
Introduction
Apache Pinot is an open source data analytics engine (OLAP), which allows users to query data ingested from as recently as a few seconds ago to as old as a few years back. Pinot’s ability to ingest real-time data and make them available for low-latency queries is the key reason why it has become an important component of Uber’s data ecosystem. Many products built in Uber require real-time data analytics to operate in our mobile marketplace for shared rides and food delivery. For example, the chart in Figure 1 shows the breakdown of Uber Eats job states over a period of minutes. Our Uber Eats city operators need such insights to balance marketplace supply and demand, and detect ongoing issues.
At a high level, Figure 2 (Credit: Apache Pinot Docs) shows a Pinot cluster consisting of several components: Pinot controller, Pinot server, Pinot broker, and a segment store. Pinot controller is a metadata service which controls the state of a Pinot cluster. Pinot server is the data node that ingests and stores both realtime and batch data. It also serves queries sent by Pinot brokers. Pinot broker is the query gateway which scatters a user query to Pinot servers and gathers the results. A segment store has staged Pinot data segments for the purposes of both data backup and download.

Pinot’s real-time consumer in each Pinot server organizes the incoming stream data into smaller chunks called Pinot segments. During data ingestion, a copy of each Pinot segment is persisted in the segment store via Pinot controller. Pinot’s real-time ingestion method provides administrators with the capability to scale their Pinot clusters according to ingestion and query rates. It also provides for easy capacity expansion and fault tolerance. These features led us to adopt it as the backbone for supporting our real time OLAP requirements.
As usage increased, we realized some shortcomings that needed work:
- If the completed segment upload to the controller failed for any reason, real-time consumption would stop. External deep storage backing Pinot controllers can be unavailable to Pinot due to uncontrollable causes, lasting minutes or hours. Once an outage happens, Pinot real-time tables can lag behind for hours, which is unacceptable for Uber’s real-time data freshness requirement.
- Completed segments were always uploaded to controllers (and the controllers would act as a pass through to deep storage). Direct upload of completed real-time segments to deep storage was not possible (unlike the offline segments, which could be pushed to deep storage directly).
Pinot implemented a split commit protocol that separated segment metadata commit from the actual upload of the segment. The intention was to allow upload to deep storage at some point in time, but significant changes were needed in Pinot to complete this work. This blog describes the improvement that we designed and implemented in order to solve the above issues.
Pinot Real-Time Ingestion Using Deep Store
Pinot real-time consumption uses a distributed protocol called segment completion protocol to ensure that exactly one replica commits each segment during the segment completion process. The other replicas may either download the completed segment, or build it locally. The first version of the segment completion protocol required that the completed segments be uploaded to the controller. The controller depended on a mounted storage for a deep store, shown below:

While working well for a few Pinot tables, the test quickly ran into issues because the design uses a controller-mounted POSIX compliant filesystem to store all the uploaded segments. The use of an NFS-mounted external storage on the Pinot controller was not deemed fit for Uber’s data ecosystem.
To replace a controller-mounted storage with a deepstore like Apache Hadoop HDFS, Pinot had a Pinot file system interface (PinotFS) such that a variety of cloud storage systems could be plugged in. In addition, Pinot implemented a split commit protocol that separated a segment’s metadata commit from its actual upload. The intention was to allow upload to a deep store at some point in time, but significant changes were needed in Pinot to complete this work. In the split commit protocol, the segment commit is carried out in three steps: (1) segment commit start (2) segment upload and (3) segment commit end with metadata update. During (2) the server first uploads the segment to a temporary location in the deep store. Only in (3) does the controller move the segment to its final location. In this way, segment metadata and binary data upload are separated. Figure 4 shows the data flow of the new protocol:

