Generative Teaching Networks: Accelerating Neural Architecture Search by Learning to Generate Synthetic Training Data
Kenneth O. Stanley and Jeff Clune served as co-senior authors of this article and its corresponding paper.
At Uber, many of the hard problems we work on can benefit from machine learning, such as improving safety, improving ETAs, recommending food items, and finding the best match between riders and drivers.
Machine learning advances have been fueled by the availability of large amounts of human-labeled data, but producing such data is time-consuming and expensive. We in Uber AI Labs investigated the intriguing question of whether we can create learning algorithms that automatically generate training data, learning environments, and curricula to help AI agents rapidly learn. In a new paper, we show that such algorithms are possible via Generative Teaching Networks (GTNs).
GTNs are deep neural networks that generate data and/or training environments on which a learner (e.g., a freshly initialized neural network) trains before being tested on a target task (e.g., recognizing objects in images). One advantage of this approach is that GTNs can produce synthetic data that enables other neural networks to learn faster than when training on real data. That allowed us to search for new neural network architectures nine times faster than when using real data. GTN-neural architecture search (GTN-NAS) is competitive with the state of the art NAS approaches that achieve top performance while using orders of magnitude less computation than typical NAS methods, and it achieves this performance via an interesting new technique.
The architecture of a neural network refers to some of its design choices (e.g., how many layers it should have, how many neurons should be in each layer, which layers should connect to which, etc.). Improved architectures for neural networks have led to major advances in machine learning in every domain (e.g. computer vision, natural language processing, speech-to-text). The search for higher-performing architectures is often done manually by scientists, and is extremely time consuming.
Increasingly, neural architecture search (NAS) algorithms are being deployed to automate the search for architectures, with great results. NAS produced state-of-the-art results on popular computer vision benchmarks such as ImageNet and CIFAR, despite armies of human scientists having already tried to find the best architectures for those problems. Machine learning practitioners throughout society benefit if we can improve the efficiency of NAS.
The challenge
NAS requires substantial computing resources. A naive NAS algorithm would evaluate each neural network by training it on a full data set until performance stops improving. Repeating that process for each of the thousands or more architectures considered during NAS is prohibitively expensive and slow. NAS algorithms avoid this cost by only training for a small amount of time and taking the resulting performance as an estimate of true performance. One possible way to speed the process up further would be to carefully select the most informative training examples from the full data set, a method that has been shown to speed up training (outside of the context of NAS).
We instead asked whether the process could be accelerated by a more radical idea: allowing machine learning to create the training data itself. This kind of algorithm would not be restricted to only creating realistic images, but instead it could create unrealistic data that is helpful for learning, much like basketball drills (such as dribbling with two balls) speed up learning, even if they are not exactly like the actual game. Thus, GTNs being free to create unrealistic data could enable faster learning than with real data. For example, GTNs could combine information about many different types of an object together, or focus training mostly on the hardest examples.
The method: Generative Teaching Networks (GTN-NAS)
The process works as follows (visualized in Figure 1). A GTN is like the generator in a generative adversarial network (GAN), except without a pressure to make data look realistic. Instead, it produces completely artificial data that a never-seen-before learner neural network (with a randomly sampled architecture and weight initialization) trains on for a small number of learning steps, e.g., the steps could be via stochastic gradient descent (SGD). Afterwards, the learner network–which so far has never seen real data–is evaluated on real data (e.g., whether it can recognize handwritten images in the classic MNIST dataset), which provides the meta-loss objective that is being optimized. We then differentiate through the entire learning process via meta-gradients to update the GTN parameters to improve performance on the target task. The learner is then discarded and the process repeats. One additional detail is that we found that learning a curriculum (a set of training examples in a specific order) improves performance over training a generator that produces an unordered random distribution of examples.
GTNs involve an exciting type of machine learning called meta-learning, here harnessed for architecture search. Researchers in the past have used meta-learning to optimize synthetic data directly (pixel-by-pixel). Here, by training a generator, more abstract information (e.g., about what a three looks like) can be reused to encode many, diverse samples (e.g., many different 3s). Experiments we conducted confirm that a GTN generator outperforms directly optimizing data. See our paper for a more detailed discussion of how GTNs compare to prior, related work.

