Creating a Zoo of Atari-Playing Agents to Catalyze the Understanding of Deep Reinforcement Learning
This research was conducted with valuable help from collaborators at Google Brain and OpenAI.
A selection of trained agents populating the Atari zoo.
Some of the most exciting advances in AI recently have come from the field of deep reinforcement learning (deep RL), where deep neural networks learn to perform complicated tasks from reward signals. RL operates similarly to how you might teach a dog to perform a new trick: treats are offered to reinforce improved behavior.
Recently, deep RL agents have exceeded human performance in benchmarks like classic video games (such as Atari 2600 games), the board game Go, and modern computer games like DOTA 2. One common setup (which our work targets) is for an algorithm to learn to play a single video game, learning only from raw pixels, guided by increases in the game score.
Looking beyond video games, we believe RL has great potential for beneficial real-world applications. This is true both at Uber (for example, in improving Uber Eats recommendations or for applications in self-driving cars), and in business and society at large. However, there is currently much more research focused on improving deep RL performance (e.g., how many points an agent receives in a game) than on understanding the agents trained by deep RL (e.g., whether slight changes in the game an agent is trained on will catastrophically confuse it). Understanding the agents we create helps us develop confidence and trust in them, which is needed before putting RL into sensitive real-world situations.
This insight motivated the research project described here: to make research into understanding deep RL easier to conduct. In particular, we created and open sourced a repository of trained Atari Learning Environment agents along with tools to understand and analyze their behavior.
The Atari Learning Environment
Before introducing the Atari Zoo, let’s first quickly dive into the Atari Learning Environment (ALE), which the Zoo makes use of. The ALE (introduced by this 2013 JAIR paper) allows researchers to train RL agents to play games in an Atari 2600 emulator. Why Atari? The Atari 2600 is a classic gaming console, and its games naturally provide diverse learning challenges. Some games are relatively simple (like Pong), while others require balancing competing short-term and long-term interests (like Seaquest, where to succeed you have to manage your submarine’s oxygen supply while shooting fish to collect points). Still others require actively exploring large swaths of the game world before collecting any rewards at all (like Montezuma’s Revenge or Pitfall).
 |  |  |
| Frame | Observation | RAM |
Figure 1: (Left) The actual 210×160 RGB frame produced by the Atari emulator in the game Seaquest. (Center) The grayscale down-sampled 84×84 observations consumed by the deep neural network policy, which include not only the present state of the game, but also the last three timesteps. (Right) All 1024 bits of the Atari 2600 RAM state [horizontal axis] shown across 2000 time steps [vertical axis] of policy evaluation in Seaquest.
What is fed into most deep RL neural networks that play ALE games is not the 210×160 RGB image coming directly from the Atari emulator (Figure 1; left), but a slightly pre-processed grayscale version of four recent frames (Figure 1; center). Also, one interesting element of ALE is that it also provides access to the Atari 2600 RAM state (Figure 1; right), which consists of only 1024 bits and manages to compactly and completely represent the full state of the game. (We’ll use this information later to highlight distinctions among how different deep RL algorithms learn to play games.)
Reducing friction in research into understanding deep RL
A major friction that complicates comparing the products of deep RL algorithms is that it often takes significant computation and expensive hardware to train deep RL agents from scratch, especially across many tasks. For example, there are over 50 games in the Atari Learning Environment. Aggravating computational requirements, RL algorithms are stochastic, which means that to understand how well they do on average requires running each algorithm multiple times.
But if each researcher or lab does all these many runs independently, and then throws away the results (which is what nearly always happens), it’s wasteful, and only researchers with the necessary resources can participate in analyzing deep RL agents. There’s no need to keep retraining all of these same algorithms over and over again—that’s why hosting a zoo of saved models makes sense.
