Building Scalable Streaming Pipelines for Near Real-Time Features
Background
Uber is committed to providing reliable services to customers across our global markets. To achieve this, we heavily rely on machine learning (ML) to make informed decisions like forecasting and surge. As a result, real-time streaming pipelines, which are used to generate the data and features for ML, have become more popular and important.
At Uber, we leverage Apache Flink to build the real-time streaming pipelines, and build platforms like Gairos and AthenaX to simplify development. However, there are still many challenges, such as scalability, due to either the complexity of computation or the amount of real-time data to be processed.
In this article, we will use the pipelines that generate demand and supply features, as an example to introduce some of the challenges we faced and how we solved them. In particular we will explain how we tune the real-time pipelines with the performance tuning framework.
Architecture
The figure below shows the high-level architecture: Streaming Pipelines in Apache Flink are responsible for the feature computation and ingestion. For the rest of the article, we will discuss these pipelines in detail.

Feature Computation
This section details how to aggregate raw events, such as the demand and supply events, by their geospatial and temporal dimensions, as well as by global product (UberX, etc.) for any given hexagon (c.f., here). The simplified computation algorithm is as follows:
- Count the number of raw events from distinct riders and drivers by hexagon and global product type in a 1-minute window
- Apply the Kring Smooth to multiple rings, up to ring-20 (discussed later) on the 1-minute window
- Aggregate the smoothed values of each ring on multiple sliding window sizes up to 32 minutes
In total, one real-time pipeline generates 54 features for a hexagon each minute, using the combination of 9 rings (0, 1, 2, 3, 4, 5, 10, 15, 20), and 6 window sizes (1, 2, 4, 8, 16, 32).
Next, we discuss step 2 of the algorithm:
Kring Smooth
The Kring Smooth process calculates the geospatial aggregation by broadcasting the event counts of a hexagon to its Kring neighbours. In other words, the feature value of a hexagon for a particular ring takes into account the event counts from all hexagons within that ring.
In order to calculate the feature value aggregated on the ring R for a given hexagon H, the equation is:
Where:
- Num(i) is the number of hexagons of ring i
- Nij is the jth hexagon of ring i
- f(H, 0) is the number of events originated from Hexagon H
So let’s check the following example to see how to compute the values of 3 features: ring 0, ring 1, and ring 2 of the hexagon A, following the equation:
Num(0) = 1
Num(1) = 6
Num(2) = 12
f(A, 0) = 1
f(A, 1) = (f(A, 0) + f(B1, 0) + f(B2, 0)) / (Num(0) + Num(1)) = (1 + 2 + 1) / 7 = 4 / 7
f(A, 2) = (f(A, 0) + f(B1, 0) + f(B2, 0) + f(C1, 0) + f(C2, 0) + f(C3, 0)) / (Num(0) + Num(1) + Num(2)) = (1 + 2 + 1 + 3 + 2 + 1) / (1 + 6 + 12) = 10 / 19

The pipeline follows the equation to calculate the values of features for multiple ring sizes, up to 20.
Temporal Aggregation
After the Kring Smooth completes for a one-minute window, step 3 of the algorithm is to further aggregate the smoothed event counts on larger windows, up to 32 minutes. In order to calculate the aggregation on a larger window for a given hexagon H, the equation is:
Where:
- T is the start timestamp of a window
- W is the window size in minutes
- q(H, T, 1) is the smoothed event count from the Kring Smooth
Figure 3 below demonstrates how to compute the feature value of hexagon A for a 2-minute window:
- The smoothed event counts from Kring Smooth for windows – W1 and W2 – are 1.0 and 3.0 respectively, and are emitted at T0 + 1min and T0 + 2min, respectively
- the feature value for the 2-minute window is 2.0 by following the equation above using the smoothed event counts, which falls into the time range of (T0, T0 + 2min)

Streaming Implementation and Optimization
This section uses the demand pipeline as the example to illustrate how to implement the feature computation algorithm in Apache Kafka and Apache Flink, and how to tune the real -time pipeline.
