Efficiently Managing the Supply and Demand on Uber’s Big Data Platform
With Uber’s business growth and the fast adoption of big data and AI, Big Data scaled to become our most costly infrastructure platform. To reduce operational expenses, we developed a holistic framework with 3 pillars: platform efficiency, supply, and demand (using supply to describe the hardware resources that are made available to run big data storage and compute workload, and demand to describe those workloads). In this post, we will share our work on managing supply and demand. For more details about the context of the larger initiative and improvements in platform efficiency, please refer to our earlier posts: Challenges and Opportunities to Dramatically Reduce the Cost of Uber’s Big Data, and Cost-Efficient Open Source Big Data Platform at Uber.
Supply
Given that the vast majority of Uber’s infrastructure is on-prem, we will start with some of the open technologies that we applied onsite.
Cheap and Big HDDs
While the focus of the storage market has moved from HDD to SSD considerably over the last 5 years, HDD still has a better capacity/IOPS ratio that suits the necessary workload for big data. One of the reasons is that most big data workloads are sequential scans instead of random seeks. Still, the conventional wisdom is that bigger HDDs with less IOPS/TB can negatively affect the performance of big data applications.
Our HDFS clusters at Uber have many thousands of machines, each with dozens of HDDs. At first we believed that the IOPS/TB would be an unavoidable problem, but our investigation showed that it can be mitigated.

The chart above shows the P99 and Average values of 10-min moving average of the HDD IO util% chart across thousands of HDDs from a subset of our clusters. The P99 values are pretty high, hovering around 60% with peaks above 90%. Surprisingly, we found out that the average IO util% is less than 10%!
The current machines at Uber have a mix of 2TB, 4TB, 8TB HDDs with an average disk size around 4TB. If we ever move to 16TB HDDs, the average IO util% may go up to 4x, or less than 40%. That is still OK, but what about P99? P99 will likely stay above 90% which will likely severely slow down the jobs and affect our user experiences. However, if we can load balance among the HDDs, we can potentially bring down the P99 by a lot.
So how do we balance the load on the HDDs? Here are a few ideas in our plan:
-
- Proactive Temperature Balancing: It’s possible for us to predict the temperature of each HDFS block pretty well using hints including when it was created, the location of the associated file in the HDFS directory structure, and the historical access pattern. Proactively balancing out the temperature of each HDFS block is the important first step for us to handle IOPS hotspots. This is especially important when the cluster was recently expanded, in which case new, hot blocks will be unevenly added into the new machines until we proactively perform temperature balancing.
- Read-time Balancing: Most of our files on HDFS are stored with 3 copies. In the traditional HDFS logic, NameNode will choose a random DataNode to read from. The main reasoning is that statistically, the probability of each copy getting accessed is the same. Given that the blocks are already well balanced, then it seems that the workload on each HDD should be the same. Not many people realize that while the expectation is the same, the actual workload on each HDD may have a huge variance, especially in a short time span of 2-5 seconds, which is the time needed to read a full 256MB to 512MB block, assuming 100-200MB/second sequential read speed. In fact, if we have 1000 HDDs and we try to access 1000 blocks randomly at the same time, each block is randomly chosen from the 3 copies among the 1000 nodes, then by expectation, we will leave around 37% of the HDDs without any workload, while the busiest drive might get 5 or more requests! The idea of the read-time balancing algorithm is simple: each DataNode tracks the number of open read/write block requests for each of the HDDs. The client will query all the DataNodes for how busy the HDD containing the block is, and then pick a random one among the least loaded HDDs. This can dramatically reduce contention for the small number of hotspots, and improve the P99 access latency.
- Write-time Balancing: Similar to read-time balancing, HDFS also has many choices in deciding on which DataNode and HDD to write the next block. Existing policies like round-robin or space-first don’t take into account how busy each HDD is. We propose that the IO load on each HDD should be an additional, important factor to consider as well, to minimize the variance of IO util% on the HDDs.
With these changes, we are ready to onboard the 16TB HDDs onto our HDFS fleet. The cost savings come from not only the reduced cost per TB of the 16TB HDDs, but also, more importantly, the reduced TCO (Total Cost of Ownership) due to a smaller machine fleet size and reduced power needs per TB.
For readers who know HDFS well, you might be wondering: what about HDFS Erasure Code feature in HDFS 3.0? Erasure Code dramatically reduces the number of copies of each block from 3x to around 1.5x (depending on the configuration). In fact, all of the balancing ideas above still work, although the Read-time Balancing idea becomes a bit more complex, due to the fact that Erasure Code decoding will be necessary if the blocks chosen to read include at least one parity block.
