Containerizing Apache Hadoop Infrastructure at Uber
Sr Staff Engineer
Introduction
As Uber’s business grew, we scaled our Apache Hadoop (referred to as ‘Hadoop’ in this article) deployment to 21000+ hosts in 5 years, to support the various analytical and machine learning use cases. We built a team with varied expertise to address the challenges we faced running Hadoop on bare-metal: host lifecycle management, deployment and automation, Hadoop core development, and customer facing portals.
With the growing complexity and size of Hadoop infrastructure, it became increasingly difficult for the team to keep up with the various responsibilities around managing such a large fleet. Fleet-wide operations using scripts and tooling consumed a lot of engineering time. Bad hosts started piling up without timely repairs.
As we continued to maintain our own bare-metal deployment for Hadoop, the rest of the company made significant progress in the microservices world. Solutions for container orchestration, host lifecycle management, service mesh, and security laid the foundations, making management of microservices far more efficient and less cumbersome.
In 2019, we started a journey to re-architect the Hadoop deployment stack. Fast forward 2 years, over 60% of Hadoop runs in Docker containers, bringing major operational benefits to the team. As a result of the initiative, the team handed off many of their responsibilities to other infrastructure teams, and was able to focus more on core Hadoop development.

This article provides a summary of problems we faced, and how we solved them along the way.
The Past
Before getting into architecture, it is worth briefly describing our old way of operating Hadoop and its drawbacks. Several disaggregated solutions working together powered the bare-metal deployment of Hadoop. This involved:
- Automation that mutated the host setup in place
- Non-idempotent action-based scripts that were triggered and monitored manually
- A loosely coupled host lifecycle management solution
Under the hood, this was implemented across a couple of Golang services, a plethora of Python and Bash scripts, Puppet manifests, and some Scala code to top it off. We used Cloudera Manager (free edition) and evaluated Apache Ambari in the early days. However, both of these systems proved insufficient due to Uber’s custom deployment model.
We had several challenges with our old operating methods, not limited to the following:
- Manual in-place mutation of production hosts led to drifts that surprised us later on. Engineers often debated the deployment process, as some changes were not reviewed and identified during incident response.
- Fleet-wide changes took forever to plan and orchestrate manually. Our last OS upgrade was delayed, and eventually took over 2 years to finish.
- Mismanaged configurations led to incidents a few months later. We misconfigured dfs.blocksize, which eventually led to HDFS RPC queue-time degradation in one of our clusters.
- Lack of good contracts between automation and human interactions led to unintended, serious consequences. We lost some of our replicas as hosts were accidentally decommissioned.
- Existence of ‘pet’ hosts and manual hand-holding for the growing numbers of ‘pets’ led to high-impact incidents. One of our HDFS NameNode migrations led to an incident impacting the entire batch analytics stack.
We took into consideration the learnings from previous experience during the re-architecture.
Architecture
As we started designing the new system, we adhered to the following set of principles:
- Changes to Hadoop core should be minimal, to avoid diverging from open source (e.g., Kerberos for security)
- Hadoop daemons must be containerized to enable immutable and repeatable deployments
- Cluster operations must be modeled using declarative concepts (instead of action-based imperative models)
- Any host in the cluster must be easily replaceable upon failure or degradation
- Uber internal infrastructure should be reused and leveraged as much as possible to avoid duplication
The following sections go into details about some of the key solutions that define the new architecture.
Cluster Management
We had reached a point where provisioning hosts and operating clusters using imperative, action-based scripts were no longer viable. Given the stateful (HDFS) and batch nature (YARN) of workloads, and the customization required for deployment operations, we decided to onboard Hadoop to Uber’s internal stateful cluster management system.
Several loosely coupled components, built based on common frameworks and libraries, enable the Cluster Management system to operate Hadoop. The diagram below represents a simplified version of the current architecture that we have today. The components in yellow depict the core Cluster Management system, whereas those marked in green represent the custom components built specifically for Hadoop.

Cluster Admins interact with the Cluster Manager Interface web console to trigger operations on clusters. The intent gets propagated to the Cluster Manager service, which then triggers Cadence workflows that mutate the cluster Goal State.
