Making Apache Spark Effortless for All of Uber
Apache Spark is a foundational piece of Uber’s Big Data infrastructure that powers many critical aspects of our business. We currently run more than one hundred thousand Spark applications per day, across multiple different compute environments. Spark’s versatility, which allows us to build applications and run them everywhere that we need, makes this scale possible.
However, our ever-growing infrastructure means that these environments are constantly changing, making it increasingly difficult for both new and existing users to give their applications reliable access to data sources, compute resources, and supporting tools. Also, as the number of users grow, it becomes more challenging for the data team to communicate these environmental changes to users, and for us to understand exactly how Spark is being used.
We built the Uber Spark Compute Service (uSCS) to help manage the complexities of running Spark at this scale. This Spark-as-a-service solution leverages Apache Livy, currently undergoing Incubation at the Apache Software Foundation, to provide applications with necessary configurations, then schedule them across our Spark infrastructure using a rules-based approach.
uSCS now handles the Spark applications that power business tasks such as rider and driver pricing computation, demand prediction, and restaurant recommendations, as well as important behind-the-scenes tasks like ETL operations and data exploration. uSCS introduced other useful features into our Spark infrastructure, including observability, performance tuning, and migration automation.
Problems with using Apache Spark at scale
Spark performance generally scales well with increasing resources to support large numbers of simultaneous applications. However, we found that as Spark usage grew at Uber, users encountered an increasing number of issues:
- Data source diversity: Spark applications access multiple data sources, such as HDFS, Apache Hive, Apache Cassandra, and MySQL. The configurations for each data source differ between clusters and change over time: either permanently as the services evolve or temporarily due to service maintenance or failure. Spark users need to keep their configurations up-to-date, otherwise their applications may stop working unexpectedly.
- Multiple compute clusters: Uber’s compute platform provides support for Spark applications across multiple types of clusters, both in on-premises data centers and the cloud. Proper application placement requires the user to understand capacity allocation and data replication in these different clusters.
- Multiple Spark versions: Some versions of Spark have bugs, don’t work with particular services, or have yet to be tested on our compute platform. Helping our users solve problems with many different versions of Spark can quickly become a support burden. Also, as older versions of Spark are deprecated, it can be risky and time-consuming to upgrade legacy applications that work perfectly well in their current incarnations to newer versions of Spark.
- Dependency issues: As the number of applications grow, so too does the number of required language libraries deployed to executors. This inevitably leads to version conflicts or upgrades that break existing applications.
The cumulative effect of these issues is that running a Spark application requires a large amount of frequently changing knowledge, which platform teams are responsible for communicating. We need to make sure that it’s easy for new users to get started, but also that existing application owners are kept informed of all service changes that affect them. Failure to do so in a timely manner could cause outages with significant business impact.
Coordinating this communication and enforcing application changes becomes unwieldy at Uber’s scale. So uSCS addresses this by acting as the central coordinator for all Spark applications. uSCS maintains all of the environment settings for a limited set of Spark versions. Users submit their Spark application to uSCS, which then launches it on their behalf with all of the current settings. This approach makes it easier for us to coordinate large scale changes, while our users get to spend less time on maintenance and more time on solving other problems.
Spark development workflow
We designed uSCS to address the issues listed above. Before explaining the uSCS architecture, however, we present our typical Spark workflow from prototype to production, to show how uSCS unlocks development efficiencies at Uber.
Data exploration and iterative prototyping
The typical Spark development workflow at Uber begins with exploration of a dataset and the opportunities it presents. This is a highly iterative and experimental process which requires a friendly, interactive interface. Our interface of choice is the Jupyter notebook.
Users can create a Scala or Python Spark notebook in Data Science Workbench (DSW), Uber’s managed all-in-one toolbox for interactive analytics and machine learning.

In DSW, Spark notebook code has full access to the same data and resources as Spark applications via the open source Sparkmagic toolset. This means that users can rapidly prototype their Spark code, then easily transition it into a production batch application.
Converting a prototype into a batch application
Most Spark applications at Uber run as scheduled batch ETL jobs. The method for converting a prototype to a batch application depends on its complexity. If the application is small or short-lived, it’s easy to schedule the existing notebook code directly from within DSW using Jupyter’s nbconvert conversion tool.