After meta-training the GTN, when limiting learning to a few steps of SGD (e.g. 32), new learners are able to learn on synthetic data faster than real data (red line vs. blue line in Figure 1).
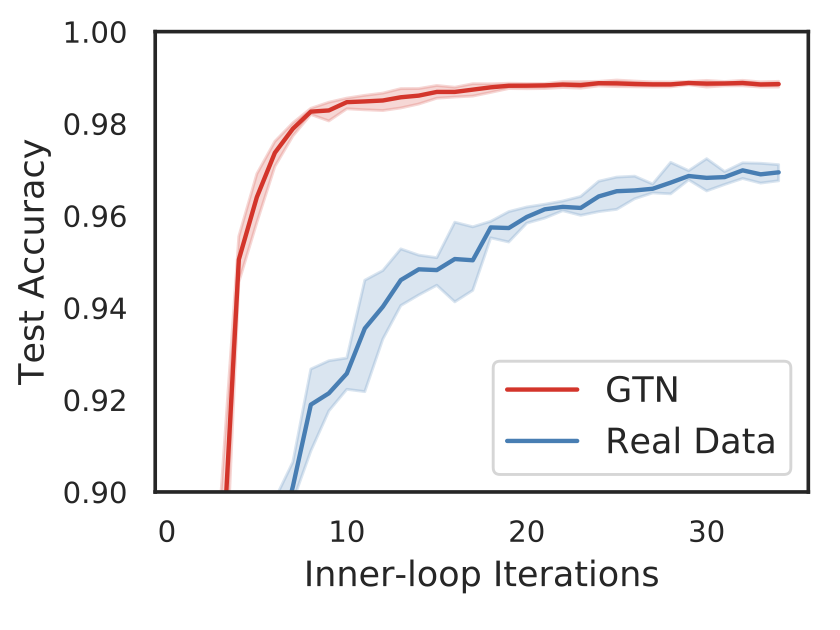
Achieving 98.9 percent accuracy on MNIST on its own is not impressive, but being able to do it with so few samples is: learners trained on GTN data achieve this level of accuracy in just 32 SGD steps (~0.5 seconds), seeing each of the 4,096 synthetic images in the curriculum once, which is less than 10 percent of the images in the MNIST training data set.
Interestingly, even though neural networks can train on these synthetic images and learn to recognize real handwritten digits, many of the GTN-generated images are alien and unrecognizable as digits (Figure 3). That these unrealistic images can meaningfully impact neural networks is reminiscent of the finding that deep neural networks are easily fooled. Also of interest is the sharp increase in recognizability towards the very end of the curriculum, after performance has plateaued (step 32 in Figure 2). See our paper for a discussion of hypotheses regarding why the images are mostly unrealistic, and for why their realism increases towards the end of the curriculum.

Having established that GTNs could speed up training on MNIST, we tried them on the CIFAR-10 data set, a common NAS benchmark. As with MNIST, learners learn faster on GTN-generated data than on real data. Specifically, they learn four times faster for the same performance level (Figure 4), even when compared to a highly optimized version of the real-data learning algorithm.

Neural architecture search with GTNs
To search for architectures, we adopt the ideas of numerous papers that search for a small architectural module that is then repeatedly combined through a predetermined blueprint to create architectures of various sizes. Once a high-quality module is discovered, it can be used to create a larger network, which is then trained on real data to convergence for the target task.
In GTN-NAS, the ultimate goal is to find an architecture that will perform well when trained for many steps (i.e. until it converges) on real data. Thus, the performance of any architecture after a few steps on GTN-produced data is only a means to the end of estimating which architectures will perform well when trained at length on real data. We found that performance on GTN-data is predictive of true performance (0.56 Spearman rank correlation for the top 50% of GTN-estimated architectures). For example, many of the top 10% of architectures according to GTN’s very fast estimation are actually very high-performing (Figure 5, blue squares). That means we can evaluate many architectures quickly with GTN-generated data to identify a few that seem promising and then train those on real data to figure out which is truly high performing on the target task. Interestingly, we found that to achieve the same predictive power (rank correlation) as achieved with only 128 SGD steps on GTN-generated data, you would instead need 1200 SGD steps on real data. That means that using GTN-produced data is 9 times faster than using real data for architecture search.

