Less is More: Engineering Data Warehouse Efficiency with Minimalist Design
Maintaining Uber’s large-scale data warehouse comes with an operational cost in terms of ETL functions and storage. In our experience, optimizing for operational efficiency requires answering one key question: for which tables does the maintenance cost supersede utility? Once identified, we can off-board these tables from our warehouse and migrate the relevant use cases to lower-cost analytics engines, achieving greater overall efficiency.
With petabytes of data to manage, answering the above question is crucial for Uber. However, this turns out to be an interesting data science problem that raises many more considerations:
- How do we quantify utility? There are several factors that go in defining utility, such as the number of queries a given table serves and the number of distinct users accessing a given set of tables.
- Where do we set the threshold for maintenance cost, and how do we measure that against utility?
- How do we incorporate direct and indirect dependency between tables when measuring utility? Usually, all tables are part of a single, large connected graph, and removing one or a few tables breaks many other queries. There are strong network effects that make the isolated analysis of a few tables extremely difficult. We have to take the full graph into account before making any major decisions.
In order to address our central question—determining which tables should be off-boarded from our central data warehouse, Uber’s Data Infrastructure and Data Science teams joined forces to solve this optimization problem.
Calculating costs and utility
To tackle this optimization problem, we split it into two parts. First was the computational cost of running queries. Since there are millions of queries that run against our analytics database, we decided to group queries into query classes. At a minimum, a query class consists of queries using the same set of tables but can be further classified by other criteria, such as the type of operators used and the resources consumed.
Let’s assume there are Q query classes. For each query class q, we also keep track of the number of queries, Lq, and the total cost of running all the queries belonging to a query class, Vq. The query cost is calculated based on the compute resources utilized by the query. Thus, the total compute cost due to all the queries can be represented as:
Above Xq is a binary decision variable. Xq = 1 indicates that query class should continue to execute on the given database. In turn, this means that all the tables needed to support query class should also be available in the database.
The second aspect of formalizing the optimization problem is the cost of maintaining tables, which includes storage and ETL costs. But utility is another important factor. Ideally, the cost of table maintenance should take into account the table’s utility, i.e., if a table has high utility, its effective maintenance cost should be considered low. We model utility using table weight multiplied by table cost. The table weight is computed based on weekly active users pertaining to a given table.
As shown in Figure 1, below, we leverage an inverse sigmoid model in order to decrease the effective cost of the table with the increasing number of users. Further, we use sigmoid function-related parameters to control the slope and the point where the function crosses 0.5 on the y-axis.

Thus, the cost of maintaining all the tables can be represented as:
Above Wt is the weight function that represents the reciprocal of utility. Dt is the cost of maintaining a table. Yt is a binary decision variable that indicates whether a table is assigned to the database or not.
The total operational cost of a database is the sum of its compute and maintenance costs, depicted below:
In order to identify tables that should be off-boarded, we need to minimize the above cost function subjected to the following four constraints. These constraints serve as guardrails, preserving the cost function’s utility for our use case:
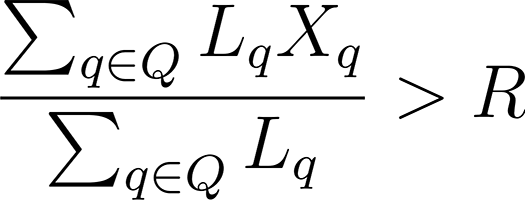
Constraint 1 and 2 enforce the decision variables X and Y to be binary. Xq = 1 indicates that the query should be assigned to the database, otherwise it would be migrated out of the database. Similarly, Yt = 1 indicates that table t should be retained, otherwise it should be off-boarded.
Constraint 3 models the dependency between queries (X) and tables (Y). If a query q uses table A, B, and C and is assigned to run on the database, then associated tables (A, B, and C) should also be assigned to the database, i.e. if Xq = 1 then Yt = 1 for all t where Mqt = 1. Mq is a binary matrix that provides dependencies between queries and tables. Mqt = 1 indicates that query q uses table t.
Lastly, constraint 4 is required to select a solution that does not result in a zero value for all Xq and Yt. The operational cost will minimize, or become zero if there are no tables, which is not practical for our purposes. In order to avoid such a situation, we introduce a query retention criteria, i.e. the query percentage that should continue to be executed on the given database.
Operational cost reduction
Minimizing the cost function (in other words, the total operational database cost) subject to these four constraints provides the answer to the key question: for which set of tables does the table maintenance cost supersede utility?
