The Journey Towards Metric Standardization
At Uber, business metrics are vital for discovering insights about how we perform, gauging the impact of new products, and optimizing the decision making process. The use cases for metrics can range from an operations member diagnosing a fares issue at the trip level to a machine learning model for dynamic pricing that shapes a balanced and robust marketplace in real time at global scale.
When democratizing access to metrics and feeding the insights to humans and machines, we found that metric standardization was a necessity. Without metric standardization, we often observed multiple versions of metrics defined or generated in different channels for the same business logic, which could be inaccurate or misleading. As a result, downstream consumers of the metrics could come to inconsistent or poor decisions.
To solve this problem, we recently built uMetric, a unified internal metric platform that powers the full lifecycle of a metric from definition, discovery, planning, computation, and quality to consumption. So far, we’ve learned some themes that are multipliers to scale the productivity of standardization across the board: definition authoring, governance, quality, and access control management.
Case Study
The Uber Marketplace team strives to cultivate a ridesharing marketplace by facilitating the matching of riders and drivers. One of the well-known metrics to measure efficiency is the “Driver Acceptance Rate”, expressed as:
Driver Acceptance Rate = Accepted requests by DriversTotal offers to Drivers
If we improve the “Driver Acceptance Rate”, riders are more likely to experience shorter waiting times. Shorter waiting times make it more likely for Uber to be the first choice for future trips, increasing the potential for more driver earnings.
There are several factors contributing to the Driver Acceptance Rate, but the trip value factor has been increasingly important and interesting for us to learn about. It reveals a new definition for value, named Network Value: with more access to the requested trip, a driver evaluates their earnings based on the current requested trip and future potential earning opportunities.
For instance, take two trips from the same origin and suppose they have the same trip pricing: T(trip time)+D(distances). Drivers cherry-pick trip A over trip B, because they know that once they arrive at the Trip B’s destination, their future potential earnings drop compared to staying in the city, where the ratio of # of requested trips/# of available drivers is higher.

To create more earning opportunities for drivers, our teams leveraged machine learning algorithms to compute likely future earnings, incorporating real time and historical # of requested trips/# of available drivers metrics.

Metric Standardization in the Era of Data Democratization
The previous case study represents how metrics are valued and play a critical role within Uber’s ecosystem of decision making. To empower company-wide products, teams across Uber have invested in each metric layer: ingestion, computation, storage, and consumption, with the goal of eliminating barriers and enabling broader access to metrics for decision makers.
Similar to the efforts at Uber, there is also an industry trend of data democratization. Today, metric consumers have more options and unfettered access to data than ever. Meanwhile, engineers also have more flexibility to brew in-house solutions, leverage public cloud technologies, or hybridize these two for their product use cases.
While we benefited from the evolution of data democratization, we also faced one of the common challenges shared by many other companies: for the same business metric, different teams craft their own data pipelines and surface the data to individual consumption tools, which can lead to observed discrepancies between metrics. As a result, people tend to draw different conclusions based on the version of the metric they consumed.
For instance, the “Shopping Session” metric counts the number of rider sessions, and is one of the most important metrics to measure and track rider activities in the Uber mobile app. In the below two visualization tools, you can see that given the same city and time duration, the metrics shown do not line up with each other.


The issue was root caused to uncover that one of the tools (Summary) used stale filters in their static query that did not capture the latest and complete list of rider states during a session.
The problems do not end here. We found more customer pain points as we understood more user interactions with metrics, such as:
- Data users like Data Scientists, Engineers, Operations, and Product Managers all had trouble finding the desired tables and metrics.
- Unmanaged, unreliable, and inefficient computation pipelines.
- Lack of essential information (description, SLA, data sources, etc).
- Needs for systematic and comprehensive quality checking.
- Inconsistent fine-grained access control.