Logical Jobs Topology
Figure 4 below illustrates the logical DAG of the streaming pipeline to calculate the demand features. For all the windows whose sizes are greater than 1 minute, they are sliding windows, and these windows will be sliding by 1 minute, which means an input event could be included within 63 windows: 32 + 16 + 8 + 4 + 2 + 1.

The table below lists the functionalities for major operators in the logical DAG:
| Operator | Functionalities |
| Kring Smooth on 1-Min | This operator applies the Kring Smooth algorithm. |
| 2-Min, 4-Min, 8-Min, 16-Min, 32-Min | These operators aggregate for those windows sliding by 1 minute, using the smoothed demands returned from Kring Smooth. |
| Merge Windows | This operator collects the aggregated results from all upstream windows (1, 2, 4, 8, 16, 32), then packs them into a single record for persistence. For example, at 1:32am, the operator will emit a record including the demand features for time windows:
|
Table 1: Logical Operators of Demand Pipeline
The Streaming Pipeline’s Data Volume
This section lists the data volumes for the demand pipeline:
- The average input rate of Kafka topics: 120k/s
- Count of Hexagons: 5M
- Count of cities: 1500
- Average and Maximum counts of Hexagons per city: 4K and 76K
- Average counts of demand events by Hexagon at 1 minute: 45
- Hexagon counts of ring-20: 1261
It’s clear that the pipeline has high volume, intensive computation, and large states to manage. The first version was actually built as per the logical DAG, which could not run stably (as shown in the dashboard below due), due to issues including backpressure and OOM. Considering that we are targeting near-real-time latency (less than 5 minutes), there is a real challenge ahead of us to build a stable, working pipeline.
Memory Monitor:

Lagging Monitor:

How to Optimize
This section discusses how to tune this streaming pipeline. At Uber, we have developed a framework of performance tuning for streaming pipelines, as well as an end-to-end integration test framework. Dedicated integration tests are developed before kicking off the actual tunings, allowing us to refactor or optimize a streaming pipeline with confidence that the pipeline will still generate correct results, similar to how unit tests protect us from regression. These integration tests become extremely valuable over the whole process of optimization.
Next, we will introduce the performance tuning framework.
Performance Tuning Framework
As shown in the inner triangle of the figure below, our framework focuses on 3 areas: Network, CPU, and Memory, measured and monitored with the metrics served by Uber’s uMonitor system. The vertices of the outer pentagon indicate the major domains that could be explored for optimization.

The table below briefly explains the techniques and potential impacts of each domain:
| Domain | Major Impacted Areas | Remarks |
| Parallelism | CPU Memory | Controls the count of containers/works for a streaming job. Use Cases:
|
| Partition | Network CPU Memory | Controls how the messages should be grouped by key, and transferred between the upstream and downstream operators. Partition is one of the most important domains, and it impacts all areas as the messages have to be se/der, which takes significant share of CPU, and might trigger more runs of garbage collector, due to the object creation at deserialization. Use Cases:
|
| Remote Call | Network CPU | Controls how an operator of a streaming pipeline interacts with external services or sinks. Use Cases:
|
| Algorithm | CPU | It’s reasonable to assume that the impact of algorithms is greatest on the CPU. Use Cases:
|
| Garbage Collector | Memory CPU | Use Cases:
|
Table 2: The Domains of Performance Tuning
Next, we discuss how to optimize the pipeline.
Optimizations
We have applied many optimizations onto the streaming pipeline, and some optimization techniques impact on multiple areas as described above. One particular technique, Customized Sliding Window, has a significant impact on all 3 areas, so we have a dedicated section to discuss it, as well as one for storage.
