Cost Efficiency @ Scale in Big Data File Format
Background
Our Apache Hadoop® based data platform ingests hundreds of petabytes of analytical data with minimum latency and stores it in a data lake built on top of the Hadoop Distributed File System (HDFS). We use Apache Hudi™ as our ingestion table format and Apache Parquet™ as the underlying file format. Our data platform leverages Apache Hive™, Apache Presto™, and Apache Spark™ for both interactive and long-running queries, serving the myriad needs of different teams at Uber.
Uber’s growth over the last few years exponentially increased both the volume of data and the associated access loads required to process it. As data volume grows, so do the associated storage and compute costs, resulting in growing hardware purchasing requirements, higher resource usage, and even causing out-of-memory (OOM) or high GC pause. The main goal of this blog is to address storage cost efficiency issues, but the side benefits also include CPU, IO, and network consumption usage.
We started several initiatives to reduce storage cost, including setting TTL (Time to Live) to old partitions, moving data from hot/warm to cold storage, and reducing data size in the file format level. In this blog, we will focus on reducing the data size in storage at the file format level, essentially at Parquet.
Apache Parquet™at Uber
Uber data is ingested into HDFS and registered as either raw or modeled tables, mainly in the Parquet format and with a small portion in the ORC file format. Our initiatives and the discussion in this blog are around Parquet. Apache Parquet is a columnar storage file format that supports nested data for analytic frameworks. In a column storage format, the data is stored such that each row of a column will be next to other rows from that same column. This will make the subsequent encoding and compression of the column data more efficient.
Format Introduction
The Parquet format is depicted in the diagram below. The file is divided into row groups and each row group consists of column chunks for each column. Each column chunk is divided into pages, for which the encoding and the compression are performed.
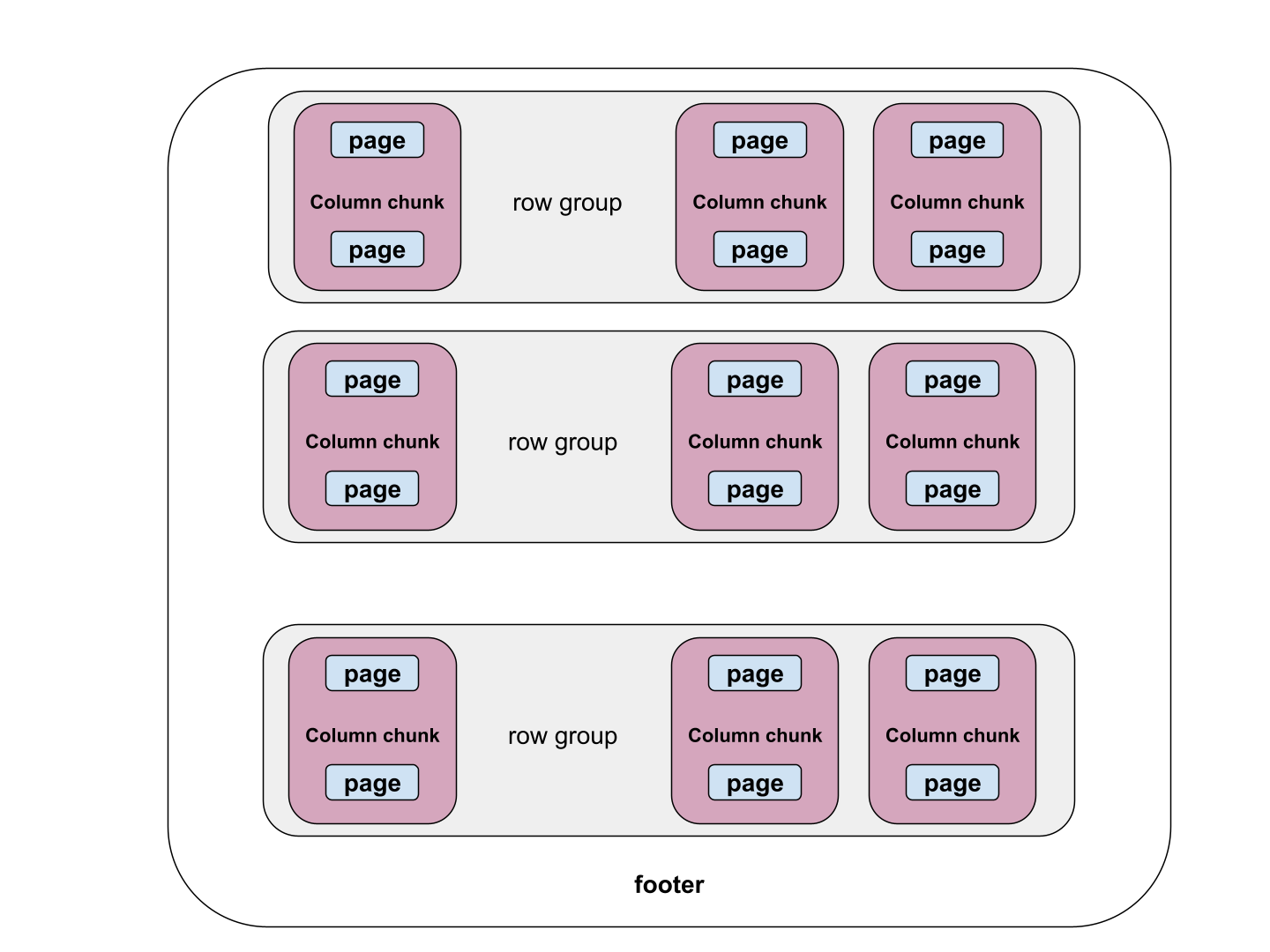
Encoding and Compression
When a Parquet file is written, the column data is assembled into pages, which are the unit for encoding and compression. Parquet provides a variety of encoding mechanisms, including plain, dictionary encoding, run-length encoding (RLE), delta encoding, and byte split encoding. Most encodings are in favor of continuous zeros because that can improve encoding efficiency. After encoding the compression will make the data size smaller without losing information. There are several compression methods in Parquet, including SNAPPY, GZIP, LZO, BROTLI, LZ4, and ZSTD. Generally, choosing the right compression method is a trade-off between compression ratio and speed for reading and writing.
