Analyzing Customer Issues to Improve User Experience
Introduction
The primary goal for customer support is to ensure users’ issues are addressed and resolved in a timely and effective manner. The kind of issues users face and what they say in their support interactions provides a lot of information about the product experience, any technical or operational gaps and even their general sentiment towards the product / company. At Uber, we don’t stop at just resolving user issues. We also use the issues reported by customers to improve our support experience and our products. This article describes the technology that makes it happen.
Support Data at Uber
Support data at Uber comes from a number of sources:
- Different types of customers who reach out for help regarding their trip or order (Eater, Courier, Rider, Driver, Restaurant, etc.),
- In-app surfaces across different apps (Eater app, Rider app, Driver app etc.), across mobile and web, and other external sources such as mobile app store reviews, social media channels etc. where customers reach out for support
- Different support experiences as part of the issue resolution (Chatbot, Automation Experiences, Agent Interactions)
- Channels for agent interactions (Chat, Phone, Messaging, etc.)
Broadly speaking, we use the support data to:
1. Improve the Support Experience
Mining users’ support interaction helps us recognize the top issues faced, as well as the efficacy of their support resolution. For example, analysis of user and support staff interactions has helped us identify patterns that can be automated, such as one-touch agent resolutions. Automating such interactions saves time and effort for users by providing them the same resolution instantly.
2. Optimize the Support Processes
Support data also helps us improve our operational processes, such as improving our knowledge base, managing workforce allocation, training the support staff, etc. For example, we can identify a surge in certain support issue types and notify the relevant agent workforce management teams to prepare for the increased volume of inbound issues by increasing staffing, etc. At Uber scale, minor efficiency gains such as a reduction in agent resolution time by just a few seconds, can contribute to significant cost savings. These also ensure a better support experience for our users.
3. Improve Product Experience
Post resolution, support issues also help us understand the root cause defects in our products. The actual defect could be in the form of an app issue, a back-end service issue, a user onboarding issue, or even an issue with partners such as restaurants. The customer feedback collected through support also helps us understand how a product feature is used and if the user experience needs to be improved.
Given the broad applicability of support data described above, we have invested heavily in building tech that transforms our raw support data into valuable insights for Uber.
Primary Challenges
The primary data source for the use cases mentioned above are the customer issues. These need to be consumed and processed differently to cater to different use cases and consumers, and come with the following key challenges:
- Converting unstructured data into structured information/metrics: Many reported user issues first arrive in unstructured formats (texts, images, etc.), from which information needs to be extracted (e.g., eater had requested “no cheese” in a burger that was delivered with cheese).
- Handling the diverse set of issues and use cases for the different Uber verticals: Each line of businesses (Rideshare, Eats, U4B, Freight, etc.) has their own set of customers and issue types (with some overlaps, such as an Eater also being a Rider). A single platform that can extract and serve insights for all these LOBs needs to be highly extensible and very easy to onboard newer products and use cases with minimal effort.
- Catering to different consumers of support data: namely, support staff managers for different LOBs, Operations teams, product teams, Ops, etc. Each of them need different metrics at different SLAs. For example, any staffing metrics need to be real-time so the staff can be moved around quickly based on demand. However, product teams look for aggregate level insights and need ad hoc exploration support of the datasets.
- Ensuring data quality and correctness at scale. We handle support for safety incidents (such as accidents) in our platform via live support channels like Phone. The data also powers critical financial and operational processes such as Billing for BPOs, Budgeting and Quarterly planning, etc. Hence we need to maintain very high data quality, availability and freshness SLAs.
Tech Requirements
While designing our Support Insights Platform architecture, we broke down the different requirements into 5 key categories based on the different use cases:
1. Real-time Metrics & Analytics
Operational and staffing needs include dashboards with real-time aggregated metrics and fast SLAs. For example, consider agent managers overseeing live channels such as Chat and Phone. Our agents handle sensitive and critical issues such as accidents or safety incidents on these channels. Agent managers and LOB managers need a real-time view of these support queues to know the inflow and outflow of the support issues, how many agents are online/offline to handle inbound issues, etc.