We boiled these down to one need: metric standardization, where a metric and the business logic have a strictly ONE to ONE mapping without ambiguities during the entire lifecycle.
uMetric
uMetric, a unified metric platform at Uber, originated from a simple idea: build engineering solutions to tackle the discrepancies in business-critical metrics. Fast forward to today, and our team has successfully built the below pillars into its ecosystem to enable the full lifecycle for a metric and extend a metric to a machine learning feature, not only for the metric standardization, but also for “metrics and machine learning features as a service.”
- Definition: Everyone can author a metric that is unambiguous and not duplicated with existing metrics.
- Discovery: Single source to search and view.
- Planner: Centralized knowledge and execution hub to generate the resource-efficient plans.
- Computation: Reliable and optimized data pipelines for batch, real-time metrics, and backfills.
- Quality: All data sources uMetric relies on and metric results are verified and monitored with one click.
- Consumption: Standardized and multifaceted access interfaces to scale the metric consumption.

For the rest of the article, we’ll share some lessons learned, highlights of technologies shipped, and ongoing engineering efforts towards metric standardization.
Less is More
You may be curious about how metric definition really works so that “everyone can author a metric which is unambiguous and not duplicated with existing metrics.”
Definition Model
The answer starts with two of the most frequent scenarios for duplicate metrics or metrics with ambiguities that we uncovered by working with 30+ teams and 10K+ metrics:
- Overwhelming metric instances per combination of slice/dice dimension and value filter, like “Completed Trips In New York,” “Completed Trips In San Francisco,” “Completed Trips Daily In San Francisco,” etc. From our observations, there can be 10X or 100X instances spinned off for a popular metric and even worse, some of their names are misleading and do not capture the complete details of the dimensions and filters.
- Obfuscating metric instances per source storage type. To accommodate the needs of freshness, latency, and time span from diversified metric consumers, the same source data is usually available in multiple storages. For example, an Operations team defines the “completed trips” metric as a Presto/Hive SQL in the last 18 months for daily dashboarding, while the Pricing Engineering team creates its own completed trips metric from a Cassandra table for real time services. Both are all valid from each team’s perspective. However, due to the nature of distinct storage types, it is non-trivial to cross-validate the consistency of two definitions regarding the business logic, dimensions, and more. Hence, they introduce one of the most complicated problems for the other teams to interpret and reuse the metrics, which ends with teams creating their own.
To solve these problems, uMetric designed and engineered the metric definition model that represents the metric logic consisting of:
- View definition, which creates the unified view for the same source data on top of tables from different storage types.
- Metric definition, which details the business logic of how a metric is calculated in SQL, such as aggregation and expression, and essential information about the metric author, primary business cases, and more.
- Dimension & Filter, which are equivalent to GROUP-BY and WHERE clauses in SQL. Their parameter values are provided by consumers during runtime API calls. Thus, uMetric offloads most of the metric instance management to the consumers while the repository of metric definitions remains lean.

The definition model forges the foundation of materializing a metric definition to either executable queries against underlying tables at runtime or batch/streaming processing jobs for precomputation in the components of Planner and Computation.
Algorithmic Dedupe
Since the view and metric are expressed as SQL statements, the metric authors often draft duplicate or similar metrics in different query formats, but really mean for one SQL semantic. Therefore, building a smart algorithmic dedupe of the equivalent SQL queries is the determining factor for uMetric given our scale.
SQL equivalence checking is proved as an NP-complete problem given its semantic as relational algebra. Based on the limitation of the SQL equivalence checking, we implemented a heuristic approach to transform the query to a canonical format and then compare the difference between queries. The transformation considered linear algebra properties such as commutative, associative, and distributive. In addition, it also flattens the SQL query to eliminate the nested query structure difference.
In Figure 7, the “new metric trip_completed_ratio” is recommended to “completed_trips / total_trips” to reuse the existing metrics.

In Figure 8, the “drafted view trip_requests” is derived as a duplicate view even though it’s a nested query which has a different structure and different alias as the “existing trip_requests” view. Our deduplication algorithm eliminates the structure difference and alias difference through the canonical transformation.

