Tricks of the Trade: Tuning JVM Memory for Large-scale Services
Running queries on Uber’s data platform lets us make data-driven decisions at every level, from forecasting rider demand during high traffic events to identifying and addressing bottlenecks in the driver sign-up process. Our Apache Hadoop-based data platform ingests hundreds of petabytes of analytical data with minimum latency and stores it in a data lake built on top of the Hadoop Distributed File System (HDFS).
Our data platform leverages several open source projects (Apache Hive, Apache Presto, and Apache Spark) for both interactive and long running queries, serving the myriad needs of different teams at Uber. All of these services were built in Java or Scala and run on open source Java Virtual Machine (JVM).
Uber’s growth over the last few years exponentially increased both the volume of data and the associated access loads required to process it, resulting in much more memory consumption from services. Increased memory consumption exposed a variety of issues, including long garbage collection (GC) pauses, memory corruption, out-of-memory (OOM) exceptions, and memory leaks.
Refining this core area of our data platform ensures that decision-makers within Uber get actionable business intelligence in a timely manner, letting us deliver the best possible services for our users, whether it’s connecting riders with drivers, restaurants with delivery people, or freight shippers with carriers.
Preserving the reliability and performance of our internal data services required tuning the GC parameters and memory sizes and reducing the rate at which the system generated Java objects. Along the road, it helped us develop best practices around tuning the JVM for our scale which we hope others in the community will find useful.
What is JVM garbage collection?
The JVM runs on a local machine and functions as an operating system to the Java programs written to execute in it. It translates the instructions from its running programs into instructions and commands that run on the local operating system.
The JVM garbage collection process looks at heap memory, identifies which objects are in use and which are not, and deletes the unused objects to reclaim memory that can be leveraged for other purposes. The JVM heap consists of smaller parts or generations: Young Generation, Old Generation, and Permanent Generation.
The Young Generation is where all new objects are allocated and aged, meaning their time in existence is monitored. When the Young Generation fills up, using its entire allocated memory, a minor garbage collection occurs. All minor garbage collections are “Stop the World” events, meaning that the JVM stops all application threads until the operation completes.
The Old Generation is used to store long-surviving objects. Typically, a threshold is set for each Young Generation object, and when that age is met, the object gets moved to the Old Generation. Eventually, the Old Generation needs a major garbage collection, which can be either a full or partial “Stop the World” event depending on the type of garbage collection configured in the JVM program arguments.
The Permanent Generation stores classes or interned character strings. It is not for objects that survived from the Old Generation to stay permanently. If this area is about to be full, there will be a GC, which is still counted as a major GC.
The JVM garbage collectors include traditional ones like Serial GC, Parallel GC, Concurrent Mark Sweep (CMS) GC, Garbage First Garbage Collector (G1 GC), and several new ones like Zing/C4, Shenandoah, and ZGC.
The process of collecting garbage typically includes marking, sweeping, and compacting phases, but there can be exceptions for different collectors. Serial GC is a rudimentary garbage collector, which stops the application for the whole collecting process and collects garbage in a serial manner. Parallel GC does all the steps in a multi-threaded manner, increasing the collecting throughput. CMS GC attempts to minimize the pauses by doing most of the garbage collection work concurrently with the application threads. The G1 GC collector is a parallel, concurrent, and incrementally compacting low-pause garbage collector.
With these traditional garbage collectors, the GC pause time usually increases when the JVM heap size is increased. This problem is more severe in large-scale services because they usually need to have a large heap, e.g., several hundreds of gigabytes.
The new garbage collectors like Zing/C4, Shenandoah, and ZGC try to solve this problem, minimizing the pauses by running the collecting phases concurrently and incrementally more frequently than traditional collectors. Also, the pause time doesn’t increase as the heap size goes up, which is desirable for large scale services within a data infrastructure.
In addition to garbage collectors, the object creation rate also impacts the frequency and duration of GC pauses. Here, the object creation rate defines how many objects with size in bytes are created for a given time range in seconds. It is easy to understand that when the rate goes higher, more objects are created and occupy the heap, triggering the GC more frequently and causing longer pauses.
In our experience with garbage collection on JVM, we’ve identified five key takeaways for other practitioners to leverage when working with such systems at Uber-scale.
Tune HDFS NameNode memory and garbage collection
At Uber, we use HDFS, which runs on commodity hardware with high fault-tolerance and throughput, for data analysis, storage, and infrastructure. For instance, HDFS powers our business intelligence, machine learning, fraud detection, and other activities that require fast access to anonymized business data.
HDFS’ primary/replicated architecture means that an HDFS cluster consists of worker nodes and a single active master server, the NameNode, the core of an HDFS cluster. The NameNode tracks the cluster’s metadata and health information in its memory. For example, we load the metadata of each file and directory in the cluster into NameNode memory at runtime. NameNode also maps block replicas to the machine list.
