Manifold: A Model-Agnostic Visual Debugging Tool for Machine Learning at Uber
Machine learning (ML) is widely used across the Uber platform to support intelligent decision making and forecasting for features such as ETA prediction and fraud detection. For optimal results, we invest a lot of resources in developing accurate predictive ML models. In fact, it’s typical for practitioners to devote 20 percent of their effort into building initial working models, and 80 percent of their effort improving model performance in what is known as the 20/80 split rule of ML model development.
Traditionally, when data scientists develop models, they evaluate each model candidate using summary scores like log loss, area under curve (AUC), and mean absolute error (MAE). Although these metrics offer insights into how a model is performing, they do not convey much information regarding why a model is not performing well, and from there, how to improve its performance. As such, model builders tend to rely on trial and error when determining how to improve their models.
To make the model iteration process more informed and actionable, we developed Manifold, Uber’s in-house model-agnostic visualization tool for ML performance diagnosis and model debugging. Taking advantage of visual analytics techniques, Manifold allows ML practitioners to look beyond overall summary metrics to detect which subset of data a model is inaccurately predicting. Manifold also explains the potential cause of poor model performance by surfacing the feature distribution difference between better and worse-performing subsets of data. Moreover, it can display how several candidate models have different prediction accuracies for each subset of data, providing justification for advanced treatments such as model ensembling.
In this article, we discuss Manifold’s algorithm and visualization design, as well as explain how Uber leverages the tool to gain insights into its models and improve model performance.
Motivation behind Manifold
Given their complexity, ML models are intrinsically opaque. As ML becomes increasingly integral to Uber’s business, we need to equip users with tools to make models more transparent and easy-to-understand; only then will they be able to use ML-generated predictions with confidence and trust. ML visualization, an emerging domain, solves this problem.
Previous approaches to ML visualization generally included directly visualizing the internal structure or model parameters, a design constrained by the underlying algorithms and therefore not scalable to handle company-wide generic use cases.1,2,3
To tackle this challenge at Uber, we built Manifold to serve the majority of ML models, starting with classification and regression models.4 We also developed Manifold to offer transparency into the black box of ML model development by surfacing feature distribution differences between subsets of data.
With Manifold’s design, we turned the traditional ML model visualization challenge on its head. Instead of inspecting models, we inspect individual data points, by: (1) identifying the data segments that make a model perform well or poorly, and how this data affects performance between models, and (2) assessing the aggregate feature characteristics of these data segments to identify the reasons for certain model behaviors. This approach facilitates model-agnosticism, a particularly useful feature when it comes to identifying opportunities for model ensembling.
Visualization and workflow design
In addition to the research prototype built in [4], we focused on surfacing important signals and patterns amid massive, high-dimensional ML datasets. In the following sections, we discuss Manifold’s interface and user workflow, dive into our design considerations, and explain the algorithms that enabled this type of visual analytics.

The interface of Manifold is composed of two coordinated visualizations:
- Performance Comparison View, consisting of a multi-way plot with violin encoding, compares performance between models and data segments.

