How Uber Achieves Operational Excellence in the Data Quality Experience
Uber delivers efficient and reliable transportation across the global marketplace, which is powered by hundreds of services, machine learning models, and tens of thousands of datasets. While growing rapidly, we’re also committed to maintaining data quality, as it can greatly impact business operations and decisions. Without data quality guarantees, downstream service computation or machine learning model performance quickly degrade, which requires a lot of laborious manual efforts to investigate and backfill poor data. In the worst cases, degradations could go unnoticed, silently resulting in inconsistent behaviors.
This led us to build a consolidated data quality platform (UDQ), with the purpose of monitoring, automatically detecting, and handling data quality issues. With the goal of building and achieving data quality standards across Uber, we have supported over 2,000 critical datasets on this platform, and detected around 90% of data quality incidents. In this blog, we describe how we created data quality standards at Uber and built the integrated workflow to achieve operational excellence.
Case Study
As a data-driven company, Uber makes every business decision based on large-scale data collected from the marketplace. For example, the surge multiplier for a trip is calculated by real-time machine learning models based on a bunch of factors: regions, weather, events, etc. The two most decisive factors, however, are demand and supply data in the current area. If supply data is higher than demand, the surge multiplier will approach its minimal value (1.0), and vice versa.
The supply and demand datasets are ingested through real-time data pipelines, consuming events collected in the Mobile App. Any system-level issue (pipeline lagging, app publishing failure, etc.) that causes data to be incomplete or inaccurate will then lead to an inaccurately-calculated surge multiplier, and impact the marketplace with reduced trip count. It’s super important to catch such data quality incidents proactively, before the data is consumed downstream, to avoid driver earnings loss.
To address quality issues for large-scale datasets, the most straightforward solution is predefining a list of validation rules (tests), then periodically executing the tests and determining whether data quality is within SLA or not. For the supply dataset, we can predefine the tests below, based on our domain knowledge. The system will execute each test with configured frequency, and trigger alerts if any test fails.
| Description | Mocked Queries | Mocked Assertion |
| Daily supply data count should be no less than 10,000 | SELECT COUNT(*) FROM supply WHERE datestr = CURRENT_DATE; | query_value > 10,000 |
| Supply data count should be consistent week over week | SELECT COUNT(*) FROM supply WHERE datestr = CURRENT_DATE; | ABS(query0_value – query1_value) / query1_value < 1% |
| SELECT COUNT(*) FROM supply WHERE datestr = DATE_ADD(‘day’, -7, CURRENT_DATE); |
Our data quality platform is built upon this solution as a foundation. However, to make it scalable to thousands of tables and deliver operational excellence, we have to consider and address the following limitations:
- There is no standard data quality measurement defined across different teams
- Creating tests for a dataset requires a lot of manual effort; it’s even more difficult to onboard a set of tables together as a batch
- Besides data quality tests, we also need standard and automated ways to create alerts, but avoid false positive incidents being triggered to users
- When a real incident is detected, it’s not sufficient to just notify users through alerts—we need a better incident management process to guarantee all detected issues are finally resolved, with minimized human efforts
- To measure performance of the platform, we need a clear definition of success criteria, and an easy approach to compute those metrics
- As a company-scale platform, it should be integrated with other data platforms to deliver a centralized experience for all data producers and consumers at Uber with correct, documented, and easily-discoverable data
Data Quality Standardization
To set up a baseline for Uber’s data quality, we have collected feedback from data producers/consumers, and analyzed all major data incidents in the past few years. Some common issues include: data arrives late after being consumed, data has missing or duplicated entries, discrepancies between different data centers, or entry values are incorrect. As a summary, we defined the following test categories to cover all quality aspects of a dataset:
- Freshness: the delay after which data is 99.9% complete
- Completeness: the row completeness percentage, computed by comparing this dataset to one of its upstream datasets