As the number of files and worker nodes increases, NameNode uses more memory. In addition, NameNode is responsible for handling file operations requests, which also consume memory for storing intermediate Java objects. Given all its activities, NameNode requires a tremendous amount of memory, which could reach more than 200 gigabytes in some of our clusters.
Because the active master NameNode cannot be horizontally scaled out, it is a centralized bottleneck in the cluster for all requests. Uber implemented a variety of initiatives to scale up our HDFS cluster to accommodate the growth in our data and requests, including using Hadoop’s View File System (ViewFs), upgrading HDFS, controlling the number of small files, using Observer NameNode, creating the NameNode Federation, and performing GC tuning. However, all of these initiatives only relieved the scale challenge. When we started this project, NameNode was still a bottleneck to scale out the HDFS cluster.
GC tuning is a process of optimizing GC parameters and heap generation sizes to fit the runtime usage of JVM memory, and has proven itself an effective way to reduce NameNode pause time, which in turn decreases request latency and increases throughput.
NameNode Concurrent Mark Sweep GC tuning
In an earlier article, we discussed our first GC tuning effort. After that effort, we performed the second round of GC tuning and experimented with a new GC method, Continuous Concurrently Compacting Collection (C4), a component of Azul System’s Zing JVM.
In the GC log, we found numerous long minor GC pauses (>100 milliseconds), and some even longer pauses (greater than 1 second). This finding surprised us because JVM’s heap design is supposed to make minor GC pauses negligible, lasting well under the amounts of time we were seeing. These breaks in service slow down HDFS RPC queue request time, a typical measurement of HDFS performance, and end-to-end latencies. These issues indicated that the JVM’s memory settings and GC parameters were not optimized and needed to be tuned.
Young Generation heap tuning
Our NameNode uses CMS as the JVM Old Generation GC, while the Young Generation uses ParNew, a “Stop the World” collector. As memory consumption increases, we observe objects filling up the heaps for both the Old and Young Generations. Sometimes we note more frequent GC occurrences with greater memory usage. If we see the heaps getting too large and GC occurring often, the common practice is to increase the heap size.
Several months before this GC tuning effort, we increased the total heap size from 120 to 160 gigabytes to accommodate the increasing memory demand. However, all other parameters, such as the Young Generation, remained unchanged. Afterwards, we noticed the GC time increased, particularly in the Young Generation.
Based on the charts of the GC logs produced by GCViewer, shown in Figure 1, below, we found that ParNew GC was the main contributor to GC pauses, with the average ParNew GC time increased by about 35 percent after we raised the total heap size. This result indicated that we should start with Young Generation GC tuning first to achieve the greatest improvement.
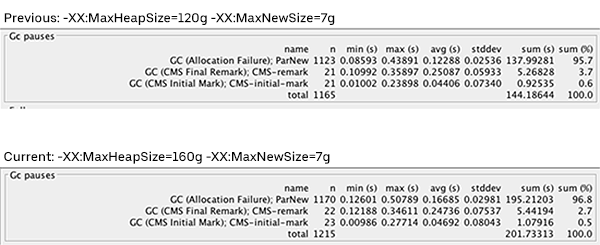
We hypothesized that increasing the Old Generation’s heap size was impacting ParNew performance. In order to test out this idea, we tested different heap allocations between the Old Generation and Eden space, part of the Young Generation. We tried a 50 gigabyte heap total with 6 gigabytes allocated to Eden space versus a 160 gigabyte heap total with 6 gigabytes allocated to Eden space. These assessments verified that ParNew GC time increases significantly when the Old Generation size increases.
We suspected that the reason the Young Generation GC increases when the Old Generation’s heap size increases is because the system has to scan the Old Generation for live object references. Based on this theory, we tried out different Young Generation sizes and parameters, such as -XX:ParGCCardsPerStrideChunk, to improve ParNew GC speed. ParGCCardsPerStrideChunk controls the granularity of tasks distributed between worker threads that find references from the Old Generation for the Young Generation. The chunk size could impact the GC performance if it is not set correctly.
Since it’s difficult to replicate our production filesystem for testing, we designed our testing based on the NameNode traffic pattern. For example, listStatus, contentSummary, and write operations generate more memory stress than other filesystem operations, so the test focused on using those three operations. To create a high volume of operations, we used large Apache Spark jobs in our production cluster, which can generate a high volume of file system operations on the testing NameNode.
We tested three sets of parameters on our replicated system, as shown below:
- Current JVM setting: -Xmx160g -Xmn7.4g
- Current JVM setting: -Xmx160g -Xmn7.4g -XX:ParGCCardsPerStrideChunk=32k
- Increase Young Generation to 16 gigabytes: -Xmx160g -Xmn16g -XX:ParGCCardsPerStrideChunk=32k
The charts in Figure 2, below, compare three different sets of parameters’ effects on the NameNode’s RPC queue average time and their GC time/count.

