Scaling of Uber’s API gateway
As a recap from the last article, Uber’s API Gateway provides an interface and acts as a single point of access for all of our back-end services to expose features and data to Mobile and 3rd party partners. Two major components for a system like API Gateway are configuration management and runtime. The runtime component is responsible for authenticating, authorizing, transforming, and routing requests to appropriate downstream services, and passing responses back to Mobile. The configuration management component is responsible for managing the workflow for developers to easily configure their endpoints on the gateway. This includes making sure the configured endpoints are backward compatible and that no functionalities are regressed during runtime. All of Uber’s back-end engineers depend on this component every day to develop, test, and publish their endpoints to the internet.
The reliability and efficiency of such a system are extremely important. As you can imagine, having a reliable and efficient gateway platform contributes directly to both the rider experience (particularly with the runtime component) and the developer experience (where any issues on the configuration management component will negatively impact feature development velocity). While reliability and efficiency of the runtime component are extremely critical as they contribute directly to Uber’s top line, the reliability and efficiency of configuration management are also extremely critical and directly related to Uber’s bottom line.
When a platform is used by a large volume of engineers to develop endpoints, it naturally creates points of contention, which can slow people down and ultimately reduce the overall developer velocity across the company. In this article, we will talk about how we scaled this platform to be used by hundreds of engineers at Uber daily. We will dive deep into the code build aspect of our configuration management component, the challenges we faced as we rolled this out, and how we solved them.
Code Build Pipeline
In this section, we will closely examine our existing code build pipeline, including the code generation step, to better understand its particular challenges and solutions.
Before we dive into the code build pipeline, it is important to understand that there are two kinds of code diffs (diffs are analogous to Github PR) that we deal with on the platform:
- Manual Platform diffs: generated by the platform team to make changes to the Edge Gateway platform itself
- User Generated UI diffs: generated through the Edge Gateway UI by the product engineers as they develop mobile/internet-facing endpoints
We had a unified code build pipeline for both user-generated UI diffs and manual platform diffs, It consisted of the below sequence of steps:

- It starts off with the user configuration (like payload schema, filter definitions, etc.), which is then fed into the Build system to generate the code for checking into the existing user diff
- The diff goes through the integration test pipeline to verify if the generated code is buildable and if the platform integration test passes.
- If the platform integration test didn’t pass, the user would need to change its endpoint configurations
- If the platform integration test passes, the changes would then be submitted to our internal change management system (Submit Queue) for landing
- Submit Queue validates that there are no merge conflicts in the diff integration, and then checks that all the unit tests passed
- If the Submit Queue checks didn’t pass, the user would need to regenerate its changes with the latest master
- If the Submit Queue checks pass, the code is then pushed to the master
Code Generation
The code build pipeline is a multi-step, time-consuming process. Thrift files along with endpoint configuration files provided by users become input. A Thrift file goes through schema augmentation in the preprocessor step, and then a thriftrw model is generated, followed by static JSON serializer generation. These models are needed for compiling the final version of code generated by the Edge Gateway.
Challenges Faced
In this section, we will list some of the major challenges we faced as we started rolling out the Edge Gateway platform.
Large Code Generation Times
As we started rolling out the platform, one of the first problems we faced is that the code generation time increased linearly with the expansion of endpoints. For every endpoint change that gets rolled out, new configurations are created/updated, and it means we have to regenerate the code for all of them. As you can imagine, we have thousands of endpoints on the Edge Gateway. When we started, it took only a minute for code generation but as we added more endpoints, we soon hit a place where code generation was taking north of 2 hours. We have hundreds of changes happening on the platform every day, and running 2 hours of code generation for change was not scalable, and slowed development. We had to quickly come up with some solutions to address this bottleneck.
Large Integration Test Times
Integration Test comprises two steps, first compiling and generating the binary, and then running the platform integration test itself. It was taking north of 30 minutes for the Go platform to build the entire binary. This was further complicated by the revocable Mesos cluster when the build took a long time and restarted the process. For user UI-generated diff, running platform tests were a waste. Even though a unified build pipeline provided simplicity, making our users wait for up to over 3 hours was not a good solution. This problem becomes even bigger when endpoint changes need to go through multiple iterations during the development phase. Thus, we needed to redesign this pipeline to accommodate for UI and manual diffs.