Network Optimization
The major optimization techniques are listed in the table below:
| Technique | Area / Domain | Explanations |
| Fields exclusion | Algorithm | Raw Kafka messages have many fields that are not used by the streaming pipeline; hence we have a mapper to filter out unused fields at the very beginning of Job DAG. |
| Key encoding / decoding | Algorithm | Global product type UUID is used as part of the output key. We encode the UUID (128 bits) with a byte (8 bits) via an internal encoding, and then convert back to UUID: writing the output to sink, which reduces the size for both the memory and the network payload. |
| Dedup | Algorithm | We have introduced a 1-Min window to only keep one demand event per distinct rider before the Kring Smooth. The dedup, implemented with a reduce function, has significantly reduced the message rate to be 8k/s for the expensive Kring Smooth calculation. The trade-off is that the dedup window has introduced one more minute to the latency, which is mitigated with other techniques. |
| Field Type Selection | Algorithm | We have refactored the algorithm so that we could choose Integer as the data type for the intermediate computation value rather than Double, which further reduces the message size from 451 bytes to 237 bytes. |
| Merge Window Output | Remote Call | We could have 2 options when writing the output into sink:
We chose the latter, as the former option could only output up to 2M/s to the sink, which simply could not handle this ingestion rate. |
Table 3: Techniques of Network Optimization
As detailed above, the key improvement was to have both fewer and smaller messages.
Memory Optimization
The techniques for memory are listed in the table below:
| Technique | Area / Domain | Explanations |
| Object Reuse | Garbage Collector | By default, objects are not reused in Flink when passing messages between the upstream and downstream operators. We have enabled the object reuse when possible to avoid message cloning. |
| Increase Containers | Partition | Due to the large data volume and states (each container could consume around 6G memory) we have used 128 containers, each with one vcore, for the streaming pipeline. |
| Key encoding / decoding | Algorithm | Global product type UUID is used as the key of the output. We encode the UUID (128 bits) with a byte (8 bits) via an internal encoding, and convert back to UUID before writing the output to Sink, which reduces the memory size. |
| Fields projection | Algorithm | Raw Kafka messages have many fields that are not used by the streaming pipeline, hence we have a mapper to filter out unused fields at the entry point of Job DAG, reducing messages’ memory load on computation. |
| Field Type Selection | Algorithm | We have refactored the algorithm to choose Integer as the data type for the intermediate computation value rather than Double, reducing the message size from 451 to 237 bytes. |
Table 4: Techniques of Memory Optimization
Note: some techniques have also been included for the optimization on the network.
CPU Optimization
The techniques applied for CPU optimization are listed below:
| Technique | Area / Domain | Explanations |
| Message in Tuple | CPU | Flink provides the Tuple type, which is more efficient compared to POJO at serialization, due to the direct access without reflection. We have chosen Tuple for messages being passed between operators. |
| Avoid boxing / unboxing | CPU | The streaming pipeline needs to call an internal library (H3) to retrieve the neighbours for a given hexagon. The API returns an array of Long, leading to unnecessary boxing/unboxing along with the computation. We have added another API to return an array of the primitive type instead. |
| Cache for API | Remote Call | We have enabled an in-memory cache to improve performance when converting the global product type, as the return from remote API does not change that much. |
| Hexagon Index Type | Algorithm | We converted the default hexagon data type from String to Long, which has reduced the window aggregation function’s time by 50%. |
| Kring Smooth | Algorithm | We have re-implemented the Kring Smooth algorithm to make it more efficient. |
Table 5: Techniques of CPU Optimization
Customized Sliding Window
The pipeline still could not run smoothly with just the tunings above, because it needs to aggregate on several sliding windows (2, 4, 8, 16, 32). The window aggregation has the following overheads, due to the need to partition the events by a key:
- De/Ser when passing messages from the upstream to window operators
- Message Transfer over network
- Object being created at deserialization
- State management and metadata required by window management, such as the window trigger
These overheads have added significant pressure to Garbage Collector, CPU and Network. To make things worse, the sliding window requires more states compared to a tumbling or fixed-size window, because one event needs to be kept in a series of slided windows. Take a 4-minute sliding window as an example: given an event occurred at 2021-01-01T01:15:01Z, this event will be kept in the following 4-minutes windows,
- 2021-01-01T01:12:00Z ~ 2021-01-01T01:16:00Z
- 2021-01-01T01:13:00Z ~ 2021-01-01T01:17:00Z
- 2021-01-01T01:14:00Z ~ 2021-01-01T01:18:00Z
- 2021-01-01T01:15:00Z ~ 2021-01-01T01:19:00Z
Due to the fan-out effect from the sliding window, the pipeline is under lots of pressure from state management. To resolve these issues, we have manually implemented the sliding window logic with an operator of FlatMap, with the following features:
- With Object Reuse being enabled, the events from the upstream operators are passed and reused, which avoids the partition and related costs
- States are managed in memory, so in effect each event only has one copy of data
We have the following estimation with respect to the maximum required memory to keep the states in memory:
Total Memory = Count(Hexagon) * Count(Product) * Max(window size) * sizeof(event)
= 3M * 6 * 32 * 237b
= 136G
With the parallelism of 128, the memory per container is around 1G, which is manageable. In production, the actual memory is far below the maximum, because not all hexagons have events for a time range.