By eliminating duplicates and ambiguous metrics, uMetric makes it more productive for users to interact with metrics from discovery until consumption, but also more manageable for governance.
Governance & Guardrails
At the early stages of uMetric adoption, we prioritized top business-critical metrics like completed trips. Given their popularity, they are overwhelmingly duplicated metrics at the company for good reasons. For instance, the “completed trips” metric has often been sliced and diced on the product types (UberX, Uber Pool, etc.) to track the performance of the ridesharing marketplace. On the other hand, the Uber Eats team is more interested in the dimensions of order types (Chinese, Thai, etc.) which are not applicable for ridesharing products. The divergence continues to grow wider and more sophisticated when the complete trips metric is applied to subteams’ products (pricing, promotion, fares, …) under two organizations. Thus, it is not surprising to discover that many teams created their own data pipelines to compute the metrics.
As much as we enriched the algorithmic dedupe, there are still some questions that remain unanswered to achieve standardization:
- What is the scope of the “one business logic”? Back to the usage of the “completed_trips” metric, the teams decided to merge the driver-related dimensions to one metric given that most are identical and come from the same upstream sources.
- Which is the most production-ready data source for the metric definition, such as quality, coverage for downstream use cases, supports for real-time and batch, etc.?
- In the case where none of the data sources is qualified, what actions should be taken and who are the owners?
To address these questions, we formed Verification Committees at the organization level with individuals who possess the in-depth domain knowledge for each product line or business, and provide resolutions or connect with the product teams who can. It has been a time consuming process and requires cross-team efforts to sign off on the final plans, but is also necessary given these metrics’ impact and numerous stakeholders.
Furthermore, scaling the process to more metrics is increasingly pressing because of the limited bandwidth of committees, but also the needs of flexibility from metric authors to conduct experiments with the new metrics at the local group/team level without being reviewed by the committees.