2. Batch Analytics
Batch Analytics power use cases where data can have slower SLAs (~24Hours) and primarily drive product and support strategy, monthly scorecards and reports, etc. For example, past ticket volumes serve as a key indicator for staffing forecasts in our workforce management processes.
3. Real-time Analytics with Batch Enrichment (Complex Event Processing)
Operational and staffing also needs metrics that are computed in real time and enriched with data from our batch processing pipelines. For example, the number of unresolved issues of a certain type might include some that are days or weeks old and still pending on the user to respond back to the agent. In that case, we need to enrich the real-time inbound contacts with stale contacts that are days old to compute the metric.
4. Batch Metrics Queried by Online Services
Metrics and insights served by our platform often get integrated into a number of online services and internal applications that enable Ops personnel to take appropriate actions. For example, content quality metrics need to be embedded in the CMS tools for the content authors to understand and improve the quality of our knowledge base articles. These metrics do not have any real-time requirements. For example, the number of views for a particular article can be accurate as of ~24 hours. However, computing the metrics cannot be done on-demand via batch processing systems such as Apache Hive™, since they need to be available and loaded along with the tool.
5. Real-time Search
We also need to support a lot of online, real-time search use cases. For example, an agent may be resolving an onboarding issue for a driver partner and needs to look up details from recently uploaded documents to resolve the issue.
Data Quality Requirements
We handle support issues for active trips and active orders with the resolutions happening in real time via live channels. As a result, we rely on data from numerous, upstream systems that may or may not be interacting with each other. An outage in one system may have a downstream impact in our metrics. We also have datacenter failovers and broader network outages that result in data loss. Our platform needs to be resilient towards these outages and be able to bounce back quickly to self-correct the metrics via strategies such as replaying past events, supporting offline modes, checkpointing, and restoring tombstoned states for a quick bootstrap, etc.
The Solution
Architecture and Components overview

The diagram above highlights the layered architecture of our platform that processes raw metrics, stores them in Data Stores, and then serves them in the UI via a Query layer. Below we will break down the responsibilities of the key components in the architecture, and highlight the technical challenges that we addressed in each layer.
Almost all of the components have been implemented using open-source technologies that are widely available. We largely use Apache Kafka® for messaging at Uber. Several microservices publish messages to Kafka using Avro encoding. These messages then either get ingested directly to Hive for batch processing, or get processed using a stream processing engine for Real-time, CEP and Search use cases.
We use Apache Flink® for our stream processing needs. Most of our stream processing jobs read messages from one or more Kafka topics, process them, and publish the processed messages back on a different Kafka topic. These processed messages are then ingested into the Apache Pinot™ database using specialized, real-time data pipelines. The Apache Spark™ engine powers our batch processing needs.
Data from real-time pipelines and Hive get ingested into the Apache Pinot database, which is specialized for serving large amounts of data (more than 100 billion records) at sub-second query latency with a QPS greater than 1K.
Our query layer is a GoLang microservice that serves data from Pinot to various different dashboards and web applications. It leverages different connectors to query other production databases, apart from our Pinot data store, for metrics enrichment. Our query layer also does several optimisations to improve freshness and latency, such as caching, query transformations, and result enrichments to avoid challenges like mutable dimensions (cf., the Query Gateway section).
While the batch processing pipelines where messages get ingested to Hive are a bit more straight-forward, the design of our stream processing pipelines is a lot more involved. In the following sections we describe each of the layers, detail the key components and challenges for our stream processing pipelines.
