Solving Big Data Challenges with Data Science at Uber
The data involved in serving millions of rides and food deliveries on Uber’s platform doesn’t just facilitate transactions, it also helps teams at Uber continually analyze and improve our services. When we launch new services, we can quickly measure success, and when we see anomalies in the data, we can quickly look for root causes.
Charged with serving this data for everyday operational analysis, our Data Warehouse team maintains a massively parallel database running Vertica, a popular interactive data analytics platform. Every day, our system handles millions of queries, with 95 percent of them taking less than 15 seconds to return a response.
Meeting this challenge was not easy, especially considering the exponential growth of Uber’s ride and delivery volume over the years. Growing storage requirements for this system made our initial strategy of adding fully duplicated Vertica clusters to increase query volume cost-prohibitive.
A solution arose through the combined forces of our Data Warehouse and Data Science teams. Looking at the problem through cost analysis, our data scientists helped our Data Warehouse engineers come up with a means of partially replicating Vertica clusters to better scale our data volume. Optimizing our compute resources in this manner meant that we could scale to our current pace of serving over a billion trips on our platform, leading to improved user experiences worldwide.
Scaling for query volume
During Uber’s initial period of rapid growth, we adopted a fairly common approach of installing multiple isolated Vertica clusters to serve the millions of analytics queries made every day. These clusters were completely isolated mirror images of each other, providing two key advantages. First, they offered tolerance to cluster failures, for instance, if a cluster fails, the business can run as usual since the backup cluster holds a copy of all required data. Second, we could distribute incoming queries to different clusters, as depicted in Figure 1, below, thereby helping increase the volume of queries that can be processed simultaneously:

With data stored in multiple isolated clusters, we investigated strategies to balance the query load. Some common strategies we found included:
- Random assignment: Randomly assign an incoming query to a cluster, with the assumption that randomization will automatically result in a balanced load.
- User segmentation: Assign users to different clusters so that all queries from a given user are directed only to the assigned cluster.
- CPU balancing: Keep track of CPU usage across different clusters and assign queries to clusters with the lowest CPU usage.
Relying on multiple, fully-isolated clusters with a routing layer to enforce user-segmentation at a cluster level came with the challenge of managing these database clusters, along with the storage inefficiency associated with replicating each piece of data across every cluster. For example, if we have 100 petabytes of data replicated six times, the total data storage requirement is 600 petabytes. Other challenges of replication, like the compute cost associated with writing data and creating necessary projections and indexes associated with incremental data updates, also became apparent.
These challenges were further compounded by our rapid global growth and foray into new ventures, such as food delivery, freight, and bike share. As we began ingesting increasing amounts of data into Uber’s Data Warehouse to support the needs of our growing business, the fact that Vertica combines compute and storage on individual machines meant a corresponding increase in the amount of hardware needed to support the business. Essentially, we would be paying hardware costs for increased storage without any gain in query volume. If we chose to add more clusters, the resource wastage implicit in the replication process would mean that the actual query volume did not grow linearly. The sheer lack of efficiency in terms of capital allocation, as well as performance, meant that we needed to think outside of the box to find a solution that scales.
Applying data science to data infrastructure
Given Uber’s expertise in data science, we decided to apply principles from that field to optimize our data infrastructure. Working closely with the Data Science team, we set out to increase query and data volume scalability for our fast analytic engines.
A natural strategy to overcome the storage challenge was to move from fully replicated databases to partially replicated databases. As shown in Figure 2, below, in comparison to a fully replicated database system where all the data is copied to all isolated database clusters, a partially replicated database system segments data into different overlapping sets of data elements, equal to the number of clusters:
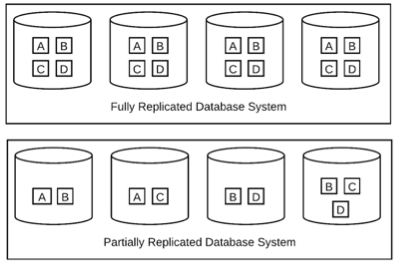
Due to the large scale of the problem, involving thousands of queries and hundreds of tables, constructing these different overlapping sets of data elements is non-trivial. Further, partial replication strategies are often short-lived as data elements grow at different rates, and these data elements change as the business evolves. Apart from considering database availability, along with compute and storage scalability, we also had to consider the migration costs of partially replicating our databases.
