Turning Metadata Into Insights with Databook
Every day in over 10,000 cities around the world, millions of people rely on Uber to travel, order food, and ship cargo. Our apps and services are available in over 69 countries and run 24 hours a day. At our global scale, these activities generate large amounts of logging & operational data that runs through our systems in real-time. This includes information about consumer demand, driver-partner availability, and other operational tasks such as payments, notifications, and more. Operating a complex marketplace such as ours requires our engineers, data scientists, data analysts, and operations managers to take real-time business decisions based on trends observed on our platform.
To help our teams easily discover and understand this data better, we built Databook. This is Uber’s in-house platform which surfaces and manages the metadata related to various data entities such as datasets, internal dashboards, business metrics, and more.
As Uber expanded, our systems became more technically complex and the breadth of our data systems grew exponentially. Similarly, our teams’ needs became more complex as well, as they now relied even more on datasets, dashboards, and business metrics to make business decisions on a global scale.
Databook was unable to scale to meet these new needs, prompting us to rethink our assumptions and rebuild our tools to better support our users and their evolving needs. Here we describe how we evolved our approach to simplifying data discovery and fluency, and the lessons that we learned along the way.
The evolution of Databook
We originally launched Databook in 2016, when Uber’s data was much less distributed and complex. It was enough to maintain a set of static HTML files, which we manually updated at regular intervals. These files simply listed the internal locations and owners of datasets at Uber.
As our data stores grew in size, teams began classifying the data. They also gathered metadata about how we generated the data, which pipelines loaded it into our data storage systems, brief descriptions of the dataset and the columns in each table. All of this metadata about our business helped people discover and comprehend the data itself. It therefore accelerated the use of insights in our decision-making and could improve Uber’s products. So, in 2017, we launched the first version of Databook, which addressed these immediate needs with a responsive and easy-to-navigate user interface.
Since then, Uber expanded to hundreds of cities around the world, and grew its offerings to include food delivery, cargo transportation, self-driving vehicles and other business units. This significantly changed our data landscape, in terms of both volume and system complexity.
Our engineers, data scientists, data analysts, and operations managers struggled to keep up and regularly turned to Databook, which was the first step on every exploration of our data. What we envisioned, namely a basic system for searching data sets and surfacing descriptions and owners, was no longer enough.
After we analyzed usage patterns and conducted extensive user research, we learned that Databook’s users wanted to understand associated data assets as well as the data itself. For example, many people wanted to know which pipelines loaded data into which tables, which business metrics we derived from these tables, and which dashboards displayed these metrics. Teams also wanted to understand other aspects of a data entity, such as its quality, how often we used it, and whether we could readily use it in high-impact applications such as machine learning.
Building on Databook to meet these new needs became increasingly difficult. As we considered support for entity types other than just datasets, we realized that our existing technology was slowing us down. It forced us to build an inferior solution that did not serve the needs of our users. With this in mind, we rethought our approach to metadata management and discovery and we redesigned Databook from the ground up.
The industry also worked to improve the productivity of data scientists and data analysts with metadata to power data insights. Other companies that have large and distributed datasets faced similar challenges and built innovative data catalogs to tackle similar problems in the context of their unique business requirements and technology. Examples include Airbnb’s Dataportal, Netflix’s Metacat, Linkedin’s Datahub, Lyft’s Amundsen, and Spotify’s Lexikon, among others.
Principles for rebuilding Databook’s architecture
Having run Databook for several years, we understood the needs and expectations of our customers. The back-end service limited our ability to quickly and effectively include metadata for non-datasets such as business metrics and dashboards.
By engaging with our teams, we defined guiding principles that were the foundation for our redesign and re-architecture:
- The meaning of metadata is important
As the variety of data entities increased, we lost the purpose of the metadata that we added to Databook due to lack of proper documentation and ownership. To provide meaningful, structured, and well-managed metadata, we established metadata management through a Data Standardization process with Dragon, a schema generation tool. It established a standard vocabulary for metadata which promoted consistency and reusability of metadata types across all of Uber.
