Customer Support Automation Platform at Uber
High Level Overview of the Problem
Introduction
If you’ve used any online/digital service, chances are that you are familiar with what a typical customer service experience entails: you send a message (usually email aliased) to the company’s support staff, fill out a form, expect some back and forth with a customer service representative (CSR), and hopefully have your issue resolved. This process can often feel inefficient and slow. Typically, this might be attributable to the tooling/processes made available to CSRs for solving your issue. For any given issue, the CSR has to navigate standard operating procedures (SOPs, a.k.a. flow) with proliferating undocumented branches/edge cases making their work mundane, tedious, and imprecise. The manual maintenance and navigation of these SOPs can create a bureaucratic bottleneck, which ultimately leaves the customer dissatisfied.
Uber Specific Context
At Uber, as we scale globally with our various products (Rides, Eats, Freight, etc.), we faced similar challenges and inefficiencies around customer service interactions. We solved these challenges by developing Policy Engine (PE): a platform that enables standardization of SOP authoring, navigation, and execution to improve efficiency, increase egalitarian application of policies, and enable automation. This blog post shares the unique technical challenges faced in building this platform to enable the codification of complex customer interactions.
Prior to the development of PE, Uber had invested in developing automation flows to solve issues for which users were commonly reaching out (e.g., cancellation fee disputes). However, as we expanded globally and across different products, this did not scale, since it required an engineer to write custom logic for each such non-happy path scenario, which had regional variance and edge cases. As such, a means of expediting the authoring and maintainability of these decision trees was needed such that it did not require engineering effort to hard code the logic for any given issue, and enable regional operations to author and maintain these automation flows.
Issues that had not been previously automated were captured as SOP wiki pages, which described how to resolve any number of issues. Many of these would be readily automatable, such as if a driver partner looking to onboard wanted to know their background check status.

Architecture
Considerations
Faced with a lack of scalable automation, policy authoring, versioning, and maintainability bottlenecks, it was important to consider technological solutions that scaled quickly, were extensible, did not rely on business specific assumptions, and could guarantee a high degree of reliability.
Considering the constituent components of the work involved—a rules engine, a common semantic language, an execution framework, data hydration, and persistence layer—we evaluated whether existing solutions could be leveraged.
Business Rule Management System
We considered various existing rules management systems when evaluating how to build this framework. For example, Drools is an open-source BRMS that could be used to execute a chain of rules. However, such full-fledged rules engines often define their own proprietary DSLs (Domain Specific Language), for which there is a learning curve and extensibility cost. Drools in particular was also Java-based, which would require the server-side execution framework’s implementation to be written in Java instead of Golang, which is preferred at Uber. As such we decided to build a custom framework.
Domain Specific Language (DSL)
In evaluating which DSL to use for expression evaluation, we went back and forth between an existing DSL/JSONPath hybrid and a plain JavaScript (JS). We decided to use JS to avoid having to define/maintain our own custom DSL.
Execution Framework
Given the above, we considered V8, Google’s open source JS engine (with bindings for Go), to execute JavaScript snippets that represent the business logic to be evaluated as part of a given flow. Other options involving an in-house execution framework were considered, but dismissed since they would not be as flexible as using JS + V8 out of the box, and would significantly complicate the architecture and maintenance cost.
Data Retrieval
In order to “hydrate” (read from various sources) the data necessary to execute automation flows, it is important to allow authors to easily identify and author hydration logic.
Use of GraphQL was considered, however due to complex schema definition semantics and performance concerns we decided against it. We also considered leveraging existing tooling built internally, which provided data hydration chaining, but it had limitations around nested object schemas that would make them difficult to work with and maintain, especially for flow authors.
As we started onboarding more and more automation flows into the system, development of data fetchers became a bottleneck. Defining each new “hydration” (i.e. data fetcher) required manual and repetitive effort. To speed this process up, we developed a capability for flow authors to create and modify “hydrations” on their own. Currently self-serve hydrations support typed RPCs (e.g. Apache Thrift, Protobuf) as well as generic REST APIs.
Data Storage
Since the data model for flows was expected to be highly relational, requiring multiple indexes, cell mutability, and <100k rows, we decided to use MySQL. As such, we also decided to use GORM to read and write to our MySQL tables.
Components
The back-end service is written in Glue (Uber’s internal MVCS framework). Persistence is done on Percona DB (MySQL) clusters. Redis is used as a cache. The front-end leverages Uber’s React framework, Fusion.JS.
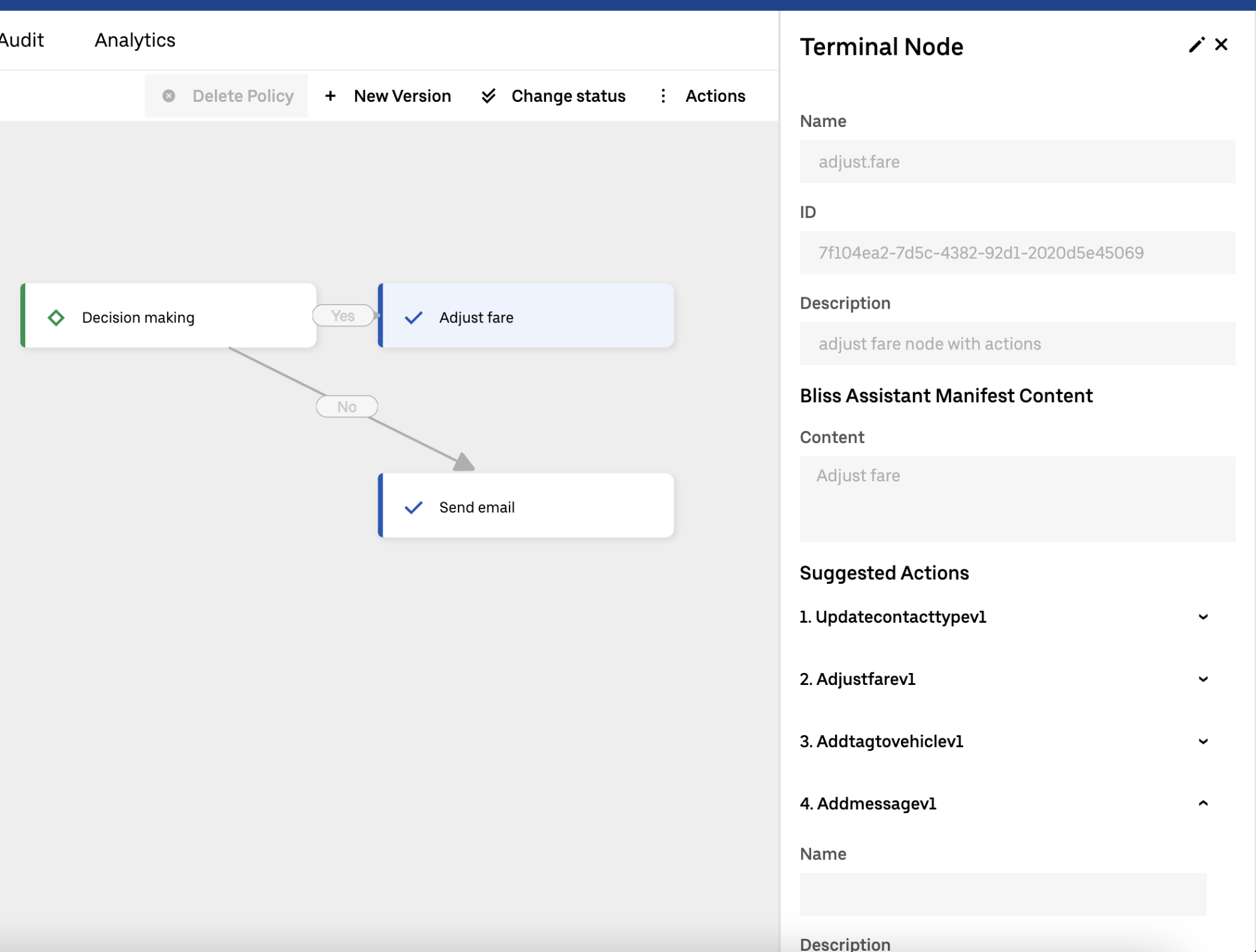
The system’s core consists of 2 parts: hydration and evaluation. The goal of hydration is to collect underlying data from across Uber in an efficient (“lazy”) manner. Evaluation is basically a traversal of a Direct Acyclic Graph (DAG). Each node represents an execution of a “rule” that specifies which hydrations are needed.