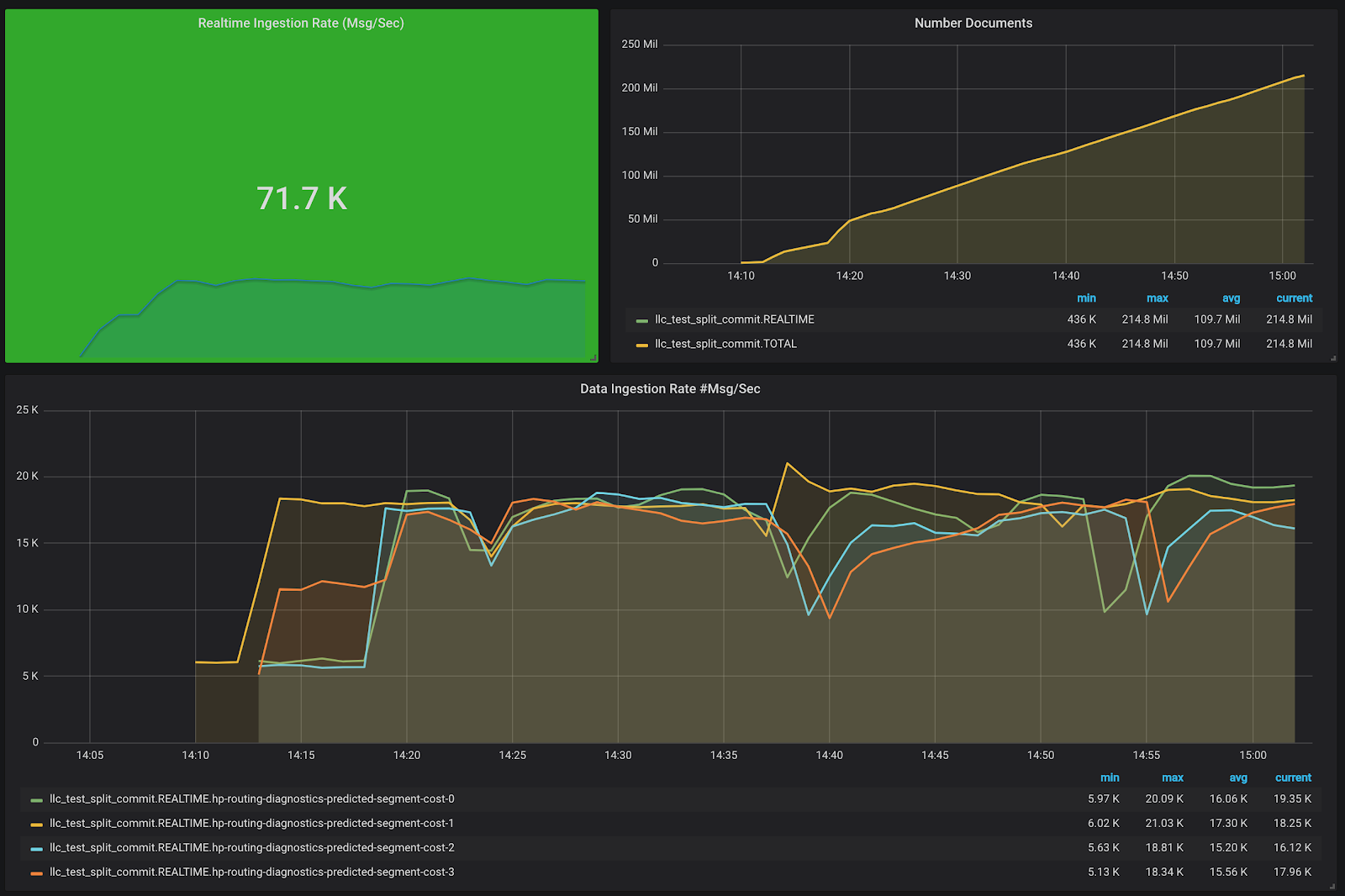
With the above modifications, one can now configure a deep store for Pinot’s real-time ingestion. In Uber, we chose HDFS as our deepstore. The addition of HDFS solves the storage limit issue, as expected. The ingestion performance works well for us: for heavier use cases, the setup can ingest up to 100k messages per second with 3 Pinot servers, as demonstrated in Figure 5:
While Pinot’s real-time ingestion worked great for us in general, we ran into several issues during the first year of operation. In the next section, we will discuss how we have resolved them.
Bypassing the Deep Store (When It Fails)
As shown in Figure 4, Pinot real-time ingestion requires the Pinot Controller to use blocking calls to upload the segment to an external storage system behind the PinotFS interface (e.g., NFS, HDFS or S3 and so on) during the segment completion protocol. Like we mentioned before, a deep storage mechanism could be unavailable for several hours due to maintenance, etc., so we still had to solve the problem of allowing for continuous consumption, even if deep storage is not available.
