Designing a Production-Ready Kappa Architecture for Timely Data Stream Processing
At Uber, we use robust data processing systems such as Apache Flink and Apache Spark to power the streaming applications that helps us calculate up-to-date pricing, enhance driver dispatching, and fight fraud on our platform. Such solutions can process data at a massive scale in real time with exactly-once semantics, and the emergence of these systems over the past several years has unlocked an industry-wide ability to write streaming data processing applications at low latencies, a functionality previously impossible to achieve at scale.
However, since streaming systems are inherently unable to guarantee event order, they must make trade-offs in how they handle late data. Typically, streaming systems mitigate this out-of-order problem by using event-time windows and watermarking. While efficient, this strategy can cause inaccuracies by dropping any events that arrive after watermarking. To support systems that require both the low latency of a streaming pipeline and the correctness of a batch pipeline, many organizations utilize Lambda architectures, a concept first proposed by Nathan Marz.
Leveraging a Lambda architecture allows engineers to reliably backfill a streaming pipeline, but it also requires maintaining two disparate codebases, one for batch and one for streaming. While the streaming pipeline runs in real time, the batch pipeline is scheduled at a delayed interval to reprocess data for the most accurate results. While a Lambda architecture provides many benefits, it also introduces the difficulty of having to reconcile business logic across streaming and batch codebases.
To counteract these limitations, Apache Kafka’s co-creator Jay Kreps suggested using a Kappa architecture for stream processing systems. Kreps’ key idea was to replay data into a Kafka stream from a structured data source such as an Apache Hive table. This setup then simply reruns the streaming job on these replayed Kafka topics, achieving a unified codebase between both batch and streaming pipelines and production and backfill use cases.
While a lot of literature exists describing how to build a Kappa architecture, there are few use cases that describe how to successfully pull it off in production. Many guides on the topic omit discussion around performance-cost calculations that engineers need to consider when making an architectural decision, especially since Kafka and YARN clusters have limited resources.
At Uber, we designed a Kappa architecture to facilitate the backfilling of our streaming workloads using a unified codebase. This novel solution not only allows us to more seamlessly join our data sources for streaming analytics, but has also improved developer productivity. We hope readers will benefit from our lessons learned transitioning to a Kappa architecture to support Uber’s data streaming pipelines for improved matchings and calculations on our platform.
Motivation
Our pipeline for sessionizing rider experiences remains one of the largest stateful streaming use cases within Uber’s core business. We initially built it to serve low latency features for many advanced modeling use cases powering Uber’s dynamic pricing system. However, teams at Uber found multiple uses for our definition of a session beyond its original purpose, such as user experience analysis and bot detection. Data scientists, analysts, and operations managers at Uber began to use our session definition as a canonical session definition when running backwards-looking analyses over large periods of time.
The data which the streaming pipeline produced serves use cases that span dramatically different needs in terms of correctness and latency. Some teams use our sessionizing system on analytics that require second-level latency and prioritize fast calculations. At the other end of the spectrum, teams also leverage this pipeline for use cases that value correctness and completeness of data over a much longer time horizon for month-over-month business analyses as opposed to short-term coverage. We discovered that a stateful streaming pipeline without a robust backfilling strategy is ill-suited for covering such disparate use cases.
A backfill pipeline typically re-computes the data after a reasonable window of time has elapsed to account for late-arriving and out-of-order events, such as when a rider waits to rate a driver until their next Uber app session. In this instance, while the event is missed by the streaming pipeline, a backfill pipeline with a few days worth of lag can easily attribute this event to its correct session. A backfill pipeline is thus not only useful to counter delays, but also to fill minor inconsistencies and holes in data caused by the streaming pipeline.
Design considerations
Having established the need for a scalable backfilling strategy for Uber’s stateful streaming pipelines, we reviewed the current state-of-the-art techniques for building a backfilling solution.
For our first iteration of the backfill solution, we considered two approaches:
Approach 1: Replay our data into Kafka from Hive
In this strategy, we replayed old events from a structured data source such as a Hive table back into a Kafka topic and re-ran the streaming job over the replayed topic in order to regenerate the data set. While this approach requires no code change for the streaming job itself, we were required to write our own Hive-to-Kafka replayer. Writing an idempotent replayer would have been tricky, since we would have had to ensure that replayed events were replicated in the new Kafka topic in roughly the same order as they appeared in the original Kafka topic. Replaying the new backfill job with a Kafka topic input that doesn’t resemble the original’s order can cause inaccuracies with event-time windowing logic and watermarking.
Another challenge with this strategy was that, in practice, it would limit how many days’ worth of data we could effectively replay into a Kafka topic. Backfilling more than a handful of days’ worth of data (a frequent occurrence) could easily lead to replaying days’ worth of client logs and trip-level data into Uber’s Kafka self-serve infrastructure all at once, overwhelming the system’s infrastructure and causing lags.
Approach 2: Leverage a unified Dataset API in Spark
Since we chose Spark Streaming, an extension of Spark’s API for stream processing that we leverage for our stateful streaming applications, we also had the option of leveraging the Structured Streaming unified declarative API and reusing the streaming code for a backfill. In Spark’s batch mode, Structured Streaming queries ignore event-time windows and watermarking when they run a batch query against a Hive table.