The Cluster Management system maintains pre-provisioned hosts, referred to as Managed Hosts. A Node represents a set of Docker containers deployed on a Managed Host. Goal State defines the entire topology of the cluster including Node placement information (host location), cluster-to-Node attribution, definition of Node resources (CPU, memory, disks), and its environment variables. A persistent datastore stores the Goal State, allowing fast recovery from unprecedented failures of the Cluster Management system.
We rely heavily on Cadence, an open-source solution developed by Uber, to orchestrate state changes on the cluster. Cadence workflows are responsible for all operations, whether it is adding or decommissioning Nodes, or upgrading containers across the fleet. The Hadoop Manager component defines all of the workflows.
The Cluster Manager does not know the internal operations of Hadoop and the intricacies around managing Hadoop infrastructure. Hadoop Manager implements custom logic (analogous to K8s Custom Operator) to manage Hadoop clusters and models workflows in a safe manner within Hadoop’s operational bounds. For example, all of our HDFS clusters have two NameNodes. Guardrails, such as not restarting both of them at the same time, go into the Hadoop Manager component.
Hadoop Worker is the first agent that is started on every Node allocated to Hadoop. All Nodes in the system are registered with SPIRE, an open-source identity management and workload attestation system. Hadoop Worker component authenticates with SPIRE upon container start, and receives an SVID (X.509 Certificate). Hadoop Worker uses this to communicate to other services for fetching other configurations and secrets (such as Kerberos keytabs).
Hadoop Container represents any Hadoop component that runs within a Docker container. In our architecture, all Hadoop components (HDFS NameNode, HDFS DataNode, etc.) are deployed as Docker containers.
Hadoop Worker periodically fetches the Node’s Goal State from the Cluster Manager and executes actions locally on the Node to achieve the Goal State (a control loop, a concept that is also core to K8s). The state would define the Hadoop Container to be started, stopped, or decommissioned, among other settings. On Nodes that run HDFS NameNode and YARN ResourceManager, Hadoop Worker is responsible for updating the ‘hosts files’ (e.g., dfs.hosts and dfs.hosts.exclude). These files indicate the DataNodes/NodeManager hosts that need to be included or excluded from the cluster. Hadoop Worker is also responsible for reporting the Actual State (or current state) of the Node back to the Cluster Manager. The Cluster Manager makes use of Actual State in conjunction with Goal State as it launches new Cadence workflows, to converge the clusters to the defined Goal State.
Host issues are continuously detected by a system that is well integrated with the Cluster Manager. Cluster Manager makes intelligent decisions, such as rate-limiting to avoid decommissioning too many bad hosts concurrently. Hadoop Manager ensures that the cluster is healthy across different system variables before taking any action. The checks included in Hadoop Manager ensure that there are no missing or under-replicated blocks in the clusters, and that data is balanced between DataNodes, among other checks, before running critical operations.
With the declarative model of operations (using Goal State), we reduced manual involvement in operating clusters. A great example of this is where bad hosts are automatically detected and decommissioned safely out of the cluster for repairs. The system keeps the cluster capacity constant (as defined in the Goal State) by adding a new host for every bad host taken out.
The following graph shows the number of HDFS DataNodes being decommissioned at any point of time within a week’s time period due to different issues. Each color depicts a different HDFS cluster.

Containerized Hadoop
We have had multiple situations in the past, where the mutable nature of our infrastructure caught us by surprise. With the new architecture, we run all Hadoop components (NodeManagers, DataNodes, etc) and YARN applications inside immutable Docker containers.
When we started the effort, we were running Hadoop v2.8 for HDFS and v2.6 for YARN clusters in production. Docker support for YARN in v2.6 was non-existent. Upgrading YARN to v3.x (for better Docker support) was a huge undertaking, given tight dependencies on v2.x by different systems (Hive, Spark, etc.) that depended on YARN. We ultimately upgraded YARN to v2.9, which supports Docker container runtime, and backported several patches from v3.1 (YARN-5366, YARN-5534).