Parquet Usage at Uber
Uber’s data lake ingestion platform uses Apache Hudi, which was bootstrapped at Uber, as the table format and Parquet is the first-class citizenship of Hudi for the file format. Our data platform leverages Apache Hive, Apache Presto, and Apache Spark for both interactive and long-running queries. Parquet is also the first-class citizen in Spark as the storage format, and Presto is also in favor of Parquet which has tons of optimizations. Hive is the only engine that drives for producing data in ORC format, but a significant portion of Hive generates tables that are also in Parquet format. In short, Parquet is the major file format in Uber. So the initiatives discussed below are around Parquet’s optimization or adding Parquet tools to achieve the goal of storage cost-efficiency.
Cost Efficiency Initiatives at the File Format (Parquet)
Bring ZSTD (Zstandard) Compression to Uber Data Lake
ZSTD Introduction
ZSTD can achieve a higher compression ratio while maintaining a reasonable compression and decompression speed (more information can be found here). It provides compression levels from 1 to 22, so that users can choose the level as a trade-off between compression ratio and compression speed. Generally when the compression level increases, so does the compression ratio, at the cost of sacrificing compression speed.
Comparison of ZSTD with GZIP and SNAPPY
GZIP and SNAPPY compression were mainly used in our data lake before this initiative. We did a benchmark test for the storage size reduction and commute (vCore) gain/loss for reading the data after compression with GZIP/SNAPPY.
We picked the top 10 Hive tables in size, converted them to ZSTD, and observed the following size reductions: From GZIP to ZSTD (default compression level 3, hereinafter for all other conversions), we observed ~7% drops in storage size, while from SNAPPY to ZSTD, we see ~39% reduction. Surprisingly, there are still some tables that are not uncompressed in our data lake. ~79% size reduction is seen when compressing them using ZSTD.

While we see the size reduction, we would like to benchmark the compute (vCore duration of queries) indications when switching from GZIP and SNAPPY.
We did a benchmark using different Hive queries and compared the vCore seconds for the data compressed with different compression methods. We chose those queries to try to mimic real use cases as much as possible.