- Truly extensible data model
The original Databook focused on datasets and the data model stored metadata associated specifically with datasets. Forcing all data entities to fit into a single model challenged and prevented us from expressing the metadata in a clear and understandable way. For example, a dataset entity has metadata on the columns of a table but a dashboard entity does not have columns. By having a more flexible and extensible data model, we could define each data entity with its specific metadata, rather than having to fit into a predefined data model.
- Centralized versus decentralized metadata system
We spread metadata across multiple systems. In a prior attempt to unify metadata systems, Databook sent requests directly to these systems for external metadata it did not store in it’s own storage.
As we began building the search and discovery infrastructure, we also needed to index this external metadata. In addition, the number of different metadata systems increased and their use cases were similar. Namely we wanted to store metadata on data entities.
Relying on different metadata systems resulted in no centralized view and duplicated effort. Having a centralized metadata store created a unified place for metadata on data entities. So other services no longer duplicated the effort of creating the same purpose metadata stores. Without an effective centralized metadata management system, we could also mishandle data and it would become untrustworthy and undiscovered.
- Focus on the user experience
From the UI to the back-end APIs, we encouraged users to explore our metadata system. We stressed the importance of making our APIs explorative and easy to use. For teams producing metadata, we have standardized the process to contribute and ingest different data entities. This increased the efficiency of adding a variety of metadata. Now our metadata consumers can discover metadata through the Databook UI or APIs. The focus on user experience makes the effort of metadata producers and consumers simple and convenient.
- Importance of relationships between data entities
One of the many ways data flows in Uber is from a Kafka topic to a Hive table through Hadoop data ingestion. In the original Databook with dataset entities, we captured this relationship between datasets. This provided insights into how the datasets were in their current state and where the data came from.
As we increased the variety of data entities, the relationship between different data entities became even more complex. This included machine learning features that depended on multiple datasets and dashboards with different business metrics.
A Graph data structure is the most natural way to represent these relationships. The knowledge graph of data entities provides great flexibility and extensibility. It does so by enabling our system to capture the relationships between these data entities. It also answers questions about the most important metadata relationship that were challenging or even impossible before.

This figure shows many varieties of data entities captured in Databook and the number continues to grow. A dashboard can depend on multiple datasets and a report may have multiple business metrics to query. A team can manage or own various data entities such as dataset, business metric, dashboard, pipelines, and more.
These guiding principles address the core values of Databook based on our experience with managing metadata. These guidelines influence our design decision in the new Databook architecture that is extensible, reliable, and scalable to the needs of Uber’s big data system.
Databook Architecture
From these principles, the Databook architecture needs:
- A controlled metadata vocabulary,
- A truly extensible data model that can ingest various metadata and metadata relationships,
- A good user experience
In addition, we must support different requirements for querying the metadata on various data entities.
Databook Components
To power data discovery for data services and products, Databook ingests millions of data entities from data storage systems and services. The design and architecture of Databook is key to address the volume of metadata in a big data ecosystem and meet user requirements.

Databook has several components:
- Metadata Sources – metadata about data entities. Databook gets this from various sources. This includes data storage systems, such as Hive and Cassandra as well as services, logs, and more.
- Metadata Ingestion – a process to ingest metadata from various sources to Databook.
- API – for metadata retrieval and modification of data through a graph engine. This also captures changes in the Metadata Event Log.
- Persistent Storage – contains complete records of all data entities and relationships.
- Metadata Event Log – all changes in Databook are in the event log. We use the events to build derived storages. This meets other use cases such as search and caching. In other cases, additional services subscribe to these changes. They then build event-driven systems to meet their requirements such as notifications or triggering workflows.
- Derived Storages – storages that can efficiently support different data use cases and requirements. Teams can build and rebuild tooling from the Metadata Event Log. In addition, we can extend the Databook API to retrieve metadata directly from these derived sources.
