Using Machine Learning to Ensure the Capacity Safety of Individual Microservices
Reliability engineering teams at Uber build the tools, libraries, and infrastructure that enable engineers to operate our thousands of microservices reliably at scale. At its essence, reliability engineering boils down to actively preventing outages that affect the mean time between failures (MTBF).
As Uber’s global mobility platform grows, our global scale and complex network of microservice call patterns have made capacity requirements for individual services difficult to predict. When we’re unable to predict service-level capacity requirements, capacity-related outages can occur. Given the real-time nature of our operations, capacity-related outages (affecting microservices at the feature level as opposed to directly impacting user experiences) constitute a large chunk of Uber’s overall outages.
To help prevent these outages, our reliability engineers abide by a concept called capacity safety, in other words, the ability to support historical peaks or a 90-day forecast of concurrent riders-on-trip from a single data center without causing significant CPU, memory, and general resource starvation. On the Maps Reliability Engineering team, we built in-house machine learning tooling that forecasts core service metrics—requests per second, latency, and CPU usage—to provide an idea of how these metrics will change throughout the course of a week or month. Using these forecasts, teams can perform accurate capacity safety tests that capture the nuances of each microservice.
In this article, we define capacity safety at Uber and discuss how we leveraged machine learning to design our capacity safety forecasting tooling with a special emphasis on calculating a quality of reliability score, a measurement that allows load testing suites to programmatically decide whether to rely on the forecast or not.
Capacity safety at Uber
As part of our capacity safety measures, each microservice must be correctly provisioned such that it doesn’t experience downtime in every data center concurrently. Under-provisioning can lead to capacity shortage, while over-provisioning can cause network-related challenges (such as higher than required connections) to downstream or upstream services.
Historically, our reliability engineering teams conducted platform-wide drills to ensure the capacity safety of core trip-flow services. Engineers monitor core metrics when the designated amount of simulated trips hit the platform. Besides monitoring microservices close to the platform’s entry point, teams are also interested in understanding how the initial load and subsequent call patterns affect the performance of downstream microservices.
While this platform-wide approach solves the broader issue of capacity safety, it introduces numerous challenges, including the need to ensure both fidelity and a seamless developer experience. Fidelity is the notion that all critical services are tested in the same manner as they would be by natural traffic. Top-level microservices are tested thoroughly, but deep back-end microservices like mapping systems and payments services do not receive similar coverage. Additionally, in order to provide a controlled testing environment, platform-wide stress tests lock down the entire deployment system. As expected, this has a negative impact on the developer experience since it stalls ongoing builds and deployments.
To solve these issues, reliability engineers came up with a localized, automated, service-specific capacity safety test built on top of existing tooling that can be independently executed. This approach is more difficult, as the intricacies, patterns, and usage of each service must be taken into account. Moreover, in order to pass this test, we built in-house tooling to forecast core service metrics, thereby providing us with a better idea of whether or not our services will meet capacity safety requirements.
Designing a machine learning-supported architecture

At a high level, each service in production at Uber is instrumented to emit metrics, some of which are resource and capacity-related. These metrics are stored in M3 and can be queried via API. Our prediction system uses a service queries configuration file to determine which services require forecasting. Internal developers interested in using the system can onboard their service by specifying their service name, a core metric (for example, requests per second), and an hourly/daily interval for forecasting.
Like any machine learning task, forecasts require a significant amount of training data to be reasonably accurate. There must be enough data capturing the trend and seasonal patterns of a time series in order to make accurate predictions. Our service utilizes a collector that performs range queries on M3 and stores the data in an abstracted storage layer.
When a service is up for forecasting, its corresponding training data is retrieved from the storage layer. The data then goes through multiple levels of preprocessing so that anomalous events are removed. In the forecasting step, various statistical techniques are used to derive accurate predictions. Finally, the prediction is validated to determine how well the model performed on the training data.