Processing Layer
Flink Jobs
Many of our Flink jobs are stateful. Some common reasons for maintaining states are: to detect duplicate events, to enrich events based on the information available on previously processed events, or to build context for the state machine. Flink provides many state management capabilities that ensure high throughput, exactly-once processing, and fault tolerance. Managing state outside of Flink, like in Redis, removes all of these advantages. On the other hand, maintaining state inside Flink takes away flexibility, particularly when a new version of the job needs to be deployed, or during launch when the job needs to be bootstrapped with the correct state, after the backfill job is completed.
Backfill itself is challenging with real-time processing. Backfill is required on the launch if the team needs to process several prior months of data or when the team fixes bugs or launches new features. Flink jobs normally reads data from Kafka, which at Uber normally holds no more than 7 days worth of data. Any backfilling or reprocessing means either doing it in batch, or publishing data back to Kafka. Processing in batch is essentially following Lambda architecture, which comes with several disadvantages (see here). We have adopted the Kappa+ architecture to solve the backfill issue.
Kappa+ Architecture
Kappa+ architecture is an extension to Kappa architecture in which Flink jobs read from Hive tables directly, instead of reading from Kafka during the backfill mode. Whenever a team needs to do backfill, they invoke the same Flink job in backfill mode. A Flink job in backfill mode reads data from Hive instead of Kafka, providing the benefit of using the same code instead of maintaining two versions of code (i.e., one for realtime and one for batch). This comes with the challenge of bootstrapping. When the team completes running a backfill job, it needs to transfer the state of the backfill job to an online job, in order to maintain continuity. This can be done with Redis. Before the backfill job completes, it writes its state on Redis. When a new online job gets invoked, it checks if it needs to update its state from Redis, based on the last processing timestamp.
Metric Computation
It is tempting to do most of the metric computation in the Flink job itself. Doing so, however, would result in a very rigid system—hard to debug, and effortful to change/introduce new metrics. On the other hand, if one can transform events into enriched records that can be used to derive metrics on the fly while querying the Pinot database, then the same Flink pipeline can be used to derive many different variants of metrics, slice and dice on different dimensions, and show at various degrees of aggregations. Doing so is possible because of the low latency and high QPS capabilities of Pinot.
Managing Faulty Services
While doing enrichment in the Flink pipeline, one may need to do API calls to other services. It is important to consider the various fault tolerance trade-offs inherent to such API calls. If the API fails, one may choose to retry with exponential backoff. On the one hand, allowing an infinite number of retries may halt the pipeline for one bad event, while on the other hand, dropping events after a limited number of retries may result in losing too many events, leading to inaccurate metrics. Having a balance between number of retries and drop percentage is important, and may vary based on the use case at hand. In many cases we tune exponential backoff delay and number of retries in such a way that we only lose a very negligible amount of events in a given day. This helps us to deal with transient errors, bad quality of events, and also service failures that sometimes take a couple of hours to fix. Doing so makes recovery completely automated, without requiring any human intervention.
Dimension Mutability
Not every dimension needs to be part of the analytics database. Any field that mutates after it gets stored in the database can be selected for storage elsewhere. Instead we may choose to store identifiers of these fields. In the query layer, queries can be transformed to fetch data using identifiers instead of field values, and also enrich the response with the field values. For example, let’s say a user wants to see a metric by product type. Given that product type can change over time, aggregating over product type ID and enriching results with product type is better than storing product type in the database directly. Aggregating on product type may result in metrics split by old and new values. Adding a custom logic to handle this split will make the system complex and unpredictable as well.
Data Stores Layer
Apache Pinot works very well for most of our real-time analytical needs. It provides an ability to compute metrics on the fly, even when volumes are high. We compute metrics on 13 months worth of data, which results in executing queries on hundreds of billions of records. Most of our metrics support more than 10 dimensions, which means that users can apply filters and/or aggregations to these dimensions on the fly, surfacing metrics to dashboards or various web apps.
