
Background
Uber has one of the largest deployments of Apache Kafka® in the world. It empowers a large number of real-time workflows at Uber, including pub-sub message buses for passing event data from the rider and driver apps, as well as financial transaction events between the backend services. As Kafka forms a critical component of Uber’s core workflows, it is important to secure the data being published and subscribed from the topics to maintain the integrity of the data and to provide an access control mechanism for who can publish/subscribe to a given topic.
Kafka Security Concepts
Before we dive into the core architecture of Kafka security, let’s go over some basic security concepts to help in understanding the design. The two important ones are authentication (authn.) and authorization (authz.). While authn. and authz. are often used interchangeably, they are distinct and typically have independent workflows. Simply put, authn. is the process of verifying who someone is, whereas authz. is the process of verifying to what specific data a user or a service has access.
The situation is like that of an airline determining which people can board a flight. The first step is to confirm a passenger’s identity to make sure they are who they say they are. Once a passenger’s identity has been determined, the second step is verifying whether their booking is valid to board that specific flight.
Encryption
Data encryption between the clients and Kafka brokers can help prevent man-in-the-middle (MITM) attacks. Kafka supports SSL/TLS on the transport layer to enable encryption. Henceforth, we will mention TLS to convey both SSL (Secure Sockets Layer) and TLS (Transport Layer Security) as SSL is the predecessor of TLS and has now been deprecated. TLS uses secret-key cryptography with hash functions to provide encryption for data confidentiality and data integrity. Before sending actual payload data on the wire, a successful TLS handshake needs to happen. TLS uses private-key/certificate pairs during the handshake process. We will talk more about generation and management of these private keys and certificates in a later section.
Authentication
Kafka supports TLS and SASL (Simple Authentication and Security Layer) to authenticate connections from clients to brokers. TLS as mentioned above is a Transport layer protocol, whereas SASL is at a higher application layer in the networking stack. At Uber we use mTLS (mutual TLS), as it can integrate seamlessly with our PKI infrastructure (which provides X.509 certs) and also provides wire encryption (described in the above section). mTLS authenticates the identity of both clients and the brokers. This is done by enabling `ssl.client.auth=required` in the Kafka server configuration.
Authorization
For Authorization, Kafka provides an interface to implement the custom Kafka Authorizer and a default implementation that stores the policies in Apache ZooKeeper™. Kafka Authorizer defines the policies on the Cluster level resources. Authorizer takes in session information (from which client identity can be extracted), resources (such as topic, consumer group, cluster, etc.), operations (read/write/delete, etc.), looks up in its policy store if such permission is granted, and then returns true or false accordingly. When enabled, the Authorizer methods will be called for each Kafka API to grant or deny permissions to the client requests.
At Uber we have implemented this Authorizer interface to delegate authorization policies to Uber’s Identity and Access Management (IAM) framework, called Charter. The implementation class is then plugged into the Kafka Broker configuration using the property `authorizer.class.name`. We also enable another Kafka config property named `allow.everyone.if.no.acl.found`, which authorizes requests if no ACLs are found for the resource being operated on. This config is discussed further in a later section.
Security Provider
A typical way of configuring keys and certificates is via defining Keystore and Truststore as static JKS (Java KeyStore) files. The disadvantage is that the rotation and distribution of the static files is hard (and even harder with the number of hosts at Uber scale). To leverage Uber’s PKI (uPKI) infrastructure for key and certificate retrieval, we define a custom security provider. Security provider contains a mapping of an algorithm (like “uPKI”) to their corresponding key and trust manager factory implementations.
Kafka config contains parameters named `ssl.keymanager.algorithm` and `ssl.trustmanager.algorithm` to let the clients/brokers configure the algorithm as to how the key manager and the trust manager factories should be loaded. These key and trust manager factories (provided via security provider) contain custom logic for fetching the keys and certificates.
While testing out the configuration, we encountered a bug in Apache Kafka. The value of `ssl.keymanager.algorithm` param was ignored when no local `keystore.location` config was set. This prevented us from injecting our custom KeyManagerFactory. We published a fix which was merged upstream.
Another major hurdle was how to inject our custom security provider (let’s call it UPKIProvider) in JDK. UPKIProvider needs to be configured as a JVM system property for the key and trust manager algorithms to be loaded. This custom provider needs to be added along with the default JDK provided security providers in the `java.security` properties file. A trivial way to inject the UPKIProvider is to add the provider class name in the `java.security` file in the clients and broker JDK as shown below:
| # Filename: $JAVA_HOME/conf/security/java.security … security.provider.9=sun.security.smartcardio.SunPCSC security.provider.10=com.uber.kafka.UPKIProvider (Here 10 is the position of the UPKIProvider in the list of providers available with the JDK) |
However, this is not a scalable solution when considering that these changes need to be made to all the JDK static properties files on all hosts to which Kafka is deployed (which will scale out in the future). The location of the file can also change with the JDK version. A better way to deal with this is to configure the provider class via command line JVM properties. This process too is unclean, especially when configuring a cluster with a lot of hosts. This is non-scalable when multiple clients want to use the UPKIProvider for fetching the keys and certificates from the uPKI, as this JVM property should be configured in all the clients using the UPKIProvider. Last but not the least, the entry needs an index (like 10 in the above snippet) and this will break if a newer JDK version already contains this index in the `java.security` file.
To solve this, we proposed KIP-492 for adding a new Kafka property `security.provider` that takes in the UPKIProvider and adds it to the JVM programmatically. This KIP has been accepted and merged. This simplifies the changes to be limited to just the Kafka `server.properties` file, as shown below:
| # Key and Trust manager algorithms for fetching keys and certs ssl.keymanager.algorithm=UPKI ssl.trustmanager.algorithm=UPKI # inject custom UPKIProvider to retrieve key and certs from uPKI security.providers=com.uber.kafka.security.provider.UPKIProvider |
As the algorithm for Key and Trust Manager is now set to `UPKI`, the UPKIProvider’s responsibility is to connect with uPKI framework to retrieve the Key and Certificates and make them available to JVM during TLS session initialization.