While this strategy achieves maximal code reuse, it falters when trying to backfill data over long periods of time. For many of our stream processing use cases, utilizing Structured Streaming requires us to backfill data from multiple days in a single batch job, forcing us to provision jobs with excess resources that might not necessarily be available on a shared production cluster.
Additionally, many of Uber’s production pipelines currently process data from Kafka and disperse it back to Kafka sinks. Downstream applications and dedicated Elastic or Hive publishers then consume data from these sinks. Even if we could use extra resources to enable a one-shot backfill for multiple days worth of data, we would need to implement a rate-limiting mechanism for generated data to keep from overwhelming our downstream sinks and consumers who may need to align their backfills with that of our upstream pipeline.
Combined approach
We reviewed and tested these two approaches, but found neither scalable for our needs; instead, we decided to combine them by finding a way to leverage the best features of these solutions for our backfiller while mitigating their downsides.
The Apache Hive to Apache Kafka replay method (Approach 1) can run the same exact streaming pipeline with no code changes, making it very easy to use. However, this approach requires setting up one-off infrastructure resources (such as dedicated topics for each backfilled Kafka topic) and replaying weeks worth of data into our Kafka cluster. The sheer effort and impracticality of these tasks made the Hive to Kafka replay method difficult to justify implementing at scale in our stack.
Similarly, running a Spark Streaming job in a batch mode (Approach 2) instead of using the unified API presented us with resource constraint issues when backfilling data over multiple days as this strategy was likely to overwhelm downstream sinks and other systems consuming this data.
In order to synthesize both approaches into a solution that suited our needs, we chose to model our new streaming system as a Kappa architecture by modeling a Hive table as a streaming source in Spark, and thereby turning the table into an unbounded stream. Much like the Kafka source in Spark, our streaming Hive source fetches data at every trigger event from a Hive table instead of a Kafka topic. This solution offers the benefits of Approach 1 while skipping the logistical hassle of having to replay data into a temporary Kafka topic first.
This combined system also avoids overwhelming the downstream sinks like Approach 2, since we read incrementally from Hive rather than attempting a one-shot backfill. Our backfiller computes the windowed aggregations in the order in which they occur. For instance, a window w0 triggered at t0 is always computed before the window w1 triggered at t1.
Furthermore, since we’re backfilling from event streams that happened in the past, we can cram hours’ worth of data between the windows instead of seconds’ or minutes’ worth in production streaming pipelines. We backfill the dataset efficiently by specifying backfill specific trigger intervals and event-time windows.
Kappa architecture implementation
After testing our approaches, and deciding on a combination of these two methods, we settled on the following principles for building our solution:
- Switching between streaming and batch jobs should be as simple as switching out a Kafka data source with Hive in the pipeline. The solution shouldn’t necessitate any additional steps or dedicated code paths.
- Beyond switching to the Hive connector, tuning the event-time windows, and watermarketing parameters for an efficient backfill, the backfilling solution should impose no assumptions or changes to the rest of the pipeline.
- Event-time windowing operations and watermarking should work the same way in the backfill and the production job.
- The Hive connector should work equally well across streaming job types. For example, it should work equally well with stateful or stateless applications, as well as event-time windows, processing-time windows, and session windows.
Preserving the windowing and watermarking semantics of the original streaming job while running in backfill mode (the principle we outlined in the third point, above) allows us to ensure correctness by running events in the order they occur. This strategy also naturally acts as a rate limiter by backfilling the job one window at a time rather than all at once. Since we’re in backfill mode, we can control the amount of data consumed by one window, allowing us to backfill at a much faster rate than a simply re-running the job with production settings. For example, we can take one day to backfill a few day’s worth of data.
To demonstrate how we implemented this two-pronged backfill system for our Spark Streaming pipeline, we’ve modeled a simple (non-backfilled) stateful streaming job that consumes two Kafka streams. This job has event-time windows of ten seconds, which means that every time the watermark for the job advances by ten seconds, it triggers a window, and the output of each window is persisted to the internal state store.