Code Merge Conflicts
Regardless of the protocol that Mobile applications use to talk to Edge Gateway, we represent all the payloads in a Thrift schema. While each endpoint exposes a unique feature, there are a bunch of common attributes/fields across all of these endpoints that are configured in a common Thrift file and imported into endpoint Thrift files. This is especially important so that we do not have different implementations for common attributes across different features at Uber. For example, we want to make sure that lat/long is always represented as a double, regardless of which endpoint uses them, so that we have a consistent way of representing them across all of Uber’s back-end services. All of these shared elements are configured in a common Thrift file, let’s call it “common.thrift”. Any endpoint that requires one of these common fields then imports the common.thrift file into its configuration. The challenge this produces is that we soon have a large dependency graph. Anytime a child Thrift is updated, all the parent endpoints need to be regenerated, regardless of whether the updated element of the child Thrift is being used by that endpoint or not. This caused a unique challenge where any time a child Thrift that is used by multiple endpoints is updated (like the common.thrift), it caused all the other endpoint changes that imported it to fail landing, due to merge conflicts. The problem is exacerbated even further by having hundreds of engineers making changes all the time. As more and more teams started using our platform, our code landing success rate due to merge conflicts suddenly dropped from 90% to 40%. This signaled we need to optimize how generated code is checked in, while still ensuring code generation on the master would not break.
Managing Large Code Base
The runnable artifact for the Edge Gateway is generated automatically from the configuration files using our open-source framework, Zanzibar. With 1500+ endpoints, we started generating enormous amounts of code (25 million+ lines), which brought with it some unique challenges. We were hitting the limit with Go Compiler due to the binary size being too large. We also were running into issues with a few files that had huge dependency graphs being so large that our code-review tool (Arcanist) could not handle the diffs. We had to mark some subset of files to be treated as binary so Arcanist would not process the diff and just update the whole file as a new version. This in turn caused issues around both losing change history on those files and causing merge conflicts even when changes were on completely different parts of the file.
Platform Changes vs Endpoint Changes
Whenever there is a platform change, it usually touches pretty much every single endpoint in the Edge Gateway. This means all the endpoint files need to be regenerated. With hundreds of engineers constantly making changes to their endpoints, this caused another unique challenge where the window for the platform engineers to make changes quickly vanished. Every time the platform has to make a change, it constantly keeps running into merge conflicts, since some developer has made a change to an endpoint. We either had to keep rebasing and retrying or pause the Submit Queue to block other developers from landing their changes for a few hours a day so that platform changes can be landed and tested. As you can see, both of these are not ideal solutions.
Large Deployment Times
Because of all the above limitations, user diff would need a very long time to get to master and be deployed in production. Deployment in itself used to take a very long time, as it needed to build the large codebase. This delays time to market for a feature or a change. We could have solved this problem by sharding the endpoints into multiple deployment instances, but we wanted to avoid it for the easier operability of the platform. Thus, we had to figure out a way to optimize the build binary size for faster deployment.
Tackling the challenges
With the challenges of establishing clear directions in which we could improve our operation, we set ourselves on the multi-pronged path to deliver an efficient gateway for our developers at Uber.
Differentiated Pipeline for UI Diffs vs Manual Platform Diffs
The redesigned code build pipeline consists of two separate pipelines for UI and manual diffs. Below are the steps executed by the UI diff pipeline:

- It starts with the user configuration, which is fed into the Build system to generate the code
- The code generation is incremental, with a beefed-up code generation module
- Generated code is **not** checked in to the existing user diff
- This generated code is then fed into the UI diff tests step to verify whether the generated code is buildable, and the URLs can be registered with an HTTP router to verify the URL sanity
- If the UI diff tests didn’t pass, the user would need to change its endpoint configurations
- If the UI diff tests pass, the changes would then be submitted to the Submit Queue system for landing
- Submit Queue test now consists of verifying whether the diff integrated into the latest master: a) would have unique URLs, b) querying whether the UI diff test passed, and c) a unit test run only for manual platform diffs
- If the Submit Queue test didn’t pass, the user endpoint configuration needs to change and resubmit into the pipeline
- If the Submit Queue test passes, the config is then pushed to the master
- Periodically the master is built and pushed to Git, described in the “Incremental Build” section below
Config Landing Without Code
As described above, only the config is landed to master. Submit Queue verifies whether the config landing would break the master. To do this check, it uses the results of UI diff tests. For manual diffs, it uses the results of integration tests to verify the same.
At times, even configuration changes can result in merge conflicts, when done to the same endpoint concurrently. These merge conflicts are resolved using a custom merge conflict resolution driver, invoked by Git upon merging. A sample implementation of a basic merge conflict resolution driver is available here.
