
Introduction
This is the second installment in our series detailing the modernization of Uber’s logging infrastructure using CLP. In our last blog, we described how we split CLP’s compression algorithm into two phases: (1) distributed, row-based streaming compression that produces a compressed intermediate representation on each container or host, and (2) full columnar compression into more efficient archives. We developed a Log4j appender that uses the streaming compression and integrated it into our Spark platform. This resulted in a substantial compression ratio (169:1), which contributed to the resolution of the SSD burnouts caused by writing large amounts of log data while allowing us to extend our log retention period by 10x.
In collaboration with CLP’s developers, we have further developed an innovative end-to-end system to manage unstructured logs across Uber’s various data and ML platforms. Many log management systems, including the one described in a previous blog, tend to focus solely on search and aggregation, which are useful for developers to bootstrap a debugging session (e.g. locating an error event or detecting anomalies occurring at a certain point in time). However, to understand how and why the error occurred, developers need to further view the sequence of logs leading up to the event. Thus, search is only useful if integrated with convenient log-file viewing, a feature often overlooked by existing tools. Our new system includes advanced log viewing and programmable analytics directly on the compressed logs, unlocking the full potential of text logs using CLP. Figure 1 below shows our current end-to-end deployment. Most of the core tools and basic features described in this blog are now open source.