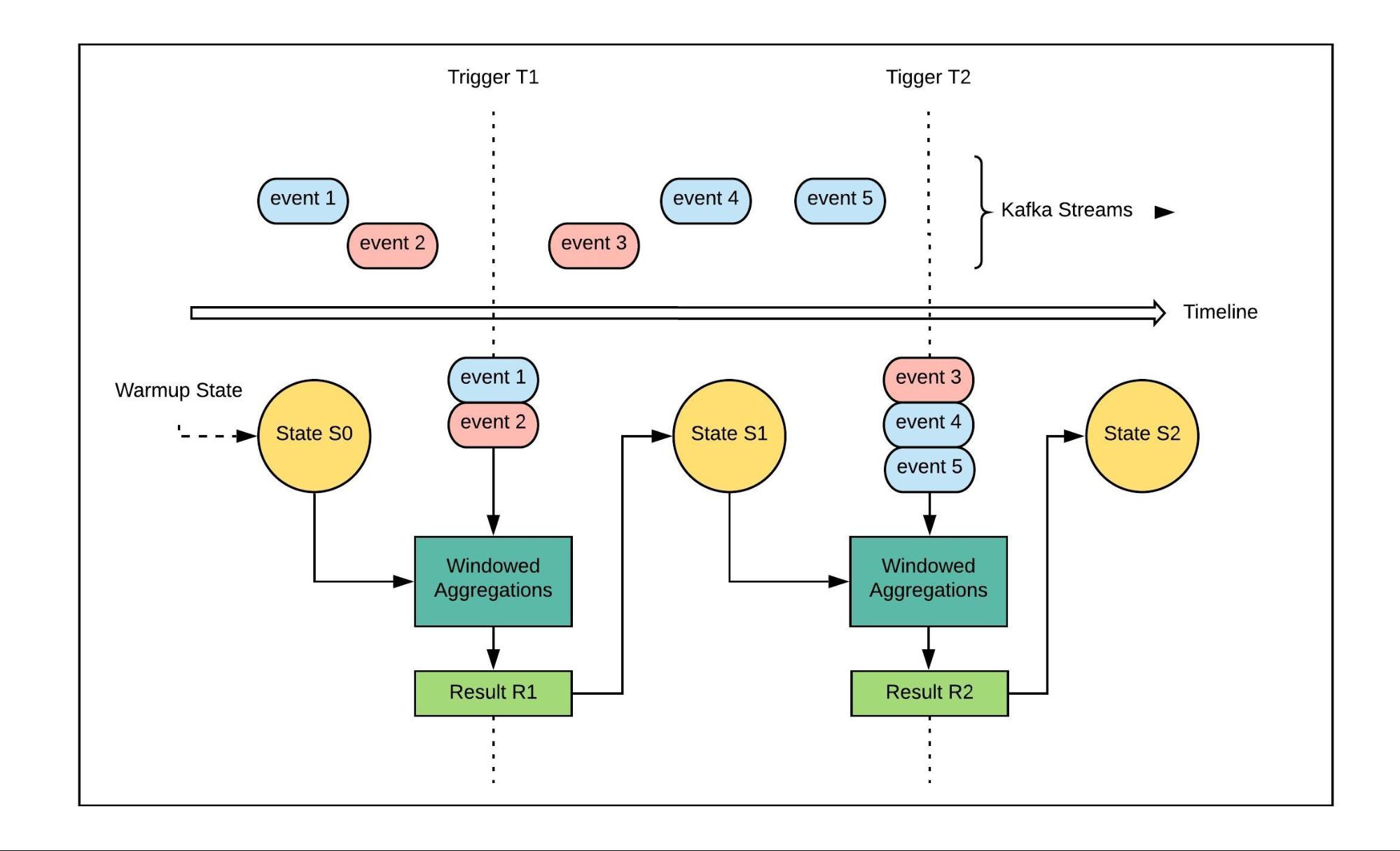
We updated the backfill system for this job by combining both approaches using the principles outlined above, resulting in the creation of our Hive connector as a streaming source using Spark’s Source API. Essentially, we wanted to replace Kafka reads with performing a Hive query within the event windows in between the triggers. While redesigning this system, we also realized that we didn’t need to query Hive every ten seconds for ten seconds worth of data, since that would have been inefficient. Instead, we relaxed our watermarking from ten seconds to two hours, so that at every trigger event, we read two hours’ worth of data from Hive.
In keeping with principle three, this feature of our system ensures that no changes are imposed on downstream pipelines except for switching to the Hive connector, tuning the event time window size, and watermarking duration for efficiency during a backfill. We implemented these changes to put the stateful streaming job in Figure 1 into backfill mode with a Hive connector. We’ve modeled these results in Figure 2, below:

When we swap out the Kafka connectors with Hive to create a backfill, we preserve the original streaming job’s state persistence, windowing, and triggering semantics keeping in line with our principles. Since we can control the amount of data read in between the triggers, we can gradually backfill multiple days’ worth of data instead of reading all the data from Hive in one go. This feature allows us to use the same production cluster configuration as the production stateful streaming job instead of throwing extra resources at the backfill job.
Comparing the two jobs, a job in production runs on 75 cores and 1.2 terabytes of memory on the YARN cluster. Our backfilling job backfills around nine days’ worth of data, which amounts to roughly 10 terabytes of data on our Hive cluster.
The future of Uber’s Kappa architecture
While designing a scalable, seamless system to backfill Uber’s streaming pipeline, we found that implementing Kappa architecture in production is easier said than done. Both of the two most common methodologies, replaying data to Kafka from Hive and backfilling as a batch job didn’t scale to our data velocity or require too many cluster resources. As a result, we found that the best approach was modeling our Hive connector as a streaming source.
We implemented this solution in Spark Streaming, but other organizations can apply the principles we discovered while designing this system to other streaming processing systems, such as Apache Flink.
If you are interested in building systems designed to handle data at scale, visit Uber’s careers page.
Amey Chaugule
Amey Chaugule is a senior software engineer on the Marketplace Experimentation team at Uber.