YARN NodeManagers run within Docker containers on the hosts. The host Docker socket is mounted to the NodeManager container to enable users’ application containers to be launched as sibling containers. This bypasses all the complexity that would have been introduced by running Docker-in-Docker, and enables us to manage the lifecycle of YARN NodeManager containers (such as restarts) without affecting customer applications.

To facilitate seamless migration of over 150,000+ applications from bare-metal JVMs (DefaultLinuxContainerRuntime) to Docker containers (DockerLinuxContainerRuntime), we added patches to support a default Docker image when NodeManager launches applications. This image contains all dependencies (python, numpy, scipy, etc) that make the environment look exactly like the bare-metal host.
Pulling Docker images during application container start time incurs additional overhead that could lead to timeouts. To circumvent this problem, we distribute Docker images through Kraken, an open-source peer-to-peer Docker registry originally developed within Uber. We further optimized the setup, by pre-fetching the default application Docker image while starting the NodeManager container. This ensures that the default application Docker image is available before requests come in, for launching application containers.
All Hadoop Containers (DataNodes, NodeManagers) use volume mounts for storing data (YARN application logs, HDFS blocks, etc). These volumes are provisioned when the Node is placed on the Managed Host and deleted 24 hours after decommissioning of the Node from the host.
We gradually flipped apps to be launched using the default Docker image, during the course of migration. We also have a handful of customers who use custom Docker images that enable them to bring their own dependencies. By containerizing Hadoop, we reduced variability and chances of errors through immutable deployments, and also provided a better experience for customers.
Kerberos Integration
All our Hadoop clusters are secured through Kerberos. Every node that is part of the cluster requires host specific service principals (identities) registered in Kerberos (dn/hdfs-dn-host-1.example.com). A corresponding keytab needs to be generated and shipped securely to the node before any Hadoop daemon is launched.
Uber uses SPIRE for workload attestation. SPIRE implements SPIFFE specs. SPIFFE ID in the form of spiffe://example.com/some-service are used to represent workloads. This is typically agnostic to the hostname where the service is deployed.
It was obvious that both SPIFFE and Kerberos are their own distinct authentication protocols, with different semantics around identities and workload attestation. Re-wiring the entire security model in Hadoop to work with SPIRE was not a viable solution. We decided to leverage both SPIRE and Kerberos without any interaction/cross-attestation with each other.
This simplified our technical solution, which involves the following sequence of automated steps. We ‘trust’ the Cluster Manager and the Goal State operations it performs for adding/deleting Nodes from a cluster.

- Use placement information (Goal State) to get all Nodes from cluster topology.
- Register corresponding principals for all Nodes into Kerberos and generate corresponding keytabs.
- Persist keytabs in Hashicorp Vault. Set up appropriate ACLs so that it can be read only by Hadoop Worker.
- Cluster Manager Agent fetches the Goal State for the Node and launches the Hadoop Worker.
- Hadoop Worker gets attested by SPIRE Agent.
- Hadoop Worker:
a. Fetches the keytab (generated in step 2)
b. Writes it to a read-only mount readable by the Hadoop Container
c. Launches the Hadoop Container
7. Hadoop Container (DataNode, NodeManager, etc.):
a. Reads keytab from the mount
b. Authenticates with Kerberos before joining the cluster.
Typically human involvement leads to mismanagement of keytabs, undermining the security of the system. With this setup, the Hadoop Workers are authenticated by SPIRE and the Hadoop Containers are authenticated by Kerberos. The entire process described above is automated end-to-end with no manual involvement, ensuring tighter security.
UserGroups Management
In YARN, the containers of the distributed applications run as the users (or service accounts) who submit the application. UserGroups are managed within Active Directory (AD). Our old architecture involved installing periodic snapshots of UserGroups definitions (generated from AD) through Debian packages. This gave way to inconsistencies across the fleet, arising from package version differences and installation failures.
Undetected inconsistencies lasted anywhere between hours and weeks, until impacting users. In the past 4+ years, we experienced several issues arising from permission issues and application launch failures due to inconsistent UserGroups information across hosts. Additionally, this led to a lot of manual effort for debugging and remediation.