These assessments demonstrated that our third parameter generated the best performance: RPCQueueTimeAvgTime dropped from over 500 milliseconds to 400 milliseconds, RPCQueueTimeNumOps increased from 8,000 to 12,000, max GC Time dropped from 22 seconds to 1.5 seconds, and max GC count dropped from 90 to 70. We also tried increasing the Young Generation to 32 gigabytes, but we saw much worse performance, so did not include that result in Figure 2.
Further, we can conclude that the Young Generation size needs to be increased when the total heap size is increased. Otherwise, the JVM cannot perform well in terms of GC, negatively impacting HDFS performance.
Old Generation heap tuning
One important parameter in Old Generation heap settings is CMSInitiatingOccupancyFraction, which sets a threshold above which the next garbage collection will be triggered. The occupancy fraction is defined as the occupancy percentage of the Old Generation heap.
This value was set at 40 before this GC tuning effort started. We took a sample of this parameter’s GC log to see if there was room to optimize it.
Figure 3, below, shows the Old Generation growth rate (the increase rate of size in bytes) between the initial mark and final remark phases of the CMS GC marking process. During a one hour time range, the accumulated growth in the Old Generation was about 4 gigabytes. Given our Old Generation uses 107 gigabytes out of the total 160, a ratio of 107/160 (67 percent). Supposing there is no Old Generation GC, one hour growth, which includes the 4 gigabyte Old Generation growth, will reach a ratio of 111/160 (69 percent).

GCViewer shows the statistics, in Figure 4, below, over the same hour:

We could increase the CMSInitiatingOccupancyFraction parameter a little bit, but doing so may run the risk of lengthening the marking pause, one phase of garbage collection. As the CMS didn’t take much pause time (3.2 percent of total pause time) in this configuration, we can keep it as it is.
CMSInitiatingOccupancyFraction,an important GC parameter, impacts the frequency of GC occuring and the duration of each individual GC. To find its most performant setting, we need to analyze two GC statistics, the Old Generation growth rate and the percentage of Old Generation GC pause time. In our case, we didn’t see much room to optimize this parameter so left it as is.
Other parameters we evaluated
Beyond the above GC parameters we evaluated, there are several others that could impact GC performance, such as TLABSize and ConcGCThreads.
We evaluated TLABSize to see if the size of the buffer could impact GC performance. TLAB stands for Thread Local Allocation Buffer, which is a region inside the Young Generation’s Eden space that is exclusively assigned to a thread to avoid resource-intensive operations such as thread synchronization. The size of TLAB is configured by the parameter TLABSize.
Java Flight Recorder, a tool for collecting diagnostic data about a running Java application, shows JVM’s automatic TLAB resizing works well in Figure 5, below. NameNode does not generate a high volume of large objects by default and its waste rate is just around 1.1 percent, so we keep the default setting.

We also evaluated the parameter ConcGCThreads, which defines the number of threads that GCs will use concurrently, to see if the concurrency of GC threads would impact the GC performance. The larger the size of this parameter, the faster the concurrent collection finishes. However, given that the amount of CPUs are fixed on a host, a larger ConcGCThreads input number means that fewer threads will work on users’ applications. We tested this parameter by increasing from JVM’s default six threads to 12 and then 24 threads. We didn’t notice any improvement on RPC queue average time, so we kept the original setting.
During this second round of GC tuning we learned that in order to improve performance, we need to constantly monitor filesystem changes, understand the NameNode process’ characteristics, and tune parameters based on them, which are more effective than testing each of the voluminous JVM parameters.
Experimenting with C4 garbage collection
Following our second round of GC tuning on NameNode described above, the increase in data spurred by Uber’s growth added further pressure on NameNode memory. G1 GC, a low pause garbage collector, has become the default garbage collector in Java version 9, which is widely used at Uber. We tested G1 GC by mimicking our production load, but we observed that it uses significantly large off-heap memory. For example, with 200 gigabytes of JVM reserved heap memory in NameNode, G1 GC needs approximately another 150 gigabytes of off-heap memory, and still did not perform as well as CMS.
Among newer GC methods that claim to have minimal GC pauses, we decided to take a look at Zing/C4. Zing is the name of Azul Technologies’ JVM and C4, which stands for Continuous Concurrently Compacting Collection, is its default garbage collector.
This GC seemed promising for our needs because it can support substantial heap sizes (we tested as large as 650 gigabytes) without significant GC pauses (most were less than 3 milliseconds). Minimizing GC pauses for large heap sizes is a great benefit to NameNode performance because HDFS NameNode requires a large heap size.
To achieve its goal of minimizing pause duration, C4 runs its GC threads concurrently with application threads. (More details can be found in Azul’s white paper on C4).
Through our evaluation, we focused mostly on NameNode’s key metric, RPC queue latency. In our tests, C4 beat CMS by about 30 percent on hardware with a 40-core CPU and 256 gigabytes of physical memory, as shown in Figure 6, below:
We used Dynamometer, a tool that emulates the performance characteristics of an HDFS cluster with thousands of nodes using less than 5 percent of the hardware needed in production, and conducted our evaluation by replaying our production traffic against the target NameNode, configured with 200 gigabytes reserved for the JVM’s heap size, and actual heap usage of about 150 gigabytes.