Uber PKI (uPKI) Framework
uPKI is Uber’s workload identity platform that provides short-lived, auto-rotated cryptographic key pairs to services running in Uber’s production infrastructure. The motivation for building the uPKI platform primarily stems from our desire to model Uber’s production environment as a zero trust network. Zero trust networking is based on the idea that any host in the network could potentially be compromised. In the absence of trust in the network, applications require strong security primitives rooted in cryptography that allow them to establish trust with one another over potentially insecure channels. Using workload identities, backend processes can mutually authenticate one another using TLS, establishing cryptographically rooted trust across the Uber service mesh.
uPKI is built on the open source SPIFFE and SPIRE CNCF projects. Workload identities are issued from SPIRE as X.509-SVIDs, a constrained version of an X.509 certificate defined in SPIFFE, along with a private key and trust bundle. When services need to exchange data with one another, they can establish an mTLS connection using their X.509-SVIDs. Communication over an mTLS connection achieves several desirable security properties: confidentiality and integrity of data sent over the network, as well as strong authentication rooted in Uber-managed cryptographic chains of trust.
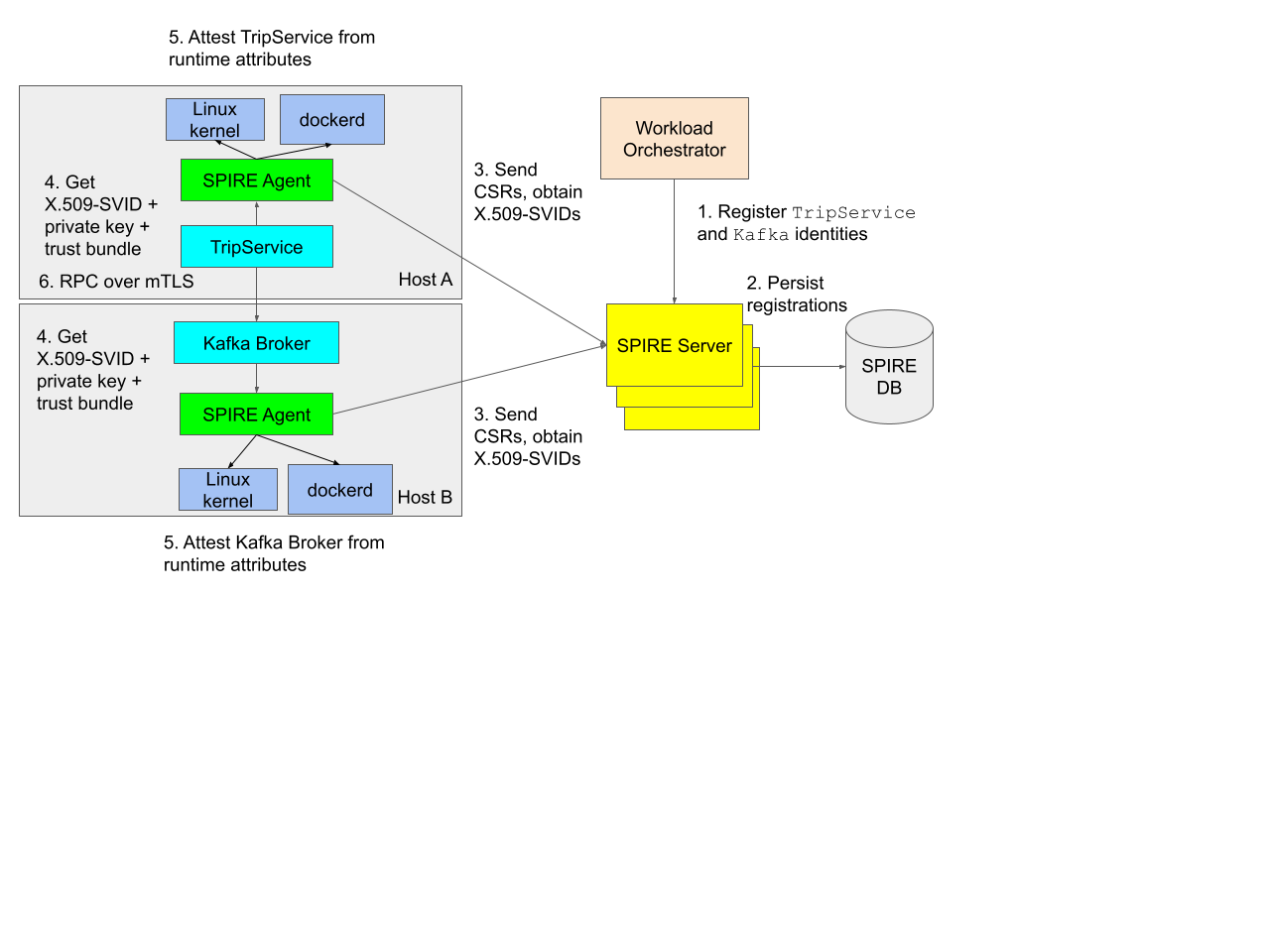
SPIRE, the identity control plane of uPKI, consists of 3 components: a server, a database, and an agent that runs on all Uber production hosts. When a workload is scheduled by an orchestrator, the orchestrator registers the workload in SPIRE (steps 1 and 2 in the diagram) with a set of known runtime selectors (e.g., Docker labels, Unix process attributes) so that the workload can be issued a unique identity on startup. SPIRE Server persists the workload’s registration in its database. Each instance of SPIRE Agent frequently requests these registrations from SPIRE Server so that it can cache them locally. SPIRE Agent also caches the X.509-SVIDs for these registrations in advance by generating an asymmetric key pair and sending CSRs (Certificate Signing Requests) to SPIRE Server (step 3 in the diagram).