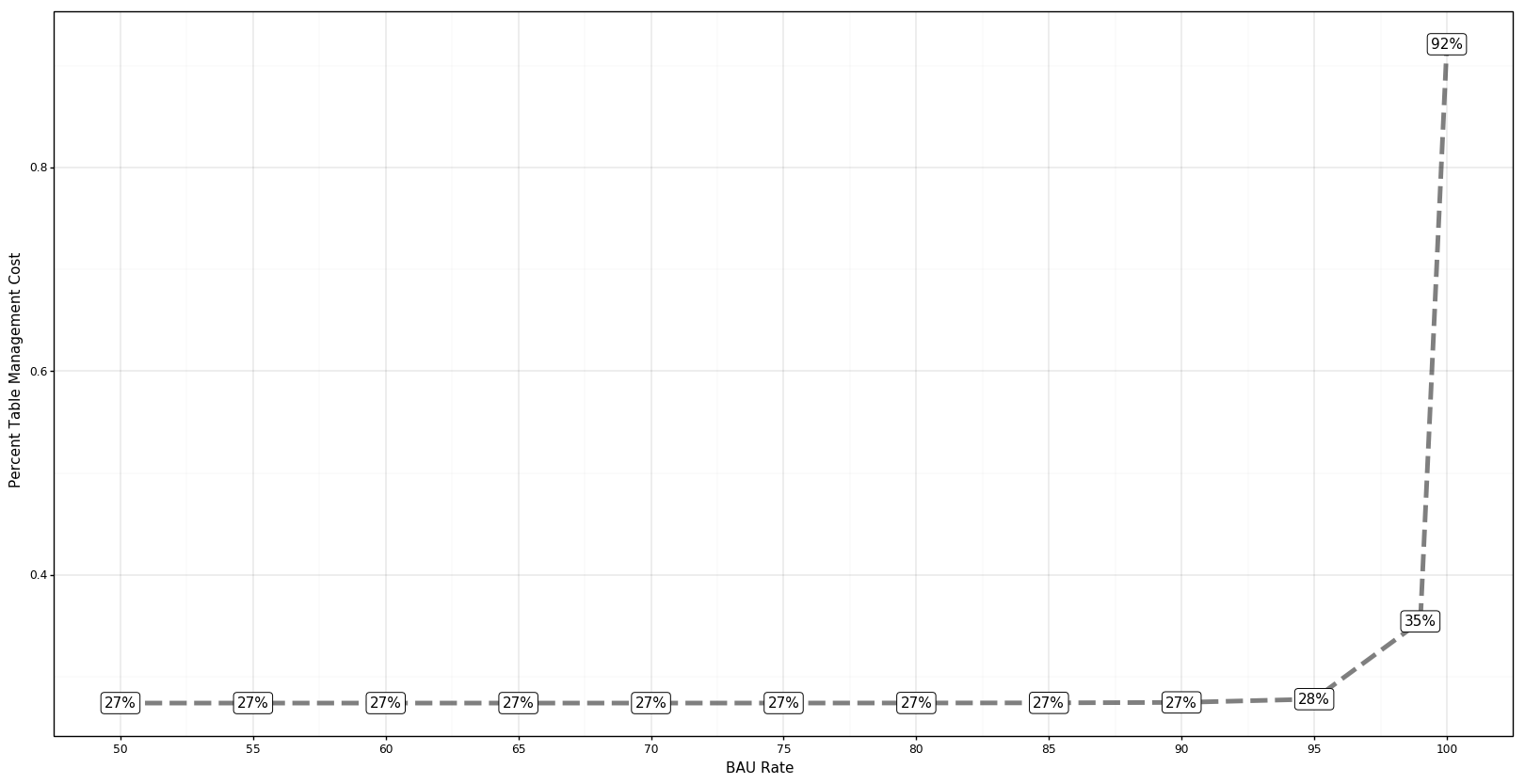
However, the resulting list of tables that fit that condition is dependent on the value of the retention rate . In order to maximize savings, as shown in Figure 2, below, we vary the query retention rate from 50 percent to 100 percent and monitor the drop in table maintenance cost. Even at a 100 percent retention rate, we noticed that the table maintenance cost drops to 92 percent due to the fact that there are some stale data tables that are not being utilized anymore, and the optimization solution correctly identified them.
Our database savings stabilizes around a retention rate of 95 percent, where the table maintenance cost drops to 28 percent of the existing table maintenance cost.
In summary, moving 5 percent of selected queries from our warehouse analytics engine to less costly options such as Presto or Apache Hive enabled us to reduce the utility of a few selected tables to zero. These tables, when off-boarded, reduced the table maintenance cost of our database by 72 percent. Overall, this has the potential to bring down the operational cost of our database by almost 30 percent.
Moving forward
Applying data science to optimize our data infrastructure has shown promise across Uber’s stack, from when we found a way to partially replicate Vertica clusters to the database utilization analysis discussed in this article. Using data science for this use case, we were able to identify the set of tables for which the operational cost supersedes their utility and thereby contributes to operational inefficiencies.
Further, the formalization of this optimization problem opens up the opportunity to consider several other important factors such as the importance of a query and expected latency. Working through this process enables us to measure operational inefficiency, another key challenge for database administrators.
However, we are just getting started. At Uber, machine learning (ML) and AI have the potential to reframe how we design better infrastructure. As our business grows and evolves, the infrastructure needs to keep up. ML and AI can be the key to designing an adaptive and optimized infrastructure.
If you are interested in working alongside us as we build a data-driven platform that moves the world, come join our team!
Girish Baliga
Girish manages Pinot, Flink, and Presto teams at Uber. He is helping the team build a comprehensive self-service real-time analytics platform based on Pinot to power business-critical external facing dashboards and metrics. Girish is the Chairman of the Presto Linux Foundation Governing Board.
Ritesh Agrawal
Ritesh Agrawal is a senior data scientist on Uber's Data Science team, leading the intelligent infrastructure and developer platform teams. His work is focused on finding innovative ways to use data science and AI to make Uber’s infrastructure more adaptive and scalable and enhance developer productivity.
Harsha Venkat Annapa Reddy
Harsha Venkat Annapa Reddy is a senior software engineer on Uber's Interactive SQL team.