In addition, Zing can handle very large heap management in situations when CMS and G1 GC completely fail. We tried these GCs on heap spaces of around 300 and 450 gigabytes by doubling or tripling all INodes, representing files and directories, in NameNode. CMS had a difficult time even starting the NameNode process, while Zing handled it well.
Of note, Zing performed particularly well on machines with more powerful CPUs or more cores in our testing. In these hardware configurations, its GC threads ran faster and generated better application performance as a result.
Despite its many advantages, one caveat about C4 is that this GC uses more off-heap memory than CMS. For servers already suffering from low memory space, an administrator would need to make more room before adopting C4 to avoid out-of-memory exceptions.
Overall, C4 delivered promising results, a 29 percent drop in latency from ~24 milliseconds to ~17 milliseconds compared with CMS. Moreover, the GC pause time won’t increase when using a larger heap size, which is an advantage compared to traditional garbage collectors. Although we found that C4 uses more off-heap memory, its performance advantages were very encouraging and we’d recommend this solution to other teams searching for JVM optimization solutions..
Reduce Hive Metastore latency by optimizing JVM memory usage
In addition to HDFS NameNode memory challenges, Apache Hive, another large-scale service within our data platform, can also experience memory issues. Hive provides a SQL-like interface to query data stored in a data lake. Hive Metastore, one of two major components in Hive, stores all the metadata for the tables. In addition to powering metadata for Hive itself, Hive Metastore also plays a critical role in the data infrastructure of other services or query engines like Apache Spark and Presto.
Scale and access pattern
As mentioned in the above HDFS NameNode section, when a JVM-powered business grows, so too does the data, metadata, and requests to access the metadata. Hive Metastore, as the source of truth of all metadata, has to increase its memory usage to accommodate the growth of the metadata size and number of requests.
A single Hive Metastore instance, for example, gets somewhere around 1,500 to 2,000 requests per minute, requiring a heap size of 50 gigabytes. With such a huge heap, GC pauses could impact the performance significantly. A latency degradation on Hive Metastore can have an amplifying effect on dependant critical services like Presto. The heap and GC need to be tuned well to keep Hive Metastore’s performance intact.
Reduce object creation to improve API latencies
During one particular incident, we were given an object lesson into how poor heap management in a service aggravated end user latencies. It all started when Hive Metastore internal users reported occasional high peaks (around 2 to 4 seconds) of latency, which usually come in at less than 100 milliseconds. These peaks were certainly not tolerable for critical interactive use cases like Presto. A getTable call was taking as long as 3 seconds, when it should be under 50 milliseconds.
The latency spikes can be due to a lot of factors, with the most common being:
- One of the upstream dependencies got degraded.
- Synchronization and queuing conflicts.
- JVM pauses due to GC.
We ruled out the first possibility, as there were no notable degradations on upstream dependencies. After looking at the source code, we also ruled out the second possibility, as the API under investigation did not have any kind of locking. To investigate our third possibility, we would need to analyze the GC logs.
GC logs give vital signals about heap health and behavior, and, most importantly, meter the global pauses triggered by the JVM’s GC. There are a plethora of UI tools available to analyze GC logs, such as GCeasy.
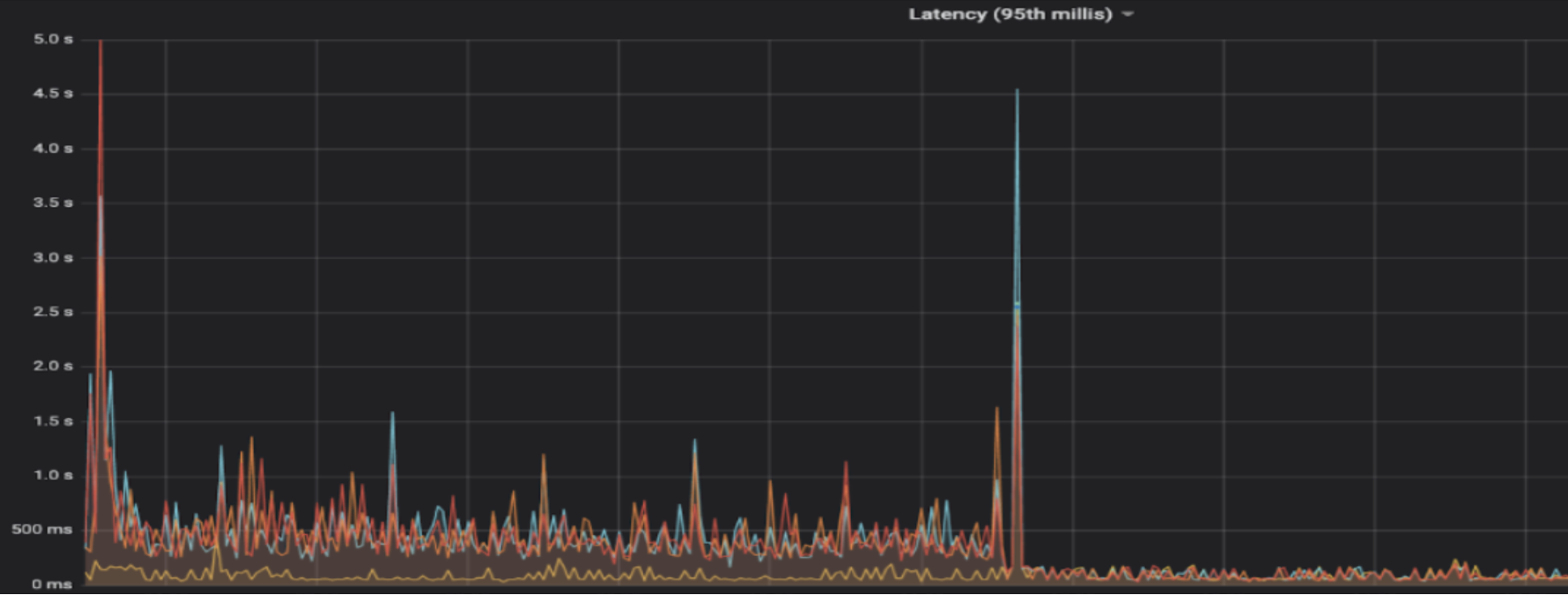
A report from GCeasy shown in Figure 7, below, indicated that there were 2,258 GCs that took somewhere between 0 to 1 second, with an average pause time of ~177 milliseconds, along with one or two outliers. These numbers lead to one clear inference: there are a lot of very frequent short pauses and the average pause time is too high.