The prediction system can be configured to run at periodic intervals throughout a given block of time. This enables the system to adapt to service-level changes and events dynamically. For example, if a service started experiencing an unusually high amount of requests, the system would take into account this new pattern and change the forecast accordingly.
After each collection and forecasting period, the results are stored in the storage layer. If the forecast changes because of aforementioned events, the stale forecasts are overwritten with the newer forecasts using priority queuing. Finally, service owners interested in using the forecasts for testing purposes can query the data through the API.
Data acquisition
The data we use, such as information on CPU and memory usage, comes from reliable sources, such as server logs, event logs, and data center reports, giving us a robust training set for forecasting. Given that the forecasting horizon directly correlates with the size of the training dataset, we decided not to limit the amount of data points collected. However, the default retention policy of M3 prevents us from obtaining enough data for forecasting. In most situations, time series data diminishes in value the older it gets, so more often than not, it is economical to drop older data. However, this “stale” data plays an important role in the prediction system as it enables the models to forecast further and further into the future. After all, the models can only capture long-term trends and seasonal patterns with datasets that cover those historical trends and seasons.

Because each range query to M3 only returns a limited amount of time series data points, we make successive queries to retrieve the entire dataset to accommodate our large fleet of servers, as depicted in Figure 2, above. However, since time series were periodically collected, we often noticed invalid data points at the beginning and end of each interval. This occurred due to an M3 design decision that pre-aggregates time series data as it comes in, then stores the output for future queries. When the collection interval is misaligned with the aggregation interval, there are no valid data points for the interval edges. To solve this problem, we introduced a buffer period at the beginning and end of each collection interval that is removed when stitching together data from consecutive collections. This feature enabled us to overwrite invalid data points while keeping the system compatible with M3’s aggregation policy.
The next step involved persisting the collected data to build a training dataset over time. Uber’s M3 team realized the increasing demand for longer retention and began to offer users an option to configure retention and aggregation policies for individual time series data.
Initially, we stored the time series data locally to facilitate rapid prototyping. We chose BoltDB, an open source embedded key-value store. BoltDB was a good choice for prototyping, but it was not sufficient for production, as the time series data could not be shared across multiple instances of the prediction system. Further, because the data was embedded, data was erased each time a new deployment occurred. As a result, we switched to DOSA, an open source storage solution we built on top of Apache Cassandra. DOSA was suitable for our needs as we were mostly conducting range queries based on timestamps, and did not need to perform complex relational queries. DOSA also solved our issues with BoltDB by providing a consistent view between instances and persisting across deployments.
Along with being persistent, we needed to keep the prediction system highly available, since it might encounter various kinds of failures during acquisition. To ensure fault tolerance, we run many instances of the prediction system across multiple data centers to guarantee at least one instance is running at any given time. In this scenario, data consistency is also an issue when concurrent collections occur. Since M3 pre-aggregates time series data, instances always query the same data, so no extra work needs to be done to maintain data consistency.
Data preprocessing
Before our system forecasts time series data, the historical dataset is preprocessed to remove outliers, anomalies, and other irregular variations that might affect our predictions. In particular, time series data retrieved from any service may contain time intervals where data center failovers occurred. Our current platform-wide capacity safety process requires data center failovers to occur. However, these time intervals must be removed from the dataset when systems in the “failed” data center show anomalous behavior.
The first step in preprocessing our time series data is identifying and removing time intervals that correspond to data center failovers. These intervals are easy to detect visually, as the traffic from one data center approaches zero while the traffic in another data center approaches twice its original load. However, automatically detecting data center failovers is a non-trivial task.

Because failovers have very specific characteristics with respect to the rest of a dataset, machine learning can be used to pick up on these characteristics as features. Unlike traditional classification tasks, our goal with capacity training is to classify anomalous intervals within a time series, making the training and prediction phases different depending on the training conditions.
