Enabling Security for Hadoop Data Lake on Google Cloud Storage
30 July 2024 / Global
Introduction
As part of Uber’s cloud journey, we are migrating the on-prem Apache Hadoop® based data lake along with analytical and machine learning workloads to GCP™ infrastructure platform. The strategy involves replacing the storage layer, HDFS, with GCS Object Storage (PaaS) and running the rest of the tech stack (YARN, Apache Hive™, Apache Spark™, Presto®, etc.) on GCP Compute Engine (IaaS).
A typical cloud adoption strategy involves using cloud-native components and integrating existing IAM with cloud IAM (e.g., federation, identity sync, etc.) (Figure 1.ii). Our strategy is somewhat unique: we continue to leverage part of the existing stack as is (except HDFS) and integrate with GCS (Figure 1.iii). This introduces technical challenges in the following two areas from security perspective:
- Moving to the public cloud requires a different approach to security than on-premise deployments. Hence, we have to develop new IAM controls around storage of data in GCS during the integration.
- The tech stack to be migrated onto GCP IaaS continues to use the Hadoop security model (Kerberos-based auth, Delegation Tokens and ACLs). We would need to make this work with GCS Object Storage by bridging the differences between HDFS and GCS (GCP IAM) security models.
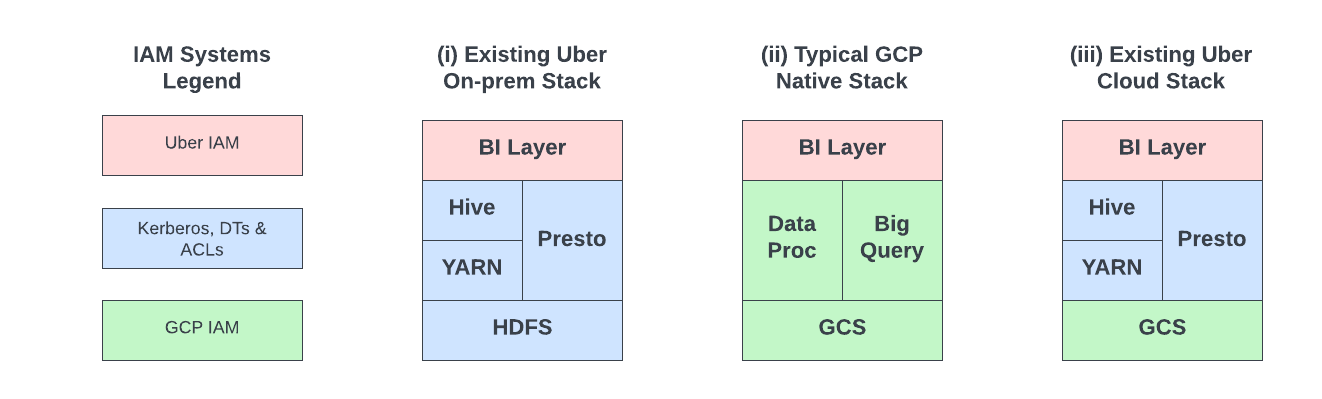
We have built several systems and integrations to support Uber’s data lake migration to GCP. Fast forward to today, we run over 19% of analytical workloads on GCP. In this article, we will explore details of how the above two technical challenges were solved at scale to support the cloud migration.
Existing Architecture