Next, the workload is spawned by the orchestrator on a host. When the workload initialises, it requests an identity (step 4 in the diagram) from SPIRE Agent over a local Unix domain socket hosting the SPIFFE Workload API. The agent interrogates local trusted authorities (e.g., Linux kernel, Docker daemon) to discover runtime selectors of the workload and match those selectors against registered SPIRE identities. If the workload process’s runtime selector set is a superset of a SPIRE registration’s selector set, the SPIRE Agent grants the X.509-SVID identity for that registration to the workload (step 5 in the diagram). This process is known as workload attestation. The workload keeps its identity cached in-memory for further use.
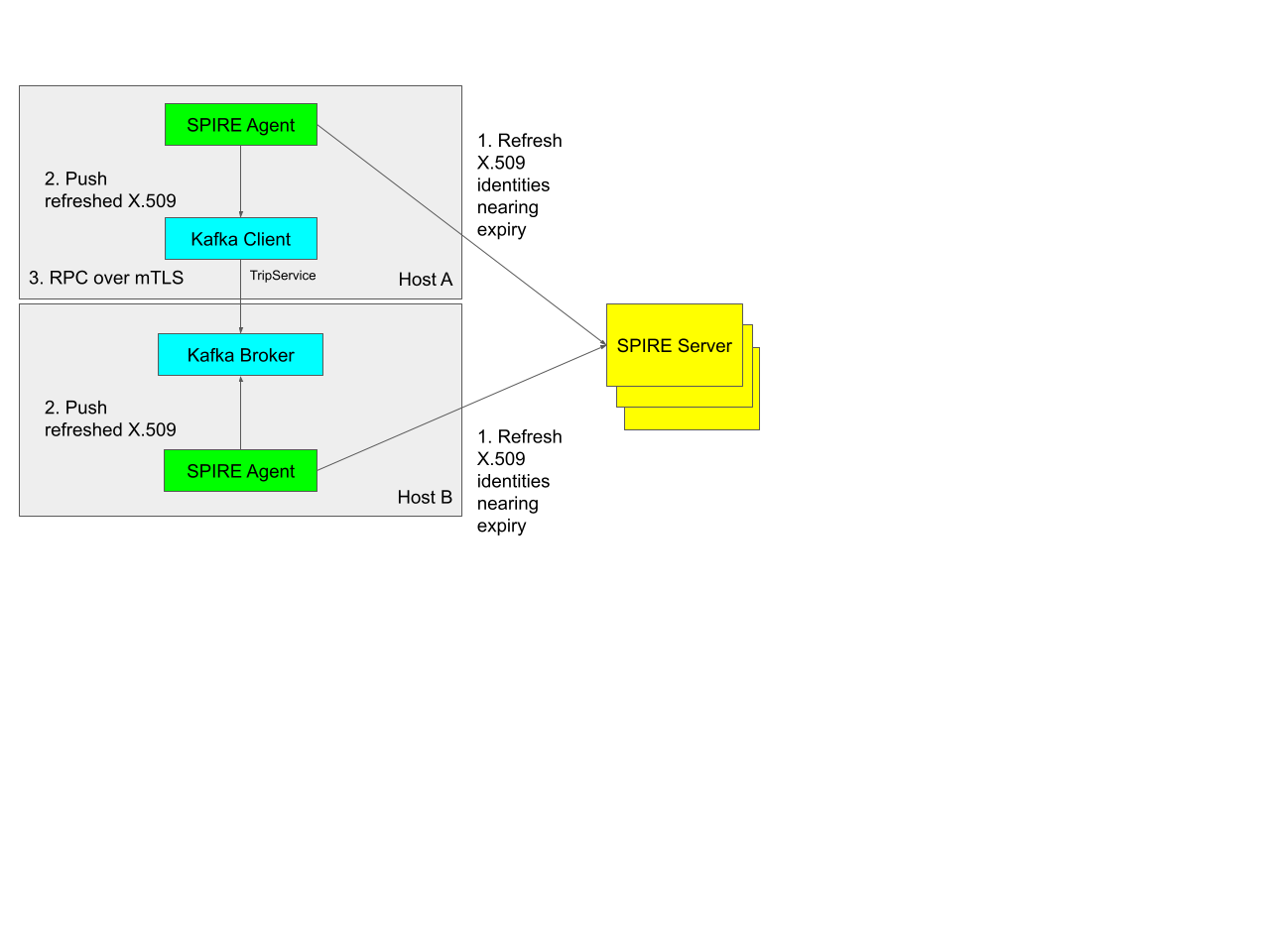
After a workload has successfully obtained its X.509-SVID from SPIRE, in the background it keeps a long-lived stream open with the local SPIRE Agent. The SPIRE Agent monitors when X.509-SVIDs it has granted are about to expire and preemptively generates a new key pair, along with sending a CSR to SPIRE Server to request a newly signed X.509-SVID. When SPIRE Agent receives the new X.509-SVID from SPIRE Server, it pushes the rotated identity over the long-lived stream it has open with the workload. The workload transparently rotates its cached identity to ensure it does not use an expired certificate. A very similar process is exercised when the trust bundle changes (i.e. new root certificate added). The automatic rotation of identities with SPIRE enables us to issue short-lived certificates to workloads, greatly minimizing the window of time that an attacker could use a compromised workload key to access Uber systems.
Kafka Principal
For authorization purposes, getting the unique identity of the client from its certificate is essential. By default, Kafka fetches the X500 Principal from the X.509 certificate during the TLS handshake and sends it to the Authorizer. This Principal is generally not a great identifier of a client as it typically consists of the client’s hostname. In a multi-tenanted environment, multiple services run on the same host so a service can’t be uniquely identified just by hostname being passed to the Authorizer.
Kafka provides brokers with an interface that can be implemented to extract the desired client ID from the SSL Session. This extracted client identity is passed to the Kafka Authorizer as an argument for authorization checks. This interface implementation can be plugged into the broker through the config `principal.builder.class`.