UserGroups management for YARN within Docker containers comes with its own set of technical challenges. Maintaining yet another daemon, SSSD (as suggested in Apache docs), would have added more overhead on the team. Since we were re-architecting the entire deployment model, we spent additional effort in designing and building a stable system for UserGroups management.

Our design involved leveraging a reputable Config Distribution System that’s been hardened in house to relay UserGroups definition to all the hosts where YARN NodeManager containers are deployed. The NodeManager container runs the UserGroups Process, which observes changes to UserGroups definition (within Config Distribution System) and writes it to a volume mount shared as read-only with all Application Containers.
Application Containers use a custom NSS library (developed in house and installed within Docker image) that looks up UserGroups definition files. With this solution we were able to achieve fleet-wide consistency for UserGroups within 2 minutes, thereby significantly improving reliability for our customers.
Config Generation
We operate 40+ clusters serving different use cases. With the old system, we were managing configurations for each of the clusters independently (one directory per cluster), in a single Git repository. Copy-pasting configurations and managing rollouts across multiple clusters became unmanageable.
With the new system we revamped the way we manage cluster configurations. The system leveraged the following 3 concepts:
- Jinja templates for .xml and .properties files, agnostic to clusters
- Starlark generation of configs for different classes/types of clusters before deployment
- Runtime environment variable (disk mounts, JVM settings, etc.) injection during deployment of Nodes

We reduced 200+ .xml config files with a combined total of 66,000+ lines to ~4,500 lines in template and Starlark files (93%+ reduction in line count). This new setup has proven to be more readable and manageable for the team, especially due to its better integration with the cluster management system. Moreover, the system was proven beneficial for automatically generating client configs for other dependent services in the batch analytics stack such as Presto.
Discovery & Routing
Historically, moving Hadoop control planes (NameNode and ResourceManager) to different hosts has been troublesome. These migrations typically result in rolling restarts of the entire Hadoop cluster and coordination with many customer teams to restart dependent services, as clients use hostnames to discover these nodes. To make things worse, certain clients tend to cache host IPs and do not re-resolve them on failure—we learned this the hard way from a major incident that degraded the entire regional batch analytics stack.
Uber’s microservices and online storage systems heavily depend on the internally developed service mesh for discovery and routing. Hadoop support with service mesh is way behind other Apache projects, like Apache Kafka. The use cases of Hadoop and the complexity involved to integrate it with internal service mesh did not justify the ROI for the engineering effort. Instead, we chose to leverage DNS-based solutions, and plan to contribute these changes incrementally back to open source (HDFS-14118, HDFS-15785).
We have 100+ teams that interact with Hadoop on a daily basis. A majority of them are using outdated clients and configs. To improve developer productivity and user experience, we are standardizing Hadoop clients across the company. As part of this effort, we are migrating to a centralized configuration management solution where customers do not have to specify the typical *-site.xml files for initializing clients.
Leveraging the same config generation system described above, we are able to generate the configuration for clients and push the configuration to our in-house Config Distribution System. The Config Distribution System rolls them out fleet-wide in a controlled and safe manner. The Hadoop Client used by services/applications would fetch configurations from a host local Config Cache.