In the existing on-premise tech stack, more than an exabyte of data is stored across several HDFS clusters. A comprehensive suite of automation and ecosystem tools uniformly manages these clusters, encompassing cluster operations, resource management, and security. For security, we rely heavily on Hadoop’s authentication and authorization (HDFS ACLs) features among others. On a high level we have the following components:
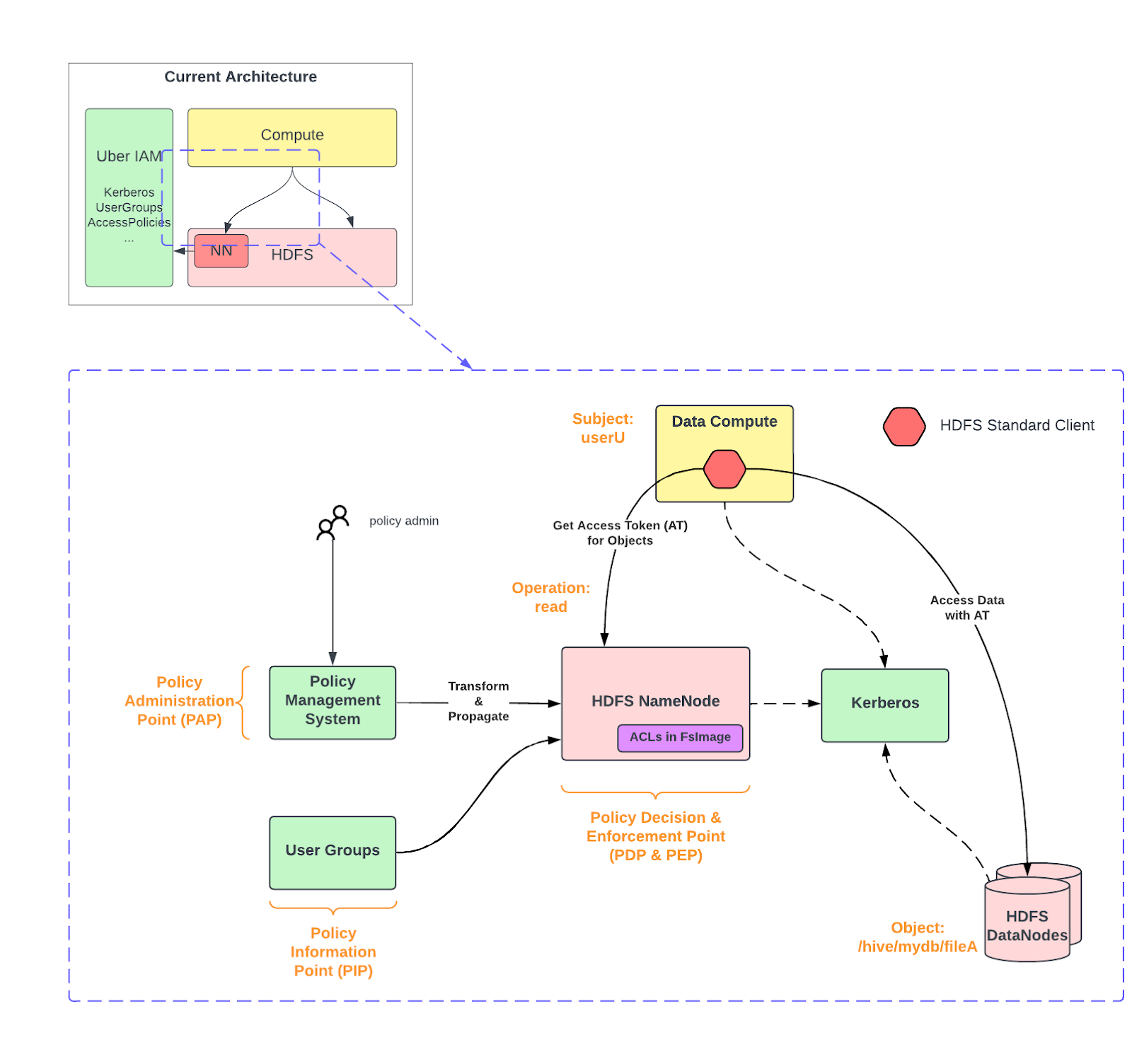
- HDFS NameNode and DataNodes — open source HDFS setup. Thousands of DataNodes store the actual data. NameNodes are responsible for all FileSystem operations, including authentication and authorization logic. HDFS NameNode is a Policy Decision Point (PDP) and a Policy Enforcement Point (PEP) (in NIST terminology).
- Data Compute — collectively refers to workloads leveraging Presto, Spark, MapReduce, etc., that access data stored in HDFS. These workloads utilize a standard HDFS client that is maintained and approved for use internally within Uber.
- User Groups — an internal system that makes Unix users and groups available on every production host – these are used for HDFS ACLs. UserGroups is a NIST Policy Information Point (PIP).
- Policy Management System — manages access control policies for datasets. This system translates dataset policies (configured by Uber’s data platform users) into native HDFS ACLs, ensuring they are synchronized periodically.
- Kerberos — handles authentication among Hadoop components and its clients. You can read how we scaled Kerberos infrastructure in a previous blog we published.
Before we go into details of how we implemented authentication and authorization to seamlessly replace HDFS with Google Cloud Storage, it is important to understand how authentication works in HDFS.
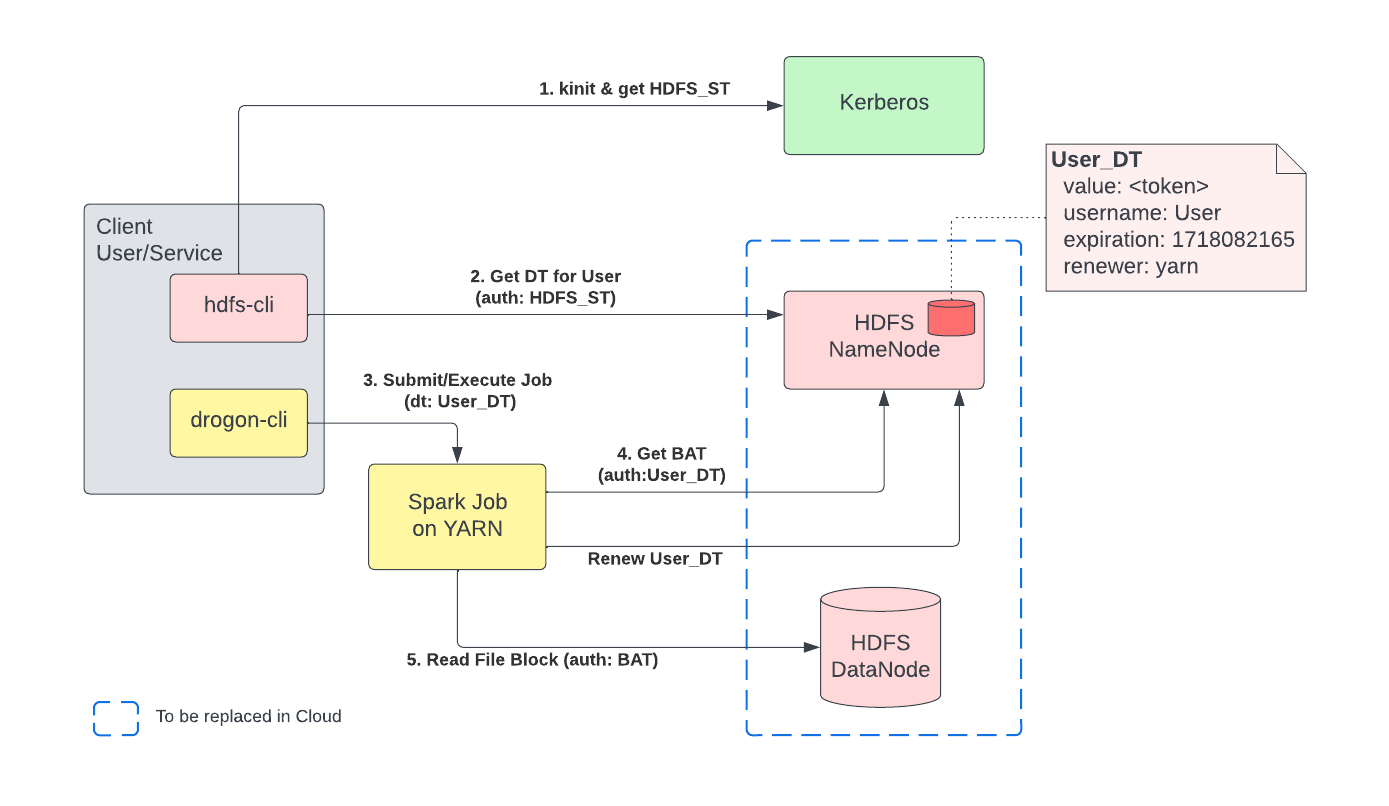
Let’s consider a case where a User wants to submit a Spark job that reads files in an HDFS directory:
- User runs `kinit` to authenticate with Kerberos. Hdfs-cli obtains a Service Ticket for HDFS (HDFS_ST) using Kerberos authentication.