Incremental Build
The code generation library is beefed up to build only incremental changes, rather than all. It recognizes the delta module to build, using a Watermark file (.build). It feeds it to the DAG of modules, which then determines the list of modules to code-generate. The “.build” file stores the last built Git ref to determine the delta modules, Thrifts, and configuration changes.
.build file: Representational build file which is a canonical way to do incremental code-gen in Edge Gateway.
| { “git_hash”: “9ea4fa10913dcb7a2433a740c685d5b60b516a36”, “glide_md5”: “9666c650dbffcb936b842422f38154ee” } |
The Master is periodically built by using this “.build” file to know the last built state. It calculates the delta and builds using the above-explained methodology. Once it is built, it pushes the code directly to the master.

Parallelization of Codegen library
The code generation library was building modules sequentially. It needed to be parallelized to utilize all cores for a few key, time-consuming substeps:
- ThriftRW code-gen parallelization: ThriftRW models are generated to be used in the generated code for serializing/deserializing and request/response transportation. This step was also made incremental to only generate the changed Thrift specs and then parallelize their incremental generation.
- Parallelize DAG creation and endpoint code-gen: DAG creation consists of several layers in Zanzibar, where each layer feeds into the next. While there is a sequential flow needed when going from one layer to another, within each layer the partial DAG node creation can be parallelized.
Once the DAG is fully created, code generation is parallelized with bounded goroutines.

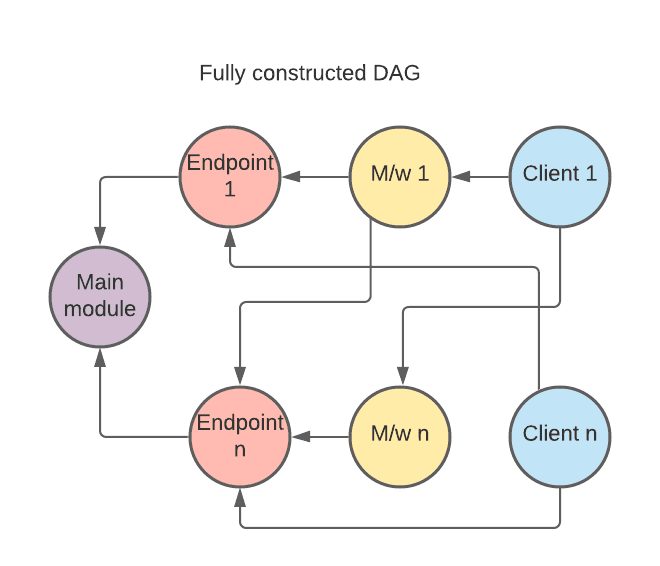
3. Vertical scaling of the Code Build system: To utilize the concurrent goroutines generation, we vertically scaled the build system to do parallel generation faster.
Selective Module Building for Faster Endpoint Testing
A production gateway register function has thousands of endpoints being registered. Compiling this large codebase to generate a binary is a time-consuming step.
| // RegisterDependencies registers direct dependencies of the service func RegisterDependencies(g *zanzibar.Gateway, deps *module.Dependencies) error { var err error } |
For UI diffs, we are only interested in testing the endpoints being changed. This opens up the possibility of registering selective endpoints.
| // RegisterDependencies registers direct dependencies of the service func RegisterDependencies(g *zanzibar.Gateway, deps *module.Dependencies) error {
} |
This reduces the DAG, which the ‘go build’ tool needs to traverse. and thus speeds up binary generation.
Trimmed IDL Spec
The existing code generation process takes in the entire set of Thrift IDLs and generates thriftrw models for all types in IDL, even if only a subset of structs are referenced. This leads to a large codebase, leading to both large diff issues with Arcanist and errors in the linking phase to produce a binary.
We introduced the following measures to reduce the generated code size:
- Generate the Thrift files from the input corpus of thrifts, containing only types that are either used in endpoints or clients (downstreams), directly or transitively
- Share the objects between modules
This generation of IDL specs is achieved using a Mark and Generate algorithm, described below:

Mark Phase
- Collect a list of used endpoints: This will iterate through the endpoints dir and get a {thrift, service method, clientid, client service method } tuple.
- Example tuple: {idl/code.uberinternal.com/rt/edge-gateway/bar.thrift, Bar::Growth, bar-client, BarService::Growth}
- Collect referenced client tuple from an endpoint: This will iterate through each client id retrieved in the above step and get a {thrift, client service method} tuple.