Charter IAM Framework
Charter is Uber’s centralized policy store managing Uber’s access control policies. Conceptually it is similar to AWS IAM, which is the central access-control system for all AWS resources. Charter provides an authorization platform for services to use for authorising any of their authorizable events.
To make an authorization decision, Charter takes 3 objects as an input:
| Actor | Generic term for an entity that is the subject of an authorization decision. In the Kafka example, the Actor value is fetched during the authentication stage after a successful TLS handshake happens. Actors are in the form of SPIFFE IDs. For example, for a service ‘TripService’, the identity provided to it could be `spiffe://upki/tripService` which will act as the Actor ID. Functionally, this is the equivalent of a java.security.Principal. |
| Resource | A resource consists of a domain and a value on which authorization is enforced. For example, for a Kafka topic ‘trips’, the resource will be named as `urn:uber:infra:kafka:topics:trips` where `urn:uber:infra:kafka:topics` is the domain and ‘trips’ is the value. Other Kafka domains could be `urn:uber:infra:kafka:clusters` and `urn:uber:infra:kafka:groups` to enforce authorizations on clusters and consumer groups respectively. |
| Operation | Action which is being attempted by the Actor on the Resource. While registering a resource domain with Charter, one can provide a list of permissible operations. For example, for the domain `topics.kafka://` available operations are `write`, `read`, `alter`, `delete` and `describe`. |
So, for example, if a client service “TripService” wants to produce a message to a topic “trips”, Kafka Authorizer will make an RPC call to Charter with the following parameters:
| {“actor”: “spiffe://upki/tripService”, “resource”: “urn:uber:infra:kafka:topics:trips”, “operation”: “write”} |
It is worthwhile to mention that the policy creation for Kafka entities (groups, topics, clusters) with security features enabled is managed independently by creating authorization policies in Charter; i.e., Charter effectively allows topic owners to create policies. As of now, however, the Kafka team manually creates policies in Charter as part of the on-call process. In the next steps section, we mention how the Kafka team plans to automate the policy creation workflow for the topic owners. Depending on Charter’s response, the client’s request is approved or rejected by the Authorizer.
Architecture
Now that we have introduced all the systems involved in the authentication and authorization flows for a produce/consume request sent to Kafka, let us put all the pieces together.
Without a loss of generality, we will run through a producer flow starting from its connection to the Kafka cluster and then successfully sending a message to a topic. Below we describe each of the steps in the flow diagram in detail.
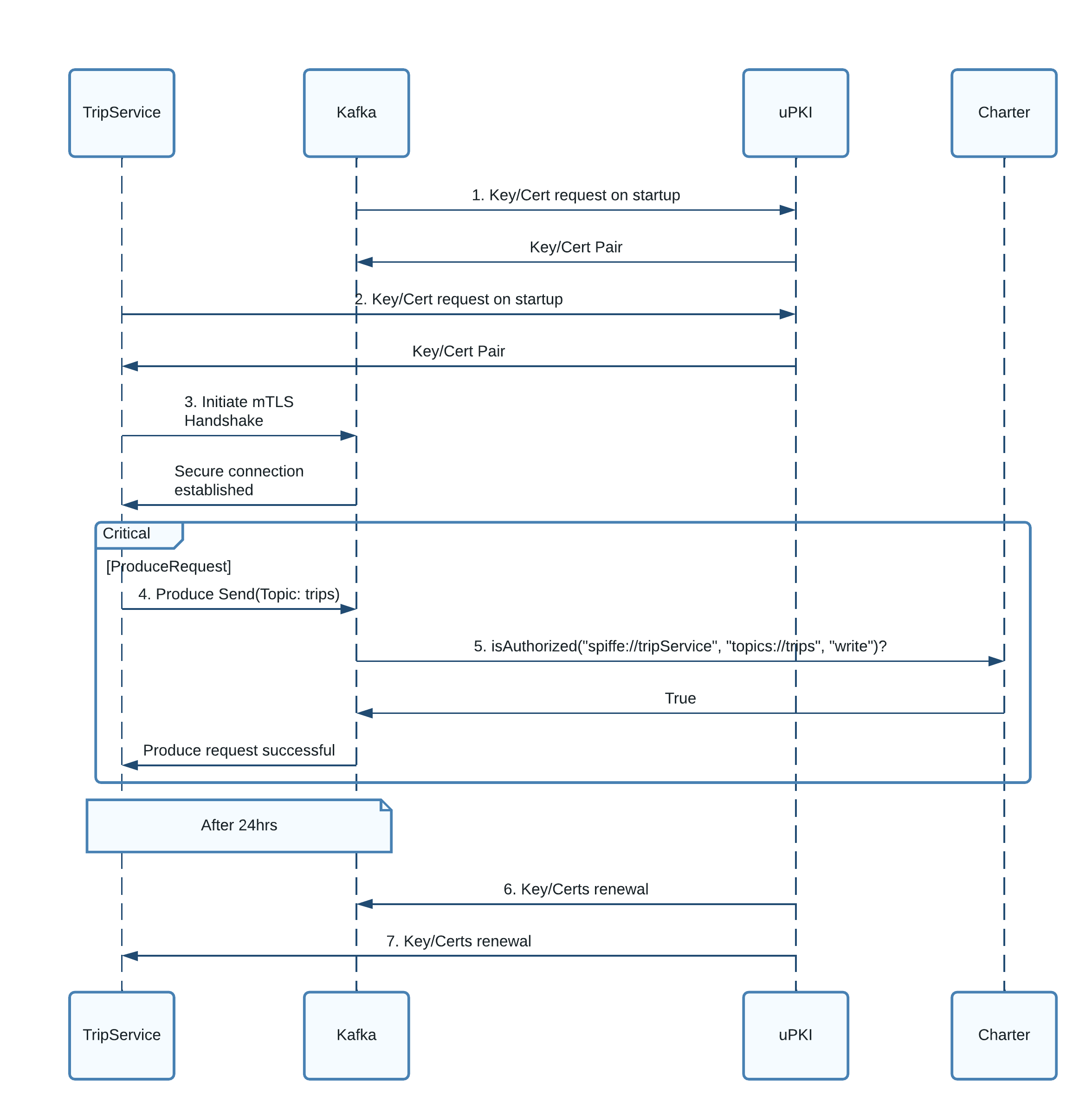
Step 1) During the startup, Kafka broker connects with uPKI via UPKIProvider and requests for a pair of X.509 Key and Certificate. uPKI validates the docker labels and userID:groupID of the Kafka process and returns back a key/cert pair on a successful validation. Kafka broker stores the pair in memory which will be used during TLS handshake with clients.