- Duplicates: the percentage of rows that have duplicate primary keys
- Cross-datacenter Consistency: the percentage of data loss by comparing a copy of this dataset in the current datacenter with the copy in the other datacenter
- Others: this category may contain any test with semantic checks or more complicated checks based on business logic
For each test category, we have expanded the definition to one or more tests measuring quality with different formulas:
| Category | Prerequisite | Test formula |
| Freshness | Completeness metric is available | current_ts – latest_ts where data is 99.9% complete < freshnessSLA |
| Completeness | Upstream and downstream datasets are 1:1 mapped | downstream_row_count / upstream_row_count > completenessSLA |
| Offline job to ingest sampled upstream data to Hive | sampled_row_count_in_hive / total_sampled_row_count > completenessSLA | |
| Duplicates | Primary key provided by data producers | 1 – primary_key_count / total_row_count < duplicatesSLA |
| Cross-datacenter Consistency | N/A | min(row_count, row_count_other_dc) / row_count > consistencySLA |
| Offline job to calculate Bloom-Filter value for sampled data in both DCs | intersection(primary_key_count, primary_key_count_other_dc) / primary_key_count > consistencySLA | |
| Others | N/A | User-generated custom tests. No standard formula. |
Data Quality Platform Architecture
At a high level, the data quality architecture contains the following components: Test Execution Engine, Test Generator, Alert Generator, Incident Manager, Metric Reporter and Consumption Tools. The core test execution engine executes onboarded tests with cadence or upon requests by interacting with different query engines, evaluating based on assertions, and saving results to the database; all the rest components are built upon the engine and cover the whole lifecycle of data quality evolvement, including onboarding, alerting, triaging, and adoption at Uber.

Test Generator
Our entry point for operational excellence in the data quality experience is streamlining the process for onboarding tests with minimal user input. Test Generator is designed to auto-generate the standard tests defined above, based on datasets’ metadata. We are leveraging Uber’s centralized metadata service as the source of truth, which fetches data from Metadata stores of different storages, as well as maintains user inputs for some metadata fields. Here are some highlighted fields required during quality test auto-generation:
- SLAs: SLAs are used as thresholds as part of assertion. All datasets at Uber are categorized with tiering levels (Tier 0 being the highest to Tier 5 being the lowest), which we use as criteria to define default SLA values, following Uber’s business requirements.
- Partition Keys: For large tables that are incrementally produced, we only test the latest partition in each execution based on partition keys, as periodically running executions will cover the whole table. Partition keys are fetched from metadata for each sink, e.g. Apache Hive™ Metadata Store for Hive tables, index template for Elasticsearch® tables, etc.
- Schedule time: For tables that are tested per partition, the tests should be executed after the partition is completely produced to avoid false positives. We leverage the freshness SLA to determine expected partition completeness, thus a test for a partition will be scheduled after the period of freshness SLA.
- Primary Keys: Primary keys are required for some test types. This is the only parameter that requires users’ input. We will skip those test types for tables missing primary keys, and send out weekly reports to remind users setting them up in metadata service.
Besides data quality monitoring for a single table, users also care about the quality for its upstream and downstream tables, so they can investigate if detected quality issues are caused by upstream tables, and notify all downstream tables that might be impacted. With that in mind, we also support auto-generating tests for all upstream and downstream tables, leveraging Uber’s lineage service. This has significantly improved onboarding efficiency, as well as providing an overall high-quality view of the entire lineage.
However, lineage data is dynamic since ETL jobs’ logic may change, and tables can be created or deprecated over time. To produce the most accurate data quality results, we created a daily cron Apache Spark™ job to fetch the latest lineage for all source tables that users have onboarded, and then prune and off-board obsolete tables that have been removed from the lineage. The daily job also refreshes all auto-generated test definitions to reflect any metadata change, and accordingly updates the logic of the test generation process.