GTN-generated data is thus a faster drop-in replacement for real data in NAS algorithms. To demonstrate this result, we chose the simplest possible NAS method: random search. The algorithm is so simple that we can be sure there is no special, confounding interaction between a complex algorithmic component and the use of GTN-generated data. In random search, the algorithm randomly samples architectures and evaluates as many as it can given a fixed compute budget. In our experiments, the estimates come either from training for 128 SGD steps on GTN-generated data or real data. Then, for each method, the final best architecture according to the estimate is trained a long time on real data. That final performance on real data is the result we care about.
Because GTNs evaluate each architecture faster, they are able to evaluate more total architectures within a fixed compute budget. In every case we tried, using GTN-generated data proved to be faster and led to higher performance than using real data (Table 1). That result held even when we gave the real-data control ten days of compute compared to two-thirds of a day for GTN (Table 1). Additionally, GTN-NAS with random search (and some bells and whistles that are listed in Table 1) is competitive with much more complex NAS methods than random search (see our paper for a comparison). Importantly, GTN-data can be dropped into those algorithms too, which we expect would provide the best of both worlds, advancing the state of the art.

Moving forward
Generative Teaching Networks (GTNs) generate synthetic data that enables new learner networks to rapidly learn a task. This allows researchers to quickly evaluate the learning potential of a newly proposed candidate architecture, which catalyzes the search for new, more powerful neural network architectures. Through our research, we showed that GTN-generated training data creates a fast NAS method that is competitive with state-of-the-art NAS algorithms, but via an entirely different approach. Having this extra tool of GTNs in our NAS toolbox can help Uber, all companies, and all scientists around the world improve the performance of deep learning in every domain in which it is being applied.
Beyond our immediate results, we are excited about the new research directions opened up by GTNs. When algorithms can generate their own problems and solutions, we can solve harder problems than was previously possible. However, generating problems requires defining an environment search space, meaning a way to encode a rich space of environments to search through. GTNs have the beneficial property that they can generate virtually any type of data or training environment, making their potential impact large. However, while being able to generate any environment is exciting, much research remains to fruitfully make use of such expressive power without getting lost in the sea of possibilities GTNs are capable of producing.
More broadly, we think GTNs are a generic tool that could be used in all areas of machine learning. We have showed their potential here in supervised learning, but we also believe they could be fruitfully applied to unsupervised, semi-supervised, and reinforcement learning (our paper has a preliminary result for reinforcement learning). Most ambitiously, GTNs could help us move towards AI-generating algorithms that automatically create powerful forms of AI by (1) meta-learning architectures, (2) meta-learning the learning algorithms themselves, and (3) automatically generating training environments. This blog post shows that GTNs help with the first of these three pillars, but they could also catalyze efforts into the third by generating complex training environments that successfully train intelligent agents.
To learn more, we encourage you to read our full paper. Our source code is also freely available.
Jeff Clune
Jeff Clune is the former Loy and Edith Harris Associate Professor in Computer Science at the University of Wyoming, a Senior Research Manager and founding member of Uber AI Labs, and currently a Research Team Leader at OpenAI. Jeff focuses on robotics and training neural networks via deep learning and deep reinforcement learning. He has also researched open questions in evolutionary biology using computational models of evolution, including studying the evolutionary origins of modularity, hierarchy, and evolvability. Prior to becoming a professor, he was a Research Scientist at Cornell University, received a PhD in computer science and an MA in philosophy from Michigan State University, and received a BA in philosophy from the University of Michigan. More about Jeff’s research can be found at JeffClune.com
Aditya Rawal
Aditya Rawal is a research scientist at Uber AI Labs. His interests lies at the convergence of two research fields - neuroevolution and deep learning. His belief is that evolutionary search can replace human ingenuity in creating next generation of deep networks. Previously, Aditya received his MS/PhD in Computer Science from University of Texas at Austin, advised by Prof. Risto Miikkulainen. During his PhD, he developed neuroevolution algorithms to evolve recurrent architectures for sequence-prediction problems and construct multi-agent systems that cooperate, compete and communicate.
Joel Lehman
Joel Lehman was previously an assistant professor at the IT University of Copenhagen, and researches neural networks, evolutionary algorithms, and reinforcement learning.
Kenneth O. Stanley
Before joining Uber AI Labs full time, Ken was an associate professor of computer science at the University of Central Florida (he is currently on leave). He is a leader in neuroevolution (combining neural networks with evolutionary techniques), where he helped invent prominent algorithms such as NEAT, CPPNs, HyperNEAT, and novelty search. His ideas have also reached a broader audience through the recent popular science book, Why Greatness Cannot Be Planned: The Myth of the Objective.
Felipe Petroski Such
Felipe Petroski Such is a research scientist focusing on deep neuroevolution, reinforcement learning, and HPC. Prior to joining the Uber AI labs he obtained a BS/MS from the RIT where he developed deep learning architectures for graph applications and ICR as well as hardware acceleration using FPGAs.