Handling Flaky Unit Tests in Java
Introduction to Flaky Tests
Unit testing forms the bedrock of any Continuous Integration (CI) system. It warns software engineers of bugs in newly-implemented code and regressions in existing code, before it is merged. This ensures increased software reliability. It also improves overall developer productivity, as bugs are caught early in the software development lifecycle. Hence, building a stable and reliable testing system is often a key requirement for software development organizations.
Unfortunately, by definition, flaky unit tests undercut this requirement. A unit test is considered flaky if it returns different results (pass or fail) on any two executions, without any underlying changes to the source code. A flaky test can occur either due to program-level non-determinism (e.g., thread ordering and other concurrency issues) within the test code or the code being tested. Alternatively, it can occur due to variability in the testing environment (e.g., the machine on which it is executed, the set of tests that are executed concurrently, etc.). While the former requires fixing the code, the latter involves identifying the reasons that resulted in the non-determinism, and addressing them to remove the flakiness. The testing of both code patterns and infrastructure must be geared towards diminishing the potential for flaky tests to arise.
Flaky tests affect developer productivity across multiple dimensions. First, when a test fails due to extraneous reasons, the underlying issue has to be investigated, which can be time-consuming, given the non-deterministic reproducibility of the failure. In many cases, reproducing the failure locally may be impractical, as it requires specific test configurations and execution environments to manifest the error. Second, if the underlying root cause for the flakiness cannot be identified, then the test has to be retried sufficiently during CI so that a successful run of the test is observed and accompanying code changes can be merged. Both aspects of this process waste critical development time, thus necessitating building infrastructural support for handling the problem of flaky unit tests.
We elaborate this problem further using a simple, illustrative example:
private static int REDIS_PORT = 6380;
…
@Before
public void setUp() throws IOException, TException {
MockitAnnotations.initMocks(this);
…
server = RedisServer.newRedisServer(REDIS_PORT);
…
}
In the setUp method that is executed before unit tests are run, a connection to the RedisServer is made on port 6380 as defined by REDIS_PORT. When the associated unit tests are run locally on a developer machine, in the absence of bugs, the tests will complete successfully. However, when this code is pushed to CI and the associated tests are run in a CI environment, the tests will only succeed if the port 6380 is available in the environment when the setUp method runs. If there are other, concurrently executing unit tests in the CI environment that are already listening on the same port, then the setUp method in the example will fail with a “port already in use” bind exception.
Generally speaking, reproducing the cause of flakiness requires a developer to understand the location of the flakiness (e.g., hard coding a port number in the example above). This is a cyclical problem, since there can be many manifestations of flakiness, and similar immediate “causes” (e.g., Java exceptions or test failure types) can correspond to very different root causes, earlier in the test execution, as shown below in figure 1. Furthermore, to reproduce the exceptional stack trace, the environment should be set up appropriately (e.g., the test that connects to the same port should also execute concurrently).

At Uber, the pain point due to flaky tests was further exacerbated when we combined individual repositories into a single, monolithic repository in order to leverage the many centralized benefits associated with developing on a monorepo. This includes the ability to manage dependencies, testing infrastructure, build systems, static analysis tooling, etc., by centralized teams, which reduces the overall costs associated with managing these systems for individual repositories, and ensures consistency across the organization.
However, the migration to monorepo surfaced the problem of flaky tests affecting developer productivity. Tests that were not necessarily flaky in the individual repositories became flaky in the resulting monorepo, due to the far more complex execution environment, and number of tests being run simultaneously. Since the tests were not originally designed to run at monorepo scale, the fact that significant flakiness was created or exposed when migrating them to monorepo was not surprising.
In the rest of this post, we will explain our approach to mitigating the impact of flaky tests. We will discuss the design of a Test Analyzer Service that is used to manage the state of unit tests and to disable flaky tests. Subsequently, we will explain our efforts in categorizing the various sources of flakiness and building program analysis tools (automated reproducers, as well as static checkers) to help reproduce flaky failures and prevent adding new flaky tests in the monorepo. Finally, we will share what we learned from this process.