To further improve Uber’s data quality standardization, we committed to 100% test coverage for top-tiered datasets. This can be achieved by either a push or pull model. We developed both approaches to guarantee timely updates, as well as to prevent data loss in the push model:
- A push model that consumes metadata changes (tier upgraded/downgraded, SLA updated, etc.) and update data quality tests in real-time
- A pull model to fetch latest top tiered tables and their metadata and update data quality tests in batches
Test Execution Engine
The test execution engine is a Celery-based web service that currently supports approximately 100,000 daily executions of about 18,000 tests. Tests can be auto-generated on standard metrics as mentioned above or defined by users on custom metrics. Each test is defined by an assertion that must be true in order for the test to pass. For example, a duplicates/uniqueness test asserts that the percentage of duplicate records in a dataset is less than or equal to .01 (or whatever number is permitted by the dataset’s SLA).
The tests themselves can be reduced to a few basic, logical assertions, the most basic being comparing a computed value with a constant number (like percentage_duplicates <= .01). Another type of assertion is comparing one computed value with another computed value. All of our standard data quality tests are defined by one of these two simple assertion patterns, though the computation step ranges in complexity (we expand on this in Compound Test Types below).
The assertion pattern is used to construct the test expression, which is a string of symbols representing instructions that can be interpreted by the execution engine. The string itself is a flattened Abstract Syntax Tree (AST) that contains both sub-expressions and parameters to configure and control the execution. At execution time, the expression is parsed into a tree and evaluated in a post-order traversal. Every test on the platform can be expressed as an AST and is ultimately processed by the execution engine in this fashion.

The test-expression model is valuable because it allows the execution engine to handle a potentially limitless number of assertions. In this way, it provides us great flexibility in terms of adding new types of tests with limited overhead, especially tests with increasing complexity.
Compound Test Types
Compound test types are test types that require additional computation steps before they can be evaluated as an AST. The additional computation requires running a job or pipeline that collects data and saves it to be used later in the final AST-based evaluation. Both our cross-datacenter consistency (lightweight and bloom filter-based) and upstream-downstream tests are compound test types.
Bloom Filter Cross-Datacenter Test
One type of cross-datacenter test makes use of a Bloom filter. Bloom filter is a probabilistic data structure that is used to perform membership checks from a set. In every daily run for a dataset, Bloom filters are built for a daily partition of that dataset in its datacenter, Datacenter A. The Bloom filter is then copied over to the other datacenter, Datacenter B, and it is being used to check every record and determine whether it is a member of the set in Datacenter A. This check is also done in reverse — building a Bloom filter in Datacenter B and using it in Datacenter A. The “building” of the Bloom filter and “use” of the Bloom filter are implemented as Hive UDFs. The build_bloom_filter UDF is an aggregate UDF that returns the string serialization of the Bloom filter and use_bloom_filter returns “exists” if the record is found in the Bloom filter or the record itself otherwise. A record in this case is a string that is used as the Bloom filter’s key. It can be a unique identifier of the row or a concatenation of multiple columns (i.e. a comma-separated list of values from multiple columns).
One limitation of Bloom Filter is that false positives are possible, which happens when filters in other datacenters incorrectly identify files as existing where they in fact do not. However, the advantage of this test type is that it can identify the missing record. Having the exact record that is missing is especially helpful for identifying the exact cause of the data loss. There are pros and cons for each test type, and so a combination of tests can help us determine the particular data quality issues at play.
Lightweight Cross-Datacenter Test
The lightweight cross-datacenter test was developed as a less expensive alternative to the bloom filter-based cross-datacenter test, in both time and compute resources required. While the bloom filter-based test compares the content between two datasets, the lightweight cross-datacenter test simply compares an aggregate characteristic of the datasets. Our standardized lightweight cross-datacenter test compares the row count between datacenters and ensures that the difference is below a particular threshold. Running a row count query is significantly more efficient than building bloom filters and comparing them, returning in just a few seconds for many datasets.
We implemented the lightweight cross-datacenter test by defining it in terms of two expressions: one tells the execution engine to run the row count query and save the result to our MySQL database; the other tells the execution engine to retrieve the stored results and compare them. The first expression is executed in both datacenters while the second expression is only executed once and creates the final test result.