Another source of friction is that it isn’t easy to collect agents from different RL algorithms and analyze them in a common framework. Algorithms are often implemented in different ways, stored in different ways, and only rarely are models easy to load after training for further analysis. As a result, it turns out that very few studies have compared deep RL agents from different algorithms on any metric beyond raw performance, because only performance numbers are universally published. But this is a matter of convenience and not science—what interesting similarities and differences among algorithms are we missing?
A final source of friction is that common analysis tools (like t-SNE state embeddings or activation-maximizing visualizations that help illuminate the role of individual neurons) often must be tediously reimplemented, which wastes researcher time.
While there has been some initial promising research into deep RL understanding, due to the sum total of these frictions we believe there is much less progress than there could be.
Introducing the Atari Zoo
To make it easier for researchers to conduct this sort of science, we ran a selection of common deep RL algorithms at scale across ALE games to create and release a collection of pre-trained models: an Atari model zoo. The concept of a “model zoo” is more familiar in the field of machine vision, where it is common to download weights for popular network architectures (like AlexNet or ResNet) trained on large-scale datasets like ImageNet.
In addition to releasing the raw data of trained models, we also open sourced software that enables easily analyzing these models (and that smoothly integrates with a previous deep RL model release). This software enables comparing and visualizing trained agents produced by different deep RL algorithms. To demonstrate the potential of this zoo and software, we have published a paper (in the Deep RL workshop at NeurIPS 2018), which includes some intriguing preliminary discoveries and hints at many unexplored questions that the zoo can help resolve.
The rest of this article highlights the features of our library through stories of what we’ve found so far while using it.
Case study #1: Self-detecting neurons in Seaquest, and three ways to visualize them
There has previously been a lot of exciting work in understanding and visualizing image classification models. (For an accessible introduction, see this video describing the Deep Visualization Toolbox, or any of the interactive publications on distill.pub, like this one). One intriguing discovery from this line of research is that deep neural networks often learn meaningful high-level features from raw pixels, as information passes through deeper layers of the neural network. For example, although never told what a human face is, image classification networks often have neurons that selectively respond to them.
An interesting question for deep RL is whether or not similar high-level representations arise. For example, are there neurons that respond only to important agents in games? To enable exploring this question, we created a tool in the Atari Zoo software to visualize how information proceeds through a deep RL policy network (inspired by the Deep Visualization Toolbox).
The hope is to peer into the black box of a many-million parameter neural network and gain insight into the network’s behavior and what exactly it has learned. For example, in the video below, which depicts an agent trained by the Ape-X algorithm to play Seaquest (best viewed in full screen), we noticed that some neurons in the third layer of the network seemed to be tracking the position of the submarine that the player controls:
Visualizing a deep RL agent’s neural network as it plays Seaquest.
Below, we zoom in on all the neurons in the third convolution layer:
And here, we zoom further onto a single sub-detecting neuron:
To help validate this insight more exhaustively, we turned to another tool in the Atari Zoo software, one that automatically identifies what image patches from the game most stimulate a particular neuron.

The results showed that indeed, in practice, this neuron was tracking the position of the submarine—in effect, the neural network learned to recognize its own “virtual body” in this game world.
To go one step further, we made use of yet another tool, a neural network interpretability framework called Lucid. Often used for visualizing machine vision models in informative posts on distill.pub, Lucid is easy to use from within the Atari Zoo software. The basic idea is to create hallucinations, images optimized from scratch to excite particular neurons in the neural network. These artificial images provide insight into what a neuron’s idealized input is—what it will maximally respond to.
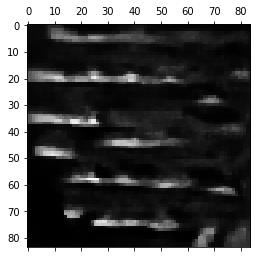 |  |
Figure 3: (Left) An image optimized from scratch to maximally activate the sub-detecting neuron. The result is a tiling of the screen with blobs reminiscent of the player’s submarine. (Right) The result of feeding the hallucinated image back into the network—the sub detecting neuron (shown with arrow) demonstrates high activation across the entire feature map.