Databook is a data-intensive application that captures large amounts of various metadata across Uber. We have different data storages to handle different use cases. A single-system data storage that can handle all access patterns and demands efficiently is unrealistic. This is because different data storage systems address specific goals, ranging from low-latency data retrieval to flexible data analytics.
Databook supports the goals we want to achieve, from flexibility in ingesting various data entities to supporting robust data discovery that powers other data products. Next, we’ll take a look at how data modeling can help in achieving those goals.
Data Model
Having a flexible model helps us address the different types of entities we collect in Uber. For example, between a Dataset entity and a Metric entity, there is common and uncommon metadata. Therefore, we cannot force Metric to have the same data model as Dataset.
Extensibility is at the core of Databook it helps us to quickly and effectively add new metadata. With a standard data entity onboarding process we can all contribute metadata that are reusable and understandable.
To register a new data entity or update the model for an existing data entity, we use a data model transformation tool called Dragon. This helps us define the data schema for each entity type. Domain experts can submit definitions, and after a central committee of experts approves the proposed schema, Databook generates the data model.
Beyond the data model, we also share the corresponding Thrift, Protobuf, and Avro across Uber. This provides a managed vocabulary of metadata that is consistent and reusable. We also review all updates in this schema and make sure they are backward-compatible.
Based on the metadata type someone defines, Databook creates the flexible data model. Given the Dragon schema, we can create a specific data model for each entity. We have two categories of data:
- Entity types – these are record types with a uniquely identifying field. In Databook, we consider all record types with an ID field an entity. Dataset, HiveTable, and Dashboard are examples of entity types.
- Value types – these keep definitions consistent and reusable. Entity types can reuse existing value types. TableName, DataCenterRegion, and ColumnType are examples of value types.

We represent metadata as a set of properties and relationships because the model is flexible and can easily evolve over time. Databook uses MySQL as the persistent storage for the following reasons:
- Flexible and extensible model – we store data as a schema-less JSON collection that continuously evolves with new metadata. It also supports indexing, transactions, referential integrity, and other MySQL features.
- Highly available – we can access data across geographical regions with replication and active/active setup.
- Familiar
- SQL is standard and most people are familiar with using it. This makes it easier for engineers to contribute, debug, and test.
- We can access many resources and help from external forums and internal experts such as our dedicated team supporting MySQL.
- Many open-source tools for MySQL such as data visualization tools to slow query analytics.
- Mature – MySQL is proven to be operational at scale for many years.
Using MySQL as the primary persistent database helps Databook support various entity types in a way that is scalable and reliable. It also helps having support from both internal and external communities.
Relationships between data entities are important. We need to capture this to derive insights into the metadata related to each data entity. We can answer questions such as “how is a dashboard related to a business metric?” or “how does a pipeline transform a dataset?” Our data users want to know how data entities relate to one another. Having a graph to represent these relationships is a natural direction to take. With our flexible data model, we can translate the relationships between data entities into a graph shown below.

Having a data model that can support a variety of data entities from different metadata sources powers our metadata management system.
Metadata Sources
Information on data entities lives across many systems at Uber. These systems are sources of metadata that Databook can collect, index, and use for discovery. With different data entities from many metadata sources, Databook needs a flexible data model that can effectively handle various use cases.
The sources for metadata on data entities varies from data storage systems to other microservices. There are crawlers that periodically scan through each system for information and ingest data into Databook. This includes indexing Cassandra tables and collecting dataset level statistics. We also have event-based sources such as data freshness and quality checks. Each source requires that Databook have a robust interface.

Databook gets metadata from various sources to provide a central view of Uber’s data ecosystem. The metadata sources range from OLTP and OLAP databases to data entities within other services such as dashboards and machine learning features. To scale with the number of metadata sources, we standardized the ingestion process and Databook APIs.
Data Ingestion API
Metadata sources are across many teams and organizations at Uber. Our colleagues have different needs and use cases to integrate with Databook and do data discovery.
