CheckEnv: Fast Detection of RPC Calls Between Environments Powered by Graphs
13 September 2023 / Global
Uber consists of a large number of loosely coupled microservices that interact with each other through remote procedure calls (RPCs). These RPC calls serve as the communication mechanism between services, allowing them to exchange data and invoke specific actions. The complex nature of the call chain, combined with the involvement of numerous services, can potentially lead to cross-environment communication, particularly between the production and non-production environments.
The intricate call chain arises due to the distributed nature of microservices, where each service performs a specific function and may depend on the outputs of other services. As data flows through the system, it traverses multiple services, triggering RPC calls at each step. The complex call chain may involve numerous services, each initiating calls to other services based on their specific requirements.
This complexity becomes a critical factor when environments such as production and staging coexist. If not carefully managed, RPC calls within the microservices architecture can inadvertently cross environment boundaries, leading to unintended interactions between the production and staging environments. Such cross-environment calls can have undesirable consequences, including data inconsistencies, unexpected behavior, or potential incidents. It is worth noting that while cross-environment calls are permissible, for example, shadowing production traffic in staging for feature validation, the focus is on preventing unintended ones.
To mitigate these risks, proper design, configuration, and deployment practices should be followed. Implementing service isolation and environment-specific configurations is essential to restrict RPC calls within their respective environments, minimizing the chances of unintended cross-environment interactions. Furthermore, establishing robust governance and testing processes, including comprehensive integration and regression testing, can proactively identify and resolve issues arising from the complex call chain.
In addition to preventive measures, it is important to have a fast detection mechanism in place for cross-environment RPC calls. This mechanism should enable prompt identification of any such calls, allowing for swift resolution before they escalate into serious incidents. By promptly detecting and addressing these cross-environment RPC calls, potential risks can be mitigated, ensuring the overall stability and reliability of the microservices architecture.
This mechanism can be applied to various use cases, such as during the load test process. To minimize the side effect of this, the load test can leverage this detection system to identify the path a call will take and alert stakeholders with an opportunity to address such interactions beforehand and ensure that the load testing process is executed without unintended effects on the production environment.
Similarly, other test scenarios like integration testing and shadow testing could use this detection mechanism as well and require manual acknowledgment before execution. Proactive scanning using this mechanism that generates daily reports can easily identify any suspicious activity related to cross-environment traffic.
In this blog, we want to share how we built CheckEnv, which leverages graphs to detect cross-environment RPC calls. By harnessing the power of graphs, we have developed an innovative approach to efficiently identify and analyze the intricate call chains within our microservices architecture. This enables us to proactively detect any cross-environment RPC calls and take timely actions to prevent potential risks and ensure the integrity of our production and non-production environments. Join us as we explore the benefits and implementation details of CheckEnv.
Exploring the Data
Service-to-service calls can be effectively represented as a dependency graph. Within Uber, multiple sources store comprehensive data on service-to-service RPC calls, including essential metrics and traces. Leveraging this rich dataset, we gain valuable insights into the dependencies and communication patterns between services, enabling us to visualize the intricate call paths.
The service dependency graph serves as a foundational tool for visualizing the call paths between services. It outlines the dependencies, both direct and indirect, and provides a holistic view of the communication flow within the microservices architecture. By augmenting this graph with environment metadata, such as production and staging identifiers, we can effectively pinpoint cross-environment RPC calls for a given service. See the red lines in the following graph:

To facilitate efficient cross-environment RPC detection, we employ advanced graph analysis techniques and algorithms. These algorithms can traverse the service dependency graph, correlating the call paths with environment metadata to identify any cross-environment RPC calls. By automating this process and integrating it into our monitoring and alerting systems, we ensure swift detection and proactive resolution of any cross-environment communication issues.
Dependency Graph Types
CheckEnv incorporates two types of dependency graphs: real-time and aggregated.
The real-time dependency graph is generated through continuous monitoring and analysis of RPC calls in real time. We construct a precise and dynamic visualization of the service interconnections by capturing essential metrics such as the origin and destination of RPC calls, service and endpoint names, and environment information. This real-time graph allows us to stay updated on the current state of service dependencies and identify any potential issues or bottlenecks. The above Figure 1 is an example of this graph type.
In addition to the real-time graph, we recognize the significance of an aggregated dependency graph in understanding the historical changes of services within our microservices architecture. The aggregated graph takes into account the evolution of service dependencies over time by incorporating a time frame node into its structure. By capturing the dependencies present during specific time intervals, we gain insights into the changes and trends in service interactions. This aggregated graph provides a comprehensive view of the service interactions history, facilitating analysis of the impact of changes on system performance and the detection of any cross-environment RPC calls across time. See the following graph as an example:

