: do we care only that the final product of a machine learning algorithm (e.g., the resulting neural network “policy”) handle stochasticity (i.e., should stochasticity be required in the test environment only), or should we also require learning algorithms to handle stochasticity during training? Let’s take each in turn.
Stochasticity during testing
We agree that agents should ultimately operate in the face of stochasticity and thus that test environments should be stochastic. Since at least 2015, the standard way of adding stochasticity to the Atari benchmark was forcing the robot to do nothing (execute a “no operation” action) a random number of times up to 30. We followed this convention. In 2017, a new proposal was made to add a higher level of stochasticity via “sticky actions”, meaning that each action has a chance of randomly being repeated. We were not aware of a shift away from the conventional form of the benchmark before our blog post, but we agree this variant of the benchmark makes the test environment much more stochastic.
The natural way to have Go-Explore handle this form of stochasticity is to add sticky actions during our robustification phase. Such experiments are underway and we will report the results ASAP. However, we tested whether our current networks are already robust to sticky actions and found they still produce results substantially above the state of the art. When tested with sticky actions, despite not being trained to handle them yet, the networks trained with and without domain knowledge on average score 19,540 and 72,543, respectively, on Montezuma’s Revenge, and 4,655 on Pitfall (with domain knowledge), all of which surpass the previous state of the art. As mentioned, we expect these scores to rise further once we have time to do things the right way.
Stochasticity during training
This issue is complex. We argue there are some use cases in which we should not require stochasticity during training, and others where we should. We start with the former. For many real-world problems, a simulator is often available (e.g., robotics simulators, traffic simulators, etc.) and can be made deterministic. In such problems, we want a reliable final solution (e.g., a robot that reliably finds survivors after a natural disaster) and we should not care whether we got this solution via initially deterministic training. Additionally, because current RL algorithms can take unsafe actions and require tremendous amounts of experience to learn, we expect that the majority of applications of RL in the foreseeable future will require training in a simulator. Go-Explore shows that we can solve previously unsolvable problems, including ones that are stochastic at evaluation time, via making simulators deterministic. Why wouldn’t we want to do that?
That said, we acknowledge that there are cases where a simulator is not available, such as learning directly in the real world, in which learning algorithms must confront stochasticity during training. As we wrote in our original post, we believe Go-Explore can handle such situations by training goal-conditioned policies during the exploration phase, a hypothesis we are currently testing.
With that framework in place, we can revisit our claim that we solved Montezuma’s Revenge and produced state-of-the-art results on this benchmark. To do so, we have to ask: which type of problem was Montezuma’s Revenge meant to represent? The first type (where all we care about is a solution that is robust to stochasticity at test time) or the second (situations where the algorithm must handle stochasticity while training)? We believe few had considered this question before our work and that Go-Explore created a healthy debate on this subject. We conclude that we should have benchmarks for each. One version of a task can require stochasticity during testing only, and another can require stochasticity during both training and testing.
Go-Explore does produce state-of-the-art results for what we thought was the classic version of Montezuma’s Revenge and Pitfall (stochasticity required at testing only). With the new results just mentioned in this update, it does so regardless of whether that stochasticity comes via initial no-ops or sticky actions. But we have not tested Go-Explore on the stochasticity-required-at-training version of Montezuma’s Revenge, where the state of the art at present belongs to the Random Network Distillation paper.
Regarding Pitfall, people who read our article have let us know about two papers that achieve scores above zero on Pitfall. To the best of our knowledge, both test in a purely deterministic version of the game (where Go-Explored scored over 60,000 points before we stopped running it). While both papers are interesting, we did not change our claim about prior algorithms not scoring above zero because we do believe the classic benchmark requires test-time stochasticity via no-ops.
We hope this clarifies our updated thinking on this issue, and sets the record straight regarding claims of state-of-the-art performance.
Author’s note, December 12, 2018: update on robustification with sticky actions
As we noted in our previous update, the proper ‘Go-Explore’ way to handle sticky actions is to add them during Phase 2, the Robustification Phase. Our experiments doing that have completed and, while these numbers could be pushed a little higher with additional training, we think they are worth sharing in their present form. Note they are higher than reported in Jeff Clune’s invited talk at the NeurIPS Deep RL workshop because we let runs go longer.