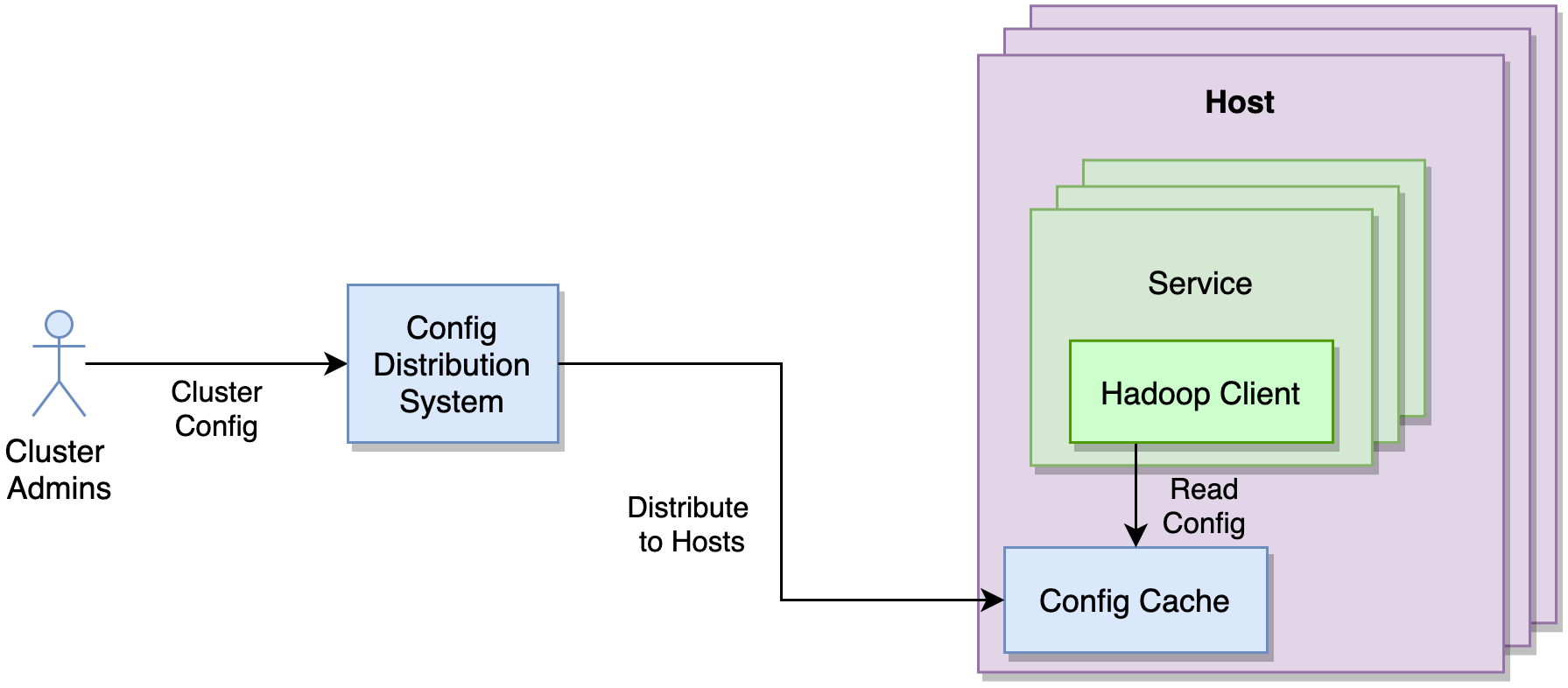
The standardized clients (with DNS support) and centralized configuration completely abstracts away the discovery and routing from Hadoop customers. Additionally, it provides a rich set of observability metrics and logging, which enables easier debugging. This further improves the experience for our customers, and makes it easy for us to manage Hadoop control planes without disrupting customer applications.
A Shift in Mindset
Since Hadoop was first deployed in production in 2016, we have developed several (100+) loosely coupled python and bash scripts to operate clusters. Re-architecting the automation stack of Hadoop meant rewriting all this logic. The effort meant reimplementing 4+ years worth of logic keeping in mind scalability and maintainability of the system.
A large overhaul for 21,000+ Hadoop hosts to move to containerized deployment and losing operability through years’ worth of scripts, came along with initial skepticism. We started using the system for new dev-grade clusters with no SLAs and then for integration testing. A few months later, we started adding DataNodes and NodeManagers to our main clusters (used for data warehouse and analytics) and gradually built confidence.
After a series of internal demos and well written runbooks empowering others to use the new system, the team was sold on the benefits of moving to containerized deployment. Moreover, the new architecture unlocked certain primitives (for efficiency and security), which the old system could not support. The team started embracing the benefits of the new architecture. Soon enough, we bridged several components between the old and new systems to materialize a migration path from the existing system to the new system.
Moving the Mammoth
One of our principles with the new architecture is that every single host in the fleet must be replaceable. The mutable hosts managed by the old architecture had accumulated years’ worth of tech debt (stale files and configs). We decided to reimage every host in our fleet as part of the migration.