Managing Flaky Tests Using Test Analyzer
Our immediate goal when addressing the problem of flaky tests was to differentiate the stable and flaky tests in the monorepo. At a high level, this can be achieved by executing all the unit tests in the main branch of the monorepo periodically and recording the history of the last k runs associated with each test. Since these tests are already part of the main branch, they are expected to succeed unconditionally. If a test fails even once in the last k runs, it is classified as flaky and handled separately.
For this purpose, we built a generic Test Analyzer tool that helps in analyzing and visualizing unit test reports for Uber’s testing needs at scale. The core of the tool is called the Test Analyzer Service (TAS), which consumes the data associated with executing tests and processes it to generate data that can be visualized and analyzed by individual developers. The analysis captures a multitude of test metadata, including time to execute a test, the frequency of test executions, last succeeded time, etc. This service is run for language-specific monorepos at Uber, and hence stores the processed information for hundreds of thousands of unit tests across them. Each monorepo has multiple CI pipelines that execute tests regularly and feed test reports into TAS. Recent data is stored in a local database, while long-term results are stored in a data warehouse for historical analysis. We leveraged TAS and set up a custom pipeline whose goal is to run all unit tests in the main branch of the monorepo, in order to help identify and separate flaky tests.
The architecture diagram below shows the flow of work, starting with the CI job that runs the tests and feeding the results into TAS through a Test Handler CLI, the results of which are stored in local DB and a data warehouse. TAS exposes this data via APIs for visualization in the Test Analyzer UI and also for further analysis. The code review tools have integration into the Test Analyzer tool for visualizing the results, and to better understand test failures.

For the purposes of flaky test detection, we use the following data captured by Test Analyzer:
- Test case metadata:
- Test name
- TestSuite name
- Target name identifying a build rule in the project.
- Test result
- Time to run test
- Number of consecutive successful runs
- Stack traces for each failing test run, if available
- Current state of test case (stable or flaky)
We use this information to classify all tests on the main branch with 100 consecutive successful runs as stable, and the remaining tests as flaky. Based on this, a flaky test disabler job periodically disables flaky tests from contributing to the results associated with CI. In other words, failures associated with flaky tests are ignored when running tests for new code changes. Figure 3 below illustrates this scenario:

As the results of flaky tests are ignored when code changes merge, this reduces their impact on developers merging changes to the monorepo. Of course, this can affect reliability because the functionality tested by the flaky test is untested for the duration of the test being categorized as flaky. This is a deliberate tradeoff that we undertook to keep the development engine running. This issue is ameliorated to an extent when developers fix the flaky tests and they are subsequently recategorized as stable after consecutively succeeding for 100 runs on the custom CI pipeline.
While differentiating between flaky and stable tests was a necessary step in handling this problem, this did not address the problem comprehensively because:
- Tests were being ignored, which affects software reliability and eventually developer productivity, due to chasing the resultant bugs
- Developers did not have infrastructural support to triage and fix flaky tests, which resulted in a significant fraction of tests classified as flaky being unfixed, since developers had no good way to reproduce (and thus debug) the test failure
Reducing Flaky Tests
We addressed the problem of flaky test reduction in a layered manner.
Initially, we manually categorized and prioritized the key reasons behind flakiness, and fixed the underlying infrastructural problems. This helped drive down the total number of flaky tests, but was not scalable, as this process could not easily handle the long tail of flaky test symptoms and root causes. Furthermore, centralized developer experience teams were not resourced to handle triaging all problematic test cases, nor often aware of the team-specific context of what each test was intending to verify (and thus the right way to fix their particular flakiness issues).
Therefore, to enable any developer to triage flaky failures, we built dynamic reproducer tools which can be used to reproduce the failure locally. Additionally, to reduce the growth of flaky tests in the monorepo, we built static checkers to prevent new tests with known sources of flakiness from being introduced into the monorepo. In the rest of this section, we discuss those strategies in detail.
Various Categories of Flakiness
A flaky test can exhibit flaky behavior independently or be flaky due to external factors, such as runtime environment/infrastructure, or dependent libraries/frameworks. To understand this, we classified the reasons for failures by analyzing the stack traces. From the initial data we found that the majority of flaky tests were due to external factors, such as:
- Highly parallel run environment: Before moving to a monorepo, each subrepo would have their tests run sequentially. Monorepo tests are run in parallel, which can lead to CPU/memory contention, resulting in erratic failures.