With this data infrastructure challenge in mind, our Data Warehouse and Data Science teams came up with three basic requirements for our optimal solution:
- Minimize overall disk space requirement: Our rapid growth meant that our existing strategy of adding fully-replicated clusters wasn’t efficient, as outlined above. Any new solution must allow us to densify our storage and make efficient use of resources.
- Balance disk usage across clusters: Ideally, we want disk space filled in each cluster to be almost the same. Assuming that data is growing at the same pace across all clusters, this is desirable as it ensures no single cluster runs out of disk space before others.
- Balance query volume across clusters: While optimizing for disk space, we also want to ensure that we are distributing query volume evenly across clusters. If neglected, we could end up with a situation where all queries are routed to a single cluster.
Our data science team formalized these requirements into a cost function that can be described as:
A brief description of the three variables in the above equation is explained below, and a more detailed discussion can be found in our paper, Ephemeral Partially Replicated Databases.
- S is described as the maximum storage utilization across N Vertica clusters. Storage utilization is the ratio of data elements stored on a single cluster to the total size of the data elements. For example, if the total size of the data element stored on a Vertica cluster is 60 petabytes, and the total size of all the data elements are 100 petabytes for a given partial configuration candidate, then storage utilization will be 0.6
- L is described as the maximum compute utilization across N Vertica clusters. Compute utilization, in turn, is described as the percentage query volume that can be handled by a given cluster.
- M is described as the maximum migration cost across N Vertica clusters. As described above, one of the challenges of using partially replicated databases is that an optimal partial configuration eventually becomes suboptimal due to the different rates at which different data elements grow as well as due to the changing nature of services and products offered by a business. As a result, replicated databases often have to be reconfigured. This reconfiguration requires moving data elements from one database to another and thereby consumes compute resources. Ideally, we prefer a configuration that minimizes the cost of migration. Migration cost pertaining to a database cluster is described as the amount of new data elements that will be copied from the given state of the database to the new state of the same database.
Minimizing the above cost function for thousands of tables and millions of queries is a difficult task. Based on empirical observations, our Data Science team identified that 10 percent of the largest tables account for about 90 percent of disk utilization. Thus, most of the disk space efficiency will be achieved with an optimal configuration of just 10 percent of our tables.
Focusing on these tables significantly reduced the number of decision parameters we required for optimization. Furthermore, our Data Science team developed an algorithm that generates purposefully sub-optimal solutions by greedily assigning tables and queries to clusters with the lowest cost. This greedy algorithm, which as compared to an optimal solution reduces disk savings by 5 percent, is significantly faster and completes within a few minutes. We decided to productionize this algorithm to favor speed over disk usage.
Once we had the data science problems figured out, the next step was to tackle the engineering challenges. To support partial replication, we had to significantly enhance two components, our proxy manager and our data manager, highlighted below:
- Proxy Manager: With fully replicated Vertica databases, a proxy manager provides a thin abstraction between the client and its corresponding databases, while also acting as a load balancer. All incoming queries are routed through this layer, which has knowledge of query load, data location, and cluster health to ensure each query is routed to a cluster that can handle it
- Data Manager: The second component needed was a data manager. In the fully replicated world, all data is copied from an upstream data lake to all the available Vertica databases. However, in our proposed design, each data element is copied to different databases depending on the partial configuration. The data manager holds information about which cluster requires which tables to be loaded on to it, and will share this information with the proxy manager.