- Example tuple: {idl/code.uberinternal.com/bar/bar.thrift, BarService::Growth}
- Collect a list of clients referenced in middleware: This will iterate through all middlewares and get a {client id} array. This will be processed to get a list of {thrift, all methods} tuple.
- Example tuple: [geofence, user-affinity]
- Map to top-level thrift to list of service methods: This will form a map of endpoints and client modules separately, which it gets from previous steps to generate a map of {thrift, a list of all used methods}. The below steps will be individually called for both modules separately.
- Example tuple: {“idl/code.uberinternal.com/bar/bar.thrift”: “BarService::Growth”}
- Example tuple: {“idl/code.uberinternal.com/rt/edge-gateway/bar.thrift”: “Bar::Growth”}
- Start a collection process from a root node: There is a forest of root nodes. This step will iterate over all child nodes for a root and get a list of all child nodes, along with the work they need to do. Work is to iterate over its type which is collected in the previous run of this loop. Each run discovers more work, which feeds into the next run. So multiple parallel BFS traversals are happening per each root node (top-level thrifts).
- Other nodes deposit work even for an already-finished child or root nodes: However, the iteration work involved to modify the node lies with other nodes’ root callers, so this is a loop step.
- Once step 6 finishes for all nodes, the program proceeds to the generate phase.
Generate Phase
- Assemble the thrift syntax tree: All nodes iterated and reachable from the root, including itself, will be assembled into a syntax tree for a Thrift file which is called a program. So the assembled program is a trimmed version of the original program with unnecessary imports removed, only using types used by other Thrifts (including own if it’s the root node).
- Schema augmentation: It is needed for custom serialization.
- Marshal Thrift program: The augmented program is written back to the Thrift file for thriftrw model gen and code generation.
These trimmed specs are fed into the code generation module rather than using raw IDL specs. In our case, it reduced the codebase size by more than 50%.
EasyJSON Objects Removal
We serialize/deserialize ThriftRW model objects to JSON using the EasyJSON library. This needs EasyJSON objects to be generated statically. This is also one of the key things that contribute massively to the already large codebase. Hence, we moved away to the dynamic JSON serialization library, JSON-Iter, which has comparable runtime costs while saving on codebase size. More details on this can follow in the future in a different blog post.
Cleanups
Here we had two easy opportunities to reduce the garbage which accumulates over time:
- Git cleanup: We see over ~50+ diffs, which are generated daily. This accumulates a lot of Git history for generated code that is not needed. So, we periodically ran Git garbage collection, along with cleaning up old tags.
- Deletion of unused endpoints: Users don’t delete unused endpoints and Thrifts from the Edge Gateway. So the periodic job takes care of doing this by querying various internal systems to form a prune list.
Scaling of the Deployment Infrastructure
Binary build time has been reduced massively by the above measures. However more needs to be done to reduce it further. We vertically scaled the build infrastructure and also ensured builds are scheduled non-preemptively on Mesos to avoid build restarts.
Any combination of these techniques could be relevant to similar systems, depending on the particular business use case and scale.
Further Work
Remote Caching with Bazel
We are now working on integrating the code generation library with Bazel. Through that, we will be able to utilize remote caching for faster builds.
Dynamic Testing
We are exploring ways to do faster testing of endpoints being developed. One of the ways is to dynamically deploy the generated build artifact to the test environment. For this, we are prototyping a solution using plugin architecture provided by Go.
Acknowledgement
This herculean effort would not have been possible without the significant contributions of so many participants. Some key acknowledgments are: Abhishek Panda, Chuntao Lu, Rena Ren, Steven Bauer, Tejaswi Agarwal, and Timothy Smyth.
Appendix
Abhishek Parwal
Abhishek Parwal is a Sr. Software Engineer II at Uber. Over the last 3+ years at Uber, he has led & built multiple large-scale infrastructure platforms from the ground up. This includes the Edge Gateway platform, which lays a solid foundation to expose API for all teams at Uber. Currently, he is helping in building the next generation Fulfillment platform powering real-time global scale shopping and logistics systems.
Karthik Karuppaiya
Karthik Karuppaiya is an Engineering Manager at Uber. He is a seasoned technologist with experience working on complex backend and data platforms. He has been managing high-performance teams at companies like Symantec, Amazon, and Uber over the last 9+ years. Since joining Uber, he has been leading the Edge Platform team which builds and operates all the Gateways at Uber.