- HDFS client connects to HDFS NameNode to generate an HDFS Delegation Token (User_DT), authenticating with HDFS_ST. HDFS NameNode creates a new token and stores it in an internal store, so it can verify it as FileSystem calls are made.
- Drogon/uSCS is Uber’s Spark as a Service solution. User_DT is passed down to YARN by drogon-cli as part of Spark job submission. YARN saves the User_DT internally and keeps track of the token’s expiration with respect to the job lifetime to renew or cancel the token as needed.
- YARN launches the User’s job as a distributed Spark application with access to User_DT. The job makes HDFS FileSystem calls (using HDFS Standard Client) against HDFS NameNode using User_DT. The access control check to see if the user is authorized to access the file is performed by the NameNode. The FileSystem operation involves asking for Block Access Token (BAT) to read blocks that constitute the file.
- The Job accesses file blocks in HDFS DataNodes, authenticating with BAT.
Cloud Architecture
Layered Access Model
Public cloud attack vectors are quite different from the on-premise deployments. We designed the access model to include security controls at the following layers while setting up the new tech stack in the cloud.
Layer 1 – Foundations: At the lowest layer we managed the following foundational primitives through our declarative infrastructure-as-code (IaC) codebase:
- Network policies: allowing Uber’s existing on-premise systems to connect with our systems in GCP and vice versa
- Service accounts and Project setup: providing access to automated systems in the layers
- Personnel Access: facilitating monitoring and debugging purposes as needed
Layer 2 – Data Mesh: Once layer 1 controls have been set up, the Data Mesh system takes responsibility for automatically setting up and managing several hundreds of GCP projects and GCS buckets. The Data Mesh system compartmentalizes all the Hive tables in the data lake into different departments and types of datasets (raw data, modeled, temporary tables, etc.) across these GCS buckets and projects. This layer provides the flexibility to lockdown access to data within different departments, for example: restricting access to modeled data owned by the Finance department. Access control at this layer is also used for operational automation beyond security requirements, such as locking buckets during data migrations.
Layer 3 – Dataset Access: Workloads themselves manifest in the form of Presto queries, Spark jobs, and Piper pipelines. These workloads access specific data residing in GCS buckets. This layer provides finer-grained access beyond GCS buckets, for Hive databases, tables, and partitions. This layer is aware of users or headless service accounts that submit workloads and access policies that provide time-bounded access to Hive table data stored in GCS.
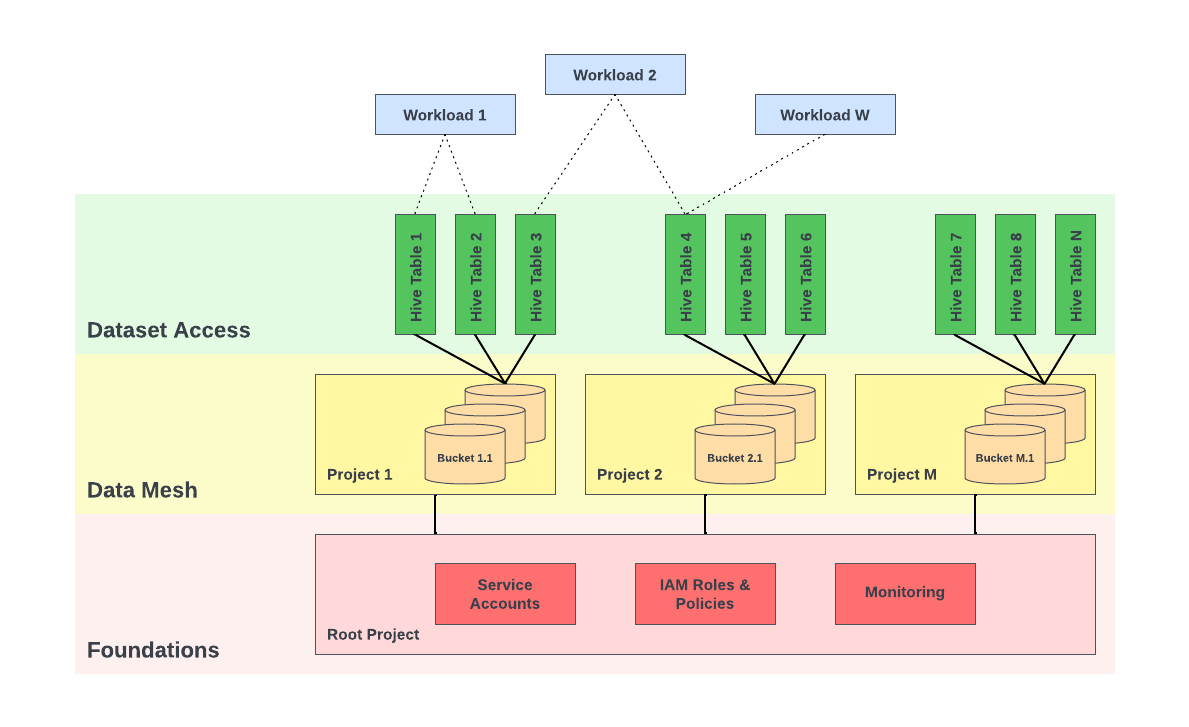
This layered access model enables us to solve challenge A mentioned in the Introduction. Employees who use the Data platform for their various analytics, reporting, and machine learning use cases on a daily basis typically do not need access to resources at layers 1 and 2. Resources at these layers are managed through automation and service accounts instead of humans. Limiting access to human identities reduces the probability of unauthorized access through human identity based attacks.