Step 2) Similar to the broker, the client also requests for a key/cert pair from uPKI. uPKI does the validation of client process workload and returns back a valid key/cert pair to the client.
Step 3) Client initiates mutual TLS connection with the Kafka broker and during the handshake, both the client and the broker present their respective TLS certificates to each other. If the cert verification is successful from both the ends, an end-to-end TLS connection is established between the client and the broker.
Step 4) During an actual produce event, the producer makes a send(topicName:“trips”, message:“trip1”)request and uses the established TLS connection to pass the request.
Step 5) Before the broker accepts the message, the request is passed through the KafkaAuthorizer. Broker calls Charter (Uber’s IAM framework) for the authorization. Broker sends the producer’s identity, the topic name and the operation “WRITE”. Charter returns back with a true / false on whether the request is authorized or not. Broker accepts or rejects the client request accordingly.
Step 6 and 7) Periodically, uPKI pushes new X.509 key cert pairs to the brokers and the clients before the TTLs of the original certs expire.
Key/Certificate Retrieval Flow
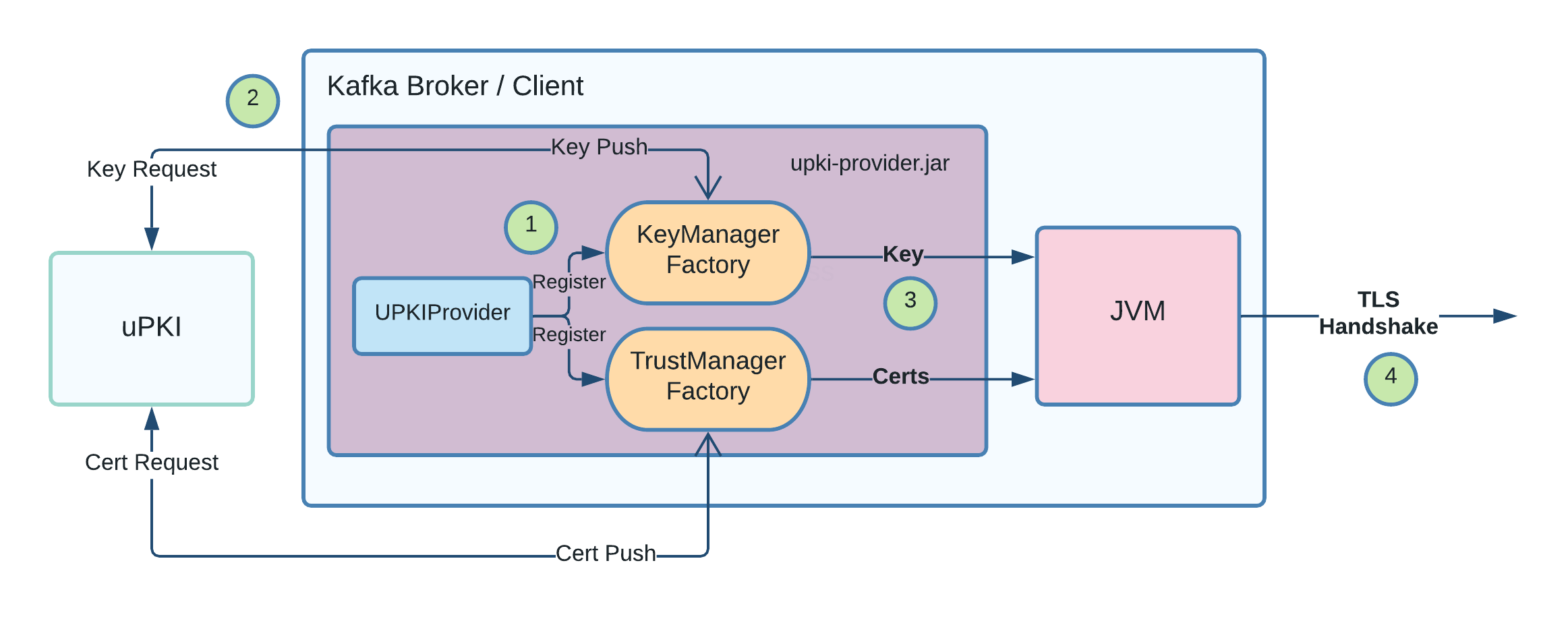
In the architecture diagram, we pointed out that the broker/client requests a Key/Cert pair and uses the received pair for the TLS handshake. In this section, we will go into more details as to how the broker/client uses the pair for the handshake.
Step 1) Kafka invokes the registered security provider (`UPKIProvider` class present in `upki-provider` jar) during startup. UPKIProvider maps UPKI algorithm with KeyManagerFactory and TrustManagerFactory classes present in the jar.
Step 2) Kafka invokes the registered classes KeyManagerFactory and TrustManagerFactory to fetch the key and certificate. The factory classes make a GRPC request to uPKI infra for the key and the certificate. After successful validation, uPKI pushes a valid set of the key and certificate back to the factory classes.