In this particular case, all of these GCs were in the Young Generation, and every time the GC occured, the Hive Metastore paused for an average time of 177 milliseconds. This result indicates that many new objects were getting created too soon. And the fact that they are not going to the Old Generation indicates that too many objects were getting destroyed too soon. Essentially the garbage creation rate was way too high, at around 400 Mbps.
This high garbage creation rate correlated with a highly dynamic oscillating heap pattern, as shown in Figure 8, below:

A high garbage creation rate indicates either:
- A busy application with too many incoming requests.
- In-efficient memory management.
We ruled out the first possibility as the heap pattern was similar in a non-production instance that was not serving any traffic.
To debug the second possibility, we needed to understand what the threads in the application were doing. A thread dump taken using the jstack utility can capture a snapshot of all threads with their call stack and state.
The thread dump showed us that there were very few scheduled threads in the runnable state. However, one of the threads was always in the runnable state even after repeated thread dumps.
The code corresponding to the thread was a scheduled metrics collector daemon that was repeating the following two steps in a loop:
- Get all JVM vital metrics from mbeans.
- Publish them to a TSDB server.
The backoff for the thread should have been one second, but was incorrectly set to one millisecond, causing the mbeans metrics call to occur 1,000 times every second, generating a lot of garbage.
Increasing the back time fixed the problem, and the heap oscillation decreased, as shown in Figure 9, below:

Setting the thread’s back time correctly also substantially lowered the number of GCs, from 2,258 to 143, as shown in Figure 10, below:

The best part for our internal data users was that Hive Metastore latencies dropped considerably, as shown in Figure 11, below:
Understanding how excessive object creation caused significant system degradation lead us to the seemingly simple solution of efficiently engineering applications to create fewer objects. Subsequently, GC reduces the rate of Young Generation pauses, improving overall system latencies. For others who are experiencing similar degradation issues, we highly recommend looking into ways to more precisely tune your JVM memory through the Hive Metastore.
Tune coordinator garbage collector to improve Presto service reliability
Along with HDFS NameNode and Hive Metastore, we also tuned Presto’s coordinator GC to improve it’s reliability. We use Presto, an open source distributed SQL query engine, for running interactive analytic queries against our Apache Hadoop data lake. Uber’s Presto ecosystem is made up of a variety of nodes that process data stored in Hadoop, and each Presto cluster has one coordinator node that compiles SQL and schedules tasks, as well as a number of worker nodes that jointly execute tasks.
Presto coordinator JVM memory pressure
The Presto coordinator is the server that parses statements, plans queries, and manages Presto worker nodes. It effectively functions as the brain of a Presto installation, and is also the node to which a client connects to submit statements for execution.
The performance of the coordinator has a huge impact on the whole cluster and the end user’s request. Presto also requires that the coordinator allocate a huge amount of memory to handle those tasks, in our case, 200 gigabytes of heap memory.
This large heap size results in frequent GCs and long GC pauses, which in turn cause a high error rate and high end-to-end latency. We adopted G1 GC because it is a low pause JVM garbage collector, but we still saw frequent long GC pauses.
Two incidents gave us insight into how to reduce long pauses in Presto’s coordinator GC and prevent consecutive full GCs. Solving these incidents successfully resulted in a positive impact for engineers in terms of performance and reliability.