We continue to use Apache Hudi™ and Apache Parquet™ for the data lake hosted in GCP. This enables us to continue using the existing Parquet-based solution for finer-grained (column-level) access control and encryption features, as is for cloud, beyond the 3 layers described above. To establish layer 3, we built a new system called Storage Access Service, which we’ll cover in the next section.
Storage Access Service
To enable secure access to data residing in GCS, we explored different options that fall into two categories: (a) rely on native GCP IAM constructs or (b) build an intermediary system to handle both authentication and authorization.
Even though option (a) to rely on GCP IAM looks like an obvious choice, we came across the following challenges and drawbacks:
- Our on-premise access control policies are modeled based on group memberships, so it would require us to build a new system to synchronize on-premise users and groups to GCP (in the absence of workload/workforce identity federation for GCS when we started the project). That system should be highly reliable with low latency sync, to avoid breaking existing features we have developed internally, such as just-in-time (JIT) access.
- A single GCS bucket has a hard limit of 250 on the number of IAM role bindings within a policy. Whereas on premise, we have more than 150,000 access control policies (translatable to GCP IAM role bindings) configured for data in HDFS. This could easily result in a management nightmare for the Data Mesh system to move dataset across buckets as they are approaching IAM policy limits. Keeping aside the cost incurred for moving terabytes or petabytes of data, it would have been difficult to make that system operational in a reliable way.
- As mentioned in the Layered Access Model section, we wanted to reduce the possibility of identity based attacks in the cloud. Synchronizing the entire footprint of tens of thousands of users and groups to GCP IAM and authoring new IAM role bindings for GCS bucket policies could increase the possible attack paths due to human identity based attacks and policy misconfigurations. The fewer moving parts we have, the easier it is to secure the system.
Taking all tradeoffs into consideration we realized that we would get better flexibility and control if we developed an intermediary system that handles authentication and authorization (option b). In the cloud data lake stack, the key architectural change comes from replacing HDFS with GCS object storage. HDFS authentication works based on Kerberos and/or Delegation tokens. GCP Cloud Storage works based on cloud tokens (OAuth 2.0 AccessTokens for GCS). To facilitate exchanging Kerberos and Delegation Tokens for Access Tokens, we built an intermediary system called Storage Access Service (SAS).
SAS began as an internal fork of gcp-token-broker (an open source project that was initiated by GCP), that has since been heavily customized to meet Uber’s requirements. Today, SAS intercepts FileSystem calls initiated by HDFS Standard Client against GCS (using gcs hadoop-connector), authenticates it and injects GCP Access Tokens that provide time-bound access to perform specific operations on specific GCS prefixes or objects.

On-premise users and groups are not synchronized to GCP IAM. All humans and workloads need to go through authentication with SAS to access data residing in GCS. SAS uses its own GCP service accounts to generate GCP Access Tokens. We leveraged Hadoop’s existing Delegation Token framework to facilitate token exchange. A Delegation Token (User_DT) is generated before the launch of the distributed application and localized within each of the application containers. When the container (FileSystem client) needs to operate on data residing in GCS, the User_DT is exchanged with SAS to get an Access Token (AT) that can be presented to GCS for authentication. See Figure 6 below for the updated authentication flow for GCS.
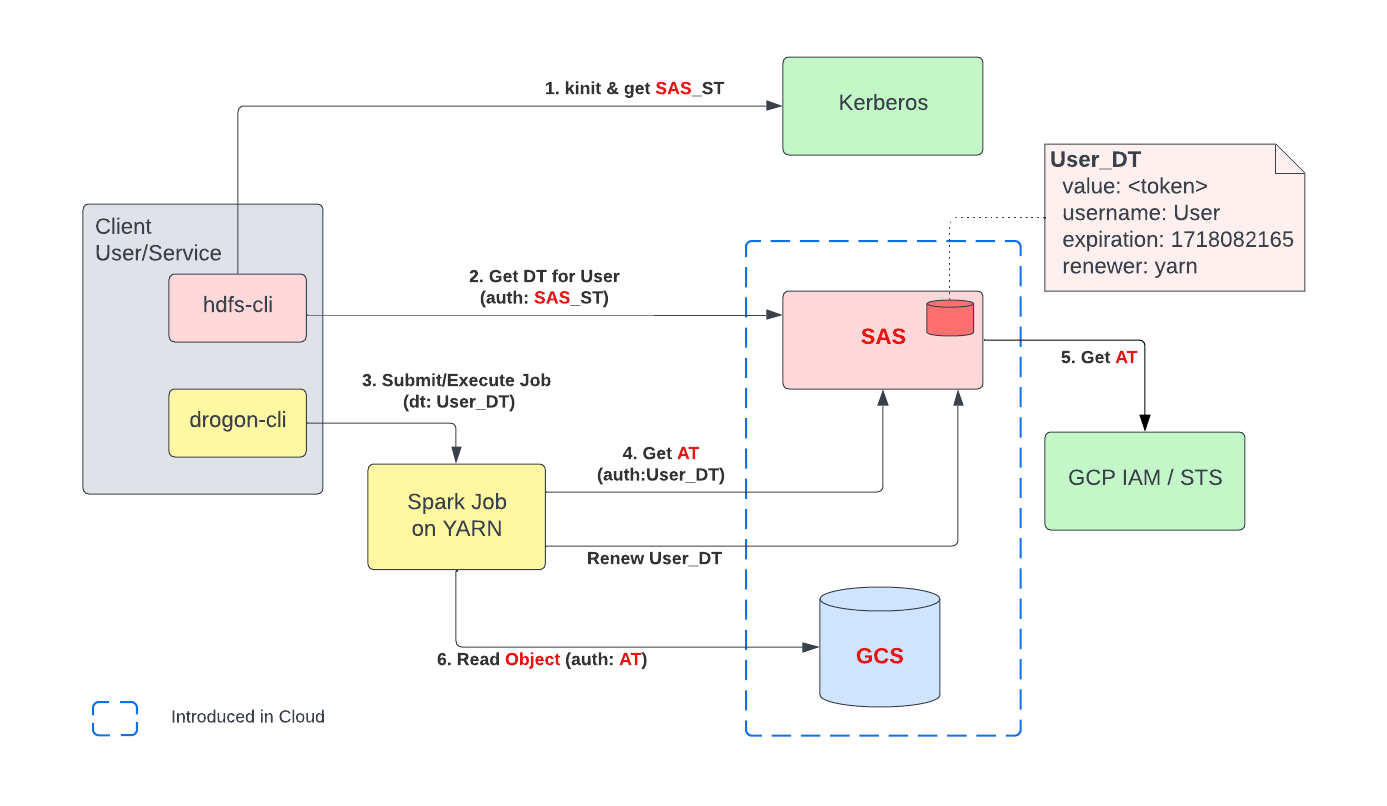
This new diagram is very similar to Figure 3 that presents the HDFS authentication flow, except for a few key changes (highlighted in red in figure 6):