The efficiency from this customized sliding window is remarkable, so we have successfully re-used this operator for more than 5 different use cases that required aggregations on multiple large sliding windows.
Final Job DAG After Tuning

After optimization, we end up with a simpler job DAG, where the customized sliding window has replaced the larger window operators.
The pipeline has been running reliably, as shown in the following 24-hour dashboards:
Lagging Monitor:
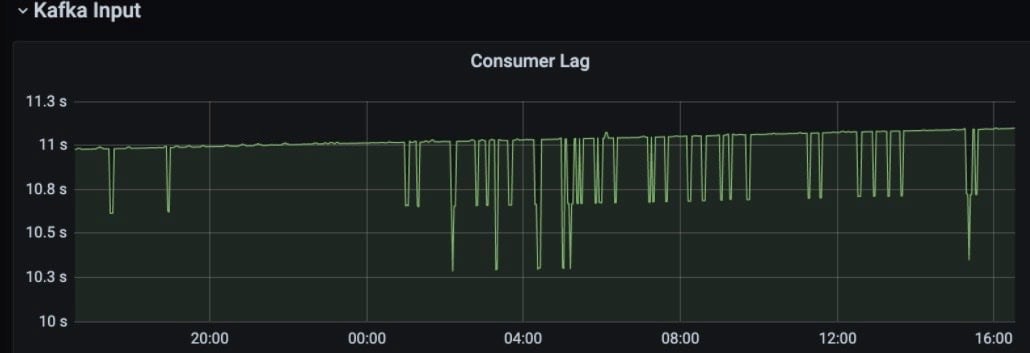
Container Memory Monitor:

Storing
To make it easier for us to maintain the pipelines and re-use the sinks, we have further refactored the pipeline DAG by separating the sink operator into a dedicated publisher job in Flink, and connecting the computation and publisher jobs with Kafka. This section focuses on the details of this publisher job.
For the model being served, it will look up the demand and supply information based on the geo, time and product. We selected Docstore (Uber’s in-house KV store solution) as our storage.
We started with a docstore cluster which is shared by many use cases.
Here are the results for inserting a one row-per-API call. Write QPS peaks around 13k, but most of the time it is on the order of hundreds.

Batching
We tried to write these rows in batches to see whether it would improve throughput. To increase the batching efficiency, we partitioned the data based on the shard number in the Docstore. However, write QPS is lower after batching is applied. After we dug deeper, we found it was due to the cardinality of a dimension of metrics emitted in the streaming job is too large. We change that dimension to a constant string instead of a random UUID. The write QPS can reach about 16k.
Before writing to Docstore, we first write the data to a Kafka topic. After disabling the Kafka sink, we can see around a 10% increase for write QPS.
Write QPS doubled to 34k after we changed the per-shard batch size to 50. We have also tried batch size 100 and 200. For batch size 100, write QPS increases to 37k (about 20% increase).
After changing batch size to 200, not much difference (c.1k) was observed.
In the following table, we list QPS under different configurations:
| Write QPS | |
| First version | 150 |
| Fixing the metrics cardinality problem | 16k |
| After disabling writing to kafka topic | 17.6k |
| Batch size 50 | 34k |
| Batch size 100 | 37k |
| Batch size 200 | 38k |
Table 6: Throughput under different batch sizes
Parallelism
Flink job parallelism is another parameter we tuned to improve the QPS.