Our proposed solution leverages Pinot’s existing replication mechanism to remove the strong dependency on a deep storage system. If an upload to a deep store fails, a server can instead try to download the segment from a peer Pinot server, rather than the deep store. Note that the segment completion protocol guarantees that there is at least one server that has the complete segment. This server can therefore serve as a peer for other servers.
Our goal here is not to get rid of the deep store. In fact, the deep store is still used the same way when it is available. However, when it is down, our modified real-time ingestion can bypass it and proceed to commit segments. It is good to have segments in the deep store to increase availability and server performance (by reducing segment download’s impact on peer servers). However, even if the segments are not in deep store, the overall function of ingestion will not be impacted.
Modified Segment Completion Protocol
Figure 6 shows the modified segment completion protocol in which (1) the success of segment upload to deep store is no longer a necessary condition for ingestion to proceed; and (2) the segment upload no longer goes through the Pinot controller.
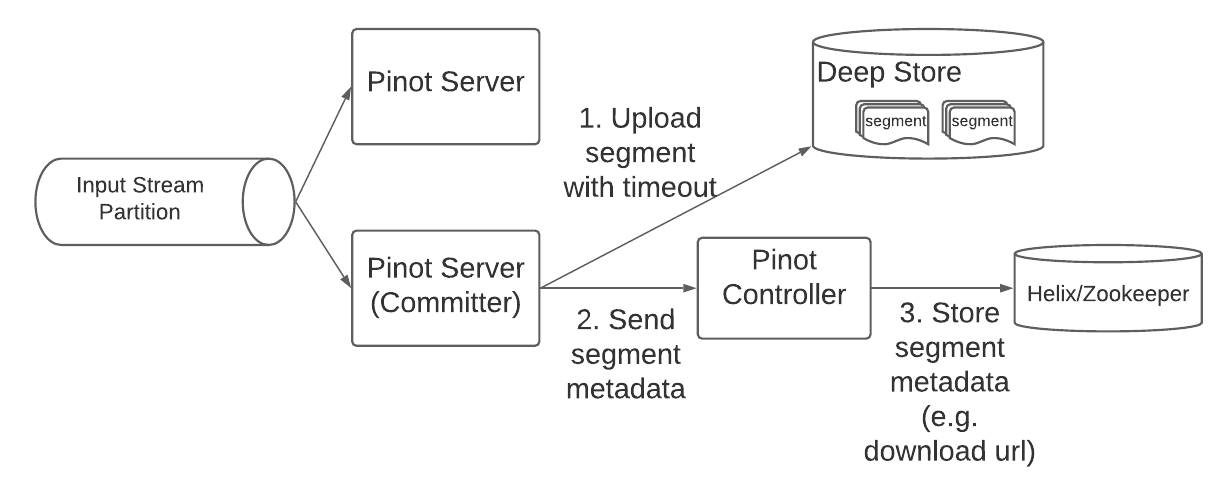
Figure 7 shows how the real-time ingestion continued to function as normal even though we manually injected a deep store failure by making it not writable.