The training phase consists of:
- Building rolling windows of k data points from the dataset
- Tagging each rolling window with “failover” or “no failover” based on curated data
- Extracting numerous time series features from each failover window
The prediction phase consists of:
- Building rolling windows of k data points from the dataset
- Using the trained model to classify each rolling window as “failover” or “no failover”
- Merging overlapping or side-by-side intervals tagged as “failover”
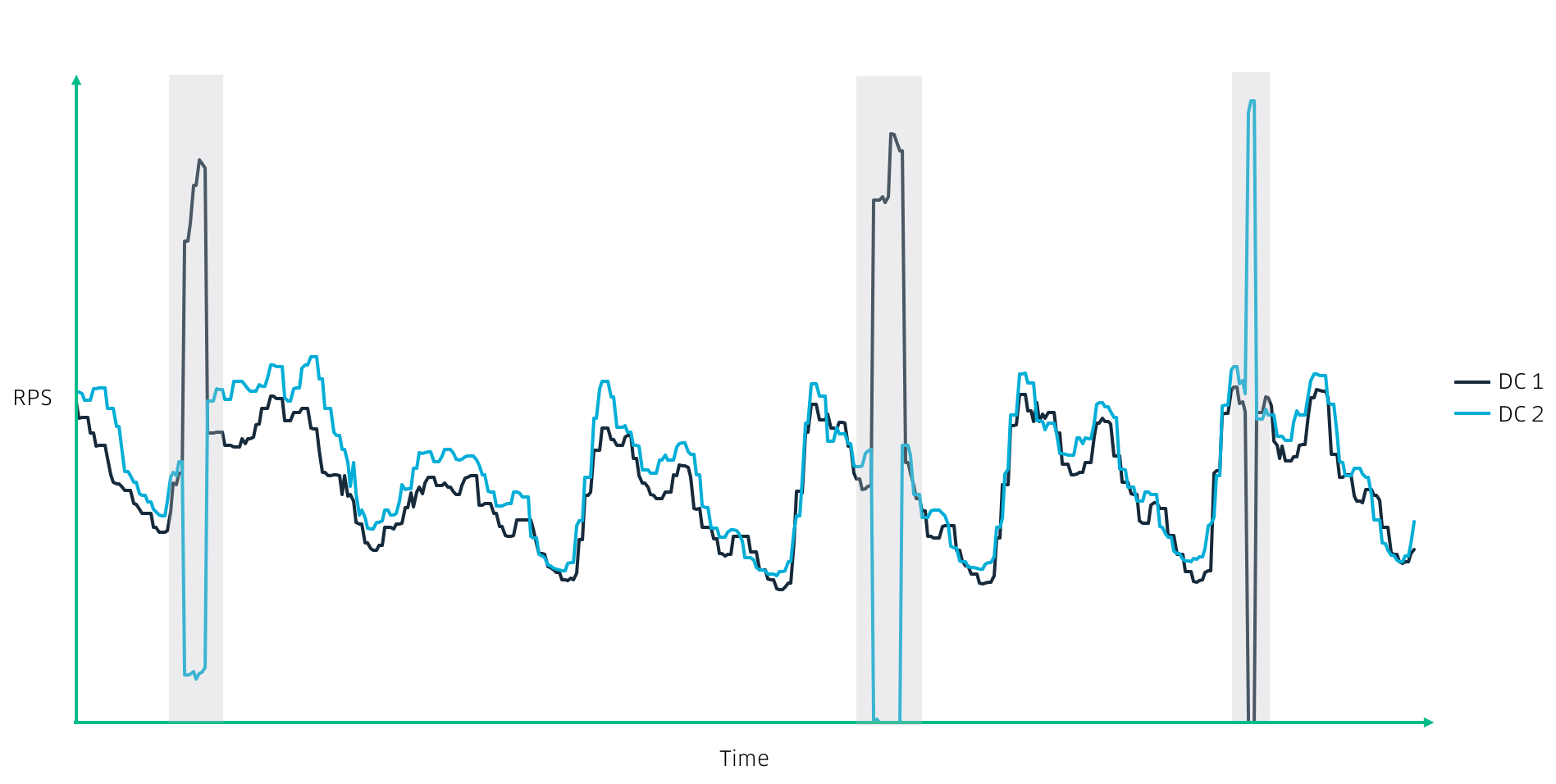
Once the failover intervals are removed from the dataset, we are left with missing values that have to be imputed in order to make the time series continuous. Naive imputation methods, such as linear interpolation, are easy to use but generate unrealistic values. Trend and seasonal components, available through time series decomposition algorithms, must be taken into account in order for imputed values to look realistic. At Uber, we leverage a hybrid imputation approach that combines linear interpolation and seasonal and trend decomposition by Loess plot (STL) to impute the missing values.