Pinot can handle more than 1000 QPS with sub-second query latency. That means 1000+ users can compute metrics at the same time with less than a second delay, and with a freshness of less than a second. Pinot manages to fulfill these conflicting requirements because of its ability to combine real-time and offline segments transparently at query time. Databases like ElasticSearch and InfluxDB also provide many of these capabilities, but they normally suffer in one or more of these capabilities. For example, ElasticSearch can provide QPS, low latency, and scale with high volumes, but it lags at freshness.
Data Modeling
While Pinot is good at handling our SLAs, it comes with its own challenges. Pinot is an append-only database, which means users can only append records, rather than being able to update or delete existing records. This makes it difficult to compute even simple metrics, like the number of open orders by city. Query needs to identify the latest record for each order and count if the status is open.
Pinot also has limited query capabilities. When we started working with Pinot it was lagging in its capability to support JOIN operations with other tables. This forced us to denormalize the data before insertion into the database. Denormalizing multi-value fields, such as tags or badges, will result in an explosion of records if the database does not support complex data types like arrays. Pinot’s limited capabilities for upsert, join, and complex data types made our data modeling challenging for certain metrics. These limitations are significantly reduced due to several contributions made by the Uber Data Platform team in supporting Upsert and Join in the latest Pinot release.
Query Layer
Query Gateway is a GoLang microservice that acts as a query layer to serve data from various analytics databases to a variety of dashboards and web applications. It leverages various available database connectors to execute queries. Our query layer also performs several optimisations to improve freshness and latency, such as caching, query transformations, and result enrichments to avoid challenges like mutable dimensions. This service also understands user context and metric offsets for supporting our data quality requirements (see Auto-healing section below).
Query Gateway exposes API endpoints to return multiple metrics in a single RPC call. A request normally contains a list of metrics, filtering criteria, pagination, and sorting with user context. The service translates the filtering criteria into conditions for the query. In some cases these translations also replace columns (e.g.,instead of filtering by Product Type it filters by Product Type ID), expands regular expressions (e.g., instead of all Product Type starting with Food* it replaces it with a list of Product Type ID), also converting filter criteria like Product Type Group to Product Type IDs by performing a lookup, either in the local cache or with an API call to another service.
It also adjusts query parameters based on user context, for example converting time range based on user local time zone, or replacing global thresholds with region-specific thresholds.
Query Gateway also enriches results by adding additional dimensions to the output based on existing dimensions. This is done to avoid storing mutable dimensions in the database, resulting in dashboards showing metrics with the latest dimension values.
Visualization
We explored several visualization tools before building our own web solution using React JS for our real-time workforce management use cases. We found that the available visualization tools work like a charm for non-real-time use cases, but often struggle with real-time datasets. We needed a tool that satisfied our below requirements:
Freshness
Ability to show metrics in real time with delays under 5 seconds on a large dataset (over 100 billion records). Most tools cache records and try to compute metrics on the cached dataset. These tools normally keep an upper cap on the size of the dataset. Some enforce restrictions on data pull intervals. A tool that allows near-real-time freshness without any restriction on dataset size should pull data directly from the database by slicing data based on user filters, pagination parameters, and computing metrics on the fly. This approach is normally possible if the underlying database provides high QPS and low latency guarantees, like Apache Pinot.
Reasoning
Visualization tools should also help users understand easily how a particular metric is getting computed. The ability to understand a metric by quickly looking at how it is computed is very important when we deal with hundreds of evolving metrics. Tools like Tableau do a great job in terms of performance, but they normally hide away details like metric computation logic, making it difficult for the users to understand it, and also complicates version control. This also makes debugging very difficult. Having a tool that computes metrics on the fly can easily show how a particular metric is being derived.
User Context
Visualization tools should be adaptable to different user personas, especially when the user base is spread across different regions. Each region may have slightly different requirements for the way they want to look at the dashboard. This can be achieved by maintaining a user context and propagating it to the query gateway. Query gateway uses this user context while performing query transformations to adapt to user persona. This could mean changing the query parameters as per user timezone, or replacing global thresholds in the query with region-specific thresholds. This helps users see slightly different versions of metrics without explicitly code for it.