Unstructured & Semi-structured Logs: Their Role and Associated Challenges
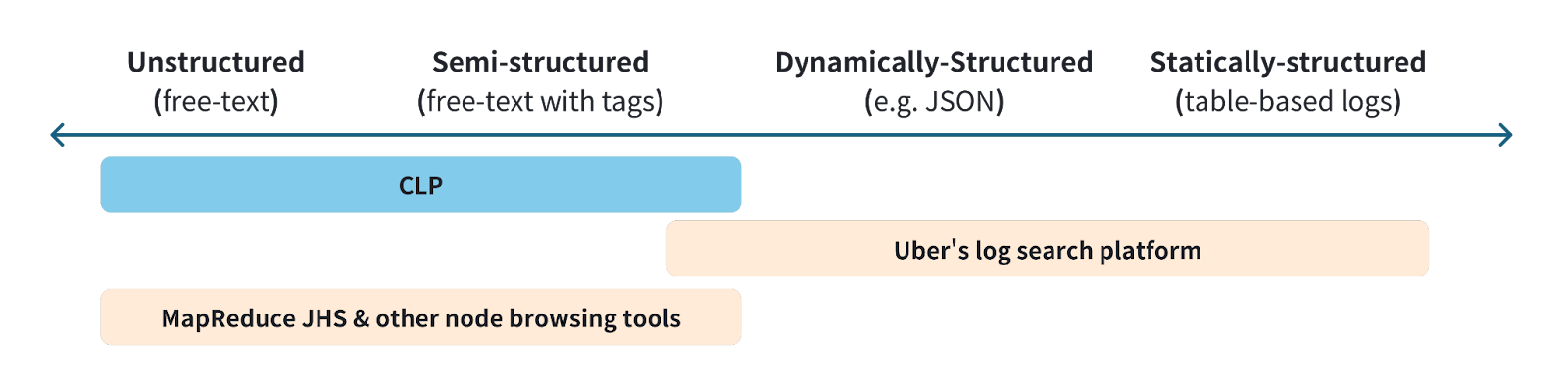
At Uber, logs are diverse and exhibit varying degrees of structure, as shown in Figure 2 above. Each unstructured or semi-structured log event is dominated by a single string containing a message intertwined with variable values. Compared to various forms of structured logs, not only are free-text logs convenient with ubiquitous cultural acceptance, they are also used for different purposes. Developers typically use such logs to describe the sequential operation of a system in an effort to allow them to reconstruct the execution flow with some context. In contrast, most structured logs exhibit properties of a trace-point that is used to record certain metrics, significant singular events, and periodic statistical information. In general, structured log events are mostly independent from each other, whereas unstructured log events collectively record an execution based on the code paths that a developer wants to track. Therefore, structured logs are typically used for monitoring purposes (e.g., detecting system errors, whereas unstructured logs are used to debug why the error occurred). This suggests the two types of logs require different types of management solutions.
When a system is small, it is not too difficult to debug using unstructured logs. Debugging can be done by simply SSH-ing into each node, viewing or grepping the logs, and diagnosing the root cause. However, as the system grows, SSH-ing into hundreds of thousands of nodes becomes unmanageable. Before our initiative, Apache Spark®, YARN®, Flink®, many Hadoop-ecosystem-based platforms, and many ML applications running on top of these platforms used the ancient MapReduce Job History Server to view their logs on each host directly. Uber also had a custom node-browsing interface (similar to SSH), but both of these tools are insufficient at Uber’s current scale. The Job History Server couldn’t scale effectively due to the sheer number of log files overwhelming the file limits of the underlying HDFS storage, coupled with a user interface that was too sluggish and unresponsive to handle the display of typical large log files. The latter method, while available and frequently used by platform maintainers, is cumbersome, insecure at best, and is not exposed to the application end-user. Thus, engineers need better tooling.
Unfortunately, there are a plethora of observability tools targeted at structured logs, but few targeted at unstructured logs. This is likely because structured logs lend themselves to being stored in a database-like backend where search and analytics can be performed and accelerated via indexing on top of tabular data (we use the term “database” to refer to any data management tool whose primary interface is search; this includes conventional RDBMSes, systems with native JSON support, NoSQL databases like Pinot, and reverse indexing tools such as Apache Lucene® that power a range of tools including Elasticsearch). As a result, developers often try to shoehorn their unstructured logs into the popular observability tool of the day; but since databases are not designed to store and analyze unstructured logs, developers are often left fighting more with the database than debugging their systems. For instance, when storing unstructured data, the database’s indices can quickly balloon in size, leading to a corresponding increase in on-disk storage and memory usage per query. In practice, retaining and searching all of Uber’s unstructured logs in such a tool would be exorbitantly costly. More importantly, it would take away the functionality that users are used to—namely, accessing and quickly viewing and analyzing individual log files.
Log Viewing
The ability to view and analyze the original log files remains an essential requirement—one that, regrettably, many existing observability tools overlook. To address this, we collaborated with the CLP development team to implement and customize a serverless log viewer that allows users to directly view the compressed logs by decompressing them on the fly, in their browser. Building on top of Microsoft Visual Studio Code’s high performance Monaco editor, the log viewer provides an intuitive and familiar interface for viewing compressed log files.
It also has many features specific to logs. For example:
- Smart Pagination to handle large log files efficiently, ones that would be unwieldy in standard text editors or command-line tools like VIM. The pagination feature lowers the browser’s memory use while allowing other features such as search to work across pages.
- Log-level Filtering to allow engineers to easily hide logs above a certain level. For example, users initially focus on critical errors and then exploratively broaden their view to info-level logs to understand the surrounding context (the log viewer makes sure to keep the cursor on the same log event when toggling between log levels, even though the pagination will change).
- Advanced Search to allow quick queries of substrings or regular expressions (users can click on a result and quickly navigate to the corresponding log event), across the pages of the log file.
- Multi-line Support to search and navigate between multi-line events (e.g., stack traces).
- Synchronized Viewing to allow viewing logs side by side, with synchronized scrolling by timestamp for cross-referencing events between different log files.
- Permanent Linking where each log event in a compressed log file has a shareable and embeddable permanent link, eliminating the need to copy-paste logs or take screenshots, streamlining collaboration and issue tracking.
- Log Prettification to automatically transform minified JSON strings, code snippets, and long lists within log events into a more readable format.
- Text Colorization to support various language modes similar to those in Visual Studio Code, along with custom modes tailored to make typical Uber logs more readable.
The GIF above shows how a user can filter the logs by their log level, and the CLP log viewer correctly recognizes a multi-line ERROR log containing a stack trace as a single log event. The capability to offer these specialized log viewing features stems from the use of CLP to parse and compress the logs, since it automatically identifies the timestamp, log level, variable values, etc.
Analytics Libraries