On-Prem HDFS with 3 copies is in general more expensive than the object storage offerings in the cloud for Big Data workloads. However, the move from 2TB, 4TB and 8TB HDDs to 16TB HDDs dramatically reduces the price gap, even without the Erasure Code.
Free CPU and Memory on HDFS Nodes
Thanks to the abundance of network bandwidth among our machines and racks, we moved to a disaggregated architecture where Apache® Hadoop® Distributed File System (HDFS) and Apache Hadoop YARN run on separate racks of machines. That improved the manageability of our hardware fleet, and allowed us to scale storage and compute capacity independently.
However, this architecture also leaves a good amount of free CPU and Memory on the HDFS nodes. The minimal CPU and Memory on one machine is still much larger than what is needed to run HDFS DataNode. As a result, we decided to run YARN nodemanager on those HDFS nodes to utilize the space.
So are we going back to the colocated HDFS and YARN of the old world? Not necessarily. The earlier colocated model was a requirement due to network bandwidth limitations. The new colocated model is an option. We only use it when there is an opportunity to optimize for cost. In the new colocated model, we still enjoy the independent scaling of Storage and Compute since we still buy a good number of pure Compute racks for extra YARN workloads.

Free Compute Resources without Guarantee
In the earlier post Challenges and Opportunities to Dramatically Reduce the Cost of Uber’s Big Data, we talked about the Disaster Recovery requirements where we have a second region with redundant compute capacity for Big Data. While this compute capacity is not guaranteed (e.g. in case of disaster), we can still leverage that for many use cases, like maintenance jobs that we will describe later in the demand section. Moreover, this Failover Capacity reserved for Disaster Recovery is not the only source of non-guaranteed compute resources. We were able to identify several more significant sources in Online Services:
- Failover Capacity: Similar to the Big Data Platform, our online Services and Storage platforms also have a significant amount of failover capacity reserved for disaster recovery. Unlike the huge demand for Big Data capacity however, there is not as much elasticity in the demand of Online Services and Storage, so we can re-allocate some of that failover capacity for Big Data
- Periodic Traffic Patterns: Online Services’ utilization of resources follows the pattern of our platform traffic very well. For example, weekday usage and weekend usage are very different, rush hours and midnights are different, and the annual peak of traffic is on New Year’s Eve. While Uber’s global presence reduces the variance of traffic compared to a single continent, the pattern is still obvious, which implies that we have a lot of compute resources to use when traffic is off-peak.
- Dynamically free CPUs: In order to keep a reasonably low P99 latency for RPCs, we do not want to run CPUs at over 65% since otherwise some instances of some services may randomly get overloaded and cause significant performance degradations. However, we can have some low-priority processes running in the background on those machines to harvest the free CPU cycles. When the RPC workloads spikes, the low-priority processes will be slowed down or even suspended.
It does take some effort to utilize that compute capacity for our Big Data Workload. First of all, we need to make our job schedulers work together. That’s why we started the YARN-on-Peloton project, where Peloton is Uber’s open-source cluster scheduler. This project provides the mechanism to run YARN workload on the Online Compute machines.
Once we have the mechanism, the next step is to determine what kind of workload can run in those non-guaranteed compute resources. We will discuss that further in the Demand section below.
Machine Accounting
Before we started working on the Cost Efficiency project, we were under the assumption that our focus should be on technical innovations like the 2 projects that we mentioned above. To our surprise, there is a lot of free efficiency to be gained by simply better accounting for the machines used by our Big Data Platform.
Over the years, we have accumulated a large number of deprecated systems, dev and test environments, and POC clusters that are either not used any more or over-provisioned for the current use case. This is probably the case not only for Uber but also for many fast-growing companies, where looking back to assess the machine inventory is typically a low priority.
Working on those one by one will be tedious and time consuming. Instead we designed and developed several centralized dashboards that allow us to break down the machines in our hardware fleet by many dimensions. The dashboards are powered by some common data pipelines.