Self Serve and Portable
The tool should also help users to create new metrics and charts by adding configurations without doing any coding for at least 60 percent of cases, minimum coding for another 30 percent of cases. and provide a workaround for remaining complex 10 percent of cases. The ability to embed charts from other visualization tools as an iframe can help reuse what’s already available in other tools, and also help consolidate data from different systems onto a single screen. It also helps users embedding metrics computed with batch pipelines, and does not have real-time refresh requirements.
Handling Data Quality Requirements
The real-time data pipeline deals with multiple subsystems like Kafka, Flink, Spark and Pinot, and all of them are distributed, complex systems under the hood. No matter how hard we try, it remains difficult to ensure 100% accuracy of metrics. It is common to receive events more than once, resulting in duplicate counting. For example, Flink job restarts result in reprocessing of some of the events. To ensure overall high quality of an analytics system, several measures need to be taken.
Auto-healing
A self-healing service is written to compare the source system with an analytics database, in order to catch possible double counting. This service maintains offset by identifying double counting or any such anomalies, and feeds to Redis. Query gateway uses this offset to adjust metric values and improve the overall correctness of dashboards. These offsets are also visible on the UI to help users understand the adjustments that inform metric calculation.
Auto-correction
While offsets help in correcting the metrics, they are often limited in their ability when dealing with trending charts, because the offsets only reflect the final picture, and not intermediate values. In order to solve this, we wrote a service to replay compensating events to Kafka. In a case of double counting, a compensating event will cancel it out to improve the correctness of the metrics. This approach ensures synthetic events capture accurate event time, so that the correctness of time series metrics do not suffer.
Conclusion and Next Steps
With the foundational elements of the platform ready, we have been able to onboard use cases such as real-time analytics dashboards for workforce management use cases. By providing insights on the inflow and outflow of support queues and the ability to drill down to support tickets in the queue, our Queue Analytics dashboards help the agent managers manage their support queues and understand potential problems, such as a sudden increase in the queue size that might require increased staffing.