After updating the parallelism of the publisher job to 256, the write QPS was around 75k, more than doubled. Batch size is 200. With parallelism 1024, we see the QPS reaches 112k. However, we see a lot of timeout errors already. After changing batch to 50, write QPS is around 120k.
| Job Parallelism | Batch Size | Write QPS |
| 256 | 200 | 75k |
| 1024 | 200 | 112k |
| 1024 | 50 | 120k |
Table 7: Throughput under different job parallelisms
Thread Pool
For each Flink job, we have also tried using a thread pool to increase the write QPS, with the following results:
| Thread Pool Size | Job Parallelism | Batch Size | Write QPS |
| 32 | 128 | 50 | 64k |
| 128 | 128 | 50 | 62k |
| 128 | 256 | 50 | 80k |
| 16 | 256 | 50 | 120k |
Table 8: Throughput under different thread pool sizes
If we use thread pool size 16, peak QPS is around 120k, but it is not very stable.
After we tried every optimization we could think of in the shared cluster, it still could not reach the write QPS we wanted. We asked for a dedicated cluster to test.
Partitioner Tuning
We removed the Docstore sink and just kept the FlatMap. If we removed the call to the partitioner, 64 containers can handle over 200k input message rate without lagging.
We added the custom partition strategy before the FlatMap.

With 384 containers, Lagging was around 12 min. Partitioner latency varies from 0.2ms to 5ms. Increasing to 512 containers brought the lagging down to 3 min. Later we found that 0.2ms per partitioner call is the bottleneck. We added a local partitioner call cache to flatmap. The cache hits were similar to input message rate after 20 min.
However, lagging kept increasing:
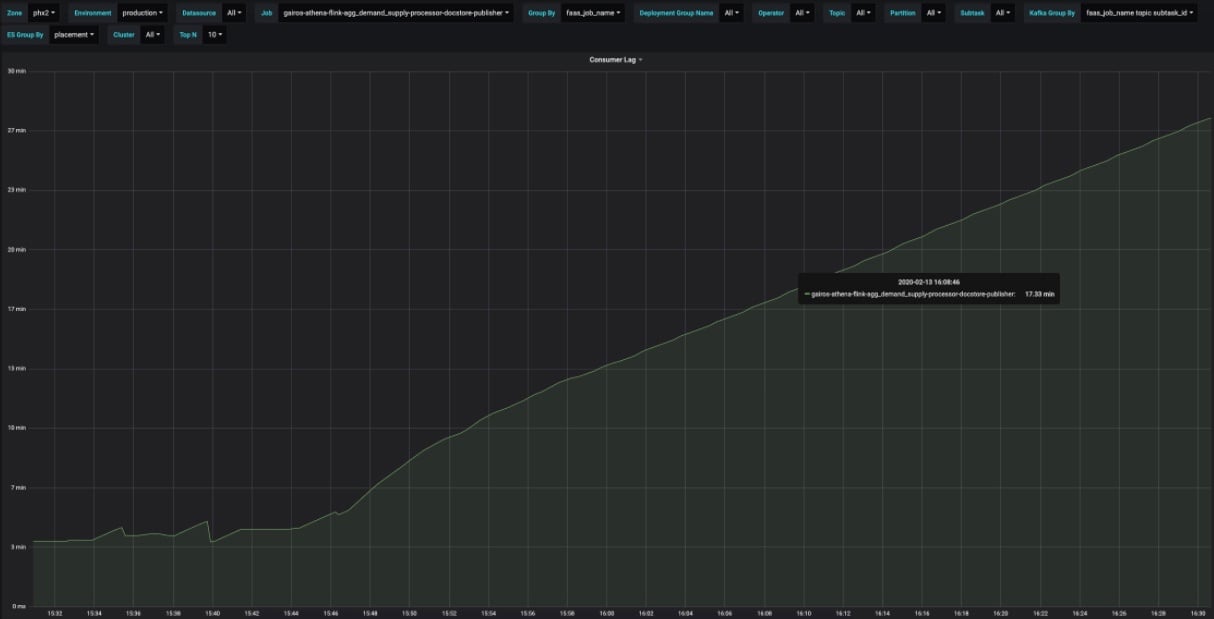
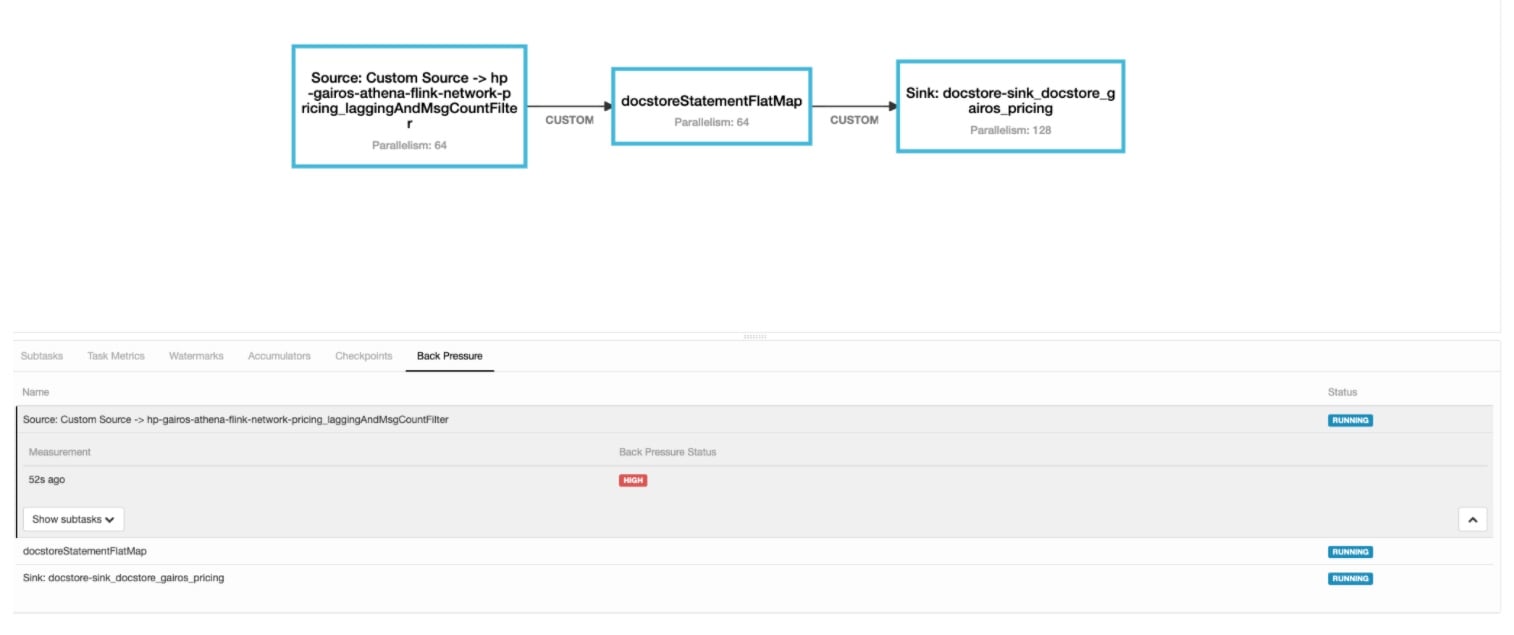
Back-pressure is at the custom partition stage.