In this case, as seen above, the hallucination image corroborates the overall general story. Interestingly, when taken individually, any of these pieces of evidence would be anecdotal. However, by investigating through multiple independent lenses, we can gain confidence in our understanding of a particular neural network feature.
Case Study #2: Do different deep RL algorithms learn distinct playing styles? (featuring three ways to explore the question)
By far the most common way to compare deep RL algorithms is to look at their objective performance: on average, does algorithm X tend to produce higher-scoring solutions than algorithm Y? However, this is a limited lens, because when deploying an agent in the real world, there are many relevant questions that go beyond just score: is the agent’s policy extremely brittle (can it at least handle slight variations of situations)? Has it learned a meaningful representation of the game world? Does it do what we intend, or has it found a loophole in the reward function? Is it risk-taking or risk averse? Aggressive or subdued?
As an initial exploration in this spirit, we looked at the question of whether different algorithms tend to have their own style of solutions (for example, does a policy gradient method like A2C learn to play in a fundamentally different way than an evolutionary algorithm like OpenAI’s ES)? We again draw on the diversity of tools in the Atari Zoo software to probe this question from different angles.
First, we can examine the learned weights of the neural networks. While in general it’s difficult to reason about what a neural network has learned by looking at its weights, the first-layer weights, which connect directly to the input, provide an exception to the rule. Such first-layer weights represent what inputs would most excite those neurons, which gives us a sense of what sort of features they are paying attention to. For example, in ALE, the inputs are images, and the first-layer weights (learned filters of a convolutional layer), when visualized, show what low-level image features the network is keying in on.

Interestingly, depicted in Figure 4, above, the filters learned by the gradient-based algorithms (A2C, Ape-X, Rainbow, and DQN) often have spatial structure and sometimes resemble edge detectors. Additionally, the intensity of weights often significantly decays as connections to older frames are considered. In other words, the neural network is more attentive to the present). However, the filters learned by the evolutionary algorithms (GA and ES) demonstrate less structure, and do not clearly demonstrate a preference for the present frame. As depicted in the graphs below, we show this trend holds statistically by averaging how strong weights are, over games and over first-layer neurons:

This result suggests that the evolutionary methods may be learning fundamentally different kinds of representations than the gradient-based methods. We can then empirically explore this hypothesis by looking at the solutions learned in a particular ALE game, made possible by the Atari Zoo software. Here, we create a grid of videos that simultaneously visualizes several solutions for each algorithm, enabling a quick survey of the resulting behaviors. Below, we show such a video for the game Seaquest:
Grid of videos that enables quickly exploring the kinds of solutions each method tends to generate for particular games. Note that a similarly-generated video highlights how difficult hard-exploration games like Pitfall are for deep RL algorithms (see our recent blog post on Go-Explore).
From the video above, it’s clear that in this game, the algorithms that are directly searching for policies (A2C, ES, and GA) are all converging to the same local optimum (in this case, going to the bottom of the ocean and staying there until they run out of oxygen). In contrast, the off-policy, value-based algorithms (DQN, Rainbow, and Ape-X) learn more sophisticated strategies. So, while earlier in this article we found that evolutionary algorithms may learn different kind of internal neural representations, this example from Seaquest highlights that they (ES and GA) may still converge to qualitatively similar solutions as gradient-based methods (A2C).
Instead of eyeballing across many videos, we can also use dimensionality reduction to get a holistic view of learned strategies from a single image, depicted in Figure 6, below. The idea is to use the popular t-SNE algorithm to embed the RAM states that agents trained by different algorithms reach, into a single two-dimensional space.