Below is a sample queue analytics dashboard powered by our platform that shows inflow / outflow metrics in real time.
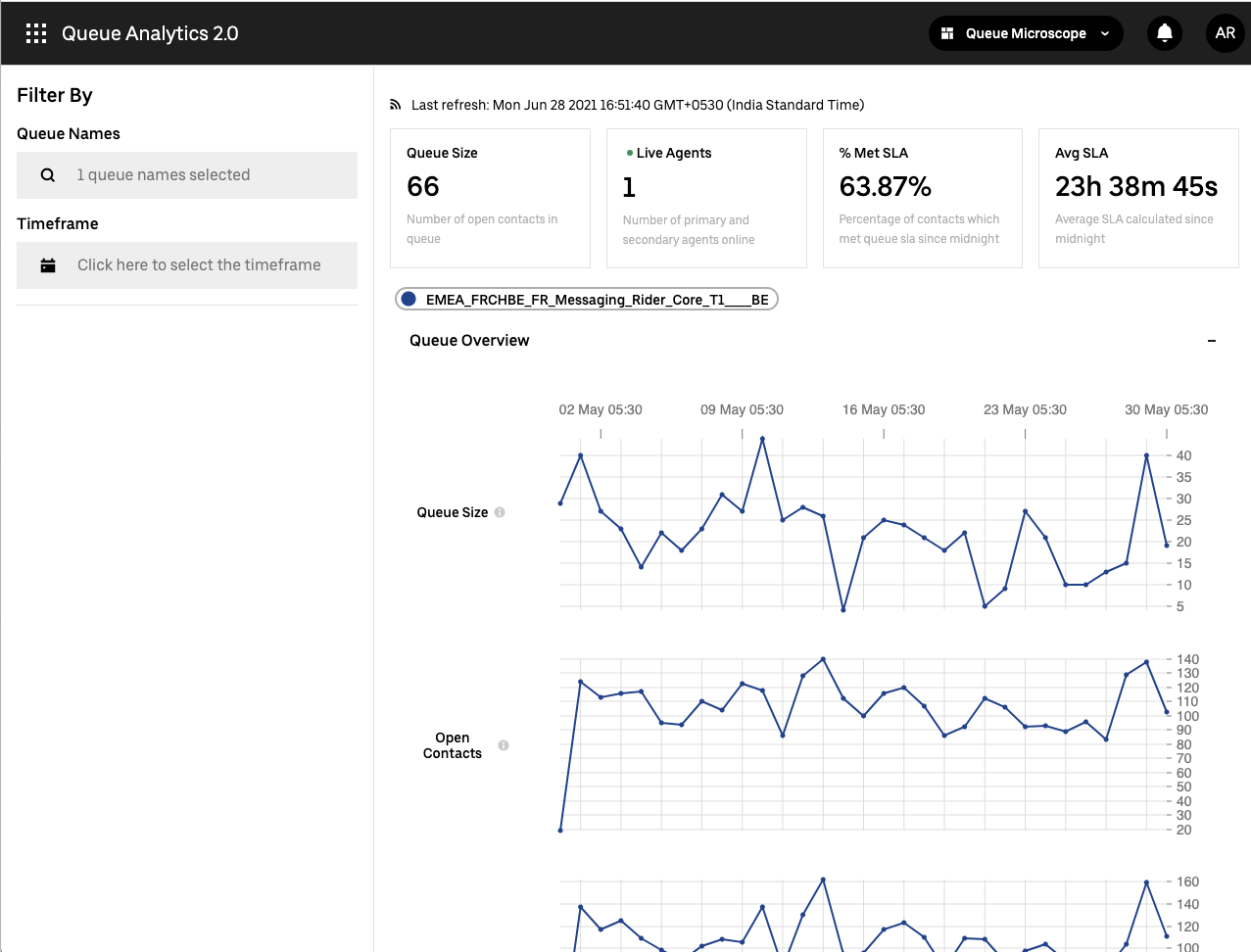
We have also migrated 70+ datasets related to customer support experiences onto our batch analytics pipelines with sufficient alerting and monitoring in place.
We are now actively expanding the capabilities of the platform with features such as:
- Alerting/monitoring infrastructure to detect and be notified of anomalies on business metrics
- Config-driven way to onboard newer metrics faster and easily
- Integrating ML pipelines for expanding the scope of the ETL data, etc.
We are also actively expanding the platform to support other use cases that address support experience improvements and product defects fixes, such as capturing end-to-end user support journeys, identifying gaps in the support experience, and surfacing real-time trends as they emerge.
If you are interested in enabling effortless digital customer care experiences across different business verticals at Uber, consider applying for a role with the Customer Obsession team. We are hiring for several roles across India and US locations.
Apache®, Apache Hive™, Apache Flink®, Apache Kafka®, Apache Spark™ and Apache Pinot™ are registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Aravind Ranganathan
Aravind is currently an Engineering Manager on the Customer Obsession team at Uber, focusing on building efficient automation experiences and improving the quality of support. He’s also led teams across various domains at Uber such as Risk and Communications Platform. He has a PhD in Computer Science and is passionate about research, teaching, and building scalable tech solutions for real-world problems.
Nimesh Agarwal
Nimesh is currently a Senior Engineer in the Customer Obsession team at Uber, focusing on building an Insights platform for the real-time analytics needs of the Customer Obsession team. He has completed his masters degree in Computer Science from IIT Delhi and is passionate about learning and building scalable antifragile distributed systems.
Pallavi Nagesharao
Pallavi is currently a Staff Engineer in the Customer Obsession team at Uber. Her focus includes data intelligence, automation, and agent experience. She has been the VP of an open source project, Apache Falcon. She has worked on a variety of technologies, from distributed computing, big data platform and applications, to ML platform and applications.