Data forecasting and backtesting
For time series forecasting, we leverage an internal forecasting API that uses an ensemble method containing ARIMA, Holt-Winters, and Theta models. Each model’s prediction is taken into account with equal weight, although for future forecasting use cases, models that perform better may be weighted higher than others. Further, the forecasting API implements automatic forecasting, which fine-tunes model hyperparameters without manual input.
To evaluate the ensemble method’s performance, we must generate a metric that quantifies the error between the expected and actual forecasts. Unlike traditional machine learning testing methods, time series data is sequenced so the points cannot be shuffled around arbitrarily. Time series data requires continuous testing, or backtesting, which uses cross-validation to evaluate model performance on rolling windows.
The backtesting procedure quantifies the error between expected and actual forecasts, giving us numerous error metrics: mean error (ME), mean absolute error (MAE), mean absolute percentage error (MAPE), and weighted mean absolute percentage error (wMAPE). We mostly use wMAPE to determine the ensemble method error as it is an unbiased, informative, and consistent metric.
Lower wMAPE scores give us more confidence in the model’s forecast, but there is often a limit to how low the error can go, as time series data can be highly volatile. Service owners using our system have found forecasts with wMAPE scores ranging from 10-15 percent more informative, a goal we try to achieve for each service on our platform.

Capacity safety validation
Weekly forecasts and backtesting scores are accessible through an HTTP API. Service owners interested in conducting local capacity safety tests can take the current state of a metric, calculate the delta between the current state and the forecasted state, and generate the delta load using Hailstorm, the load testing framework at Uber. This provides insight into whether a service is correctly provisioned: if the load test fails, it indicates the service might have performance regressions in the future.

The goal of our prediction system is to streamline the process of forecasting important metrics, conducting local capacity safety drills, and receiving feedback as to whether a service is correctly provisioned. From the development of this service, we found that accurate time series forecasting is feasible given enough operational data. We need two broad sets of statistical techniques, one for preprocessing and another for forecasting. Ensemble-based models are also powerful for inculcating the perspectives of various models.
Moving forward
With operational metric forecasting and API-driven load generation, it is possible to conduct adaptive, automated capacity safety tests for individual microservices. SLA adherence can be validated proactively, as opposed to retroactively.
In the future, we intend to completely automate this process so reliability engineers can ensure the capacity safety of trip-flow services without touching a button. This will also allow quick experimentation and iteration on less critical systems, leading to both greater developer flexibility and better services.
Interested in building a next generation reliability platform? Consider joining our team!
Ruogu Du
Ruogu Du was a software engineering intern on Uber’s Maps Reliability Engineering team in San Francisco in 2018.
Ranjib Dey
Ranjib Dey is a Staff Software Engineer on Uber’s Maps Production Engineering team in San Francisco, CA. Ranjib works on end-to-end resiliency engineering practices across change, incident, and capacity management. Outside Uber, Ranjib is enthusiastic about Open Source and The Internet of Things.
Shrey Desai
Shrey Desai is a software engineering intern on Uber’s Maps Reliability Engineering team in San Francisco in 2018.