- query_1 (Q1): full table scan query
- query_2 (Q2): full table scan query with shuffle operation
- query_3 (Q3): full table scan query with condition filter
- query_4 (Q4): full table scan query with condition filter, aggregation, and shuffle operation
- query_5 (Q5): full table scan query with condition filter and unnest row transformation
The table below shows the benchmarking comparison result.
| Query | Snappy (vCoreSeconds) | GZIP (vCoreSeconds) | ZSTD (vCoreSeconds) |
| Q1 | 546,077 | 652,543 | 562,616 |
| Q2 | 870,472 | 639,184 | 213,914 |
| Q3 | 240,781 | 353,926 | 191,614 |
| Q4 | 132,490 | 271,814 | 93,082 |
| Q5 | 337,208 | 380,638 | 109,012 |

In general, we see a positive return when converting from GZIP/SNAPPY to ZSTD in terms of not only storage size reduction, but also vCore seconds savings.
ZSTD Compression Level Test
As briefly mentioned earlier, ZSTD supports 22 compression levels. There is a trade-off between compression ratio and resource consumption when compression levels change. We wanted to benchmark the size reduction vs. compression level, and read/write time vs. compression level. This time, we chose GZIP as the baseline. When converting from GZIP to ZSTD, we chose the compression level from 1 to 22 and checked the result.
We set up our benchmark tests by selecting 65 Parquet files from 3 tables, where each file is about 1 GB in size. Those files were compressed using GZIP. The test reads the data into memory by decompressing with GZIP, and then writes the data by compressing them using ZSTD back into Parquet format. We ran it for 22 loops, each loop with a compression level from 1 to 22. The benchmark result is shown below:

The figure shows that generally as compression increases, so does the reduced storage size. Interestingly, when the level is changed from 1 to 2, the reduced size decreases. From levels 8 to 17, the reduced size remains constant. We don’t see the proportional change as the compression level changes, but we do see the trend that when increasing the compression levels, the reduced size increases.
The figures below show the write and read times when the compression level changes. We can see that when the compression level increases, the write time also increases while the decompression time stays constant.


The benchmark results help us to decide the right compression levels based on the use cases. For offline translation of existing data from GZIP to ZSTD, we can choose a higher compression level while sacrificing the compression write time, which the offline staging can tolerate. We choose level 19 because going beyond it won’t benefit the reduced size while writing time increases. The good news is that reading time stays constant so that whatever compression level we choose won’t impact our customer’s query speed.
Parquet to Support ZSTD
Parquet (version 1.11.1 and lower) supports ZSTD, but relies on the implementation provided by Hadoop (version 2.9.1 or higher). Uber’s Hadoop is running on an earlier version than that, so it would be a huge effort to upgrade. Also, local development would be painful if it relied on Hadoop, because setting up Hadoop in localhost would be difficult. We took the initiative to replace Hadoop ZSTD with ZSTD-JNI, which is a wrapped package linked to Parquet, letting us avoid setting up Hadoop. The change has been merged to Parquet 1.12.0 and above. For Hive and Spark, this is sufficient to support ZSTD, but Presto is another story. Presto rewrites some parts of Parquet and its compression is using the airlift package. We made the change PR-15939 to let it support ZSTD.
Column Deletion
When a table is created, table owners can create whatever columns they want, as there is no governance on that. But some of them might not be used, and those unused columns took a lot of space. We found that just one table after removing unused columns, there were PB level data savings.
To find which column needs to be removed, we detect if a column is used or not by analyzing table linkage and audit log. We also developed a Parquet tool to estimate the size of the column to be removed. This tool has been merged to open source Parquet-1821.
Initially, we used Spark to do column deletion. It reads the data into memory, removes the columns, and then writes back to files, but this is very slow since it involves many time-consuming operations (encoding/decoding, shuffle, etc.). In order to run column deletion in a high-throughput way, we developed a tool to remove the column during file copy and skip the column to be deleted directly. In this way, the speed is pretty fast since it only copies the file. We have seen a 20X speed increase over using Spark directly. The Parquet column prune tool is open source and has been merged into Parquet upstream Parquet-1800.
Our data lake uses HDFS for storage, which doesn’t support in-place file updates. So we use the tool to remove the desired columns and put the new files in a new location with the exact same file names and permissions. We will keep the HMS and Hudi schema unchanged, and keep the files beyond that time range intact. There is a known issue that multiple online rewriters accessing data at the same time location create a conflict. The long-term goal is to onboard the rewriter to Hudi clustering, which can coordinate between writers and rewriters.