- HDFS NameNode is replaced with SAS. In the new model SAS handles both authentication and authorization like NameNode.
- HDFS DataNodes are replaced with GCS, which stores objects instead of file blocks.
- SAS is now a Delegation Token provider (implements DelegationToken related interfaces such as AbstractDelegationTokenIdentifier). FileSystem clients need to request Delegation Tokens (User_DT) from SAS.
- And finally, HDFS Block Access Token is replaced with GCP OAuth 2.0 Access Token for reading objects
To satisfy access control requirements, the existing Policy Management System (figure 5) was extended such that it maintains a translated version of dataset access policies that can be mapped to GCS prefixes. This enabled a consistent user experience using existing UI for managing access control for datasets regardless of data storage location (GCS or HDFS). Access control policies and dataset <> GCS prefix data are retrieved from Policy Management System and cached within SAS instances.
We designed an authorization plugin that leverages AuthFx library in SAS to evaluate access policies by checking whether a given identity can access the requested GCS resource. If the authorization decision evaluates to ALLOW, a GCP Access Token is returned. For DENY decision, an AuthorizationException is thrown by SAS. GCP supports “downscoping” an Access Token to specific GCS prefixes or objects with its Security Token Service (STS) API. We leveraged this feature to mint time-bound Access Tokens for GCS prefixes by configuring appropriate access boundaries and permissions using IAM conditions. The workload uses the Access Token returned by SAS to perform the specific operation on a certain GCS prefix for a predetermined period of time.
We developed a SAS client library and packaged it into the Uber supported standard HDFS client. The SAS client library provides higher level APIs that generate requests against SAS to request ATs and User_DTs (figure 6). Access Tokens are non-renewable–the SAS client library is intelligent enough to request a new Access Token if needed as long as User_DT is valid.
The SAS client library packaged within HDFS standard client made the security aspects of the cloud migration completely transparent to existing hundreds of thousands of distinct workloads executed daily. By building SAS, we were able to bridge the differences between GCS and HDFS security models and abstracted away the intricacies from users of the data platform (solving challenge B mentioned in the Introduction).
Scaling the System
SAS intercepts all FileSystem calls to support authentication and authorization. Scaling this system to support existing use cases was critical to facilitate migration. We followed the same guiding principles that we follow for other projects: “Assess current scale requirements (X) through data-driven analysis, design for 10X scale and build MVP for 1X scale with a clear feasible path towards supporting 10X”.
Based on existing metrics from several HDFS clusters that support the existing data lake, we estimated X as the ability to serve ~500,000 RPS (throughput) at p99 ~20ms latency. Note that a typical FileSystem operation in HDFS includes security auth in addition to the core FileSystem logic that involves inode changes, locking, etc depending on the operation. We budgeted 10% of 20 ms (i.e., 2 ms) as the latency requirement for auth. GCP’s Security Token Service API has a quota of 6k rpm (note this is RPM – not RPS) for token exchange requests. During prototype testing, we observed the request latency was around ~50 ms.
| Requirements | GCP Security Token Service (STS) | |
| Throughput | ~500,000 RPS | 6,000 RPM (100 RPS Limit) |
| Latency (p99) | ~2 ms | 50 ms (Uber’s test observation) |
Multi-Level Caching
To address the impedance mismatch for throughput and latency and scale SAS to meet the requirements, we employed a multi-level caching solution. The multi-level cache involved three layers of caching, which became the core of SAS’ strategy to scale.