Databook provides a simple process for ingesting metadata on data entities. With Metadata Ingestion, metadata sources push metadata to a Kafka topic and then Databook processes them. We recommend the ingestion process, though depending on urgency and requirements, the APIs can also do synchronous writes, such as displaying an update in the UI.

Databook ingests metadata in a streamlined manner and is less error-prone. Once Databook ingests the metadata, it pushes information which details the changes to the Metadata Event Log for auditing and serving other important requirements.
Event Log
Once Databook ingests the metadata, we add all changes to the Metadata Event Log on Kafka. The event log records all metadata changes in the application, in sequential order, which makes it readily available to consume.

We leverage our log-oriented architecture to enable the following:
- Support different query requirements. The log of changes helps us to build additional storages for specific use cases. This includes graph-based analytics to time-series data since no single storage system can efficiently support every query pattern.
- Rebuilding storage. If we have issues with a storage system, we can rebuild it through the event log or re-apply changes from a certain point in time.
- Support event-driven architecture. Microservices can rely on the event log to trigger tasks such as the notification system, triggering data quality checks, and more.
- Audit changes. The data in a current point in time may not be enough. We may want to determine how a certain data entity reached its current state.
The Metadata Event Log provides essential information into Databook activity. It also provides extensibility to meet the numerous requirements of a centralized metadata management system for data discovery.
Search and Discovery
With Metadata Event Log, Databook supports search and discovery on data entities which reflects changes in near real-time. Databook collects metadata on data entities such as Datasets, Business Metrics, Dashboards, Pipelines, and more. As a result, Databook supports discovery in other data products such as:
- Databook UI,
- Internal tools that provide front-end functionality for Uber’s databases, such as Querybuilder, and
- State-of-the-art visualization tools, such as Dashbuilder, and more.
With millions of data entities, users need to know what they are looking for with a proper search and discovery platform.
We build search indices in ElasticSearch by consuming events from the Metadata Event Log. This ensures all changes in the user search results are in near real-time. In this approach, we leverage the log-oriented architecture. This provides benefits such as rebuilding the search indices from any point in time of the log and effectively updating only when there is a change.

Search and discovery helps Databook users find the relevant data entities and decreases time spent looking for the right resource. Databook architecture meets the demand of our users and increases their productivity throughout their daily tasks.
Benefits of Databook 2.0 Architecture
After having the new Databook in production over 18 months, we saw excellent results from users who adopted the service for metadata management and discovery. The solution covers hundreds of thousands of datasets, millions of columns/fields, and hundreds of thousands of other data entities such as dashboards and pipelines.
In addition, other internal Uber tools use Databook’s metadata for data discovery and to enhance their products. With the new Databook we can rapidly onboard new entities in less than one hour. In the past, it took multiple weeks to implement and test new entities. The onboarding experience is now simpler and we are confident in the correctness of our work in serving our end users.
With Databook architecture, we have a metadata management platform that is truly extensible, scalable, and reliable. We ingest millions of data entities in the big data ecosystem and support the search and discovery in Uber’s data products. Having an extensible backend enables us to rethink the Databook UI. This would further improve our users’ journey in data discovery and insights.
Visualizing data relationships through Databook’s UI
The advancements to the technology stack underneath Databook position us well to deliver a much richer data discovery experience for users. It also helps us to stay true to our mission of turning data into knowledge.
Databook offers two primary ways to discover data:
- RPC and GraphQL APIs, or
- Through a web-based UI.
The API, which we discussed in previous sections, supports other data tooling at the company. This presents point-in-time information and insights to users, such as through our query engines, through workflow orchestration systems, and more. The web-based UI remains the primary way to interact with Databook, and thousands of users every week use it for data discovery.