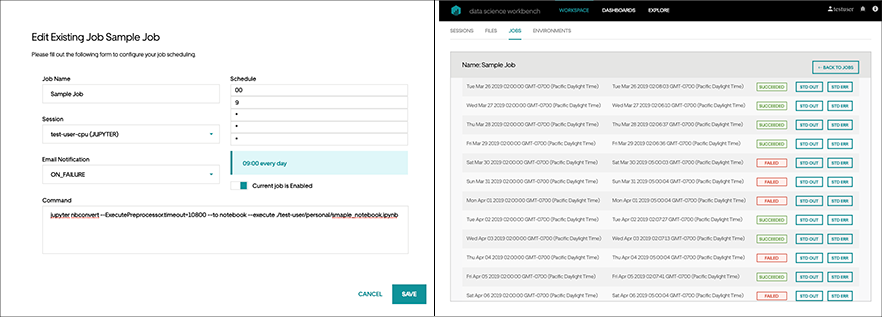
For larger applications, it may be preferable to work within an integrated development environment (IDE). So users are able to develop their code within an IDE, then run it as an interactive session that is accessible from a DSW notebook. This type of environment gives them the instant feedback that is essential to test, debug, and generally improve their understanding of the code.
Production
Our standard method of running a production Spark application is to schedule it within a data pipeline in Piper (our workflow management system, built on Apache Airflow). Through this process, the application becomes part of a rich workflow, with time- and task-based trigger rules. Once the trigger conditions are met, Piper submits the application to Spark on the owner’s behalf.
Monitoring and debugging applications

Users monitor their application in real-time using an internal data administration website, which provides information that includes the application’s current state (running/succeeded/failed), resource usage, and cost estimates. If the application fails, this site offers a root cause analysis of the likely reason. There is also a link to the Spark History Server, where the user can debug their application by viewing the driver and executor logs in detail.
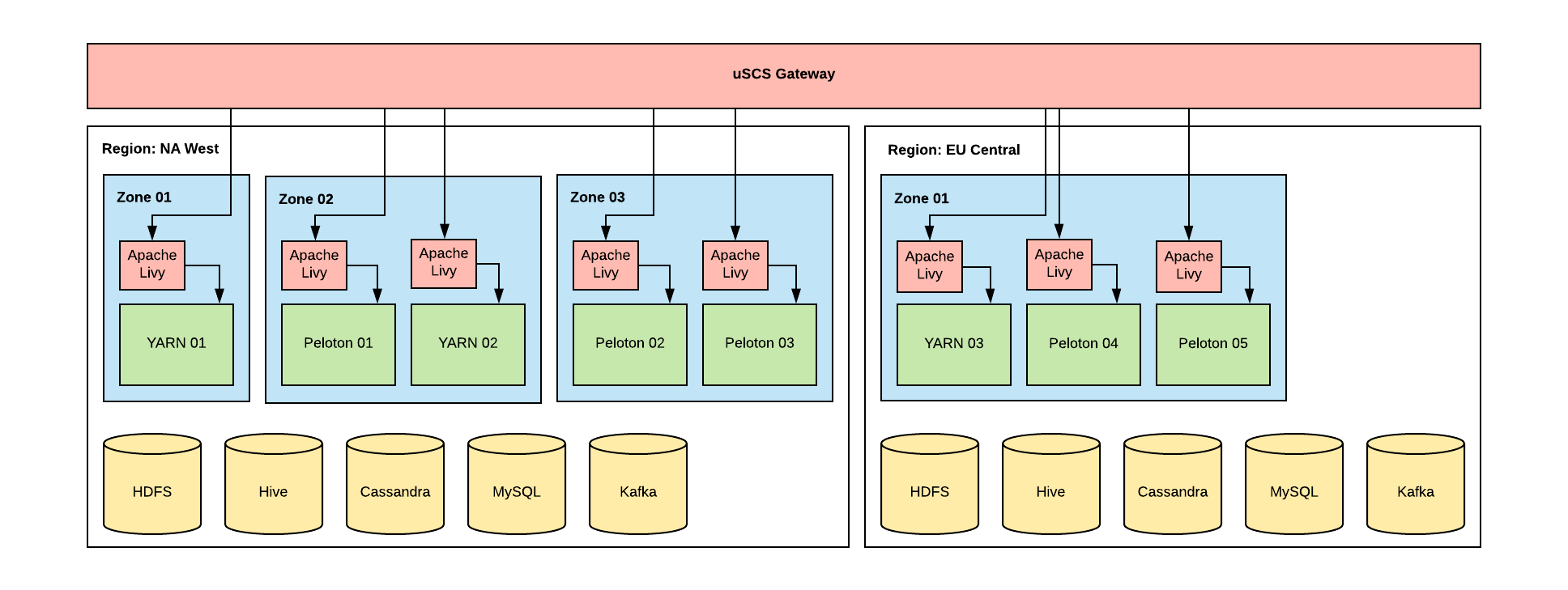
Clusters at Uber
We maintain compute infrastructure in several different geographic regions. Each region has its own copy of important storage services, such as HDFS, and has a number of compute clusters. The storage services in a region are shared by all clusters in that region.