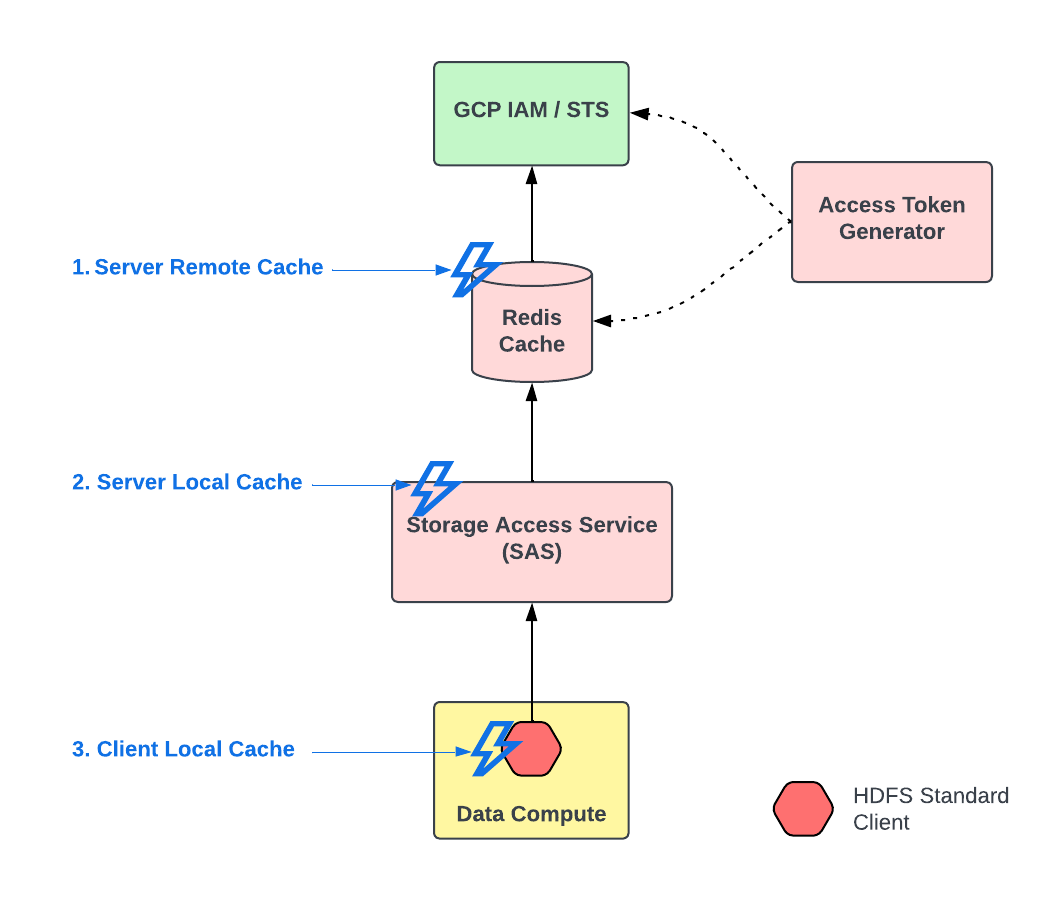
1. Server Remote Cache: The most critical part was to decouple the FileSystem client request (read) for Access Token from SAS, from its generation (write) from GCP APIs. SAS is made aware of all the possible Hive datasets (tables, databases, etc.) and their GCS path prefixes (by the Policy Management System). An Access Token Generator process (hosted on SAS instances) uses this information to proactively generate all combinations of tokens (required for different operations on Hive tables) from GCP STS APIs and store them in a secure Redis cluster. The logic of generating tokens from GCP STS APIs is controlled in such a way that it stays under GCP STS API limits. This read-write segregation (CQRS design pattern) enables us to scale SAS horizontally to serve the throughput requirements required by the FileSystem client independent of the GCP limits.
The tokens stored in Redis are keyed by the GCS prefix and operation the token provides access to. This enables SAS to easily look up and respond with Access Tokens to the FileSystem client based on the GCS path and operation requested. The Access Token Generator is intelligent enough to keep track of expiration time of each token and generate a new token as it nears its expiration time. Proactively generating and caching tokens greatly reduced the likelihood of a cache miss. In the event of a cache miss, we implemented the cache aside pattern logic into SAS (request token from GCP, save to Redis and return to FileSystem client).
2. Server Local Cache: From our observation with existing HDFS data, we found that some tables (such as fact tables) are quite popular and commonly used. Hence, tokens associated with these tables would need to be retrieved from Redis frequently. We implemented an in-memory cache within SAS servers to avoid the round trip latency to Redis for this scenario. This enabled us to improve the overall latency observed by clients.
3. Client Local Cache: Any given workload (job or query) reads a finite set of Hive tables during its lifetime, which could translate to hundreds of thousands of files within a deterministic set of GCS prefixes (and hence, tokens). Since tokens can be reused for the objects under the same GCS prefix, we introduced a client side cache that significantly reduced the number of calls from FileSystem clients to SAS servers. This not only improved the token retrieval latency observed by the FileSystem clients, but also reduced the pressure on SAS servers to scale in order to support the bursty and periodic throughput changes observed for batch and interactive workloads.
Cache Eviction
GCP Access Token size (~200 bytes) was minimal and cardinality of tokens at any given time was in the order of combination of number of Hive datasets (or GCS prefixes) and possible operations. Hence, cache size (< 20 GB) was less of a concern for Server Remote Cache backed by Redis cluster. We set reasonable upper bounds on cache size limits on both Server Local and Client Local caches.