- Embedded databases/servers: Many tests use embedded databases (e.g., cassandra, mariadb, redis) with their own logic for starting/stopping and cleaning up their state. These custom implementations often had subtle bugs, which would lead to a bad state if the embedded server failed to start. Subsequently, the rest of the tests using the embedded database would fail in the parallel run environment.
- Port collisions:
- The embedded databases/servers would often have hard-coded ports, which made tests unreliable when they were run in parallel on CI.
- Spark by default starts up a UI server, which was often not disabled during testing. The UI server uses a fixed port, which led to port binding failures, resulting in flakiness whenever two tests involving spark ran together.
Since the majority of flaky tests were due to external factors, we started tackling them in a centralized manner:
- We migrated tests which used embedded databases to access the containerized databases, instead of by leveraging the testcontainers library.
- This helped in decoupling the implementation, along with stabilizing the start and stop process of test databases
- The databases now run on their own containers, thereby resolving the unavailable port issue as each container is assigned a random available port
- The testcontainers library was used for MariaDB, Cassandra, Redis, Elasticsearch and Kafka
- For Spark tests, Spark UI was disabled during testing, as none of our tests depended on the Spark UI being shown, which removed flakiness.
While fixing these infrastructural causes for flakiness, we also simultaneously embarked on building reproducer tools to handle flakiness that still inevitably occurs.
Reproducing Flaky Tests
A roadblock faced by developers in handling flaky tests was their inability to investigate the root cause of flakiness. This was mainly due to their inability to reproduce these failures reliably. Therefore, based on the categorization of the flaky tests and our own analysis of fixes to other flaky tests, we built dynamic reproducer tools to enable the reproduction of observed flaky test failures.
We built a system where a developer can input the details of a test and trigger an automated analysis associated with it. Our analysis will execute the test under various scenarios, in order to help reproduce the underlying problem. Specifically, it will:
- Run just the input test
- Run all the tests in the input test class
- Run all the tests in the test target
- Run the test under port collision detection mode.
- Repeat steps 1 – 3 while increasing the resource load on the system
The first three categories of executing the tests are to handle any local issues within the test method, class, or target. For instance, in a few cases, running the test method alone without other tests in the class can help in reproducing failures, due to dependencies between the appropriate tests (i.e., unit tests not really being independent, but expecting state setup by other tests in the same test class). Applying this simple heuristic helped uncover a non-trivial number of flaky tests.
Based on our analysis, we had also noticed that there were many flaky tests categorized under port collisions. We observe that detecting the combination of tests that access the same ports depends on simultaneously invoking the appropriate combination of tests. Applying this strategy on a collection of hundreds of thousands of tests is not practically feasible. Instead, we designed an analysis which executes each test independently, but identifies potential sources of port collision with any other possible tests.
For this, we use the Java Security Manager to identify the set of ports accessed by the test. A separate process, named Port Claimer, is spawned to bind and listen on the identified port (on both IPv4 and IPv6). While the Port Claimer listens, the test is re-executed and any new set of ports accessed are identified, and then subsequently acquired by the Port Claimer. This analysis is repeated a few times to gather the potential set of ports used by the test. If a constant port is used, then one of the re-executions of the test will fail because Port Claimer is listening on the port identified previously. Otherwise, a new port can be accessed by the test. By repeating this process a few times, we can overcome usage of a constant set of ports by a test. If the execution of a test fails, then we can output a simple reproducer command that will spawn Port Claimer to connect a set of identified ports, and then execute the flaky test under consideration. This can be then used by a developer to triage the problem locally and fix the root cause.