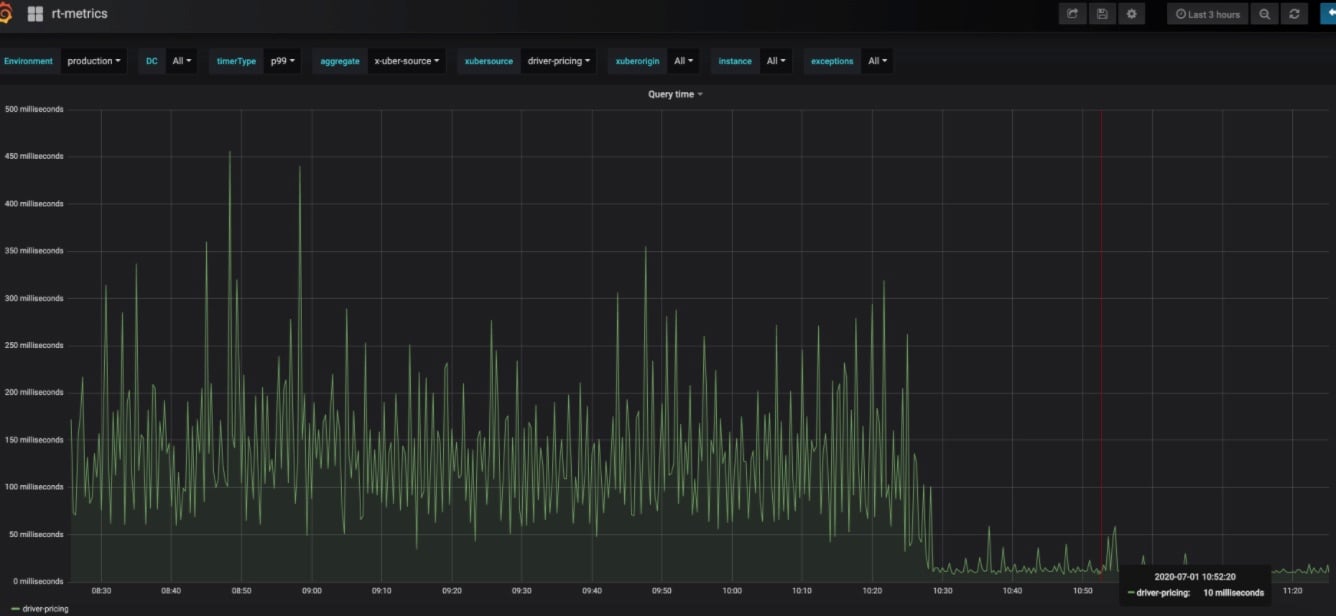
Updating parallelism to 128 effectively removed any lag from the pipeline. Each DC can write 300K QPS without any problem.
Data Size
We tried 3 different schema to see the data size difference. The first uses one column for each (ring size, time bucket, supply/demand) tuple. The second one uses one map for demand and one map for supply. The third one groups 7 hexagons at granular level 9 into one row.

With 6 days of data, we get the data sizes like this:
| No compression | With compression | |
| driver_pricing | 96.3TB | 36.8TB |
| driver_pricing_map | 105.6TB | 43.6TB |
| driver_pricing_map_group | 328TB | 132.6TB |
Table 9: Compression under different data schemas
After enabling the compression, we are seeing around 60% disk savings on all 3 tables.
Serving
During testing, we found some latency issues: P99 latency is around 150ms. It is unacceptable for our pricing workflow. Through debugging we found that each partition key has many rows–around 6k. This means our database engine needs to scan at least 6k rows and then will apply the filtering passed in the Query. As the partition key’s size grows, it causes periodic spikes of 200msec or so. But we realized that TTL is also set for this table, so what we have done is deployed a hot patch in Query to restrict the result to only rows that are not expired, and then apply the filtering passed in the query. This reduced the scan on the underlying engine, and P99 latency dropped to 10ms.
Conclusion
Powering machine learning models with near real-time features can be quite challenging, due to computation logic complexity, write throughput, serving SLA, etc. In this blog, we introduced some of the problems that we faced and our solutions to them, in the hope of aiding our peers in similar use cases.
If you are interested in joining the Marketplace Intelligence team, tackling challenges for large scale streaming (e.g. Flink, Apache Samza), OLAP (e.g. Elasticsearch®) and ML (e.g. ETD prediction), please apply to join our team!
Apache®, Apache Cassandra®, Apache Flink, Apache Kafka, Apache Pinot, Apache Samza, Cassandra®, Flink, Samza, and Kafka are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks. Elasticsearch is a registered trademark of Elasticsearch BV.
Feng Xu
Feng Xu is a Senior Software Engineer II at Uber. He leads the streaming computation framework in Gairos, uMetric.
Gang Zhao
Gang Zhao is a former Senior Software Engineer II who led Gairos optimization, uMetric consumption while focusing on storage layer Elasticsearch, Apache Pinot, Apache Cassandra, Docstore, and query layer optimization.