Reducing Presto coordinator long garbage collection pauses
As system users submitted more queries through Presto, we observed an increased error rate. Our weekly average error rate reports showed it as high as 2.75 percent, meaning only 97.25 percent reliability. After analyzing the service logs and GC logs, we found the Presto coordinator suffered from a long GC pause time, which came in as high as 6.59 percent of total run time. During the GC pause, the coordinator stops processing all user requests, resulting in longer latency and timed out sessions.
Further analysis of the GC pause showed a significant portion of the time was spent on String Deduplication, a feature introduced in Java version 8 update 20 to save memory from duplicate string objects. When this feature is enabled, G1 GC visits string objects and stores their hash values. When the collector detects another string object with the same hash code, it compares the char arrays of the two strings. If they match, then only one char array is used and the other one will be collected in the G1 GC collection process.
The JDK document for this feature only minimally discusses the benchmarks and the overhead, instead, focusing primarily on performance improvement. In our experience, we found that the overhead may be amplified when the JVM heap size reaches several hundred gigabytes. We tested our performance by enabling and disabling this feature to see if the GC pause time dropped significantly.
Disabling String Deduplication decreased the GC pause time from 6.59 percent to 3 percent of total run time, as shown in Figure 12, below:

This reduction in GC pause time resulted in the error rate dropping from 2.5 percent to 0.73 percent.
Preventing continuous full garbage collections
In another incident, we found the Presto coordinator sometimes stopped accepting queries and did not progress currently running queries. We checked the service log and found WARN entries, as demonstrated below:
2019-07-10T04:04:47.362Z WARN
ContinuousTaskStatusFetcher-20190710_040047_05467_jdjqr.8.45-3102231 com.facebook.presto.server.remotetask.RequestErrorTracker Error getting task status 20190710_040047_05467_jdjqr.8.45:
Running the jstack utility, a stack tracer for Java threads, on the Presto coordinator determined that there were many threads in a blocked state. Checking the GC log, we observed that before the coordinator stalled, there were a series of long GC pauses followed by an out-of-memory error in the JVM. Uploading GC log to GCeasy to plot the GC pause duration, we found several full GCs occured when the coordinator stalled, as shown in Figure 13, below:
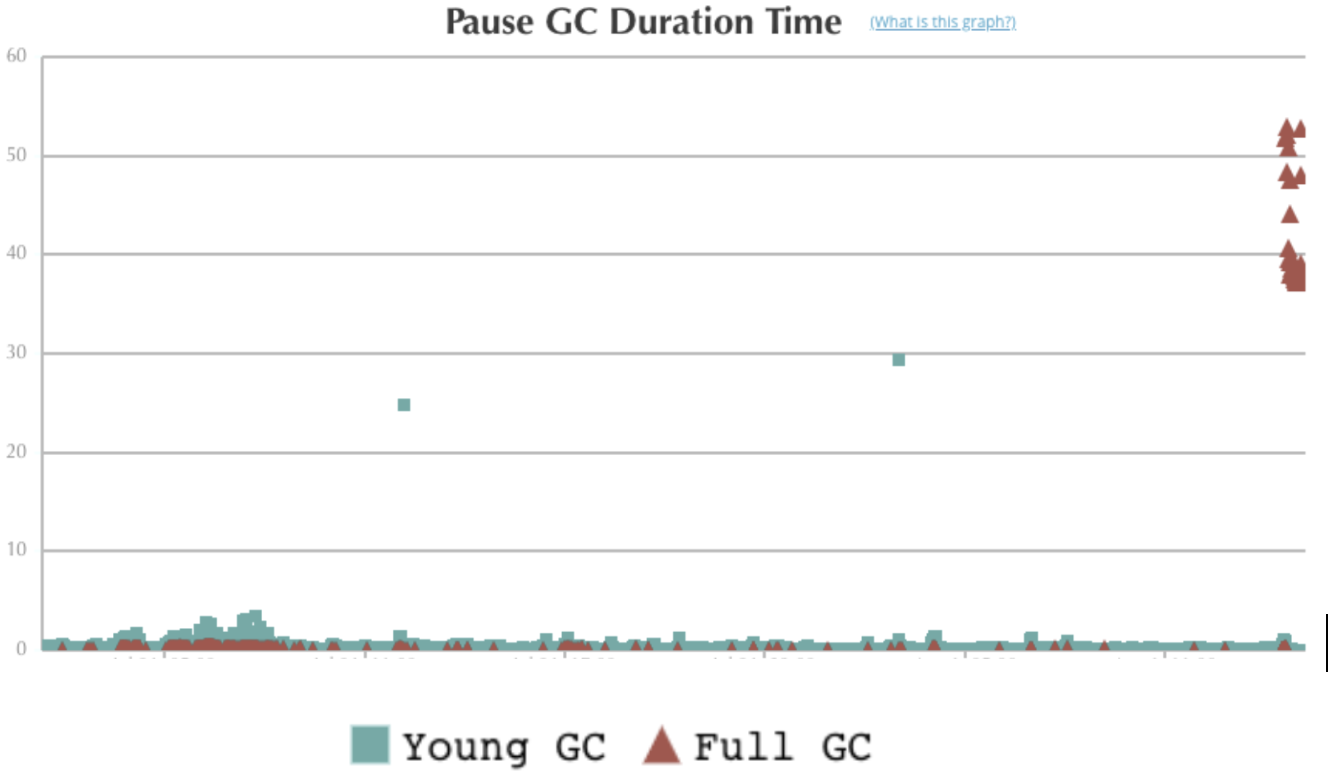
Further investigation revealed that after every full GC, there were very few bytes reclaimed, as shown in Figure 14, below:
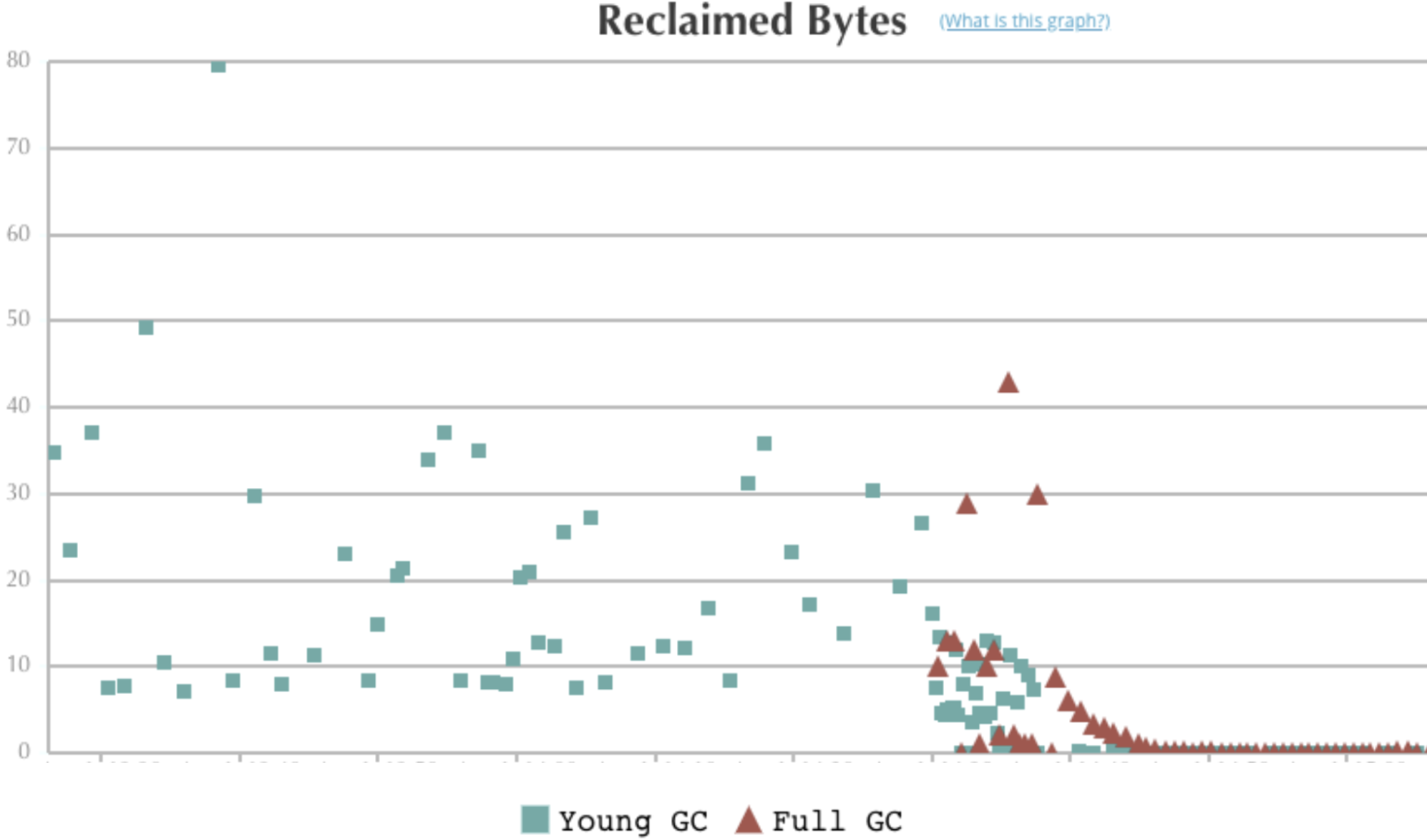
When each full GC could not reclaim enough bytes to continue, it triggered another full GC, and so on. After this cycle repeated several times, out-of-memory exceptions were thrown and the service was stopped.