In the upcoming sections, we will delve into the implementation details of both the real-time and aggregated dependency graphs within CheckEnv. By examining the implementation process, we aim to provide a comprehensive understanding of how these graphs were developed and integrated into the CheckEnv application.
Architecture Overview
At a high level, CheckEnv is built on top of two Uber graph data storage systems:
- Grail aggregates the current state of Uber infrastructure into a single global view, spanning all zones and regions and serving as the graph model. Its data includes the current call graphs.
- Local Graph platform is the storage and serving layer for the aggregated call graph data collected from Grail. Local Graph provides a generic ingestion framework that enables users to ingest their data into the graph. The ingestion process uses Apache Spark™ underneath to read data from Apache Hive™ and transform it into triples which eventually form the graph structure. On the serving side, Local Graph View is used to explore call graph data with low latency.
Grail Data
Grail has various data source providers, including real-time RPC calls data, which serves as the resource for constructing real-time dependency graphs. By leveraging Grail, we can access the relationship between services and their dependencies based on the environment by executing a single query like the following:

We can gain a comprehensive understanding of the relationship between a service node and its dependencies using grail queries. This data, continuously ingested into Hive, serves as a major data provider to Local Graph for constructing the aggregated dependency graph.
Local Graph Data
Local Graph is used as the storage for storing the aggregated call graph data from Grail. It provides a generic ingestion framework that enables users to ingest their data into the graph. The ingestion process uses Apache Spark and Spark SQL underneath to read data from Hive and transform it into a graph structure. Local Graph’s view layer is highly performant for serving the graph data.
Let’s look at an example Hive table we have for the call graph data:
| datestr | caller | callee | caller_env |
| 2023-05-25 | Service A | Service B | production |
| 2023-05-25 | Service C | Service B | staging |
| … | … | … | … |
Local Graph Data uses a Triple Data Model to store entities, relationships between them, along with properties for each entity. With this data model, everything can be modeled using Subject, Predicate, and Object.
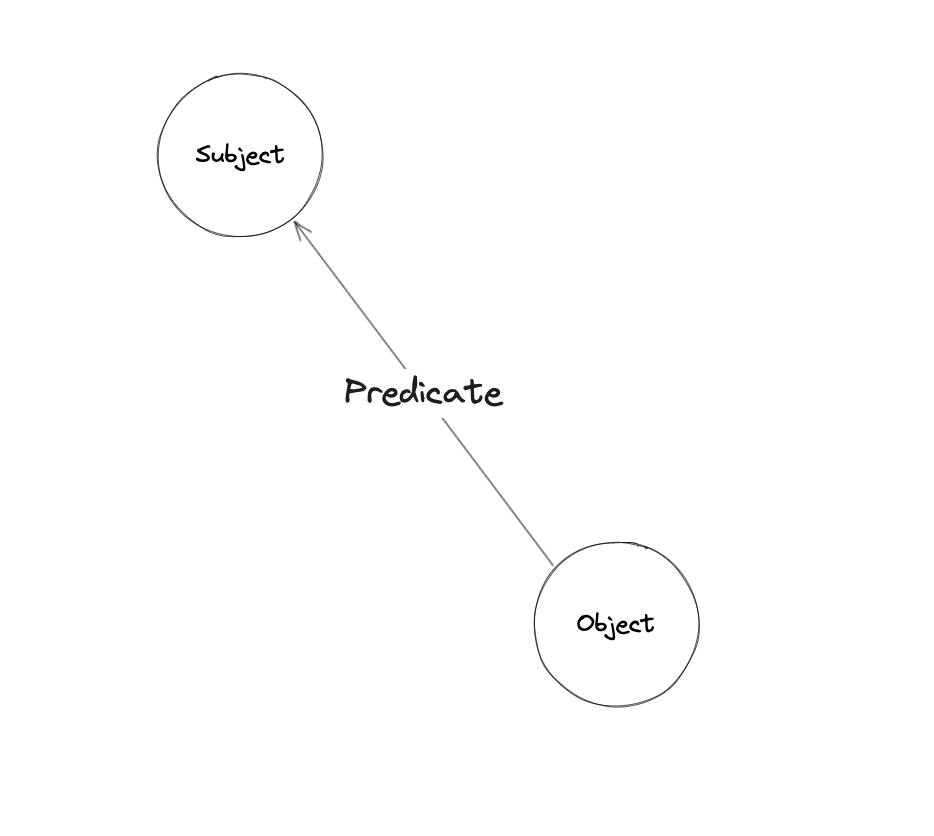
The graph node relationship is stored as the above triple model. For example, a service-to-service RPC call can be represented as:

Properties can store node-related information. In this case, each node stores the node metadata such as service_name, caller_env, etc.
By looking at the Hive table and the triple model, it becomes evident that a row can be directly converted into a triple representation. Once the data is ingested into Local Graph as triples, we can immediately start using Local Graph View layer to read graph hops and implement any custom graph traversal logic. The view layer provides RPC procedures to explore the ingested graph data. With Local Graph traversal API, we can traverse the graph as we want and collect properties as needed.
CheckEnv Architecture
The following is the high-level architecture for CheckEnv:

Essentially, CheckEnv leverages the power of dependency graph data from Local Graph to facilitate its functionalities. As an application built upon dependency graphs, CheckEnv provides a set of APIs that enable users to access and retrieve valuable information, such as:
- ListAllDependencies – retrieves a comprehensive list of all the dependencies for a service, including indirect dependencies
- ListPathsToProdDependencies – identifies and lists the paths leading to production dependencies
By exposing these APIs, CheckEnv empowers users to efficiently access and utilize the dependency graph data for various purposes, including anomaly detection, troubleshooting, and optimization within their microservices architecture.
The entire data ingestion pipeline that is responsible for constructing the graphs within CheckEnv is referred to as MazeX in the above diagram. MazeX plays a crucial role in collecting, processing, and transforming the data required for building the graphs. By leveraging MazeX, CheckEnv is equipped with a reliable and efficient mechanism for consuming the necessary data. This pipeline ensures that the graphs in CheckEnv are continuously updated and accurately represent the interdependencies within the microservices architecture.
Within the MazeX pipeline, the g-to-h bridge component takes on the responsibility of continuously collecting Grail data and persistently storing it in a Hive table. Another scheduled daily data ingestion job is implemented to process the Hive data and perform the necessary transformations to convert the Hive data into Local Graph triples. You can find below an example of a dependency graph in Local Graph–a center node makes RPC calls to other nodes:

Figure 7: Graph in Local Graph
Use Case at Uber
Ballast, Uber’s synthetic load testing platform, is the first consumer of CheckEnv. When users initiate a load test, Ballast asks CheckEnv to detect potential cross-environment calls specifically for that load test. Ballast requests CheckEnv to analyze the call chains and promptly notifies users if any suspicious call chains are identified. This proactive warning system ensures that users are alerted to any potential issues related to cross-environment calls before running a load test, enabling them to take appropriate measures and mitigate any risks that may arise. By leveraging the capabilities of CheckEnv, Ballast enhances the overall load-testing process by providing valuable insights and alerts to users, promoting a more secure and reliable testing environment.
What’s Next
CheckEnv serves as an example of how the MazeX graph data ingestion pipeline can be applied to address real-world challenges. As we envision the future, our objective is to expand MazeX data ingestion capabilities and construct a significantly more powerful graph. By incorporating a broader range of relevant data sources into our system, we aim to enhance the richness and depth of information available for graph construction. This expanded dataset will empower us to capture a more comprehensive understanding of the microservices landscape to further improve the reliability and efficiency of our products.
Our next focus will be on addressing the RPC calls efficiency problem by analyzing communication patterns and relationships between services. This analysis will enable us to optimize data flow, resulting in the improved overall efficiency of services as a group.
By adopting a graph-based approach, we can represent intricate relationships and dependencies in a well-organized and understandable way. This empowers us to extract valuable insights and make informed decisions. Graphs provide a robust framework to effectively tackle complex challenges within a microservice architecture, including real-time fault detection, incident prediction, service health anomaly detection, community detection for efficiency improvement, and workflow management. With this approach, we can efficiently address these issues while maintaining clarity and efficiency.
Apache®, Apache Spark™, Spark™, Apache Hive™, Hive™, and the corresponding logos are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.

Minglei Wang
Minglei Wang is a Staff Software Engineer on the Maps Production Engineering team at Uber. He works on reliability and efficiency initiatives across multiple organizations and platforms. He is currently leading the load testing initiative across the company.

Kamyar Arbabifard
Kamyar Arbabifard is Senior Software Engineer on the Local Graph Platform team at Uber. He has been focusing on building and expanding Local Graph’s onboarding capabilities to help teams across Uber onboard their use cases quickly using a SQL query and defining the mapping logic to build a graph.
Posted by Minglei Wang, Kamyar Arbabifard
Related articles


Most popular
Terms and Conditions: HK Seasonal Travel Campaign

Migrating Large-Scale Interactive Compute Workloads to Kubernetes Without Disruption

Building Uber’s Multi-Cloud Secrets Management Platform to Enhance Security