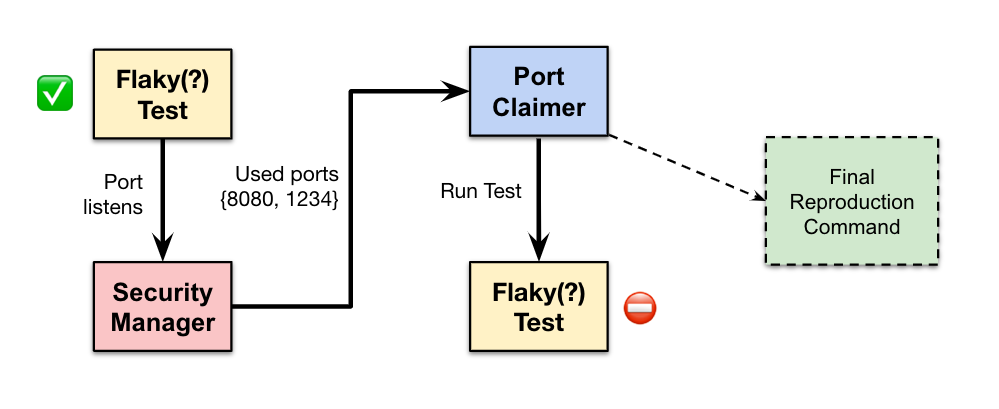
This process is depicted above in Figure 4. A flaky test may succeed when run independently. Security manager is used to listen to the ports accessed by the test, and that information is provided as input to the Port Claimer process. When the test is executed along with Port Claimer holding onto the identified ports, and the test fails, a reproducer command is generated. This command can be used to help developers deterministically reproduce the problem locally, by claiming the identified ports and running the test under those conditions.
Finally, we also run the tests under additional load on the node. We achieve this by spawning multiple processes (similar to the stress command) and ensure that the tests succeed under these high-CPU-load conditions. If the tests have timing dependencies encoded internally—another common source of flakiness—then this flakiness can be immediately reproduced. We use the corresponding data to output a reproducer command that can be used by a developer to triage the problem locally by running the test under the required stress load.
Crowdsourcing the Fixes to Flaky Tests
The categorization of flaky tests described above helped in addressing the infrastructure-related failures and other types of failures that could be centrally handled. In order to scale the process of fixing the flaky tests, we crowdsourced the fixes from engineers across Uber, and performed this at multiple levels: driving the fixes during “Fix It Week” events targeting all developers committing code to the monorepo, and engaging specific teams with the highest fraction of flaky tests.
Our focussed deployment efforts, along with the infrastructural and tooling support to reproduce the flaky failures, led to significant reductions in the overall percentage of flaky tests within a short span of time. Building a reproducer infrastructure also has ensured that newer flaky tests can be easily triagged and fixed by developers periodically.
Static Checks
Removing existing flaky tests after they have been merged into the monorepo is only one part of the equation. In order to provide a stable CI over time, we ideally want to also reduce the rate at which new flaky tests are introduced in the first place.
We wish to do this without incurring the extra cost of running multiple dynamic reproducers on the full set of tests for every code change. A comprehensive dynamic analysis approach would require us to run many tests per code change to look for potentially conflicting test cases. It would also require running test cases multiple times under different dynamic flakiness reproducers. Since such overhead would have an unacceptable impact on developers’ workflows at code review time, the natural solution is to use some form of lightweight static analysis (a.k.a., linting) to look for patterns known to be associated with flakiness in newly added or modified tests.
At Uber, we use Google’s Error Prone framework primarily for build-time static analysis of Java code (see also: NullAway, Piranha). As part of our comprehensive effort on reducing test flakiness, we have begun implementing simple Error Prone checkers to detect code patterns that are known to introduce flakiness in our CI testing environment.
When a test matches any of these patterns, an error will be triggered during compilation—this happens locally, as well as on CI—prompting the developer to fix (or suppress) the issue. We monitor the rate at which these checks fire through analytics tracking and keep track of the rate at which individual checks are suppressed.
In the rest of this section, we will focus mostly on one particular static check example: our ForbidTimedWaitInTests checker.
For example, consider the following code using Java’s CountDownLatch:
final CountDownLatch latch = new CountDownLatch(1);
Thread t = new Thread(new CountDownRunnable(latch));
t.start();
assertTrue(latch.await(100, TimeUnit.MILLISECONDS));
…
Here, the developer creates a latch object, with a countdown of 1. This object is then passed to some background thread t, which will presumably run some task (abstracted here as a CountDownRunnable object) that will signal completion by calling latch.countDown().
After starting this thread, the test code calls latch.await, with a 100 milliseconds timeout. If the task completes within 100 milliseconds, then this method will return true and the JUnit assert call will succeed, continuing onto the rest of the test case. However, if the task fails to be ready within 100ms, the test will fail with an assertion failure. It is very likely that a 100ms timeout is always enough for the operation to complete when the test is run on its own, but far too short a timeout under high CPU stress.