Motivation
After we reworked Databook’s technical architecture, we focused on understanding how these advancements appeared in the UI. Our existing UI from 2017 helped teams discover datasets. However, it was not very extensible and users found it hard to discover additional data entities, such as metrics, dashboards, pipelines, and more. The front end components we used to build it were no longer supported. They were cumbersome to maintain, upgrade, and modify.
We wanted to ensure that our UIs matched the improvements made to our back-end, and remained easy to modify and upgrade. So we redesigned the frontend using modular, standard components that all other teams use at Uber. This frontend is built using Uber React Base Web components. This helped us develop quickly by reusing existing UI components previously built by other teams at Uber. These tools interface with a GraphQL server for effective data retrieval.
Having made the decision to rebuild Databook’s web UI, we came up with a few guiding principles:
- Access to the metadata in our systems continued through both the API and the web UI
- The API would remain as powerful, or more powerful, as the UI. We recommended that teams integrate with this API to surface rich metadata-driven insights in their own products
- Databook’s UI focused on surfacing insights that the majority of users find useful. We monitored API usage to identify new features to provide to a wider audience in the Databook UI
With these founding principles, we started our user research. We wanted to determine how we could restructure our UI to serve our mission of turning data into knowledge. The primary function of Databook is data discovery.
Previously, we handled only datasets – now our scope has expanded to include business metrics, dashboards, pipelines, and more. Our new architecture allows us to gather additional metadata about each of these data entities, and identify trends and relationships between them. Finally, we invested in data quality monitoring and anomaly detection. This is an area that our customers said they cared about. With this information, we designed the Databook experience around these pillars:
- Discover: Give users a powerful search experience that helps them perform complicated, multi-faceted searches, with enough filters to quickly sift through results. Add support for data entities like dashboards, business metrics, ML features, and more. This ensures that Databook becomes the single destination for search at Uber.