There are two main cluster types, as determined by their resource managers:
- YARN, which only handles batch workloads
- Peloton, Uber’s open source resource scheduler, which colocates batch and online workloads
Because storage is shared within a region, an application that runs on one compute cluster should run on all other compute clusters within the same region. However, differences in resource manager functionality mean that some applications will not automatically work across all compute cluster types. One of our goals with uSCS to enable Spark to work seamlessly over our entire large-scale, distributed data infrastructure by abstracting these differences away.
uSCS architecture
Our development workflow would not be possible on Uber’s complex compute infrastructure without the additional system support that uSCS provides.
uSCS consists of two key services: the uSCS Gateway and Apache Livy. To use uSCS, a user or service submits an HTTP request describing an application to the Gateway, which intelligently decides where and how to run it, then forwards the modified request to Apache Livy. Apache Livy builds a Spark launch command, injects the cluster-specific configuration, and submits it to the cluster on behalf of the original user.
The uSCS Gateway makes rule-based decisions to modify the application launch requests it receives, and tracks the outcomes that Apache Livy reports. Example decisions include:
- The specific cluster to run on
- The Spark version to use for the given application
- The compute resources to allocate to the application
These decisions are based on past execution data, and the ongoing data collection allows us to make increasingly informed decisions. If an application fails, the Gateway automatically re-runs it with its last successful configuration (or, if it is new, with the original request).
Apache Livy submits each application to a cluster and monitors its status to completion. We run multiple Apache Livy deployments per region at Uber, each tightly coupled to a particular compute cluster. Therefore, each deployment includes region- and cluster-specific configurations that it injects into the requests it receives. We also configure them with the authoritative list of Spark builds, which means that for any Spark version we support, an application will always run with the latest patched point release.
We have made a number of changes to Apache Livy internally that have made it a better fit for Uber and uSCS. These changes include.
- Support for Multi-Node High Availability, by storing state in MySQL and publishing events to Kafka.
- Support for selecting which Spark version the application should be started with.
- Resource Manager abstraction, which enables us to launch Spark applications on Peloton in addition to YARN.
- Authentication scheme abstraction.
- Automatic token renewal for long running applications.
We would like to reach out to the Apache Livy community and explore how we can contribute these changes.
The uSCS Gateway offers a REST interface that is functionally identical to Apache Livy’s, meaning that any tool that currently communicates with Apache Livy (e.g. Sparkmagic) is also compatible with uSCS.
uSCS example workflow
To better understand how uSCS works, let’s consider an end-to-end example of launching a Spark application.
A user wishing to run a Python application on Spark 2.4 might POST the following JSON specification to the uSCS endpoint:
| { “name”: “MonthlyReport”, “file”: “hdfs:///user/test-user/monthly_report.py”, “args”: [“–city-id”, “729”, “–month”, “2019/01”], “sparkEnv”: “SPARK_21”, “queue”: “example-queue”, “driverMemory”: “8g”, “executorMemory”: “8g”, “executorCores”: 2, “numExecutors”: 100 } REGION: NA WEST CLUSTER: ZONE 01 YARN 01 |
This request contains only the application-specific configuration settings; it does not contain any cluster-specific settings. This is because uSCS decouples these configurations, allowing cluster operators and applications owners to make changes independently of each other. Decoupling the cluster-specific settings plays a significant part in solving the communication coordination issues discussed above.
Based on historical data, the uSCS Gateway knows that this application is compatible with a newer version of Spark and how much memory it actually requires. It also decides that this application should run in a Peloton cluster in a different zone in the same region, based on cluster utilization metrics and the application’s data lineage. The resulting request, as modified by the Gateway, looks like this:
| { “name”: “MonthlyReport”, “file”: “hdfs:///user/test-user/monthly_report.py”, “args”: [“–city-id”, “729”, “–month”, “2019/01”], “sparkEnv”: “SPARK_24”, “queue”: “example-queue”, “driverMemory”: “8g”, “executorMemory”: “4073m”, “executorCores”: 2, “numExecutors”: 100 } REGION: NA WEST CLUSTER: ZONE 02 PELOTON 05 |
Apache Livy then builds a spark-submit request that contains all the options for the chosen Peloton cluster in this zone, including the HDFS configuration, Spark History Server address, and supporting libraries like our standard profiler. It applies these mechanically, based on the arguments it received and its own configuration; there is no decision making. Then it uses the spark-submit command for the chosen version of Spark to launch the application. The Gateway polls Apache Livy until the execution finishes and then notifies the user of the result.
Figure 6, below, shows a summary of the path this application launch request has taken:

Advantages of this architecture
We have been running uSCS for more than a year now with positive results. The advantages the uSCS architecture offers range from a simpler, more standardized application submission process to deeper insights into how our compute platform is being used.