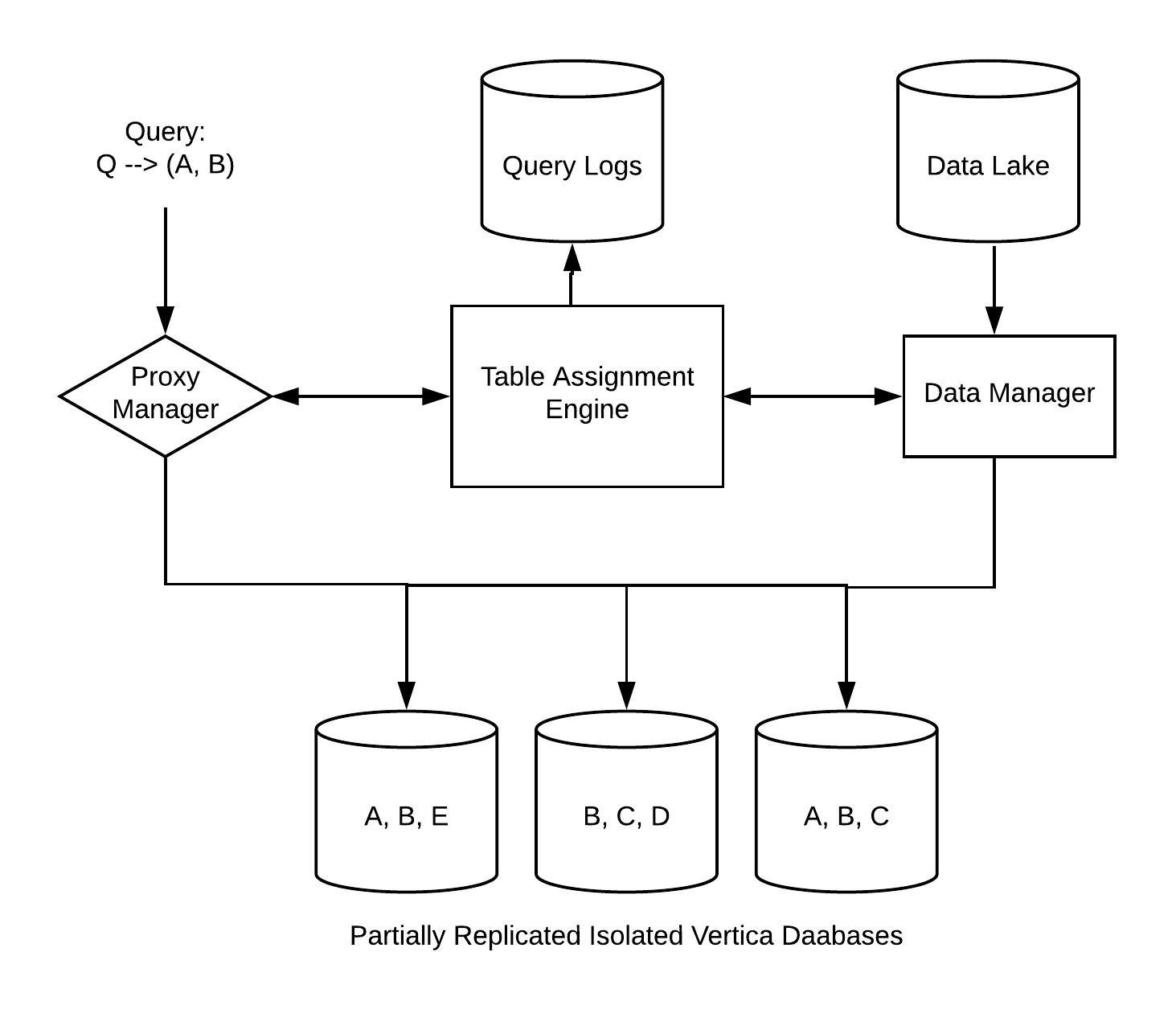
With all these pieces in place, our solution was able to significantly reduce overall disk consumption by over 30 percent, while continuing to provide the same level of compute scalability and database availability. The savings achieved resulted in decreased hardware cost despite query volume growth and also ensured that we were able to balance load evenly across clusters. For Uber’s internal teams using this data, this load balancing meant improved uptime as all queries were always directed to the most healthy clusters and reduced failures for ETLs.
Building an intelligent infrastructure
Working closely with the Data Science team on this project demonstrated how the power of machine learning and data science can be infused into the data infrastructure world, and be used to create a meaningful impact not only on Uber’s business but also for thousands of users, from AI researchers to city operations managers, within Uber who rely on us to power insight-gathering and decision-making. The success of this project has spurred deeper collaboration between our Infrastructure and Data Science teams and has led to the development of a new Intelligent Infrastructure team to rethink infrastructure design for Big Data applications.
If you are interested in working alongside us as we build a data-driven platform that moves the world, come join our teams!
Atul Gupte
Atul Gupte is a former product manager on Uber's Product Platform team. At Uber, he drives product decisions to ensure our data science teams are able to achieve their full potential, by providing access to foundational infrastructure and advanced software to power Uber’s global business.
Ritesh Agrawal
Ritesh Agrawal is a senior data scientist on Uber's Data Science team, leading the intelligent infrastructure and developer platform teams. His work is focused on finding innovative ways to use data science and AI to make Uber’s infrastructure more adaptive and scalable and enhance developer productivity.