The neural networks produced by Go-Explore when robustified and then tested with stochasticity in the form of sticky actions on Montezuma’s Revenge score an average of 281,264 (and reach level 18) with domain knowledge, and 33,836 without domain knowledge. On Pitfall, the average score with domain knowledge is 20,527 with a max of 64,616. All of these numbers substantially surpass the prior state of the art (when not requiring stochasticity during training, but only during testing, as discussed in our previous update). Interestingly, the maximum Pitfall score of 64,616 was achieved when robustifying a trajectory that scored only 22,505. It thus learned from that demonstration skills that it used to generalize to new situations to more than triple its score, revealing a new interesting benefit of the Go-Explore approach of adding a robustification phase after discovering a solution.
References
[1] Andrychowicz M, Wolski F, Ray A, Schneider J, Fong R, Welinder P, McGrew B, Tobin J, Abbeel P, and Zaremba W (2017) Hindsight experience replay. In Advances in Neural Information Processing Systems, pp. 5048-5058. 2017.
[2] Aytar Y, Pfaff T, Budden D, Le Paine T, Wang Z, and de Freitas N (2018) Playing hard exploration games by watching YouTube. arXiv preprint arXiv:1805.11592.
[3] Burda Y, Edwards H, Storkey A, and Klimov O (2018) Exploration by Random Network Distillation. arXiv preprint arXiv:1810.12894.
[4] Cully A, Clune J, Tarapore D, Mouret JB (2015) Robots that can adapt like animals. Nature. Vol 521 Pages 503-507.
[5] Hester T, Vecerik M, Pietquin O, Lanctot M, Schaul T, Piot B, Horgan D et al. (2017) Deep Q-learning from Demonstrations. arXiv preprint arXiv:1704.03732.
[6] Pohlen T, Piot B, Hester T, Azar MG, Horgan D, Budden D, Barth-Maron G et al. (2018) Observe and Look Further: Achieving Consistent Performance on Atari. arXiv preprint arXiv:1805.11593.
[7] Koos A, Mouret JB, and Doncieux S (2013) The transferability approach: Crossing the reality gap in evolutionary robotics. IEEE Transactions on Evolutionary Computation 17, no. 1: 122-145.
[8] Mouret JB, Clune J (2015) Illuminating search spaces by mapping elites. arXiv 1504.04909v1.
[9] Salimans T, and Chen R (2018) Learning montezuma’s revenge from a single demonstration. OpenAI Blog.
[10] Schaul T, Horgan D, Gregor K, and Silver D (2015) Universal value function approximators. In International Conference on Machine Learning, pp. 1312-1320. 2015.
[11] Tobin J, Fong R, Ray A, Schneider J, Zaremba W, and Abbeel P (2017) Domain randomization for transferring deep neural networks from simulation to the real world. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 23-30.
Joel Lehman
Joel Lehman was previously an assistant professor at the IT University of Copenhagen, and researches neural networks, evolutionary algorithms, and reinforcement learning.
Jeff Clune
Jeff Clune is the former Loy and Edith Harris Associate Professor in Computer Science at the University of Wyoming, a Senior Research Manager and founding member of Uber AI Labs, and currently a Research Team Leader at OpenAI. Jeff focuses on robotics and training neural networks via deep learning and deep reinforcement learning. He has also researched open questions in evolutionary biology using computational models of evolution, including studying the evolutionary origins of modularity, hierarchy, and evolvability. Prior to becoming a professor, he was a Research Scientist at Cornell University, received a PhD in computer science and an MA in philosophy from Michigan State University, and received a BA in philosophy from the University of Michigan. More about Jeff’s research can be found at JeffClune.com
Kenneth O. Stanley
Before joining Uber AI Labs full time, Ken was an associate professor of computer science at the University of Central Florida (he is currently on leave). He is a leader in neuroevolution (combining neural networks with evolutionary techniques), where he helped invent prominent algorithms such as NEAT, CPPNs, HyperNEAT, and novelty search. His ideas have also reached a broader audience through the recent popular science book, Why Greatness Cannot Be Planned: The Myth of the Objective.
Adrien Ecoffet
Adrien Ecoffet is a research scientist with Uber AI Labs.