- Understand: Increase the number of signals about our data entities, however also ensure users can cut through the details. Help users synthesize recommendations, while they can still choose to see detail.
- Manage: As our data volumes grew, curating a small set of data entities was no longer possible. As we added new data entities to our repository, we needed a way to crowd-source useful information, such as descriptions. We also needed a way that creators could organize this information
Below, we describe how we approached each of these pillars, and illustrate what the refreshed experience looks like.
Discover
Data discovery was the main reason for users to frequent Databook. With this redesign, we wanted to make search and discovery of data entities easy. This includes datasets, metrics, dashboards, pipelines, and machine learning features.
Through user research and analyzing user patterns, we realized that about 75% of users returned to Databook regularly to view a fairly small set of data entities. These were often for the part of the organization they work in or are for popular data entities for the entire company.
To make the Databook UI more intuitive, we introduced curated data entities. These included popular entities at the company or one an organization recommended. We also automatically suggested data entities to people, based on their usage patterns, and they could bookmark these for quick access
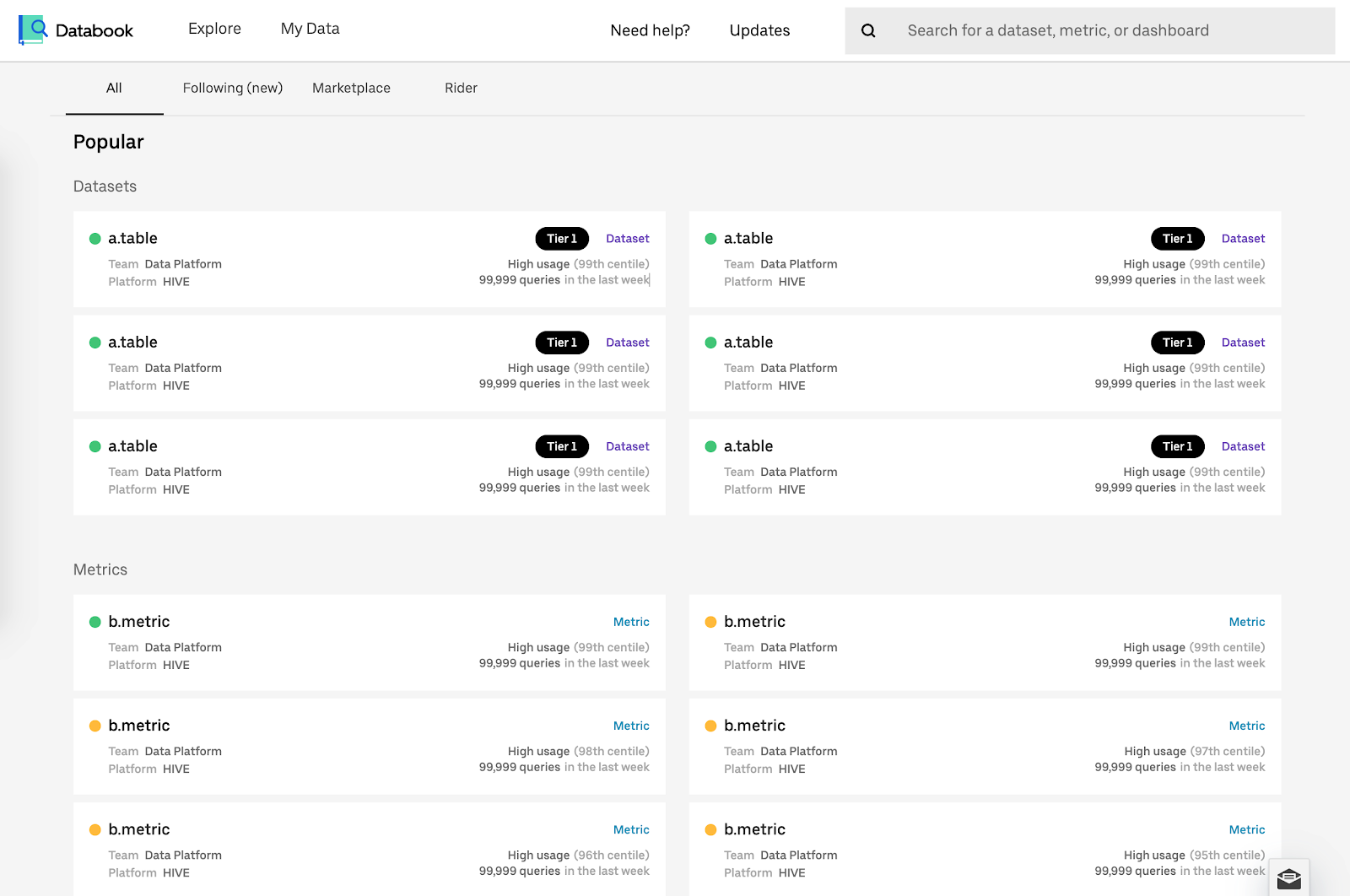
Databook aggregates metadata about each data entity. This can include ownership details, descriptions, usage statistics, quality information, and more. We invested heavily in our search to provide multifaceted and multidimensional search. This meant users can type in a series of related terms that we interpret to serve a list of relevant results, ranked intelligently. Users can also use filters to further narrow their list of results.
This improved everyday interactions that our users have had with our product for several years. We next focused on helping users understand each data asset, without having to visit several tools or rely on inaccurate or insufficient resources.
Understand
Helping users find what they’re looking for is the first step, however we wanted to also help them understand key details about data entities. We restructured Databook’s architecture so it could gather many more signals about data entities. This included relationships between entities, the data quality associated with an entity, usage statistics, samples, ownership & descriptions, as well as information about data privacy implications while using them.