Step 3) During the TLS handshake process, JVM fetches the key and certificate stored in memory in the factory classes. Periodically, uPKI pushes renewed keys and certificates to the KeyManagerFactory and the TrustManagerFactory to keep the key and certs fresh.
Step 4) With certificate validation done from both the client and the broker, TLS handshake successfully gets completed.
Authorization Flow
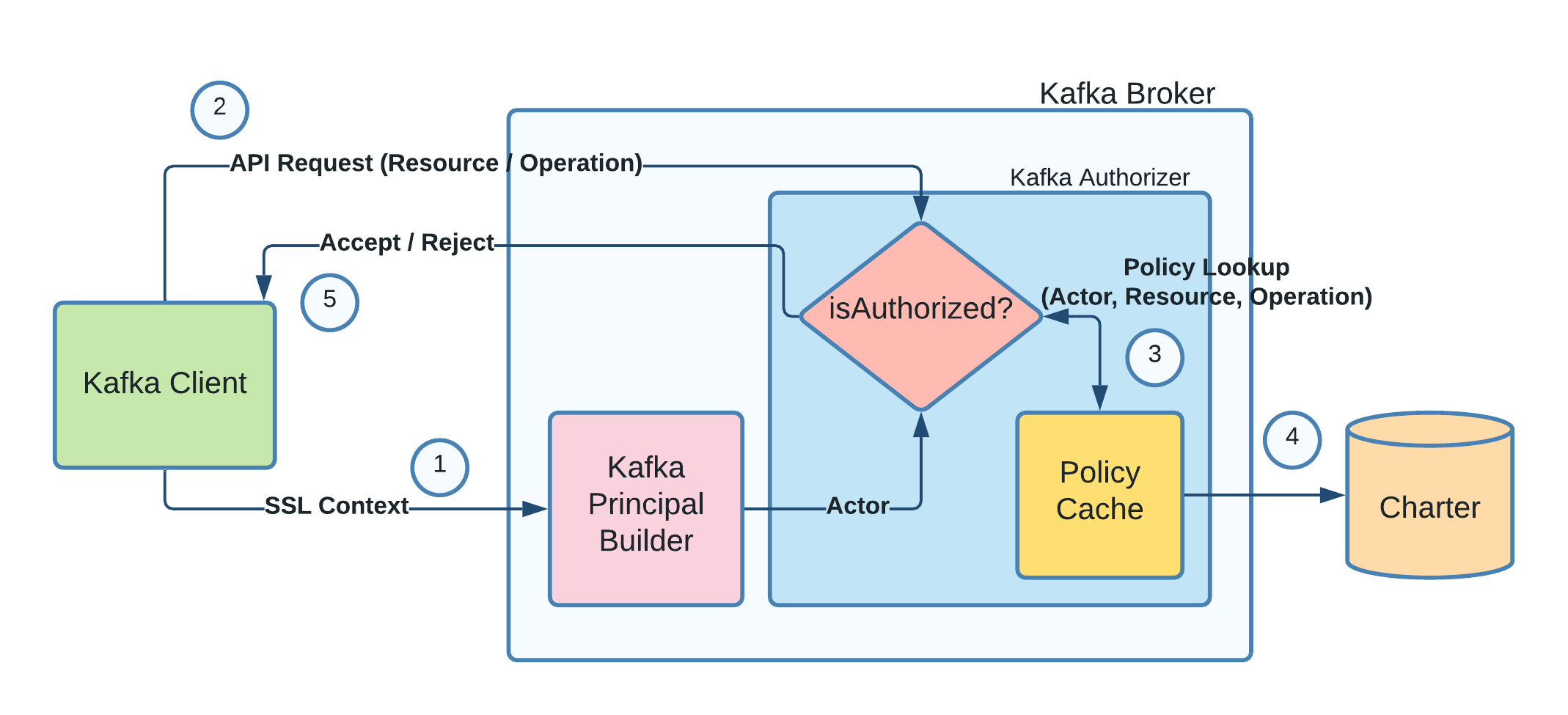
In this section, we will explain the authorization flow which takes place after a successful authentication over the following steps:
Step 1) Kafka retrieves the client’s identity from the existing SSL/TLS connection using the PrincipalBuilder Module. This identity is the Actor.
Step 2) Client makes an API request to the broker to publish a message to a particular topic. The topicname will act as the Resource and as it’s a publish request, the Operation will be WRITE.
Step 3) Kafka passes the request to the Authorizer passing the above collected information (Actor, Resource, and Operation) to perform the authorization check. Authorizer checks in its cache if there was a lookup already performed for the given params. If yes, the result is returned, else the query is sent to Charter to perform the check.
Step 4) Charter fetches applicable policies, evaluates them to return an accept/reject decision. This decision is cached via the Policy Cache module for faster lookups in future.
Step 5) The client’s API request is either processed or rejected based on the Charter decision.
Enabling Security Feature on Clusters
With the above described authorization model, enabling the security feature on existing clusters was a challenging task. Kafka clusters at Uber run as multi-tenant clusters i.e., the same clusters are used by different product teams for their topics. If the security feature is enabled on a cluster, all the topics would need to be associated with valid authorization policies, else the requests will get rejected. Adding authz policies to all topics of a cluster is hard because 1) the clients (which can range in hundreds) also need to make auth config changes, 2) not all topics are super critical to be onboarded to secure in the first iteration, and 3) not all clients are easy to track.
To make the security feature deployment smoother and safer, we decided to make changes in our authorization model. The aim was to keep the non-secure topics able to publish/subscribe even from a security feature enabled cluster without any issues. In this manner, a security feature enabled cluster will be able to host both secure and non-secure topics. To achieve this, we added an extra Kafka config “allow.everyone.if.no.acl.found” which was used in the Kafka Authorizer. This config means that the request will be allowed if and only if there is no Actor associated with the (Resource, Operation) tuple.