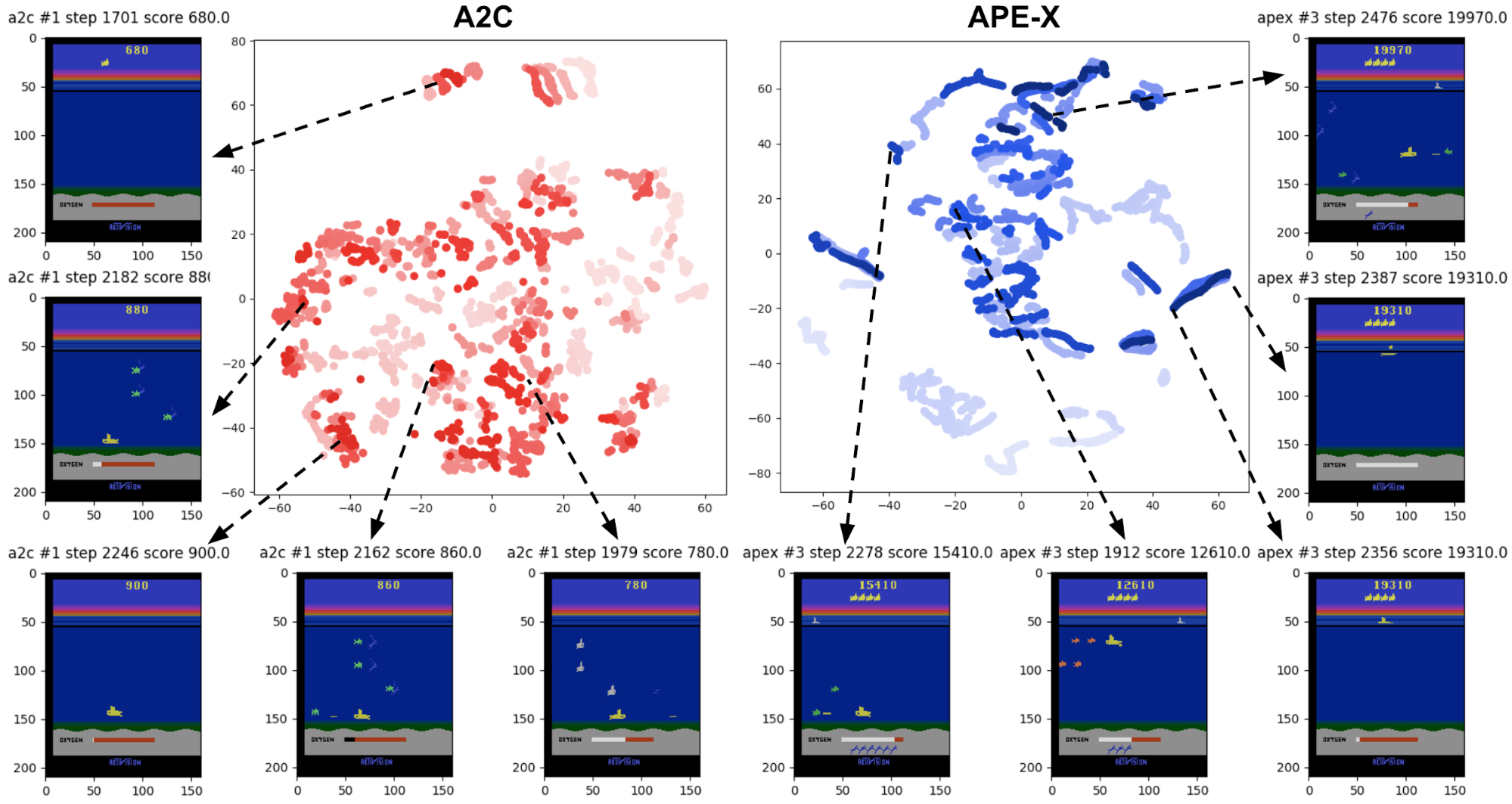
Our paper dives deeper into other tools and studies on automating this kind of question. For example, it includes a study that trains vision models to distinguish which algorithm generated a particular image observation. How confused the trained model is on a held-out testing set (i.e., how many mistakes it makes) highlights which algorithms end up visiting similar parts of the state space.
Overall, this case study provides further examples of the kinds of discoveries that could be unearthed by exploring the Atari Zoo.