The diagram below shows how the files are changed and what is preserved:

Multiple Column Reordering
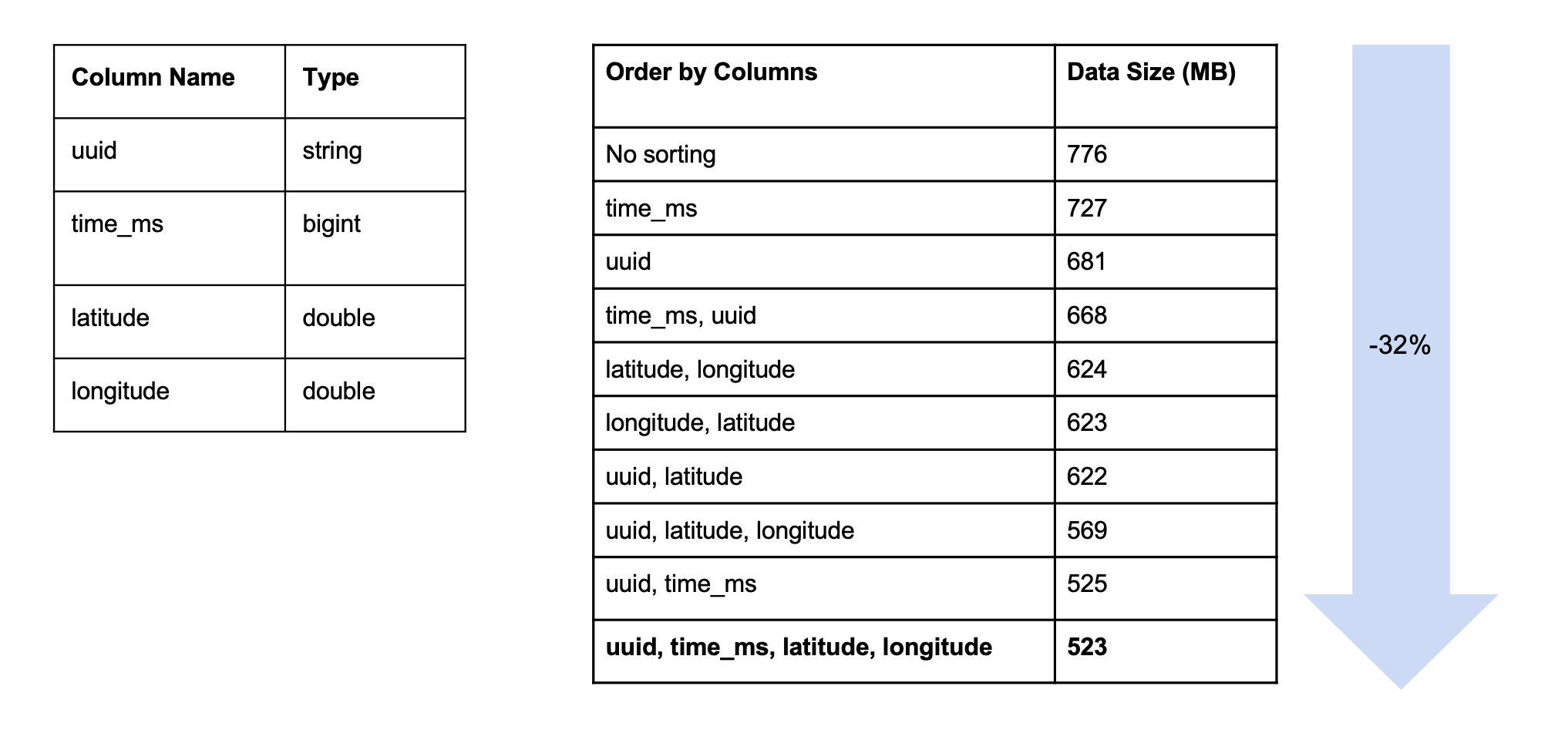
Another technique we used to reduce Parquet file size is called column reordering. After sorting the columns, the encoding and compression are more efficient by sorting similar data together. Inspired by this paper, Reordering Rows for Better Compression: Beyond the Lexicographic Order, we invested the effort to benchmark the savings gained from sorting different columns. The experiment is for one table and one partition, with 4 columns containing the type of UUID as string, timestamps as BIGINT, and lat/long as double, which we sort in different orders. The results show that data size is affected by ordering. Eventually, we see a 32% drop in the data size from no sorting to 4 columns sorting with the right order (UUID, time_ms, latitude, longitude).