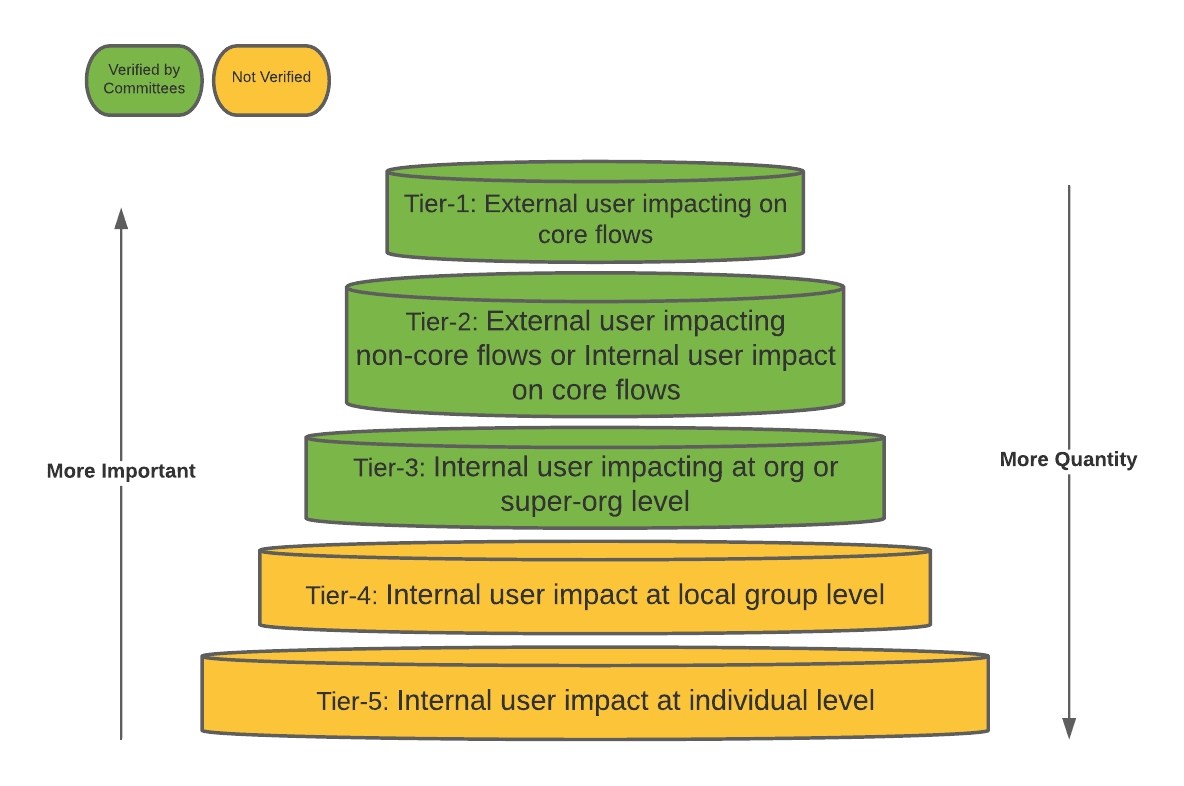
The concept of the “tiering” is introduced for this very purpose:
- Align the priority for committees and authors by differentiating what is important and what is not.
- Delegate more responsibilities and grant more permissions to metric authors to scale the standardization efforts.
Quality & Trustworthy
The quality component has been crucial for our success to earn customers’ trust on uMetric’s data by providing transparent and actionable insights into metric quality.
In particular, the upstream source quality has a direct impact on the metric quality. Once production metrics are defined on the source, its quality needs to be monitored and its owner is responsible for the triggered alerts from one or more checks of:
- Freshness tests validate that source(s) are within a certain freshness period. Source freshness describes how up-to-date the data is and its value is defined by the source owner. A metric’s freshness is derived as the MAX of all upstream sources’ freshness.
- Upstream Cross-Datacenter Consistency tests validate that source(s) data row counts between datacenters are within x% of each other. A metric’s cross-datacenter consistency is bounded by the least cross-datacenter consistent source.
- Upstream Completeness/Duplicates tests validate the metric’s source table’s completeness and duplication to ensure that the data used to compute the metric is complete and free of duplicate rows.
For a metric to meet our quality standards, each upstream source must pass all tests. The threshold of the above checks are determined by the downstream metrics as part of the process of qualification evaluation from metric authors and verification committees, but the hard work to uphold the quality falls on the source owner who is the cornerstone for the metric standardization.
Access Control
With the full lifecycle of metrics managed by uMetric, our top priority is to maintain consistency between the access control policy of upstream sources and the end consumers, including but not limited to:
- Inherit the access control policy from the sources on cluster/table/column/row levels to identify consumers with permission to the raw data.
- Propagate the inherited policy to the precomputed metric data in the storage layer.
- Enforce the policy per user/service basis with authentication during the consumption time.