- Feature Attribution View, consisting of two sets of feature distribution histograms, compares the features of two selected data segments.
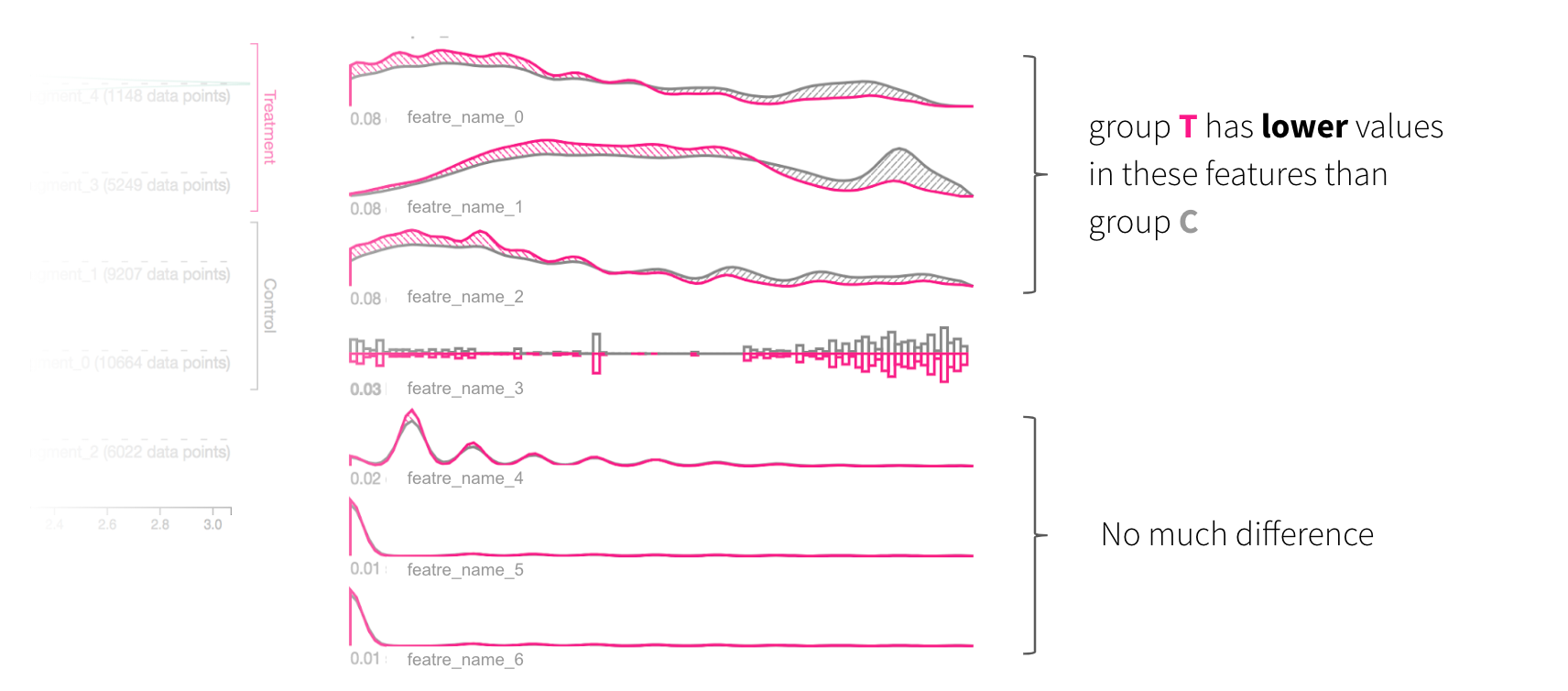
Manifold helps users uncover areas for model improvement through three steps:
- Compare: First, given a dataset with the output from one or more ML model(s), Manifold compares and highlights performance differences across models or data subsets (Figure 3a.)

- Slice: This step lets users select data subsets of interest based on model performance for further inspection (Figure 3b.)

- Attribute: Manifold then highlights feature distribution differences between the selected data subsets, helping users find the reasons behind the performance outcomes (Figure 3c.)

Our goal with Manifold is to compare how different models perform on various data points (in other words, feature values). As a design alternative, a straightforward implementation of this visualization is depicted in Figure 4, below:

In Figure 4, each point in the plot represents the performance of model x on data point y. While the concept works in theory, in practice there are three main challenges with this approach:
- There are too many points in the point cloud to clearly identify patterns; some abstraction or reduction of the points is needed to reveal patterns.
- It’s difficult to pinpoint which features are most valuable for the y-axis to use in order to identify relevant patterns in the point cloud.
- It becomes more difficult to compare different models as the number of models increases.
To preemptively tackle these issues, we implemented the following aggregation/simplification: instead of representing each data point separately, we group them into subsets. Instead of using the y-axis to encode the value of a particular feature, we turn it into a categorical axis representing different subsets of data. This approach evolved into our final performance chart, leading to these two significant benefits:
- Data points that are essentially similar will not be duplicated on the chart. Only the most prominent, high-level differences are highlighted.
- Since the number of shapes in the chart is reduced, different models can be plotted on the same chart to make better comparisons.
The key to revealing patterns in the tool’s Performance Comparison view was to divide the test dataset into subsets. In Manifold, subsets are auto-generated using a clustering algorithm based on one or more performance columns. This way, data with with similar performance in regards to each model is grouped together (because the algorithm ensures the performance of Model X for different data points in Subset Y to be consistent with each other). Figures 5 and 6, below, illustrate this process:

 |  |
Figure 6. On left: Performance metrics are used as inputs to the clustering algorithm run in Manifold. On right: Users can alter clustering parameters to explore patterns in the dataset.
Manifold architecture
Since generating Manifold visualizations involves some intense numerical computations (clustering, KL-divergence), subpar computation performance slows down UI rendering and affects the overall user experience. With this in mind, we started implementing all heavy-weight computations in Python, utilizing its optimized DataFrame processing and ML libraries (such as Pandas and Scikit-Learn).
However, having to rely on a Python backend made Manifold less agile and harder to componentize, which became a drawback when it came to integrating Manifold with the larger ML ecosystem at Uber, for example, our ML platform, Michelangelo. Therefore, in addition to Python computation, we added a second user workflow path with GPU acceleration entirely written in JavaScript, a much more agile language.
Figure 7, below, depicts how the two workflows integrate with Manifold:

Users can leverage Manifold in two ways: via a Python package or an npm package (through a web page). Since code reusability and modularity is crucial for the coexistence of two workflows, both the Python and JavaScript codebases are organized into three different functional modules:
- Data transformer, a feature that adapts data formats from other internal services (e.g. Michelangelo) into Manifold’s internal data representation format
- Computation engine, a feature that is responsible for running clustering and other data-intensive computations
- Front-end components, the UI of the Manifold visual analytics system (its Python package uses a built-in version of JavaScript front-end components)
Unlike its Python counterpart, handling data-intensive computation is a challenge for our JavaScript computation engine. For users to see meaningful patterns, it requires about 10,000 data records (“rows”). The clustering and computation of KL-divergence, among other actions, would need to happen in the frontend, which could pose a bottleneck to speed and severely detract from the user experience. In fact, based on our experiments, computation implemented in plain JavaScript could take more than ten seconds in the browser each time a user updates the number of clusters in the performance comparison view.
Instead, we make use of TensorFlow.js as a linear algebra utility library to implement our k-means clustering and KL-divergence computations. Because this type of computation could be vectorized and therefore accelerated using WebGL through TensorFlow.js, the same task of updating the number of clusters could be completed within sub-seconds—over 100x the original performance.
Being componentized and contained within an npm package gives Manifold the flexibility to be used as a standalone service, as well as integrated into other company-wide ML systems like Michelangelo. Because most visualization tool boxes for ML require extra computation processes beyond what is included in the model training backend, integrating them with enterprise ML systems can be cumbersome or unscalable. Manifold proposes a solution to this situation by handling computation needed in the visual analytics system separately from those needed for training models, and therefore enabling faster iteration and a cleaner data interface.
Using Manifold at Uber
ML-focused teams across Uber leverage Manifold for everything from ETA prediction to make better sense of driver safety models. Below, we walk through two of our most common use cases: identifying useful features of ML models and eliminating false negatives in model results. In these instances, Manifold empowers data scientists to discover insights that guide them through the model iteration process.
Identifying useful features
The Uber Eats team used Manifold to evaluate the effects of a new model that predicts order delivery time. During model iteration, they integrated an extra set of features which they thought had the potential of improving the performance of the existing model. However, after they incorporated these features, the model’s overall performance was barely altered. Why were the new features not helping? Should they give up on the idea of using those features or was there something else to blame for this sub-par performance?
To answer these questions, they used the models depicted in Figure 8, below—an original model (green) and a model trained with extra features (orange)—as inputs to Manifold. All other aspects of these two models were identical.

