Open Sourcing Manifold, a Visual Debugging Tool for Machine Learning
In January 2019, Uber introduced Manifold, a model-agnostic visual debugging tool for machine learning that we use to identify issues in our ML models. To give other ML practitioners the benefits of this tool, today we are excited to announce that we have released Manifold as an open source project.
Manifold helps engineers and scientists identify performance issues across ML data slices and models, and diagnose their root causes by surfacing feature distribution differences between subsets of data. At Uber, Manifold has been part of our ML platform, Michelangelo, and has helped various product teams at Uber analyze and debug ML model performance.
Since highlighting this project on the Uber Eng Blog earlier this year, we have received a lot of feedback from the community regarding its potential in general purpose ML model debugging scenarios. In open-sourcing the standalone version of Manifold, we believe the tool will likewise benefit the ML community by providing interpretability and debuggability for ML workflows.
New features in version 1
In our first open source version of Manifold, we added various features to make model debugging even easier than in our in-house iterations.
Features in the version 1 release include:
-
- Model-agnostic support for general binary classification and regression model debugging. Users will be able to analyze and compare models of various algorithm types, enabling them to discern performance differences with regards to diverse data slices.
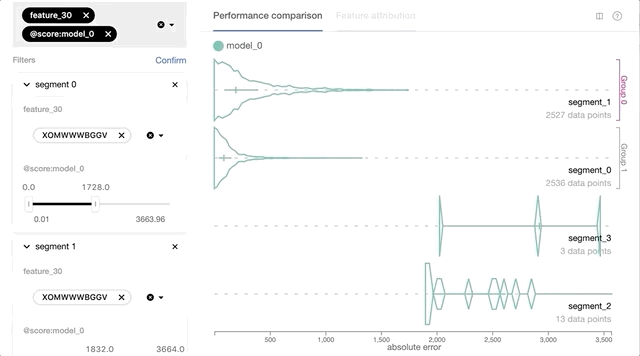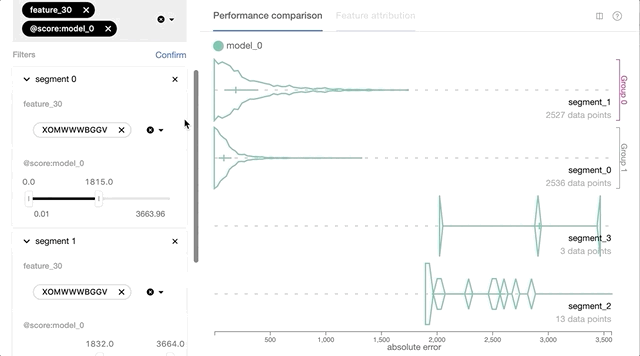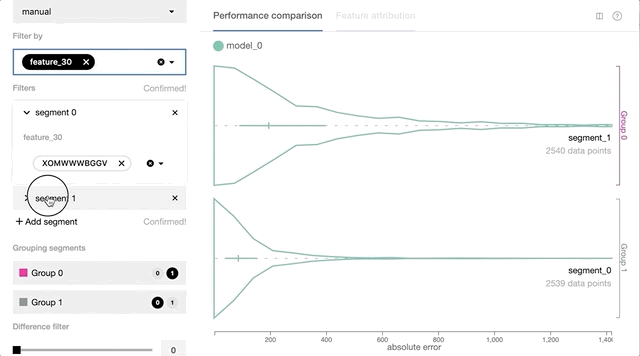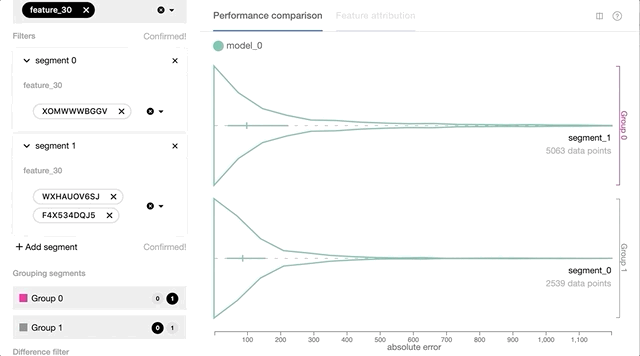
- Visualization support for tabular feature input including numerical, categorical, and geospatial feature types. Using the feature value distribution information of each data slice, users can better understand the potential cause for certain performance issues, for instance, if there’s any correlation between the model’s prediction loss and the geo-location and distribution of its data points.

-
- Integration with Jupyter Notebook. Through this integration, Manifold accepts data input as Pandas DataFrame objects and renders a visualization of this data within Jupyter. Since Jupyter Notebook is one of the most widely adopted data science platforms for data scientists and ML engineers, this integration enables users to analyze their models without breaking their normal workflows.

-
- Interactive data slicing and performance comparisons based on per-instance prediction loss and other feature values. Users will be able to slice and query data based on prediction loss, ground truth, or other features of interest. This functionality will enable users to quickly validate or reject their hypothesis through versatile data slicing logic.
Next steps
The open source version of Manifold comes with an npm package version and, for the Jupyter Notebook binding, a Python package version. To get started, follow the docs in the github repo and install it locally, or check out our demo website.
We encourage you to try Manifold for yourself and look forward to hearing your feedback!
Lezhi Li
Lezhi Li is a software engineer on Uber's Machine Learning Platform team.