Key Takeaways
The Rise of ZSTD
We translated a huge amount of data from GZIP/SNAPPY to ZSTD and observed a huge reduction in storage size. In addition to storage savings, we also gain vCore seconds benefit with ZSTD. We merged our changes to the upstream Apache Parquet repo, including “Replace Hadoop ZSTD with JNI-ZSTD” and “Add trans-compression command.” The first change removes the dependency on setting up Hadoop and the second dependency increases the speed of translating existing compression from GZIP/SNAPPY.
High-Throughput Column Pruning to Remove Unused Columns
In big data analytic tables, some columns could be huge in size, but never used, such as UUID columns. Removing the unused columns will save a lot of storage space. Relying on the column-level audit log of query engines, we can detect the unused columns. We also introduced a column pruning tool and merged the code change to the Apache Parquet repo. The benefit of using this tool instead of using query engines is the speed. The speed of this tool is close to that of copying files, which is far faster than query engines.
Moving Forward
Delta Encoding
Delta encoding is adapted from the Binary packing described in Decoding billions of integers per second through vectorization by D. Lemire and L. Boytsov. This encoding is similar to the RLE/bit-packing encoding. However, RLE/bit-packing encoding is specifically used when the range of ints is small over the entire page. The delta encoding algorithm is less sensitive to variations in the size of encoded integers.
Byte Splitting Encoding
Byte Stream Split encoding was introduced into Apache Parquet 1.12.0. This encoding itself does not reduce the size of the data, but can lead to a significantly better compression ratio and speed when a compression algorithm is used afterward. This encoding creates several byte-streams, and the bytes of each value are scattered to the corresponding streams. As a result, the length of the same values like ‘0’s would increase and benefit the following RLE.
This encoding creates K byte-streams of length N, where K is the size in bytes of the data type and N is the number of elements in the data sequence. The bytes of each value are scattered to the corresponding streams. The 0-th byte goes to the 0-th stream, the 1-st byte goes to the 1-st stream, and so on. The streams are concatenated in the following order: 0-th stream, 1-st stream, etc.
Conclusion
The file format is an area that many companies ignore. We proved that investment in this area (e.g., improving compressions, encodings, data ordering, etc.) brings a huge return on investment.
The ZSTD is an effective compression technique that can achieve not only storage efficiency but also faster reading of the data compressed by ZSTD. After our work is merged to open source (1.12.0+), onboarding to ZSTD using Parquet doesn’t need Hadoop setup anymore.
Column deletion is a challenging area but also effective to detect unused giant columns and remove them to save huge spaces.
Column ordering and decimal precision reduction, along with advanced encoding like Byte Stream Splitting, can achieve a higher compression ratio and save storage space.
Converting existing data on a large scale to apply the above techniques is challenging. We have made several innovations in Parquet to increase the speed by 10X to make the conversion fast. The changes are merged to open source Parquet.
We would like to thank Roshan Savio Lasrado for his great contribution to benchmark the performance of ZSTD!
Xinli Shang
Xinli Shang is the ex–Apache Parquet™ PMC Chair, a Presto® committer, and a member of Uber’s Open Source Committee. He leads several initiatives advancing data format innovation for storage efficiency, security, and performance. Xinli is passionate about open-source collaboration, scalable data infrastructure, and bridging the gap between research and real-world data platform engineering.
Zheng Shao
Zheng Shao is a Distinguished Engineer at Uber. His focus is on big data cost efficiency as well as data infra multi-region and on-prem/cloud architecture. He is also an Apache Hadoop PMC member and an Emeritus Apache Hive PMC member.
Mohammad Islam
Mohammad Islam is a Distinguished Engineer at Uber. He currently works within the Engineering Security organization to enhance the company's security, privacy, and compliance measures. Before his current role, he co-founded Uber’s big data platform. Mohammad is the author of an O'Reilly book on Apache Oozie and serves as a Project Management Committee (PMC) member for Apache Oozie and Tez.
Kai Jiang
Kai Jiang is a Senior Software Engineer on Uber’s Data Platform team. He has been working on Spark Ecosystem and Big Data file format encryption and efficiency. He is also a contributor to Apache Beam, Parquet, and Spark.