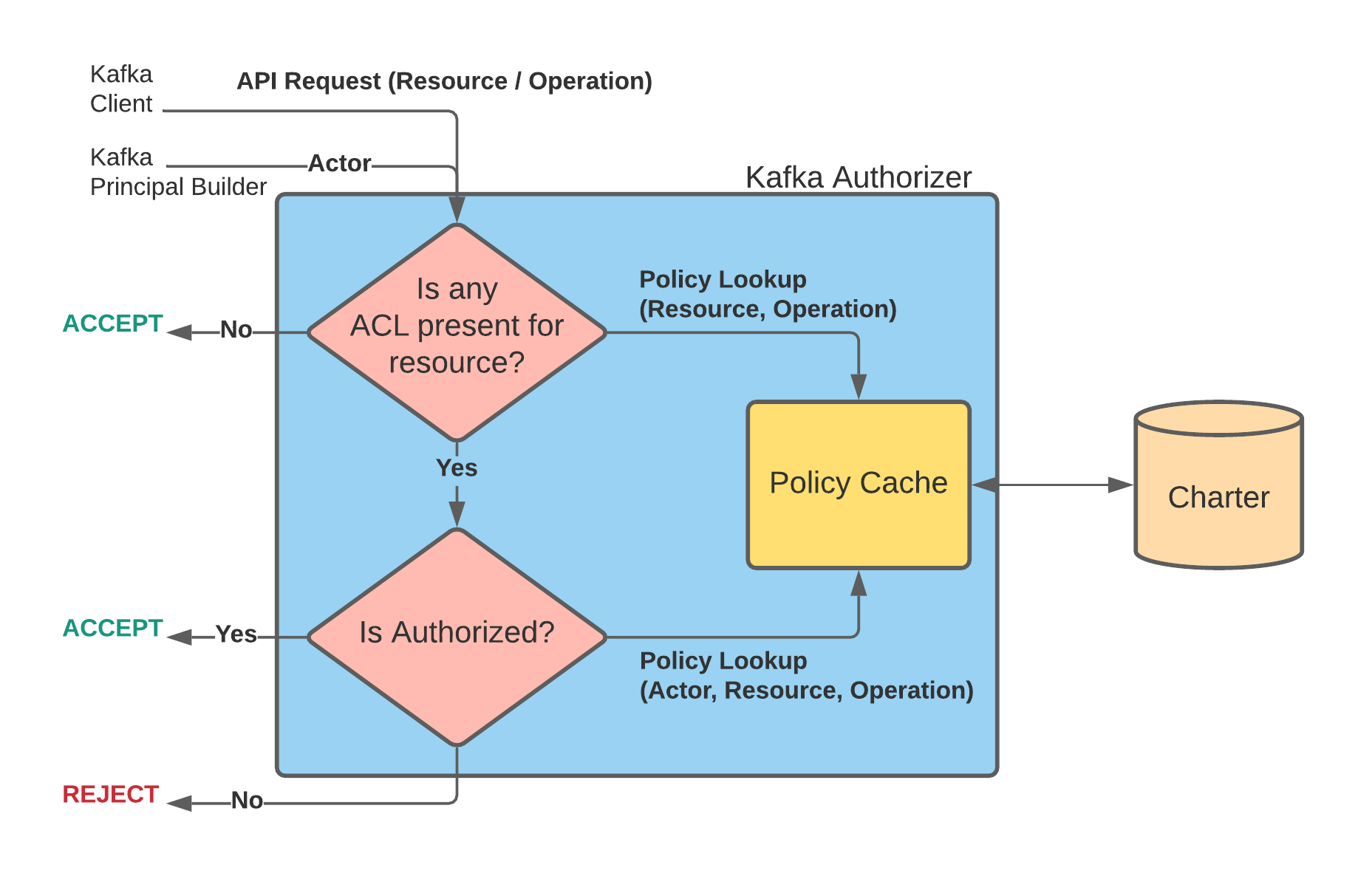
The new authorization model needs Kafka to make two Charter calls. The new flow looks like:
Step 1) Kafka Authorizer checks if there is any Actor associated with (Resource, Operation) tuple in Charter.
- YES: Authorizer carries on with the second lookup shown in Step 2.
- NO: If no Actor is associated with the tuple, the Resource is deemed to be non-secure. In this case, the request is approved.
Step 2) Kafka Authorizer makes a complete policy lookup with (Actor, Resource, Operation) params as was described in the earlier authorization model.
- YES: The request is accepted by the Authorizer and Kafka proceeds with the request.
- NO: The request is rejected.
Note that the newer model does not compromise security. Instead, the definition of a security feature enabled cluster now shifts to a secure topic, which is now hosted on a hybrid cluster (containing both secure and non-secure topics). If an Actor is associated with a particular topic in the policy store, that topic will be treated as a secure topic and no other unassociated Actor will be allowed to access that topic.