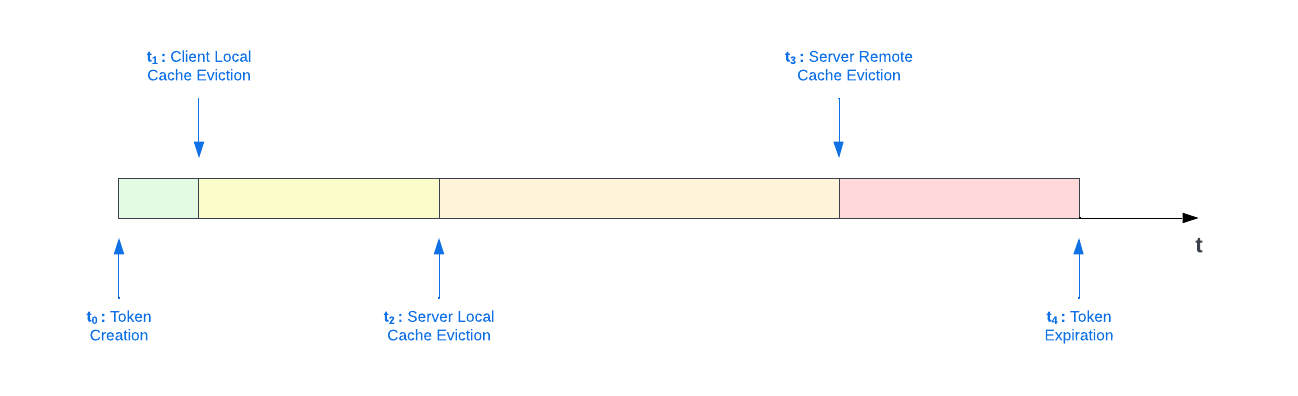
The cache eviction strategy primarily centered around Access Token lifetime. Access Token has a maximum lifetime of 1 hour (configurable up to 12 hours). Not evicting tokens before expiration would lead to FileSystem call failures (Unauthorized since token has expired). Evicting tokens too soon would lead to higher cache misses resulting in higher latencies and more pressure on scalability of the system. We adjusted the cache time (as indicated by figure 9) across the different caching layers to achieve a high degree of cache hit ratio taking these factors into consideration.
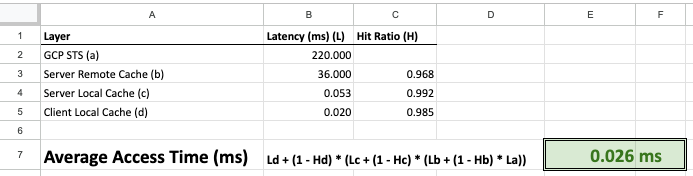
We closely monitored caching latencies and hit ratio across the different layers. With the multi level caching strategy we observed average latencies in the order of 0.026 ms.
Benchmarking & Testing
For benchmarking, we employed the same strategy that we previously used for load testing HDFS NameNodes: utilizing Dynamometer. We adapted the existing dynamometer codebase such that it can replay existing HDFS cluster audit logs against SAS and GCP APIs. We conducted over 45 iterations of benchmark tests across various parameter combinations, including authorization enabled/disabled and caching enabled/disabled. Our goal was to meet performance targets for vertical scaling (single SAS container) and determine the number of containers required for horizontal scaling. These extensive tests helped us identify gaps and meet specific performance goals.
We discovered several optimizations by analyzing results from logs, flame graphs, and memory dumps. Key improvements included datastore/caching related enhancements, reducing redundant calls to GCP APIs, tuning gRPC timeouts, improving resources utilized for logging, and utilizing a faster algorithm for token encryption and decryption. These optimizations significantly boosted our system’s overall performance and reliability.
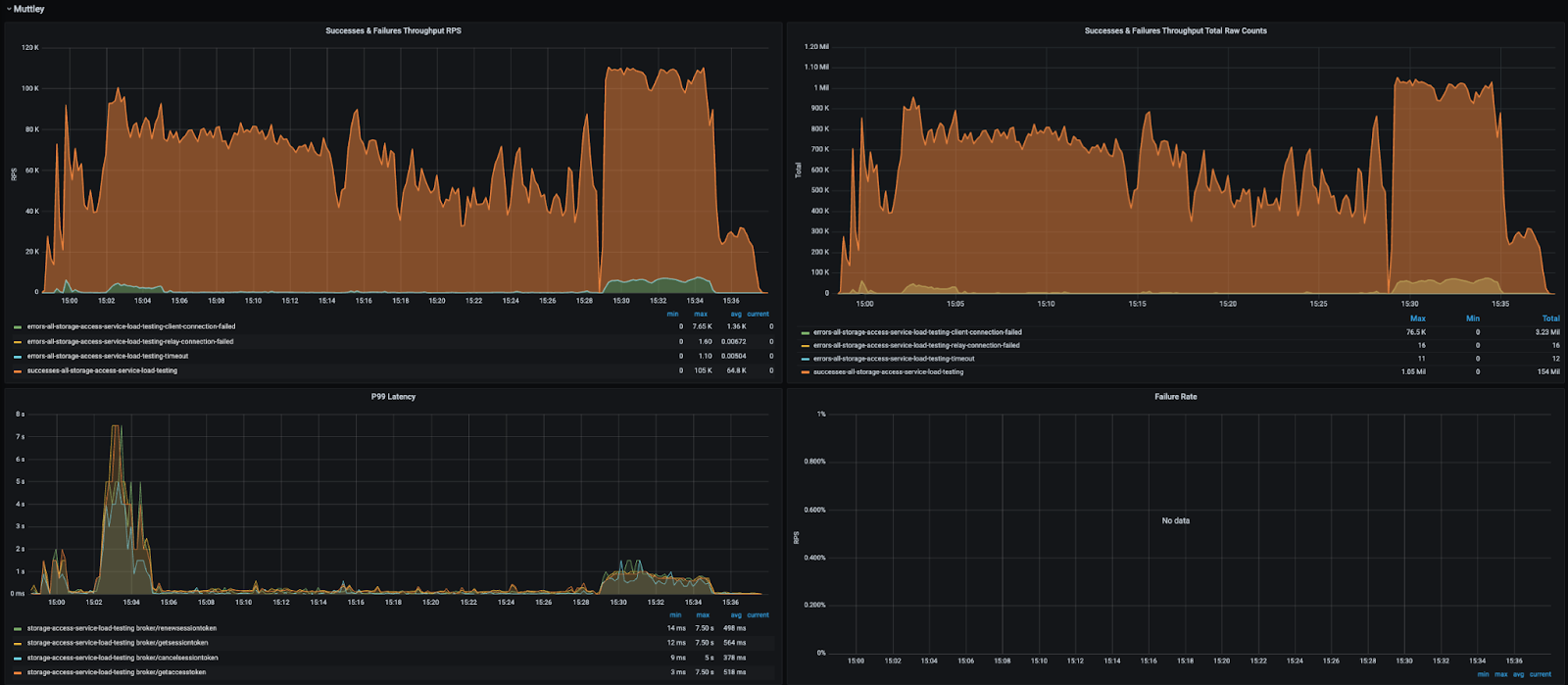
We developed continuous probing to test all possible FileSystem operations on GCS buckets used for production data lake. The tests exercised different Hadoop authentication strategies (direct, proxy, and delegated auth) and access control policies through positive and negative tests. These prober tests are also executed in the dev environment to facilitate developer velocity and are triggered with every new change, both before and after merging. Additionally, we closely monitor for regressions across different environments (dev, staging, beta, and prod) using appropriate observability tools, including metrics, logs, and alerts. This diligent monitoring helps us to promptly identify and address issues, and maintain the integrity and performance of our system across all stages of deployment.