We observed a network traffic reduction of over 10x on the Pinot controllers after we switched on the new segment completion protocol over a large cluster with over 100 Pinot real-time tables (Fig. 8). This was expected, because the controller no longer receives and uploads segment data.


Segment Download

In the segment completion protocol, a server may need to download a segment instead of building its own, in some scenarios: for example, it falls too far behind in stream consuming or if it restarts after a failure. In the event that the deep storage is not available, we allow a server to download the segment from peer servers. To discover the servers hosting a given segment, we utilize the Helix external view of the Pinot table to find out the latest servers hosting the segment. The complete segment download process works as follows (Figure 9):
- Download the segment from the deep store download URI found in the property store of the zk server if the URI is not empty
- If (1) failed for any reason (including there being no deep store URI in the property store for the segment), get the Helix external view of the table to discover the ONLINE servers hosting the segment
- Download the segment from a randomly chosen ONLINE server, formatted as a Gzipped file of the segment on the source server
To support segment download from a Pinot server, we added a new server API for segment download. The REST URI path is: /tables/{tableName}/segments/{segmentName}.
Failure Handling
Pinot real-time segment completion is a complex distributed protocol. Any modification to it needs careful consideration of new failure cases and race conditions introduced. Our deep store bypass proposal is no exception. The main new failure case we introduced happens when the committer server fails to upload the segment to the deep store. As the previous section mentioned, in such a case a non-committal Pinot server N needs to discover peer servers with the segment, via the table’s external view (EV) mapping. In a distributed system, the EV update by Helix is done asynchronously, and happens concurrently with segment download. If N attempts to download the segment before the EV update is completed, it may find no server is hosting the segment. To avoid such race conditions, we introduce retry with exponential backoff during segment download to minimize the impacts caused by the EV update lag.
How to Use This Feature
To use the deep store bypass feature, one can refer to this section of the official Apache Pinot documentation for the required configuration.
Further Optimization
If the segment upload to the deep store fails, the segment has no download URL in Apache Zookeeper. That means that Pinot server always has to download it from peer Pinot servers. Download of segments from peer servers will result in additional CPU and network usage in peer Pinot servers, and thus should be avoided as much as possible. To this end, we plan to add a new periodic job to Pinot controller’s RealtimeValidationManager in order to upload segments to deep storage if the download URLs are empty. These segments need to be pulled from one of the servers hosting the segment.
To do that, the periodic job scans all segments’ metadata in Zookeeper. If it finds a segment does not have a deep store download URI, it will find a server with that segment again using the table’s External View, and instruct the server to upload the segment to the deep storage. After the upload, it will then update the segment’s download URL with the deep storage URI.
The reason we have postponed this optimization is because the return is marginal. The retention time on the real-time table is usually small (under a week). The cost incurred in pushing the segment to deep storage is a scan of all the segment metadata in the periodic job, which could be an expensive operation (in terms of Zookeeper load).
Lessons Learned
In this article, we explained how we added a deep store to Pinot real-time ingestion protocol, and then contributed a major enhancement to the original protocol to solve Uber’s operational pains. Pinot’s Real-Time Ingestion is a sophisticated distributed data synchronization protocol at its core. Any changes to it require a deep understanding of the original protocol and new failure scenarios introduced. Here are a few lessons we learned during the journey:
Break Down Changes into Phases
We carried out the changes in two main phases: the first to alleviate the storage system limitation and the next to revolve more structural issues, like hard dependencies on deep stores. During the first phase, we gained quick operational experience with the protocol and contributed bug fixes to the new split commit mode. At the same time, we evaluated its issues and worked on the enhancement.
Add and Use Integration Tests for Verification
A large, distributed system with many components, like Pinot, is hard to test. Real-time ingestion as a distributed protocol makes it even harder to test and verify any major change on it. To validate ideas and implementations, a good integration test can greatly shorten the development cycle. Pinot has a great suite of integration tests, which set up all components of a Pinot cluster. We added a few new integrations which is very helpful to test that the system works from end to end.
Engage the Community
The Apache Pinot community is always open to new ideas and proposals. After the initial proposal from Uber was reviewed, the original author of the Protocol joined the team in implementing the feature in an extensible, backward-compatible way.
Acknowledgement
We acknowledge the Pinot dev team in Uber and LinkedIn, as well as the Pinot open source community for providing valuable feedback, guidance, and prompt reviews during design and implementation.
Trademarks
Apache®, Apache Pinot, Apache Zookeeper, Apache Hadoop HDFS, Pinot, Hadoop HDFS and Zookeeper are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.

Ting Chen
Ting Chen is a Software Engineer on Uber’s Data team. He is a Tech Lead on the Stream Analytics team whose mission is to provide fast and reliable real-time insights to Uber products and customers. Ting is an Apache Pinot committer.

Subbu Subramaniam
Subbu Subramaniam is a Lead Engineer on LinkedIn’s Pinot Team, and an Apache Pinot PPMC member. Subbu has been working on Pinot for 5 years, and is the architect and author of the Realtime Ingestion system in Pinot.

Chinmay Soman
Chinmay Soman is a former Software Engineer on Uber's Data team. He led the Streaming Platform team. The team's mission is to build a scalable platform for all of Uber's messaging, stream processing, and OLAP needs. Chinmay is an Apache Pinot contributor.
Posted by Ting Chen, Subbu Subramaniam, Chinmay Soman