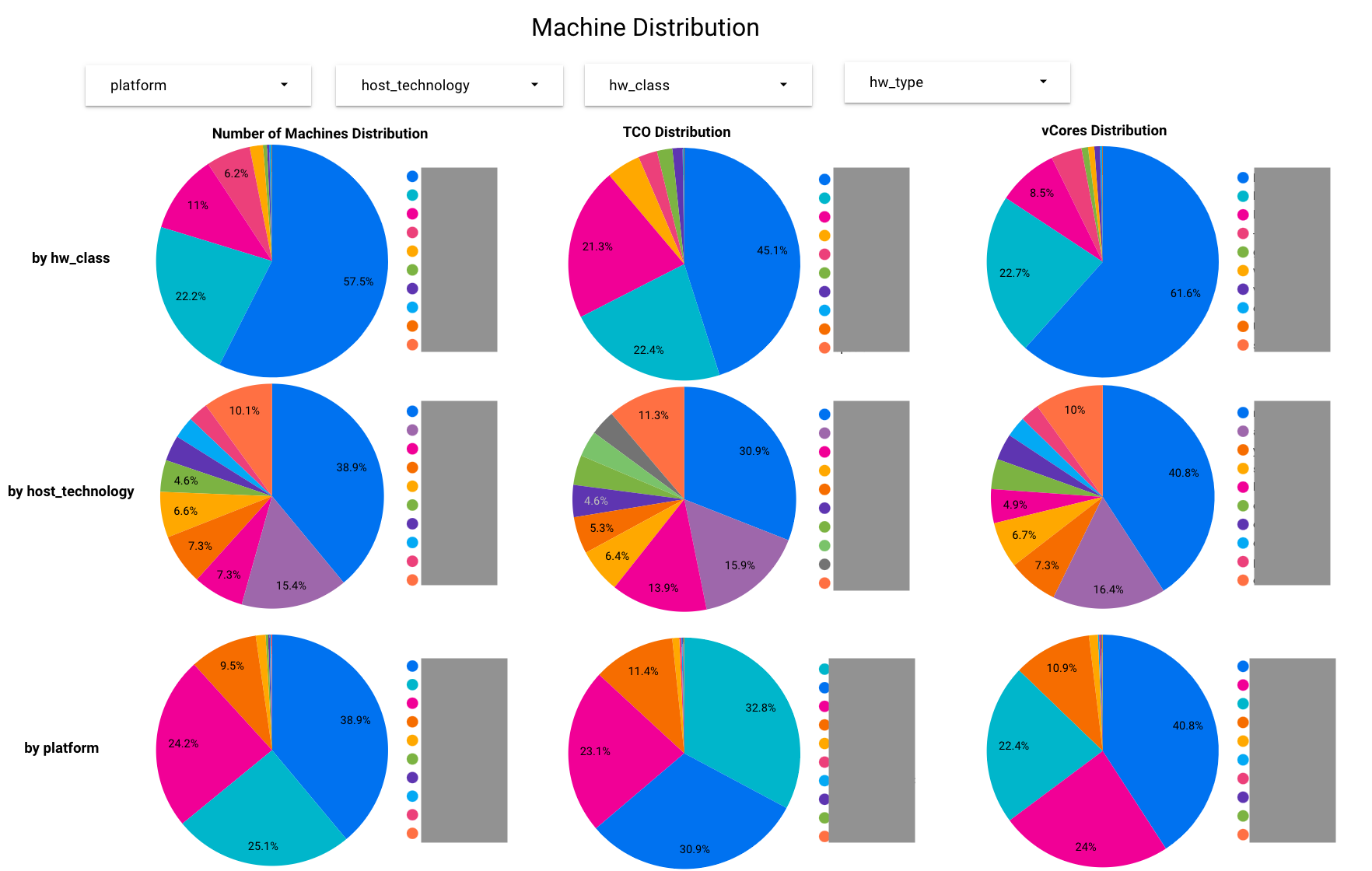
In this effort, we leveraged several open-source frameworks and cloud technologies to make it happen quickly. The result was impressive. With a set of clear dashboards, we were able to drive a good number of teams to release several thousand machines in total over 6 months.
Demand
In the last section, we covered the cost efficiency from the supply side of our Big Data Platform. However, what turned out to be more important for cost efficiency is the demand side.
That’s because many of our Big Data workloads are experimental. Users are in a constant cycle of trying out new experiments and Machine Learning models, and deprecating the old ones. To enable our users to continue to innovate as fast as possible, we need toolings that enable them to manage their demand with minimal effort.
Ownership Attribution
The first step for any demand management is to establish a strong ownership attribution mechanism for all workloads, storage and compute, on our Big Data Platform.
While this seems obvious and straightforward on the high level, it turns out to be a difficult task for several reasons:
- People change: Employees can transfer to different teams or leave the company. Organizational structures can change over time, and so it’s hard to keep all ownership information up to date.