In addition to log viewing, which satisfies users’ basic needs, we also offer libraries for users to perform programmable analytics. The core of these libraries is developed in C++ with native bindings for Python, Go, and Java. Since CLP parses the logs as they’re compressed, the library is able to provides users with direct access to structured data such as the Unix epoch timestamp, log type (i.e. the static text portion of a log message), variables within the message, and of course the decompressed log message itself. This approach relieves users from the burden of crafting extra text parsing logic for raw messages and mitigates the runtime performance costs associated with such parsing, particularly for multi-line log messages, allowing them to concentrate on the core logic of their log analytics programs. Today, a diverse set of users use the libraries for various purposes.
For platform maintainers, the analytics library streamlines complex programmatic queries, such as analyzing log types and the frequency of permission errors within a specific application over the past 30 days. Users often conduct substring searches and then apply further aggregation and deduplication logic to the results provided by the CLP analytics library. For instance, users can use the log type of each matching event as a means to identify duplicates, rather than using the decompressed message, which might change due to variable values. This facilitates the grouping of different unstructured log events with similar structures with ease.
For on-call duties or root-cause analysis, users can create a scripted search that detects a series of specific known problematic log events or sequences of log events that meet user-defined criteria, assisting in swiftly and automatically narrowing down the scope of analysis. When a suspicious log event is identified, users can obtain its permanent link from the CLP log event object and clicking this link takes them directly to the specific matching event within the corresponding log file in the log viewer, for further in-depth analysis.
For ML teams, the analytics library facilitates the quick extraction and processing of valuable training or inference data from logs, within various environments like Jupyter Notebooks, production scripts, or locally, on a user’s development laptop. Once the analytics results are available, the data can then be used as input for automated scripts, for instance, as part of the next training batch, or compiled into analytical reports for evaluation and decision-making purposes.
Ingesting a Huge Number of Log Files
The initial log ingestion pipeline, reliant on HDFS, had a few significant limitations for our logging workload. First, HDFS couldn’t scale to meet our log retention requirements due to the NameNode struggling to maintain an index of a huge number of small log files. In addition, data access, especially on developers’ laptops or development machines outside of a walled-off production environment, was primarily hindered by complex Kerberos authentication and other access barriers. In contrast, modern object storage solutions like S3 and GCS, designed for massive scalability, can accommodate petabytes of data and billions of objects. These platforms lessen our management load by obviating the need for HDFS cluster maintenance and offer enhanced security features such as encryption at rest and during transit, along with integrated ACLs and other access control features, automatic object lifecycle (i.e., retention time) management as well as providing a higher reliability and availability. We also benefit from the pay-as-you-go model, and the flexibility to significantly boost storage needs temporarily, for instance, extending log retention period following a major security incident. Thus, we switched from uploading and storing logs on HDFS to storing them in an object store.
One key distinction between HDFS and common object stores is that HDFS employs a filesystem hierarchy whereas object stores function as flat key-value stores. Luckily, in large distributed systems, log files typically have a unique, unchanging filesystem path based on the logging entity’s hierarchy in the system, so this path works well as the key for the compressed logs. Furthermore, object stores offer APIs that facilitate key access in a manner akin to file system navigation, thereby maintaining a familiar log browsing experience.
Ensuring and Guaranteeing Log Freshness
Services like YARN and streaming applications, including Flink jobs, are typically designed for prolonged execution and are only shut down infrequently, in the event of failures, hardware replacements, or upgrades. Consequently, log uploads can’t be deferred until the “end” of a job as was feasible in Phase I with shorter-duration Spark applications. Also, object storage systems typically lack support for append operations, posing a challenge for log freshness when dealing with the upload of large log files.
Our log management includes a rotation feature that segments extensive log files into smaller, more practical chunks. We trigger the creation of a new compressed log file when the existing file hits the 16MB mark. The chosen size is a strategic compromise for object stores, maximizing compression ratio, minimizing storage and synchronization overhead while only slightly raising API access costs. Note that despite the small compressed log file size, the high compression ratio means the 16MB chunk of compressed data represents a substantial amount of uncompressed data.
To enhance log collection with near-real-time behavior and resilience, and at the same time minimize API costs associated with each upload request, our log library employs a tailored flush and upload policy specific to logging needs. We initially considered uploading logs every time they were flushed, but by default log libraries flush every time a log event is appended. This is too expensive. The libraries can also be configured to flush periodically, but this is too generic for logs. Ideally, we want an approach that changes depending on the characteristics of the logging workload. For instance, uploading sooner when important log events (e.g., ERROR-level) occur or uploading when there’s an absence of logs for a certain period of time.