Sampling Test
The sampling test is a completeness test that randomly collects samples from an upstream dataset and verifies if the data exists in the downstream dataset. This methodology is designed to be used for upstream datasets that are outside of Apache Hadoop®, such as Schemaless. For every test run, a number of samples are pulled from the upstream datasets and they are being stored and ETL into a Hive table. These samples are then used to check if they made it to the corresponding downstream dataset.
Alert Generator
Similar to data quality tests, alerts can also be auto-generated following templates and business rules. Some extra parameters are needed, such as table owners, alert email and keys, which are also accessible in Metadata service. We create data quality alerts per dataset per test category, as shown in data quality architecture, based on stats generated by the test execution engine. The ultimate goal is 100% alert coverage for top-tiered datasets, which can be generated in the same test onboarding process; however more work is needed here to prevent false alerts and maintain a consistently good user experience.
The first question that comes up is: does each failed test execution result indicate a real data quality incident? Consider a test monitoring a dataset produced in real time, which validates the trip count on an hourly basis. Is it possible the test transiently failed only once at 1am, as in the below diagram? To avoid triggering too many such transient alerts, we introduced a sustain period indicating the table SLA that allows for test failures. In the same example, the sustain period is set as 4 hours, so the platform will set status as WARN until the test failures violate the sustain period. At 8am, test status is triaged to FAIL and the alert is triggered for this real data quality incident.
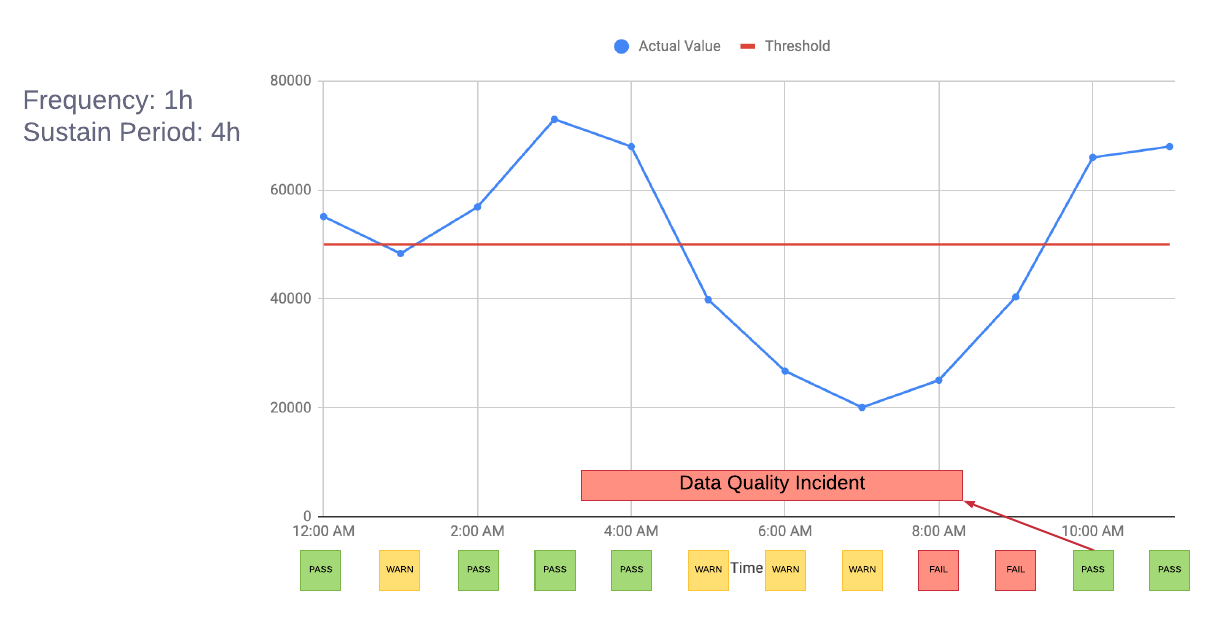
Even for real alerts, we should limit the unnecessary alert count to avoid overwhelming users. One possible case is duplicated alerts, when data is known as not fresh: the Freshness alert will trigger for sure, which also indicates that the latest partition is not complete. In that case Completeness and Cross-datacenter Consistency alerts are very likely to be triggered at the same time, caused by the same data latency issue. Our strategy is setting the Freshness alert as dependency of other categories by default, so other alerts will be suppressed to avoid duplicated notifications about the same root cause. Another improvement is the gradual onboarding process: we set proper grace periods before enabling actual alerts, to give users plenty of time for investigating and fixing known quality issues in their datasets.