- Lineage: The end-to-end data flow can have 10 or more steps, each of which might be owned by a different person or team. In many occasions, the ownership cannot be simply attributed to either Data Producers, Data Processors, or Data Consumers. Data Lineage gives us the end-to-end dependency graph, but we still need domain knowledge to accurately attribute the real ownership.
- Granular ownership: The same data set might need multiple ownerships for different parts. For example, a product team may want to own the log data for a specific period of time, and they are willing to have it deleted afterwards. However, another team like compliance may request the data sets to be stored for longer. Another example is a general mobile log table where many types of messages, each owned by a different team, are logged. One more example is a wide table with many columns, where different column sets are owned by different teams.
To solve these problems, we leveraged a combination of organizational charts and a home-built, hierarchical ownership tool to keep track of the owner information. We also built an end-to-end data lineage system to track the lineage information. We are right now investigating ways to allow granular ownership to data sets.
Consumption Per Business Event
Once all Big Data workloads have a clear owner, the next step is to project out the demand growth and measure whether it is above our forecast. There are several reasons for demand growth, which we categorize into 2 buckets:
- Business Event growth: Business Event here refers to Uber trips and UberEats orders. When those grow, we anticipate the big data workload to grow proportionally.
- Per Business Event growth: This is the demand growth net of the business event growth. Common reasons for this include new features, more experiments, or simply more detailed logging or more data analysis and machine learning models. We set this to a predetermined value based on historical data.
Every month, we check with each ownership group whether their usage is above the forecast. In cases where it is, we ask the owners to dig in and understand the underlying reasons. Owners can often find innovative ways to reduce their usage by leveraging their domain knowledge of their use cases. In some cases, the ownership group is too big, and they would ask us for more detailed breakdowns. That’s why we built a Data Cube for them to have full visibility into different dimensional breakdowns as they want.
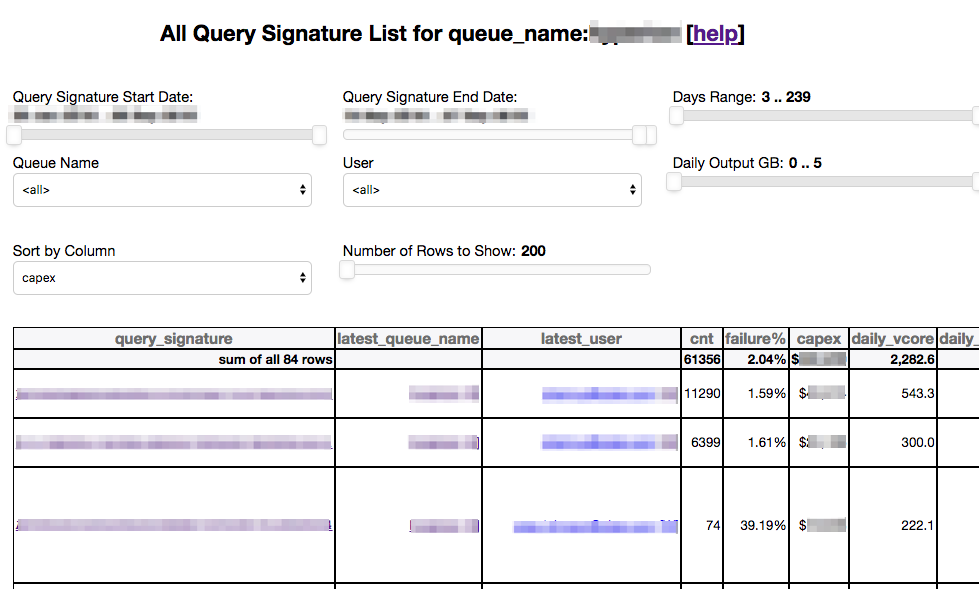
Data Cube for Understanding the Costs
Our Data Cube is defined based on sets of dimensions and of measures. Take the HDFS Usage Data Cube as an example, with the following dimensions:
- Region
- HDFS cluster
- HDFS tier
- HDFS directory
- Hive database
- Hive table
- Hive partition
And the following measures:
- Number of files
- Number of bytes
- Estimated annual cost
We built a slice-and-dice UI as shown below. Users can change the filters, the dimensions of the breakdowns, as well as the measure. This powerful and flexible tool has given users detailed visibility into where the biggest opportunities are for potential cost savings.

In addition to the Usage Data Cubes like above, we also built drill-down UIs for Queries and Pipelines. While the dimensions and measures are completely different, they serve a similar purpose for users to have a deep understanding of their workload.