Conclusion
If you have read this far into this blog post, here are the three key insights we hope you take away from our journey:
- Enhanced Security in the Cloud: We have migrated over 160+ PB of data to GCS. With the layered access model, human identities do not have direct access to data stored in GCS. SAS serves as the authentication and authorization layer for access to the data lake on GCS. We took the cloud migration as an opportunity to strengthen our access control measures.
- Scaling with Multi-Layer Caching: We developed a multi-layer caching strategy and conducted rigorous benchmarking/testing over several iterations with various parameters. With 19%+ of analytical workloads running on GCP, we have observed that SAS authenticates and authorizes GCS operations that peak to over 500k rps. The request volume seen by SAS instances themselves hover well below 10,000 RPS, while the GCP IAM/STS APIs stay below 60 RPS. The multi-level caching strategy has been highly effective and helped us scale the overall system.
- Seamless Migration Support: We invested judiciously on standardizing HDFS clients across the company in the past. We used the standard HDFS client as a vehicle to get all workloads to adopt a SAS client which abstracts out the security integrations through proper design. With this approach, Uber’s data platform users are not aware of any differences between HDFS and GCS security models, which enables seamless migration to the cloud.
During the initial planning stages of our cloud migration project, the “Security Integration” workstream was identified as a high priority. Through careful design and development, we successfully overcame the technical challenges. As Uber’s cloud migration continues, we invite you to follow our journey. We’ll be sharing more technical details on other critical workstreams discussed in our previous blog post. Stay tuned for more insights and updates!
Acknowledgements
The work portrayed in this article would not have been possible without close collaboration with our partnering GCP team members: Mandeep Singh Bawa, Julien Phalip, Shlok Karpathak, Namita Sharma, Arend Dittmer and Matthew Rahman. Their expertise and support have been instrumental in designing and implementing the solution to achieve our goals.
Header Image Attribution: The “Secure Cloud – Data Security – Cyber Security” image is covered by a CC BY-SA 2.0 license and is credited to perspec_photo88.
Apache®, Apache Parquet™, Apache Hudi™, Apache Spark™, Apache Hadoop YARN™ are registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Presto® is a registered trademark of The Linux Foundation in the United States and/or other countries. No endorsement by The Linux Foundation is implied by the use of these marks.
GCP™ infrastructure platform is a registered trademark of Google LLC in the United States and/or other countries. No endorsement by Goggle LLC is implied by the use of these marks.Kerberos is a trademark of the Massachusetts Institute of Technology (MIT) in the United States and/or other countries. No endorsement by MIT is implied by the use of these marks.

Matt Mathew
Matt is a Sr. Staff Engineer on the Engineering Security team at Uber. He currently works on various projects in the security domain. Previously, he led the initiative to containerize and automate Data infrastructure at Uber.

Alexander Gulko
Alexander is a Staff Software Engineer working on the Data Security team based in Seattle, WA. While the team is responsible for all aspects of data security and compliance, he primarily focuses on Authentication and leads various initiatives in that area.

Lei Sun
Lei Sun is a Tech Lead Manager on the Technical Privacy team at Uber. His team builds highly scalable, highly reliable yet efficient infrastructure with innovative ideas to protect the privacy of customers and empower Uber engineers to seamlessly integrate security, compliance and privacy into their product development lifecycle.

KK Sriramadhesikan
KK Is a Sr Staff Security Engineer at Uber. KK secures Uber’s use of the cloud. He also works on a broad set of cross-functional initiatives on Security & Privacy at Uber.

Alan Cao
Alan is a Staff Software Engineer on the Core Security Engineering team at Uber. He works on the unified authorization platform for Uber’s services and infrastructure.

Omkar Kakade
Omkar is a Software Engineer working on the Data Security team at Uber. His expertise primarily lies in authorization, where he leads various initiatives to safeguard data integrity.
Posted by Matt Mathew, Alexander Gulko, Lei Sun, KK Sriramadhesikan, Alan Cao, Omkar Kakade
Related articles




Most popular
Terms and Conditions: HK Seasonal Travel Campaign

Migrating Large-Scale Interactive Compute Workloads to Kubernetes Without Disruption

Building Uber’s Multi-Cloud Secrets Management Platform to Enhance Security