Figure 8, above, depicts this analysis as represented by Manifold’s data visualizations. As depicted, the test dataset was automatically segmented into four clusters based on performance similarity among data points. For Clusters 0, 1, and 2, the model with additional features provided no performance improvement. However, the performance of the new model (the one with extra features) was slightly better in Cluster 3, as indicated by a log-loss shifted to the left.
Since the data segment in Cluster 3 was poorly predicted by the original model, (as indicated by its higher log-loss value than those of other clusters), we believe that the features were valuable to their model since they appeared to tackle some of the hardest individual cases, like those represented in Cluster 3.
Eliminating false negatives
In a different example, Uber’s Safety team used Manifold to improve the performance of a binary classification model which identifies trips that might incur safety incidents. Specifically, they wanted to eliminate the number of false negatives that were generated by their model (instances that should be predicted as having a Positive label, but the model have failed to capture), and to do so, they needed to determine the reason why their model would predict a Positive instance as Negative in those situations.
To achieve this purpose, they filtered out all instances in a test dataset labeled as Negative, and then compared the differences among cases labeled as Positive. They set the x-axis metric of the Performance Comparison chart to “actual prediction score” (1), increased the number of clusters (2), and compared the subsets whose values are below and above the decision threshold (3), as depicted in Figure 9, below:

As a result, we noticed that there were several features (A, B, C, D, E) showing notable distribution differences between the true positive group (grey) and the false negative group (pink), shown in Figure 10, below. In other words, if a data point has low values in features A, B, C, or D, and its true label is Positive, the model tends not to predict value E correctly.