Dead Datasets, Orphan Pipelines, and Beyond
In addition to the passive visualization and exploration tool above, we also proactively analyze the metadata to “guess” where the cost efficiency opportunities are.
- Dead Datasets are those datasets that nobody has read or written to in the last 180 days. These sets are often created with valid use cases, like experiments and ad hoc analysis. Owners of these tables usually want to keep them for some time, but very few people would remember to delete them when no longer needed. After all, people usually remember what they need, and forget about what they don’t need! We built a reminder system that automatically creates tasks for people to confirm if they still need the dead datasets every 90 days. In addition, we also added support for Table-Level TTL and Partition-Level TTL that will automatically delete the table or partitions of the table.
- Orphan Pipelines are ETL pipelines whose output datasets are not read by anyone (except other Orphan Pipelines) in the last 180 days. Similar to Dead Datasets, many Orphan Pipelines can be stopped with owners’ confirmations.
Next Steps and Open Challenges
The work mentioned above allowed us to save over 25% of our Big Data Spend. However, there are still a lot more opportunities. Looking forward, we are doubling down on our Big Data cost efficiency efforts in the following areas:
Supply
Cloud resources
While most of Uber’s infrastructure is on-prem, we also have some cloud presence. Cloud resources have several advantages over on-prem:
- Elasticity: It takes a lot less time for us to get additional capacity in the cloud compared to on-prem. While this may not be as important when we can predict our needs accurately, Uber’s business is affected by many external factors, like COVID-19 in early 2020, and the recovery for the foreseeable future. Elasticity will allow us to reduce the capacity buffer (and thus the cost) without risking too much into supply shortage situations.
- Flexibility: Cloud provides multiple purchase options like reserved, on-demand, spot/preemptible instances, together with many different instance types with various sizes. This gives us the flexibility to use the cheapest option that fits the workload needs.
Given Uber’s large on-prem presence, it’s not realistic to move to the cloud overnight. However, the distinct advantages of cloud and on-prem resources give us a great opportunity to utilize the strengths of both! In short, why don’t we use on-prem for the base of the workload, and use cloud for the workload above the base, like load spikes and huge ad-hoc workloads? There are open questions related to network bandwidth, latency and cost, but most of our Big Data workload is batch processing which doesn’t require sub-second latency, and network traffic in the cloud is charged in the outbound direction only.
Demand
Job Tiering and Opportunistic Computation
In a multi-tenant Big Data Platform, we have many thousands of jobs and tables. Not all of them have the same priority. However, since they are from different owners, it’s hard if not impossible for us to have them agree on the relative priority of everything.
Still, we believe it’s our responsibility to come up with a guideline for tiering of the jobs. Different tiers of jobs will have different priority in getting resources, and they will be charged differently. Combined with the Pricing Mechanism in the Platform Efficiency section, we can work out the optimization algorithm that allows us to maximize customer satisfaction with limited cost budget, or maintain customer satisfaction and reduce the cost.
From Big Data Workloads to Online Workloads
With everything discussed above and in the previous 2 posts, we are confident that we are on the right track to halve our Big Data spend in the next 2-3 years. When we reflect on our thoughts, a lot of them apply to the online workload (Online Services, Online Storages) as well. We are right now actively collaborating with our peers on Online Compute Platform and Online Storage Platform to explore those opportunities. With that, we might be able to dramatically reduce the overall infrastructure spend of Uber! Please stay tuned for future updates.
This initiative would not be possible without the contributions from over 50 colleagues in and out of Uber’s Data Platform team. We would like to thank their hard work and collaboration over the last 2 years.
Apache®, Apache Hadoop®, Apache Hive, Apache ORC, Apache Oozie, Apache TEZ, Apache Hadoop YARN, Hadoop, Kafka, Hive, YARN, TEZ, Oozie are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Mohammad Islam
Mohammad Islam is a Distinguished Engineer at Uber. He currently works within the Engineering Security organization to enhance the company's security, privacy, and compliance measures. Before his current role, he co-founded Uber’s big data platform. Mohammad is the author of an O'Reilly book on Apache Oozie and serves as a Project Management Committee (PMC) member for Apache Oozie and Tez.
Zheng Shao
Zheng Shao is a Distinguished Engineer at Uber. His focus is on big data cost efficiency as well as data infra multi-region and on-prem/cloud architecture. He is also an Apache Hadoop PMC member and an Emeritus Apache Hive PMC member.