Introducing Orbit, An Open Source Package for Time Series Inference and Forecasting
May 14, 2021 / Global
Orbit is a general interface for Bayesian time series modeling. The goal of Orbit development team is to create a tool that is easy to use, flexible, interitible, and high performing (fast computation). Under the hood, Orbit uses the probabilistic programming languages (PPL) including but not limited to Stan and Pyro for posterior approximation (i.e, MCMC sampling, SVI). Below is a quadrant chart to position a few time series related packages in our assessment in terms of flexibility and completeness. Orbit is the only tool that allows for easy model specification and analysis while not limiting itself to a small subset of models. For example Prophet has a complete end to end solution but only has one model type and Pyro has total specification model flexibility but does not give an end to end solution. Thus Orbit bridges the gap between business problems and statistical solutions.

There are many different use cases of time series forecasting at Uber, both strategic ones (long-term) and tactical ones (short-term). This Uber blog post provided an overview of those use cases. Many of them not only require end-to-end forecasting, but also a causal inference structure in order to provide explainability, quantify uncertainty, and perform a what-if scenario analysis. Orbit could improve the quality and efficiency of this process.
Orbit has a wide range of applications in Uber’s marketing data science team for measurement, planning, and forecasting. Primarily it is used in measuring the performance for various marketing levers at subchannel and daily granularity.
Orbit enables the easy decomposition of a KPI time series into trend, seasonality, and marketing channels effects. This decomposition enables unbiased forecasting and dynamic insights, including cost curves and ROAS of marketing channels. The forecasting is an important part of planning future marketing budgets and the optimization of spending across different channels and regions.
Orbit can utilize real world data in multiple formats simultaneously; i.e., incorporating results from previous experimentations along with multiple channels of contemporaneous data.

What is Orbit?
Orbit stands for Object-ORiented BayesIan Time Series. It is used to conduct time series inferences and forecasting with structural Bayesian time series models for real-world cases and research. Like many other ML use cases, the best model structure is largely dependent on that particular use case and available data. A common approach to determine a well-suited model is to try out different model types, perform backtesting, and diagnose how well they perform. Having one, consistent interface for performing all these tasks largely simplifies our ability to determine the best model for a given use case.
While there are plenty of time series model implementations in the Python ecosystem, Orbit aims to provide a consistent Python interface to simplify Bayesian time-series modeling workflow by linking one command to each step in the following diagram. Check out the How to Use Orbit? section for command examples.

We follow a number of object-oriented design patterns to maintain independence between Estimators and Models. What that means for the end users is that there will be consistency in package usage to accomplish a desired use case. What that means for model developers is that their focus can be on the structure of the model, rather than the Orbit interface or interactions with the underlying PPL.

Estimators are classes that handle interactions with the PPL such as Stan or Pyro. It may seem unnecessary to implement this class if we are using an underlying PPL, however, in addition to the nuances of each PPL, a user must also determine:
- Whether to perform a point estimate or sample a full distribution
- What algorithm to use for sampling a distribution
- What kind of aggregation to use for a point estimation
- And various algorithm fine-tuning configurations
We abstract away some of the decisions, and allow a Model to compose a specified Estimator within it. A Model is a concrete implementation of a model structure, and how to perform inference after the parameter estimation. Currently implemented are two main classes of models, named Local Global Trend (LGT) and Damped Local Trend (DLT), which we’ll discuss in further detail below. We found that for our use cases, the current two model implementations performed well relative to other solutions. One important goal of Orbit is to quickly incorporate new models while maintaining a consistent interface. Furthermore, we have modules for backtesting, diagnostics, and visualization that will work out of box with any Orbit model object. To be specific, our package provides:
- A general interface for training and prediction of time series models with great extendibility
- Child classes for a family of Bayesian exponential smoothing models
- Data loaders for quick access of time series data sets with different granularities
- Rich diagnostic plotting tools
- A general-purpose backtesting utility
- A hyper-parameter tuning utility
How to Use Orbit?
Orbit’s APIs are descended to have a similar interface to Scikit-learn (the de-facto standard Python library for general-purpose statistical and machine learning model building). An example workflow using Damped Local Trend (DLT) model in Orbit API is as follows:

For more details, read our quick start guide and documentation page.
After model training, the predictions can be visualized at convenience.


Orbit also provides a rich set of plotting tools to visualize and diagnose the posterior distribution of sampling parameters and the trace of posteriors.
![]()

![]()

![]()

The Orbit package also comes with a general-purpose backtesting utility, to evaluate the time series forecasting performance. Two backtesting schemes are supported: expanding window and rolling window. Figure 2 presented earlier is an animation to visualize the forecasting results by using the expanding window scheme with 6 splits.
A Little Math
Currently, we implemented two major types of Bayesian structural time series models in Orbit:
- Seasonal Local/Global Trend Model (LGT)
- Damped Local Trend Model (DLT)
(With the OO design from Orbit, developers can create their own problem-specific models.)
LGT
LGT model is an additive model with the following forecasting equations:

where  ,
, ,
, ,
,  and
and  can be viewed as level, local trend, global trend, seasonality, and error term, respectively.
can be viewed as level, local trend, global trend, seasonality, and error term, respectively.
The update process follows a triple exponential smoothing form:

where  ,
,  and
and  are the smoothing parameters. They will be automatically estimated during the MCMC sampling process.
are the smoothing parameters. They will be automatically estimated during the MCMC sampling process.
Our LGT model is a variant based on the multiplicative model proposed by Smyl in Rlgt. Its advantages over the original Rlgt models are two-fold: first, the computation is more effective with the additive form; second, in Rlgt is parameterized with that introduces dependency in noise generation, while is refined as an independent noise in LGT. With this change, it reduces the computational cost by vectorizing the noise generation process.
One limitation in LGT, however, is that it assumes  ,
,  . To ensure this condition is satisfied, it requires that
. To ensure this condition is satisfied, it requires that  , .
, .
DLT
For use cases with  , we provide an alternative – Damped Local Trend (DLT) model, which has the following forecasting equations:
, we provide an alternative – Damped Local Trend (DLT) model, which has the following forecasting equations:

Similarly, the update process follows an exponential smoothing form:
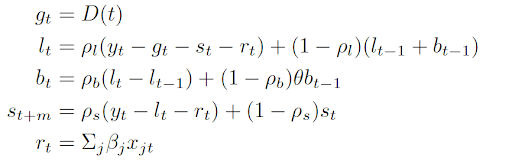
We provide flexible choices for the deterministic global trend  : the options include flat, linear, log-linear, or logistic. Another important feature of DLT is the introduction of the regression component
: the options include flat, linear, log-linear, or logistic. Another important feature of DLT is the introduction of the regression component  . This serves the purpose of nowcasting or forecasting when exogenous regressors are known, such as events and holidays. Without loss of generality, one can assume:
. This serves the purpose of nowcasting or forecasting when exogenous regressors are known, such as events and holidays. Without loss of generality, one can assume:

Beyond the normal distribution, there is a rich set of priors for the regression component implemented in the Orbit package, including Lasso, Ridge, and Horseshoe priors. To our knowledge, Orbit is one of the few packages to systematically implement all these priors for structural Bayesian time series models.
Benchmark
In order to evaluate where Orbit stands compared to other time series forecasting packages, we did a comprehensive benchmark study on a rich collection of datasets:
- Uber’s rider first trips series (20 weekly series by city)
- Uber’s driver first trip series (20 weekly series by city)
- Uber Eats first order series(15 daily series by country)
- M3 competition series (1428 monthly series)
- M4 competition series (359 weekly series)
Symmetric Mean Absolute Percentage Error (SMAPE) was used as our performance metric. Following what the competitions suggested, we used 13 forecast horizon and 18 forecast horizon, respectively, for M4 weekly and M3 monthly series with 1 split; for Uber’s datasets, we used 13 forecast horizon, 3 splits with 26 incremental steps for weekly trip series and 28 forecast horizon, 4 splits and 14 incremental steps for daily Eats order series.
We compared the Orbit models, LGT and DLT, to other popular time series models including SARIMA and Facebook Prophet. Both Prophet and Orbit models use Maximum A Posteriori (MAP) estimates and they are configured as similarly as possible in terms of optimization and seasonality settings. It’s worth pointing out that Uber’s data sets cover the Covid-19 lockdown periods across the cities. This was useful for testing how the models would perform with the presence of such extreme events. The benchmark performance table is given below. Orbit models showed competitive results compared to other models, with improved metrics ranging from 12% to 60%.

Looking forward
We already presented the Orbit-related work at the 40th International Symposium on Forecasting and StanCon 2020, where we received valuable feedback from the conference attendees. Our next major milestone for the Orbit project is to introduce more dedicated Bayesian time series models. As part of this effort, we’ll be focusing on the following priorities:
- Implementation of kernel-based, time-varying coefficient Bayesian time series model
- Capacity to deal with multivariate time series
- Integration with Uber’s ML platform Michelangelo
- Integration with Arviz for exploratory analysis of Bayesian models
To learn more about Orbit, be sure to check out repo on GitHub and our white paper on Arxiv. By open-sourcing the package, we are looking forward to more collaborations and adoptions from other Uber Data science teams and the broader data science community.
Acknowledgements
We’d like to thank the following individuals:
- Athena Dai, Mert Bay, and Sharon Shen for supporting the adoption of Orbit in many use cases at Uber.
- Dirk Beyer and Gavin Steininger for helping to review and edit this blog post.
- Sean Lopez for designing the logo of Orbit.
- Slawek Smyl and Fritz Obermeyer for being the consultants on Bayesian forecasting.

Edwin Ng
Edwin Ng is a Senior Applied Scientist at Uber where he leads the team to build statistical and machine learning models to support measurement and strategic decisions in marketing. He was one of the speakers in the 40th International Symposium on Forecasting and AdKDD 2021 where he presented probabilistics forecasting and its applications in marketing.

Yifeng Wu
Yifeng Wu is a Senior Applied Scientist on the Marketing Data Science team. Yifeng works on building the creative optimization platform and real time bidding strategies on display channels using causal inference. Yifeng is a contributor to Orbit.

Jing Pan
Jing Pan is a data scientist in the Marketing Data Science team. She is focusing on the targeting, personalization, optimization and causal inference for marketing.

Ariel Jiang
Ariel Jiang is an Applied Scientist on Uber’s Marketing Data Science team. She works on planning and forecasting, marginal benefit, and experimentation.

Steve Yang
Steve Yang is a former data scientist at Uber. Currently, Steve works on causal inference and optimization problems at Facebook Reality Labs. As a full stack data scientist, Steve’s work includes translating business problems into statistical and machine learning tasks, engineering data pipelines, deploying statistical Python packages, and productionizing models.
Posted by Edwin Ng, Lindsey Elkin, Yifeng Wu, Jing Pan, Ariel Jiang, Steve Yang