Service configuration abstraction
Prior to the introduction of uSCS, dealing with configurations for diverse data sources was a major maintainability problem. The abstraction that uSCS provides eliminates this problem. For example, when connecting to HDFS, users no longer need to know the addresses of the HDFS NameNodes. We can also change these configurations as necessary to facilitate maintenance or to minimize the impact of service failures, without requiring any changes from the user.
Observability
Before uSCS, we had little idea about who our users were, how they were using Spark, or what issues they were facing. uSCS now allows us to track every application on our compute platform, which helps us build a collection of data that leads to valuable insights. Some benefits we have already gained from these insights include:
- Seeing when applications are failing so that we can act quickly: If it’s an infrastructure issue, we can update the Apache Livy configurations to route around problematic services. If it’s an application issue, we can reach out to the affected team to help. For example, we noticed last year that a certain slice of applications showed a high failure rate. When we investigated, we found that this failure affected the generation of promotional emails; a problem which might have taken some time to discover otherwise.
- Recognizing failure trends over time: As we gather historical data, we can provide increasingly rich root cause analysis to users. In some cases, such as out-of-memory errors, we can modify the parameters and re-submit automatically.
- Better understanding Spark usage at Uber: We are now building data on which teams generate the most Spark applications and which versions they use. When we need to introduce breaking changes, we have a good idea of the potential impact and can work closely with our heavier users to minimize disruption.
Instrumentation and performance tuning
By handling application submission, we are able to inject instrumentation at launch. Specifically, we launch applications with Uber’s JVM profiler, which gives us information about how they use the resources that they request. We are then able to automatically tune the configuration for future submissions to save on resource utilization without impacting performance. As a result, the average application being submitted to uSCS now has its memory configuration tuned down by around 35 percent compared to what the user requests.
Migration automation
We expect Spark applications to be idempotent (or to be marked as non-idempotent), which enables us to experiment with applications in real-time. We do this by launching the application with a changed configuration. If the application still works, then the experiment was successful and we can continue using this configuration in the future. If it does not, we re-launch it with the original configuration to minimize disruption to the application.
This experimental approach enables us to test new features and migrate applications which run with old versions of Spark to newer versions. We also took this approach when migrating applications from our classic YARN clusters to our new Peloton clusters.
Interactive notebooks
As discussed above, our current workflow allows users to run interactive notebooks on the same compute infrastructure as batch jobs. This is possible because Sparkmagic runs in the DSW notebook and communicates with uSCS, which then proxies communication to an interactive session in Apache Livy.
Launching applications via services
The HTTP interface to uSCS makes it easy for other services at Uber to launch Spark applications directly. As a result, other services that use Spark now go through uSCS. The most notable service is Uber’s Piper, which accounts for the majority of our Spark applications. Opening uSCS to these services leads to a standardized Spark experience for our users, with access to all of the benefits described above.
Application-specific containers
Peloton clusters enable applications to run within specific, user-created containers that contain the exact language libraries the applications need. uSCS benefits greatly from this feature, as our users can leverage the libraries they want and can be confident that the environment will remain stable in the future.
We now maintain multiple containers of our own, and can choose between them based on application properties such as the Spark version or the submitting team. If we do need to upgrade any container, we can roll out the new versions incrementally and solve any issues we encounter without impacting developer productivity.
Moving forward
uSCS offers many benefits to Uber’s Spark community, most importantly meeting the needs of operating at our massive scale. Its workflow lets users easily move applications from experimentation to production without having to worry about data source configuration, choosing between clusters, or spending time on upgrades.
Through uSCS, we can support a collection of Spark versions, and containerization lets our users deploy any dependencies they need. uSCS’s tools ensure that applications run smoothly and use resources efficiently. The architecture lets us continuously improve the user experience without any downtime.
While uSCS has led to improved Spark application scalability and customizability, we are committed to making using Spark even easier for teams at Uber. In the future, we hope to deploy new capabilities and features that will enable more efficient resource utilization and enhanced performance
We are interested in sharing this work with the global Spark community. Please contact us if you would like to collaborate! If working on distributed computing and data challenges appeals to you, consider applying for a role on our team!
Acknowledgements
We would like to thank our team members Felix Cheung, Karthik Natarajan, Jagmeet Singh, Kevin Wang, Bo Yang, Nan Zhu, Jessica Chen, Kai Jiang, Chen Qin and Mayank Bansal.
Chinese Water Dragon photo by InspiredImages/Pixabay.
Abhishek Modi
Modi is a software engineer on Uber’s Data Platform team. Modi helps unlock new possibilities for processing data at Uber by contributing to Apache Spark and its ecosystem.
Adam Hudson
Adam is a senior software engineer on Uber’s Data Platform team. Adam works on solving the many challenges raised when running Apache Spark at scale.