Currently, automated workflows orchestrate the migration with minimal human involvement. At a high level, our migration workflow is a series of Cadence activities iterating through sizable batches of Nodes. The activities perform various checks to ensure that the cluster is stable, intelligently pick and decommission Nodes, provision them with new configurations, and add them back into the cluster.
The initial estimate to finish the migration was north of 2 years. We spent a considerable amount of time tuning our clusters to find a sweet spot where the migration progresses fast enough and at the same time does not hurt our SLAs. Within 9 months, we managed to migrate ~60% (12,500/21,000 hosts). We are on a strong trajectory to finish the majority of fleet migration over the course of next 6 months.

Scars to Remember
We would be lying if we claim that our migration was peaceful. The initial phase of the migration was pretty smooth. However, we uncovered unexpected issues as we started migrating clusters, which were more sensitive to changes.
- Losing Blocks & Adding More Guardrails
One of our largest clusters had multiple operational workflows executing concurrently. A cluster-wide DataNode upgrade in conjunction with migration happening on another part of the cluster triggered degradation in NameNode RPC latencies. A series of unexpected events later, we lost the battle and ended up with missing blocks in the cluster that we had to restore from another region. This forced us to put in more guardrails and safety mechanisms for automation and operational procedures.
2. Disk Usage Accounting with Directory Walk
The Cluster Manager Agent performs periodic disk usage accounting for usage analysis, feeding into company-wide efficiency initiatives. Unfortunately, the logic meant a ‘walk’ through all the HDFS blocks stored on 24 x 4TB disks on DataNodes. This contributed to a considerable amount of disk i/o. It did not affect our less busy clusters. However, this negatively impacted one of our busiest clusters, driving up HDFS client read/write latencies, which led us to enhance the logic.
Key Takeaways & Future Work
Over the course of the last 2 years, we have made monumental changes to the way we operate Hadoop. From a hodgepodge of scripts and Puppet manifests, we upleveled our deployment to run large-scale Hadoop production clusters in Docker containers.
Transitioning from scripts and tools to operating Hadoop through a full-fledged UI was a major cultural shift for the team. Time spent on cluster operations dropped by over 90%. We let automation take control over fleet-wide operations and replacement of bad hosts. We no longer let Hadoop manage our time.
Following are the key takeaways for us from our journey:
- Hadoop can turn into a mammoth to tame without advanced operational excellence. Reassess deployment architecture periodically and pay down technical debt at a regular cadence before it is too late.
- Large scale infrastructure re-architecture takes time. Build a strong engineering team, focus on progress over perfection, and always expect things to go wrong in production.
- Our architecture was solid, thanks to all the engineers who pitched in across different Infra teams. Collaborate with people outside of the Hadoop domain to gather different perspectives.
As we watch migrations progress towards completion, we are shifting our focus to do more exciting work. Leveraging the benefits from underlying container orchestration, we have the following planned for the future:
- Single-click multi-cluster turn up and cluster balancing across multiple zones within a region
- Automated solutions for proactively detecting and remediating service degradations and failures
- Provide on-demand elastic storage and compute resources by bridging cloud and on-premise capacity
If you are daring enough to take up these technical challenges and tame the mammoth, consider joining our team:
Senior Software Engineer – Data Analytics Storage & Compute
Tech Lead – Data Analytics Storage and Compute
Acknowledgements
The work portrayed in this article was only possible due to consistent effort from engineers across several Uber Infrastructure teams. We would like to thank everyone who has supported us through our journey, and also everyone who reviewed and assisted in improving this article.
Matt Mathew
Sr Staff Engineer
Matt is a Sr. Staff Engineer on the Engineering Security team at Uber. He currently works on various projects in the security domain. Previously, he led the initiative to containerize and automate Data infrastructure at Uber.
Shuyi Zhang
Shuyi Zhang is an Engineering Manager at Uber leading OpenSearch adoption and development at Uber and innovations in open source. She’s also a member of the Observability technical advisory group under the OpenSearch project.
Qifan Shi
Qifan is a Senior Software Engineer with the Data Infrastructure team at Uber, and a core contributor for Hadoop containerization. He has been working on multiple systems that effectively orchestrates large-scale HDFS clusters.
Jackie Murchison