Because of this, we take the somewhat opinionated step of discouraging bounded versions of the latch.await(…) API call in test code, and replacing them with unbounded await() calls. Of course, unbounded awaits have their own problems, leading to potential process hangs. However, since we enforce this convention only on test code2, we can rely on carefully selected global unit test timeout limits to detect any unit test that would otherwise run indefinitely. We believe that this is preferable to trying to somehow statically estimate “good” timeout values for specific operations in unit tests.
Besides Java’s CountDownLatch, our check also handles other APIs introducing flakiness due to dependency on wall clock times. As a side note, we explicitly allow testing code that uses bounded waits if our checker identifies that the operation is expected to always timeout, which is not a source of flakiness under stress.
What is the Impact of These Changes for a Developer?
Developers put up code changes, which go through CI for identifying any compilation or test failures, and if builds are successful on CI, developers merge their changes using a custom internal tool, called SubmitQueue (SQ). Flaky tests lead to failed CI and SQ jobs, which previously were not actionable by developers, negatively affecting development speed and their ability to deploy and release new features.
The various steps and tools mentioned above reduced the failures in CI/SQ jobs run by developers, and also led to reduction in CI resource usage by avoiding several re-runs and reduced CI run times. With the number of flaky tests significantly reduced (by around 85%), we were further able to enable reruns of the test cases that fail during CI, to determine if they could be flaky, and if so pass the build anyways (without having to wait for TAS to remove the flaky test). This approach removed all effects of flaky tests on both CI and SQ resulting in a big win for software reliability and developer productivity.
Future Directions
Besides the work described above, we are looking into more opportunities to reduce flaky tests, including:
- More general systems to detect root causes of flakiness, including concurrency bugs and generalized interactions between test cases
- Tools to assign reproducible flaky tests failures to individual engineers with the relevant ownership and domain area context
- Extending our dynamic reproducers and static checkers to handle other sources of flakiness (e.g.,we are working on static checks to prevent hard-coded port numbers from appearing in tests, including those that arise from library defaults and configuration files)
- Improving the efficiency of running our dynamic reproducers, possibly getting them to run at code review time
- Extending our tooling to handle flaky unit tests in other major language-specific Uber monorepos (e.g., Go)
Acknowledgements
We would like to thank other contributors (in alphabetical order) to this project: We would like to thank several contributors from Developer Platform teams across Amsterdam and US who have contributed to this project including Maciej Baksza, Raj Barik, Zsombor Erdody-Nagy, Edgar Fernandes, Han Liu, Yibo Liu, Thales Machado, Naveen Narayanan, Tho Nguyen, Donald Pinckney, Simon Soriano, Viral Sangani, Anda Xu.
Vijay Subramanian
Vijay Subramanian is an Engineering Manager leading the Java Developer Experience team at Uber, he has been involved in developing software for over 15 years on various domains and mobile platforms. He has a patent for a mobile device security system, and has always been passionate about technology.
Gautam Korlam
Gautam Korlam is a staff software engineer on Uber’s Java Developer Experience Team. He is passionate about tools to improve developer experience in large codebases. He has spoken about a wide variety of topics around Monorepos, Build systems, CI & CD at scale etc.
Ravi Agarwal
Ravi Agarwal is a senior engineer on Uber's Java Developer Experience Team. His focus area is building and enhancing tools used by the Java Monorepo users. This includes the build system (Buck), dependency resolution (OkBuck), test frameworks and CI tooling used to run builds and tests. He is passionate about making builds fast and reliable for large codebases.
Murali Krishna Ramanathan
Murali Krishna Ramanathan is a Senior Staff Software Engineer and leads multiple code quality initiatives across Uber engineering. He is the architect of Piranha, a refactoring tool to automatically delete code due to stale feature flags. His interests are building tooling to address software development challenges with feature flagging, automated code refactoring and developer workflows, and automated test generation for improving software quality.
Lazaro Clapp
Lazaro Clapp is a Staff Engineer and TLM on Uber's Programming Systems team. His current focus is on improving application reliability using fast type-system based tools. His broader research interests include general static and dynamic analysis, modeling of third-party code behavior, and automated testing and code repair. https://lazaroclapp.com/