Performance and Monitoring
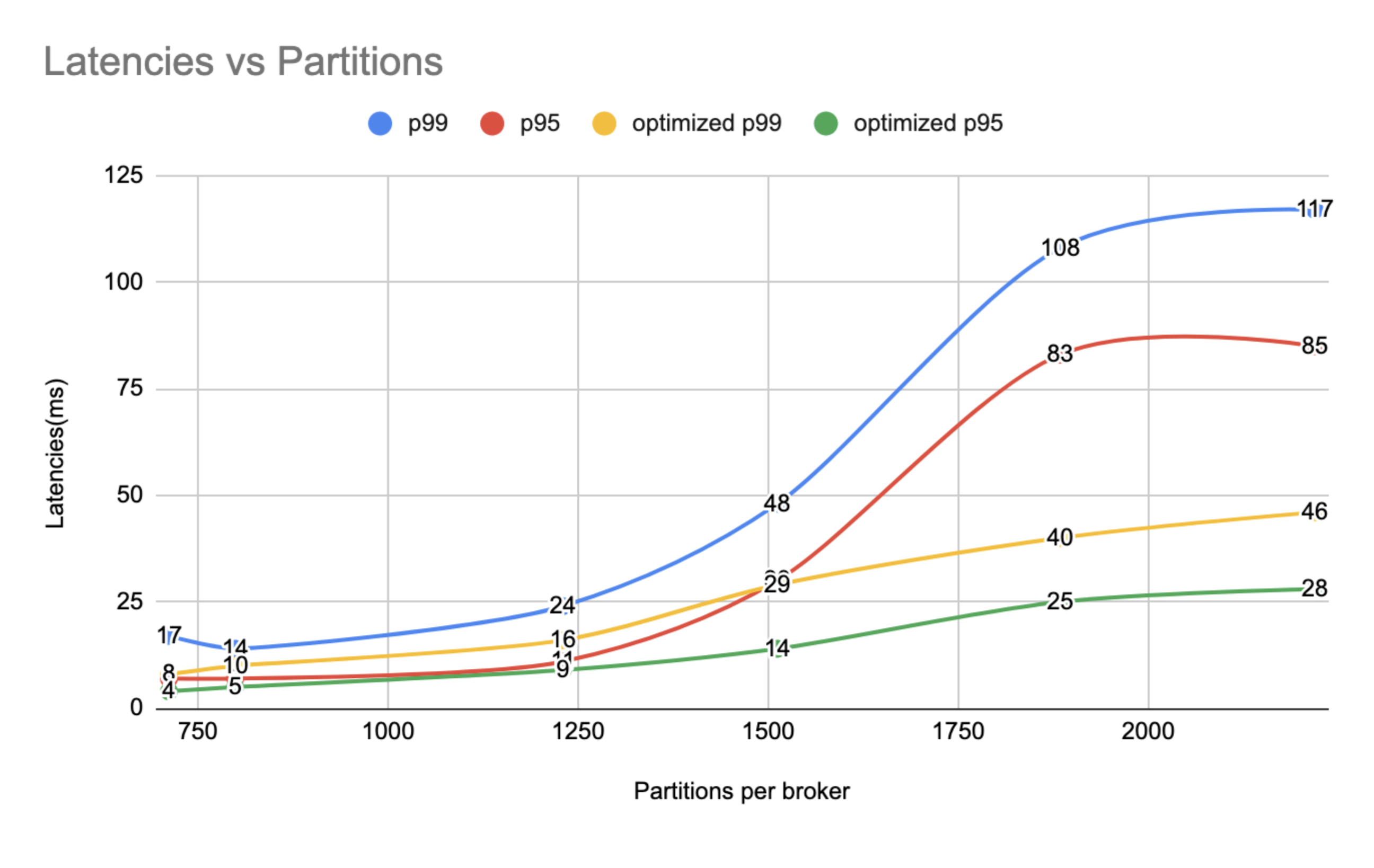
During our performance runs, we saw ~2.5X degradation in the p99 latencies when enabled security feature on the clusters. On further investigation, we discovered that Java 11 has significant SSL/TLS performance improvements over Java 8 because of faster cryptographic operation handling in Java 9+. With Java 11 onboarding and proper GC tuning, we were able to bring down the latencies significantly, as shown in the below graph. Other improvements include adding a caching layer before Charter to reduce the remote calls.
Before rolling out the security feature on our clusters on production, we made sure we had exhaustive monitoring checks in place to identify issues as soon as possible. On the authentication front, we put checks for broker certificate TTL reaching expiry, failed authentication counts, uPKI health, etc. On the authorization end, we had checks for failed authorization counts, Charter health, etc.
What’s Next
- Self-serve topic onboarding to secure: To scale with the growth of topics, we plan to delegate access policy management for a topic (with a proper auditing trail) to the corresponding Kafka topic owners.
- Security feature support for Ingestion and AthenaX pipelines: Apart from service clients, Kafka topics are also consumed by systems like Spark (using Kafka connectors) and AthenaX (using Flink Kafka clients) for ingestion to Data Lake and streaming use-cases respectively. We are working with the teams to upgrade Kafka clients to make their communication with the security enabled Kafka cluster.
Conclusion
In this blog we showed the essential components to enable security features on a Kafka cluster. We then showed how Kafka interacts with uPKI and Charter (IAM) systems together to attain security on the Kafka clusters. We discussed how we incrementally enabled security features on Kafka clusters and topics without any degradation. Finally we discussed performance tuning and the different points we monitored during the rollout so that the issues surfaced immediately. As of this blog post, we enabled security features on 500+ critical Kafka topics and counting.
If you’re interested in tackling hard problems like the one described above and more, then please apply to join the Kafka team!
Acknowledgements
Kafka Security project at Uber has been a multi-year project and wouldn’t have been possible without the efforts from these folks:
Apache®, Apache Kafka®, Apache Zookeeper™, Kafka®, and Zookeeper™ are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Image at the beginning of the article is under CC license: Reference.

Prateek Agarwal
Prateek Agarwal is a Staff Software Engineer on Uber’s Streaming Data Team. He is passionate about distributed systems, security, and automation areas. He has been working on highly available, fault resilient streaming systems, including core Kafka, Zookeeper, and Kafka ecosystem services.

Ryan Turner
Ryan Turner is a Staff Software Engineer leading Platform Authentication and Kubernetes Security initiatives and a maintainer of the SPIRE project.

KK Sriramadhesikan
KK Sriramadhesikan is a Senior Staff Security Engineer on Uber’s Security Engineering team. He leads secure authentication and authorization across Uber’s security infrastructure.
Posted by Prateek Agarwal, Ryan Turner, KK Sriramadhesikan
Related articles

How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global


Most popular

Scaling AI/ML Infrastructure at Uber

Uber Reveals 2023 “Airport of the Year” Award Winners
How LedgerStore Supports Trillions of Indexes at Uber

Uber Rider x Miami HEAT Ticket Sweepstakes OFFICIAL RULES
Products
Company