Looking forward and conclusions
The paper we wrote to introduce the Atari Zoo only scratches the surface of the kinds of analyses that could be performed with it. We believe that there are likely many intriguing properties of deep RL agents waiting to be uncovered, which this model zoo might make easier to discover (just as model zoos for vision helped reveal the ubiquity of adversarial and fooling images).
We hope to add more deep RL algorithms to the zoo (like IMPALA), and welcome community contributions of new analysis tools (like saliency maps and improved visualization techniques). Future work could explore adding recurrent networks to the zoo, or networks trained with intrinsic motivation and auxiliary objectives, or trained by new flavors of RL like Go-Explore (to see if such networks learn more or less rich internal representations). Also intriguing would be to expand the zoo to include more complicated 3D domains, like VizDoom or DMLab.
While the main reason we created the zoo was to encourage research into understanding deep RL, the trained models may also be useful for transfer learning research (e.g. to explore how to successfully leverage training on one game to more quickly learn to play another one), and the data the models generate could be used to explore learning or using models of Atari games for model-based RL (see these research papers, for example).
In conclusion, we’re excited to introduce a new resource to the deep RL community, and are eager to see the kinds of research questions that the zoo enables the community to pursue. We hope you download and explore our software package, which includes Jupyter notebooks to help you quickly get started (or see the colab notebook here). Also, through online web-tools, you can also browse videos of agents acting and explore their neural activations.
Acknowledgments
We’re grateful to our collaborators Pablo Samuel Castro (@pcastr) and Marc Bellemare at Google Brain, and Ludwig Schubert at OpenAI, for their much-appreciated help with the project. We also thank the entire OpusStack Team at Uber for providing resources and technical support.
Rosanne Liu
Rosanne is a senior research scientist and a founding member of Uber AI. She obtained her PhD in Computer Science at Northwestern University, where she used neural networks to help discover novel materials. She is currently working on the multiple fronts where machine learning and neural networks are mysterious. She attempts to write in her spare time.
Joel Lehman
Joel Lehman was previously an assistant professor at the IT University of Copenhagen, and researches neural networks, evolutionary algorithms, and reinforcement learning.
Rui Wang
Rui Wang is a senior research scientist with Uber AI. He is passionate about advancing the state of the art of machine learning and AI, and connecting cutting-edge advances to the broader business and products at Uber. His recent work at Uber was published on leading international conferences in machine learning and AI (ICML, IJCAI, GECCO, etc.), won a Best Paper Award at GECCO 2019, and was covered by technology media such as Science, Wired, VentureBeat, and Quanta Magazine.
Yulun Li
Yulun Li previously worked as a software engineer with Uber AI.
Felipe Petroski Such
Felipe Petroski Such is a research scientist focusing on deep neuroevolution, reinforcement learning, and HPC. Prior to joining the Uber AI labs he obtained a BS/MS from the RIT where he developed deep learning architectures for graph applications and ICR as well as hardware acceleration using FPGAs.
Jeff Clune
Jeff Clune is the former Loy and Edith Harris Associate Professor in Computer Science at the University of Wyoming, a Senior Research Manager and founding member of Uber AI Labs, and currently a Research Team Leader at OpenAI. Jeff focuses on robotics and training neural networks via deep learning and deep reinforcement learning. He has also researched open questions in evolutionary biology using computational models of evolution, including studying the evolutionary origins of modularity, hierarchy, and evolvability. Prior to becoming a professor, he was a Research Scientist at Cornell University, received a PhD in computer science and an MA in philosophy from Michigan State University, and received a BA in philosophy from the University of Michigan. More about Jeff’s research can be found at JeffClune.com
Vashisht Madhavan
Vashisht (Vash) is a recent graduate of UC Berkeley, where he received his BS and MS in Computer Science, with a focus in Computer Vision and Artificial Intelligence. At Berkeley, his work focused on perception systems for autonomous vehicles. His interests lie at the intersection of computer vision, machine learning, and reinforcement learning.