To further drill down to the root cause of these false negatives, we directly compared the feature distributions of the Positive group and the Negative group, as depicted in Figure 11, below:
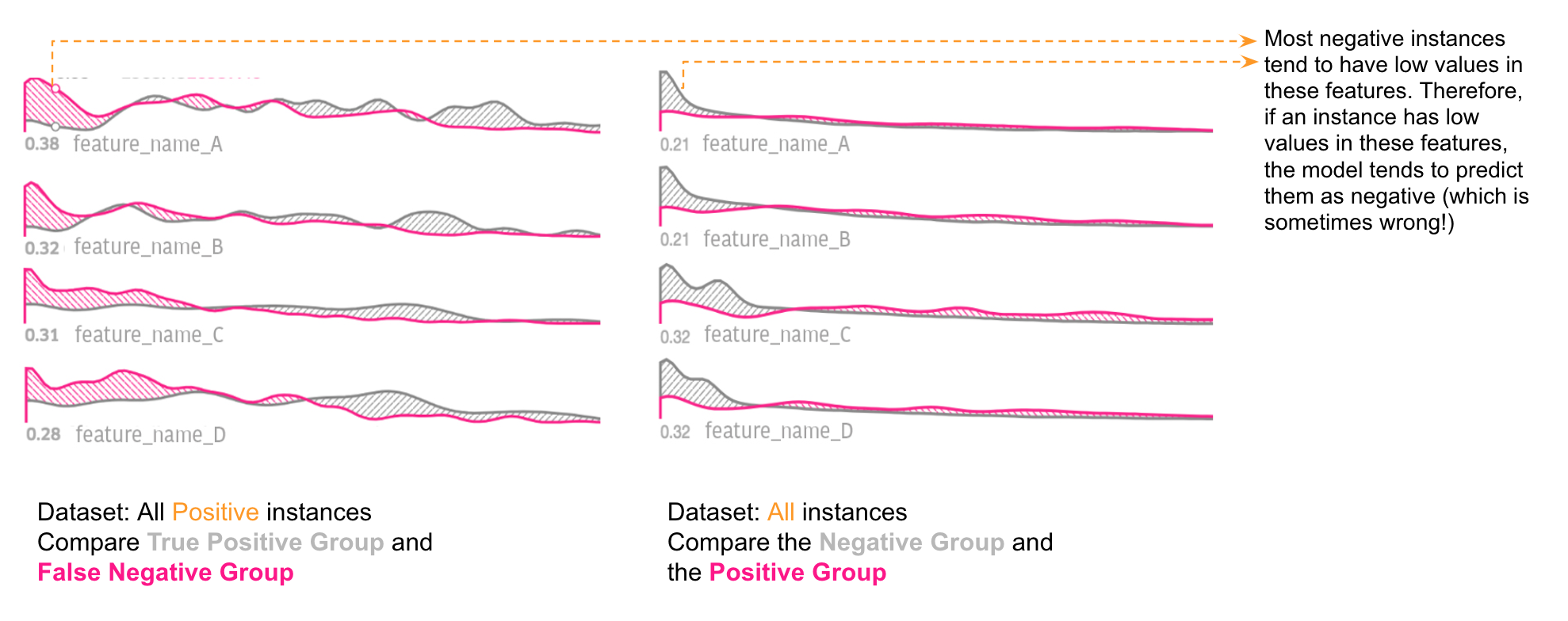
We noticed that most true Negative instances also tended to have low values in features A, B, C, or D. Therefore, if an instance has low values in these features, the model tends to predict them as negative (which is sometimes wrong!). After conducting this analysis with Manifold, they realized that the model was over-indexing on these features. To improve performance, they could either find more features that could help distinguish the false negatives from true negatives or train a separate model for the data partition where these features were below a certain threshold.
Next steps
Since launching Manifold in August 2018, the tool has become an integral component of Uber’s ML model development process. Manifold’s three primary benefits include: model-agnosticism, visual analytics for model performance evaluation that look beyond model performance summary statistics for inaccuracies, and the ability to separate visual analytics system and standard model training computations to facilitate faster and more flexible model development.
Currently, Manifold is a standalone web tool and a Python package. To increase Manifold’s functionality, we plan on integrating the of Manifold toolbox into Uber’s myriad data science platforms, further establishing the tool as a key part of our broader data science workflow. By doing so, we will be able to truly grow the potential of Manifold’s data-agnosticism against various data science usage scenarios across the company. From there, we intend to make design improvements based on these applications, thereby enabling more robust support of these use cases.
If tackling large-scale engineering problems with machine learning and data visualization interests you, consider applying for a role on our team!
Acknowledgements
We would like to thank Uber’s Visualization and Machine Learning Platform teams for their support during the development of this project. We also thank Uber AI Labs’ Piero Molino and Jiawei Zhang for working with us on the ideation and the research prototype of Manifold, as well as Uber data scientists Le Nguyen and Sunny Jeon for their invaluable support while we built this tool.
References
- M. Kahng, P. Y. Andrews, A. Kalro and D. H. Chau, “ActiVis: Visual Exploration of Industry-Scale Deep Neural Network Models,” in IEEE Transactions on Visualization and Computer Graphics, vol. 24, no. 1, pp. 88-97, Jan. 2018.
- Y. Ming, S. Cao, R. Zhang, Z. Li, Y. Chen, Y. Song, and H. Qu. Understanding hidden memories of recurrent neural networks. arXiv preprint arXiv:1710.10777, 2017.
- L. Padua, H. Schulze, K. Matkovic, and C. Delrieux. Interactive ´ exploration of parameter space in data mining: Comprehending the predictive quality of large decision tree collections. Computers & Graphics, 41:99–113, 2014
- J. Zhang, Y. Wang, P. Molino, L. Li and D. S. Ebert, “Manifold: A Model-Agnostic Framework for Interpretation and Diagnosis of Machine Learning Models,” in IEEE Transactions on Visualization and Computer Graphics, vol. 25, no. 1, pp. 364-373, Jan. 2019.
Lezhi Li
Lezhi Li is a software engineer on Uber's Machine Learning Platform team.
Tim