As we redesigned the Databook UI, we determined which signals were most important, and how best to surface this information. To serve our broad user base, we now provide actionable recommendations at a glance, while users can easily find details. We introduced these features in a few different ways:
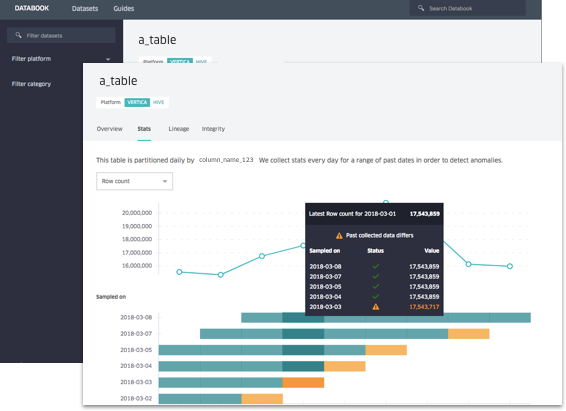
- We show data quality through a series of basic checks on each data entity and show this with a traffic-light-indicator. Users simply rely on traffic light signal colors that show if an asset is ready for use, possibly anomalous, or unsafe to use. We also provide the data we capture from each data quality test.
- We show trends about a data asset, such as usage. We also show characteristics about the data it contains, such as minimum, maximum, mean, median and null ratios are through trendlines.

With these new elements in the UI, from the homepage to individual detail pages for each data asset, users are no longer overwhelmed by these signals. They can rely on Databook to make informed decisions.
Manage
When we built Databook, we decided on a knowledge-base model instead of a wiki-based model. We did this so we could guarantee that people who owned data entities verified their information. This also meant that the signals we gathered from the metadata were reliable.
As we expanded the variety of data entities in Databook, and surfaced more signals about these entities, we wanted to make it easier for people to manage these entities. We also wanted to ensure that users could easily communicate with owners, ask questions, and provide feedback.

Data entity owners have a single view of all their entities. This helps them easily visualize asset quality, edit metadata, and view and respond to user issues or questions. Users can report issues or ask questions directly to data entity owners. By integrating with our existing ticketing system, we provide accountability, trackability and transparency for any issues. Behind the scenes, we deduplicate questions and route them to the appropriate team’s on-call.
By focusing our design process around the three main pillars, we built a world-class data catalog for Uber that will continue to evolve and grow with Uber.
Future plans
The current version of Databook includes a revamped, modular UI frontend as well as a flexible insight-generation architecture back end. It is our latest attempt at making data at Uber more useful through actionable insights. Every week, thousands of engineers, data scientists, data analysts, and operations managers turn to us to facilitate search, discovery, and perform a variety of actions. They use it to make sense of Uber’s metadata graph, which contains millions of data entities such as datasets, metrics, dashboards, ML features and more.
As the tool grew to index a wider variety of data, it’s success lay not in merely accessing the data, but also developing insights from the data. With our most recent additions, data at Uber are more readily discoverable and useful. This boosts the productivity of our engineers, data scientists, data analysts, and machine learning researchers.
Our work is far from complete. This year, we’re working on some fundamental challenges:
- Build intelligence around metadata
- Personalize experience for users
- Expand the knowledge graph
These are just some of the impactful additions we’re making to Databook. We will continue to expand its functionality through features that power discovery, exploration, and knowledge at scale.
Acknowledgments
Databook has been a labor of love that has spanned multiple Data teams over the course of the last two years. Several engineers, product managers, engineering leaders, UX designers, and technical writers have collaborated to build a product that truly serves the needs of our customers at Uber. Through this blog, we’re acknowledging the efforts of everyone that has worked on the Metadata Platform team over the years, and contributed to the continued success of Databook. We also want to highlight the support we’ve received from across Uber’s Data organization, as it has been instrumental in helping Databook simplify the data discovery journey.
Sunheng Taing
Sunheng Taing is a senior software engineer on Uber’s Metadata Platform team. He is passionate about building scalable, reliable, and high-quality data systems. Outside of Uber, he enjoys biking around San Francisco and checking out different food spots.
Atul Gupte
Atul Gupte is a former product manager on Uber's Product Platform team. At Uber, he drives product decisions to ensure our data science teams are able to achieve their full potential, by providing access to foundational infrastructure and advanced software to power Uber’s global business.