For example,
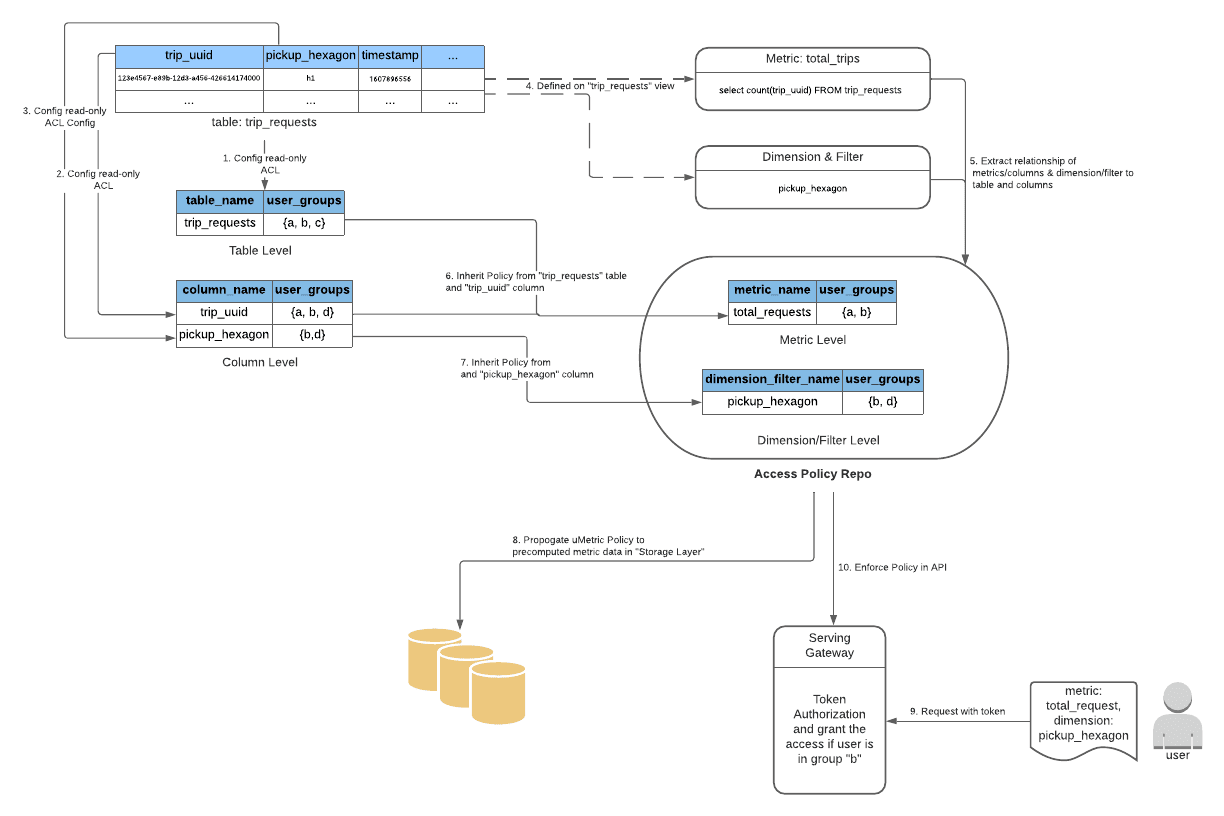
In step 5 in Figure 10, it is straightforward to connect the “total_trips” metric to both the trip_requests table and the trip_uuid column from select count(trip_uuid) FROM trip_requests. But the SQL queries for the metric definitions can be arbitrarily complex with aliases, WITHs, or JOINs, introducing challenges on matching identifiers in a SQL with a source table column.
To tackle this, uMetric builds a powerful SQL processor by leveraging Apache Calcite, which parses a SQL string into a structural tree model and then analyzes the underlying relationships between the nodes.

Future Work
The more customers we onboard, the clearer it becomes that we have shared problem spaces across organizations and products. However, there are always custom needs for each customer team. We are still at the early stages of the journey of metric standardization, but we firmly believe in and continue to invest in the main themes of definition authoring, governance, quality, and access control management. They establish a balancing structure that systemically consolidates platform efforts and initiatives into uMetric with clear expectations, engages with corresponding stakeholders, and delegates the associated responsibility to scale the standardization. If you are interested in joining the uMetric team, please apply to join our team!
Will Yu
Will is a software engineer on Uber's uMetric team and leads the development of the definition component and the federated query gateway. Previously at Uber, he worked on the walking optimization platform and scaled the platform to empower millions of trips per day.
Yun Wu
Yun is an engineer at uMetric team at Uber and leads the computation and consumption components.
Xiaodong Wang
Xiaodong is the engineering manager for uMetric team. With his leadership, uMetric is standardized as the single source of truth for business metrics and empowers machine learning features engineering Uber wide.
Wenrui Meng
Wenrui is a Senior Software Engineer at Uber working on real-time data metrics optimization.