Our uploading policy can be summarized as follows. Upon logging an event, the file should be uploaded after some delay 𝑆, but 𝑆 can be pushed to a later time if more log events occur before the delay expires. We call this a soft deadline. In contrast, we also maintain a hard deadline 𝐻 such that there is a guaranteed delay 𝐻 before the file is uploaded (𝐻 should be longer than 𝑆). For example, if 𝑆 is set to 10 seconds and 𝐻 is 300 seconds, it means when an event 𝐸 gets logged at time 𝑇 , it will be uploaded at 𝑇 + 10 if no other event arrives between [𝑇, 𝑇 + 10]. Otherwise, 𝐸’s upload will be delayed, but no later than 𝑇 + 300. These delays are configurable per log level, such that, for example, a user can set shorter deadlines for ERROR events than INFO ones. The delays also get reset once an upload occurs.
Effective Log File Filtering with Tags
Uber operates a huge number of internal services across various platforms, each of which has dozens of users running many jobs per day. Users often have advanced knowledge of system failures and their timing, thanks to comprehensive metrics and monitoring from integrated platform facilities or external monitoring tools. Therefore, in the majority of cases, users want to immediately limit their log search and viewing to a specific subset of compressed logs (e.g., those from a specific job, application, user, time slice, and their combination).
Our system enables flexible tagging of compressed logs with multiple identifiers, such as service ID, job ID, app ID, user ID, and timestamp range. Tags can be incorporated into object store file paths, recorded in external databases, or simply attached as object metadata and maintained by the object store. The user interface for searching and viewing logs leverages these tags allowing CLP to efficiently narrow down the log files relevant to each user’s search or viewing request.
Cross-platform Integration of CLP
Our initial integration of CLP was with Spark, leveraging a re-implementation of CLP’s C++ code-base in Java for rapid integration with Spark’s default logging framework (Log4j). Its success, reliability, and user experience improvement led to integration requests from other platform teams and application end-users, including many Marketplace and ML teams. However, this integration path posed a challenge for adoption across different applications using other logging frameworks such as Logback and other programming languages, such as Python. Instead, we utilized Foreign Function Interface (FFI) libraries for various languages (including Java, Go, and Python) that interact with the CLP’s C++ library via native bindings. By integrating these into various logging libraries for each language, we were able to integrate CLP’s distributed streaming compression seamlessly into the platform team’s codebase without needing to change the application code.
Impact
The cost-effective, distributed CLP compression and ingestion pipeline has become the preferred log ingestion and management solution for Uber’s Data team. As mentioned in our previous blog, this system has facilitated the effortless increase of our log retention period to the industry-standard 30 days, significantly reducing concerns over storage costs, maintenance complexity and availability. Furthermore, the log viewer and programmatic analysis features have gained popularity amongst end-users like the ML and Marketplace teams, as well as the platform maintained within Uber’s Data team. For example, the open-source Python CLP log analytics library has been downloaded 141,880 times, and the Python logging library plugin has seen 4,845 downloads in the last six months. The higher download rate of the analytics library reflects its wider use among engineers who analyze logs (“consumers”), compared to the number of service owners who implement the logging library plugin (“producers”).
Next Steps
We aim to focus our future efforts on three key areas:
Observability Platform Integration: Integrating CLP with the observability team’s existing log-collection infrastructure, which operates outside of application containers, reducing the severity of log loss during OOM scenarios and capturing logs not directly produced by applications (e.g., bash scripts). User experience can also be enhanced by unifying and streamlining access to both unstructured and structured logs.
Migrate Suitable Cold Logs to CLP: CLP excels with logs that don’t necessitate near-real-time search capabilities. While CLP is extremely efficient and offers fast search performance, it is not intended to replace existing online indexing-based solutions. Migrating suitable logs to the CLP platform should reduce cost and improve reliability and user experience.
Structured Log Support: CLP has introduced native support for structured logs, and its effectiveness is documented in an upcoming OSDI ’24 paper showcasing excellent compression and search capabilities for structured log data compared to existing solutions.
Conclusion
By seamlessly integrating CLP with advanced features like log viewing, programmable analytics, and efficient log ingestion, Uber has revolutionized our unstructured log management. This comprehensive system not only addresses the challenges of scalability and debugging at Uber’s immense scale but also empowers engineers across various teams with tools that streamline their workflows. As a result, Uber has achieved significant cost savings, improved log retention, and enhanced developer productivity. The open-source availability of core tools and features further solidifies CLP’s impact, fostering broader adoption and innovation within the industry. With ongoing efforts focused on platform integration, log migration, and structured log support, Uber is poised to continue leading the way in efficient and effective log management.

Gao Xin
Xin is a Staff Engineer on Uber’s Data Compute, YARN, Real Time Analytics, and Pinot team. He productionized the CLP ecosystem and spearheaded the modernization of Uber batch compute logs. He is also a contributor to the CLP open-source project.

Jack Luo
Jack is a Consulting Engineer collaborating with many Data teams—including Pinot, Flink, YARN, Spark, HDFS, and Kafka—to enhance Uber’s logging, observability, and analytics infrastructure. Jack also co-authored CLP’s academic research paper during his PhD research at University of Toronto and serves as one of the core maintainers of the CLP project.

Kirk Rodrigues
Kirk, a key maintainer of the open-source CLP project, collaborated with Jack and Xin to improve and develop Uber’s logging infrastructure. He was one of the authors and core developers of the CLP system during his PhD research at the University of Toronto.
Posted by Gao Xin, Jack Luo, Kirk Rodrigues
Related articles





Most popular

Building Uber’s Multi-Cloud Secrets Management Platform to Enhance Security

Introducing Advantage Mode & Standard Mode
NJ Driver Surcharge