Incident Manager
Incident Manager is another critical component in the architecture to improve the experience of triaging alerts. In this section, we will describe how we built the system and tools to help users manage received data quality alerts.
After users have received an alert, investigated the root cause and mitigated the quality issue, how should we resolve that alert? Shall we ask users to notify our platform that the corresponding incidents have been resolved? The answer is no because a) it involves unnecessary user’s efforts to resolve each alert; b) we need a more reliable way to identify different incident stages. To address this, we added an internal scheduler to automatically rerun failed tests with exponential backoff. Thus we can validate whether the incident has been resolved successfully if the same test passed again, and resolve the alert automatically without any user input. Furthermore, it can eliminate transient alerts, since some tests might be auto-resolved before it triggers alerts, such as failures caused by data lagging.
Besides auto rerun scheduler, we also developed a tool for users to manually annotate an incident and trigger a rerun. The tool can be used in several scenarios:
- When users want to resolve an alert immediately, instead of waiting for next scheduled rerun
- For false positives, such as wrong test configuration, the same test will never pass again through rerunning, so users can leverage this tool to force resolve an alert
- Even for true alerts, we still encourage users to annotate critical incidents with recovery ETA, root cause, backfill status, etc, so data consumers will have the same context, and data producers can track historical incidents with annotated details for further analysis
However, we cannot guarantee that all potential incidents will be detected, no matter how intelligently the tests are designed. Through the same tool, users can also report any incident they’ve discovered when consuming the data. The data quality platform will check if it overlaps with any detected incidents, and notify data producers to acknowledge reported incidents. As a result, we will aggregate both auto-detected and user-reported incidents so the final data quality status can cover all quality-related factors. The whole incident-management workflow is as follows:

Metric Reporter
Based on data collected by the incident management workflow, we can define and calculate the success metric for our data quality platform through Metric Reporter. We cannot simply use the number of detected incidents to measure success, as a higher number might be caused by false alerts, and a lower number might be caused by real incidents avoiding detection. Instead we choose Precision and Recall as combined metrics, which are calculated by:
Precision = TP / (TP + FP)
Recall = TP / (TP + FN)
- TP: Duration of true positive incidents, detected by the platform and able to be auto-resolved through rerun
- FP: Duration of false positive incidents, detected by the platform, but force-resolved by users
- FN: Duration of false negative incidents, reported by users, but which are not detected by the platform
Different from Precision and Recall measuring the data quality platform, we also defined another two metrics to measure the overall quality of onboarded datasets:
- Data level quality score: Duration of real incidents / duration of total time range
- Query level quality score: Number of failed queries / number of total queries, where failed queries are issued when there are ongoing incidents, and the data range specified in the query overlaps with the incidents involved data ranges
Consumption Tools
The data quality platform at Uber also provides a variety of different tools to assist users in understanding their datasets’ quality and prevent them from consuming bad data.
Dashboard
Databook is the centralized dashboard that manages and surfaces metadata for all datasets at Uber. It’s the most commonly used tool for both data producers and consumers to check table definition, owners, metadata and stats over time. Thus we integrated our platform with Databook to show data quality results in the UI. The quality is aggregated to category level, then overall table level, which means any failed test will fail in the corresponding category, and the overall status.