Usually, consecutive full GCs are caused by the under-allocation of JVM heap size, which is less than the application requires. To choose the right heap size, there are several considerations:
- Typically, the heap should use less than 75 percent of the available RAM for the JVM. Of course, along with RAM allocated to the JVM, we also need to account for how much RAM the operation system and other processes on the same host will need. And, if it is run on a Linux host, IO buffering needs to be considered.
- We can use a verbose GC log to find out the maximum memory footprint. The memory footprint is the heap size leveraged when a full GC reclaims all the garbage. Typically, the total heap size should be larger than the maximum memory footprint. Considering the traffic could be subject to periods when it comes in bursts, we set the total heap size 20 percent larger than the memory footprint.
After the heap size was increased by 10 percent, this issue was resolved and the JVM heap stabilized.
In summary, we found the String Deduplication feature can add extra time to GC pauses and cause a high error rate. While we found that the majority of existing documentation about this feature focused on its memory-saving benefit, the side effect was rarely discussed. Further, consecutive full GCs are common issues in large scale services. We investigated one instance where it occurred and found that a tuning the heap size fixed the problem. We highly suggest that organizations in similar situations do not overlook the impact of String Duplication and consider how you can increase heap size to compensate.
Key takeaways
Through our experience maintaining and improving query support for Uber’s data platform, we learned many critical lessons about what it takes to optimize successful JVM memory and GC tuning. We consolidated these learnings into more granular takeaways for improving JVM and GC performance at Uber’s scale, below:
- Discern if JVM memory tuning is needed. JVM memory tuning is an effective way to improve performance, throughput, and reliability for large scale services like HDFS NameNode, Hive Server2, and Presto coordinator. When GC pauses exceeds 100 milliseconds frequently, performance suffers and GC tuning is usually needed. In our GC tuning scenario, we saw HDFS throughput increase ~50 percent, the HDFS latency decrease ~20 percent, and Presto’s weekly error rate drop from 2.5 percent to 0.73 percent.
- Choose the right total heap size. The total JVM heap size determines how often and how long the JVM spends collecting garbage. The actual size is shown as the maximum memory footprint in the verbose GC log. Incorrect heap size could cause poor GC performance and even trigger an out-of-memory exception.
- Choose the right Young Generation heap size. The Young Generation size should be determined after the total heap size is chosen. After setting the heap size, we recommend benchmarking the performance metric against different Young Generation sizes to find the best setting. Typically, the Young Generation should be 20 to 50 percent of the total heap size, but if a service has a high object creation rate, the Young Generation’s size should be increased.
- Determine the most impactful GC parameters. There are many GC parameters to tune, but usually changing one or two parameters makes significant impact while others are negligible. For example, we found changing Young Generation size and ParGCCardsPerStrideChunk improved the performance significantly, but we did not see much difference when changing TLABSize and ConcGCThreads. In tuning Presto GC, we found the String Deduplication setting dominates the performance impact.
- Test next generation GC algorithms. In a large scale data infrastructure, critical services usually have very large JVM heap sizes, ranging from several hundreds of gigabytes to terabytes. Traditional GC algorithms have trouble handling this scale and experience long GC pause times. Next generation GC algorithms, such as C4, ZGC, and Shenandoah, show promising results. In our case, we saw that C4 reduces latency (P90 ~17ms) compared with CMS (P90 ~24ms).
Moving forward
While we made great progress improving our services for performance, throughput, and reliability by tuning JVM garbage collection for a variety of large-scale services in our data infrastructure over the last two years, there is always more work to be done.
For instance, we began integrating C4 GC into our HDFS NameNode service in production. With the encouraging and beneficial performance improvement in the staging environment as described above, we believe C4 will help prevent NameNode bottleneck issues and reduce request latency.
GC tuning in distributed applications, particularly in Apache Spark, is another area we want to examine in the future. For example, the ingestion pipelines used in our data platform are built on top of Spark, and our Hive service also relies on Spark. JVM Profiler, an open source tool developed at Uber, can help us analyze GC performance in Spark so we can improve its performance.
If using your detective skills to determine how to optimize Big Data memory appeals to you, consider applying for a role on our team!
Girish Baliga
Girish manages Pinot, Flink, and Presto teams at Uber. He is helping the team build a comprehensive self-service real-time analytics platform based on Pinot to power business-critical external facing dashboards and metrics. Girish is the Chairman of the Presto Linux Foundation Governing Board.
Xinli Shang
Xinli Shang is the ex–Apache Parquet™ PMC Chair, a Presto® committer, and a member of Uber’s Open Source Committee. He leads several initiatives advancing data format innovation for storage efficiency, security, and performance. Xinli is passionate about open-source collaboration, scalable data infrastructure, and bridging the gap between research and real-world data platform engineering.
Fengnan Li
Fengnan Li is an Engineer Manager with the Data Infrastructure team at Uber. He is an Apache Hadoop Committer.
Amruth Sampath
Amruth Sampath is a Senior Engineering Manager on Uber’s Data Platform team. He leads the Batch Data Infra org comprising Spark, Storage, Data Lifecycle management, Replication, and Cloud Migration.