Query Runner
Uber has a Query Runner tool for quick and safe access to any data storage, including Hive, MySQL, Postgres, etc. This is the gateway to all Uber’s datasets, thus the appropriate place to integrate with the data quality platform and return quality status for any incoming query. Data quality API takes the queried dataset name and time range as requests, and verifies if the query time range overlaps with any ongoing data incidents or not. Based on the integration results, users can decide to continue using query results or to hold off until any reported incidents are resolved.
ETL Manager
The ETL Manager is the controller for all data pipelines at Uber. There are multiple stages in which the data quality platform can be leveraged here:
- When a data pipeline has successfully finished, ETL Manager can call data quality platform to trigger a new test execution immediately and ensure fast detection
- Before a data pipeline is scheduled, ETL Manager can consume data quality results for all its input datasets; if the quality of any didn’t meet SLA, ETL Manager can suspend the pipeline to avoid bad data being ingested to downstream datasets
Metric Platform
Beyond datasets ingested in different storages, Uber has a metric platform that defines consolidated business metrics definitions, and then calculates and serves metrics by aggregating data from raw datasets. We have close interaction with the metric platform, by defining specific standard tests for metrics, as well as providing metric-level quality through the metric platform query layer.
Besides the above Uber-wide data tools, the data quality platform is also integrated with multiple other internal clients across different teams. For example, data quality coupled with an experimentation library to block experimentation jobs if leveraged datasets have known quality incidents detected. This has resulted in widespread adoption of data quality standards throughout the company, and further ensured operational excellence, as data quality is now more consistent throughout the company.
Moving Forward
We are working on the next chapter of the data quality platform to expand the impact and supported test cases. Some major features we are developing are:
- Backtesting: The current platform starts monitoring data quality only after a dataset has been onboarded; we are building a new functionality to test historical data with current test definitions
- Anomaly Detection: Most standard tests are benchmarking metrics against a peer dataset, but by introducing more tests based on anomaly detection, we will cover more incidents, such as data trend outliers
- Dimension/Column level tests: In many cases, users are more interested in dimension or column level data quality (e.g., whether data is good in San Francisco, or whether there’s semantic error in a specific column), so we plan to create tests in the dimension or column level, to support more accurate and granular data quality results.
If you’re interested in exploring data quality and how it applies to Uber’s standardized metrics, or developing similar highly cross-functional platforms with impact at scale, consider applying for a role on our team!
Apache®, Apache Hive™, Apache Spark™ and Apache Hadoop® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Postgres, PostgreSQL and the Slonik Logo are trademarks or registered trademarks of the PostgreSQL Community Association of Canada, and used with their permission.
Maggie Ying
Maggie Ying is an Engineering Manager for the Uber For Business’s Employee Products team. She previously was the Tech Lead for the Data Quality team. She was the pioneer of Data Quality at Uber by introducing the first self-serve data assertion platform that was used across the company.
Wei Yan
Wei Yan is a Senior Software Engineer on the Marketplace Data Foundation team. She is a main contributor for the Data Quality Platform.
Ying Zou
Ying Zou is the Engineering Manager for the uMetric Computation team at Uber. She was previously the Engineering Manager for the Marketplace Data Foundation team. She led the data quality standardization based on existing solutions and promoted the platform to Uber-scale.
Sanjay Sundaresan
Sanjay Sundaresan is a former Senior Staff Engineer for the Batch Storage Infra team. He led the HiveSync and Cloud Migration teams at Uber.
Isabel Geracioti
Isabel Geracioti is a former Software Engineer on the Metadata Platform team under Data Platform at Uber. She worked on metadata-based projects including data quality and lineage.
Sriharsha Chintalapani
Sriharsha Chintalapani is a Senior Staff Software Engineer and the Tech Lead for Data Platforms at Uber. The Data Quality Platform provides quality checks and alerts to our Data Assets (tables, metrics) at Uber.