Decision Graph Flow Structure
Customer support flows are codified as a DAG structure. Each node in the graph contains a JS code snippet, which allows “hot deployment” and testing of flows. We decided to use JS, a scripting language, instead of a compiled language, to simplify the testing and deployment of flows. We leverage the V8 engine to run the JS snippets in the back-end.
Each decision node requires data from some service at Uber to make a decision. Therefore, we developed a specialized data aggregation framework that supports “lazy” loading of data fetchers and interdependencies between data fetchers. For example, as you traverse the decision tree, you do not want to fetch the same data twice. Moreover, one data fetcher’s result might be used by another data fetcher, hence dependency between them should exist.
All of the above was built as a platform, enabling non-engineers to self-serve. For “decision nodes” we created a “testing” framework. For the “data aggregation” framework, we created configuration-based data aggregation (think “GraphQL” for Go).
Authoring UI
Authoring
We developed drag-and-drop features to author workflow versions by adopting Uber’s flowchart library react-digraph. The authoring interface expedites development by constructing the required workflow format via simplified UI components and integration with services.

Testing
To ensure that workflows run as expected in production, we enforce testing processes before releasing any workflow to production. We developed a UI for simulating execution scenarios and saving them as test cases. The test screen enables workflow authors to cover all relevant scenarios pertaining to particular versions and preview the results before releasing them to production.

Versioning
The development lifecycle of a policy version involves the following transition states:
Draft → Shadow → Final → Live
Draft State
When in draft status, the version can be modified any number of times. This allows the users to iteratively work on a version, saving their progress at every step.
Shadow State
Shadow mode is where the version can be enabled to run in production without affecting the end users. This is done by running the version without taking any actions or showing any details to the users. One caveat here is on handling inputs. It is possible for a policy tree to have an intermittent node that asks the users for some input. Since we don’t show the users that a policy is running in the background, it is impossible to get a concrete input. In such cases, the policy engine randomly picks one of the possible inputs and runs the policy to termination.
Final State
Once there is enough confidence in shadow mode, the version can be made available for running in production. There is an inherent check to make sure of the confidence level. Currently the API checks if at least 60% of all nodes in the policy have been hit at least once during shadow mode executions from the last modified time of the version (which should be when the version was enabled for shadow mode). There is also a check that the last modified version has run in shadow mode for at least 24 hours. Once a version is marked as production-ready, it cannot be modified any time in the future.
Live State
Any one of the production-ready versions can be set as default to be run in production when the policy is invoked. One policy has only one version set as live at any given time.
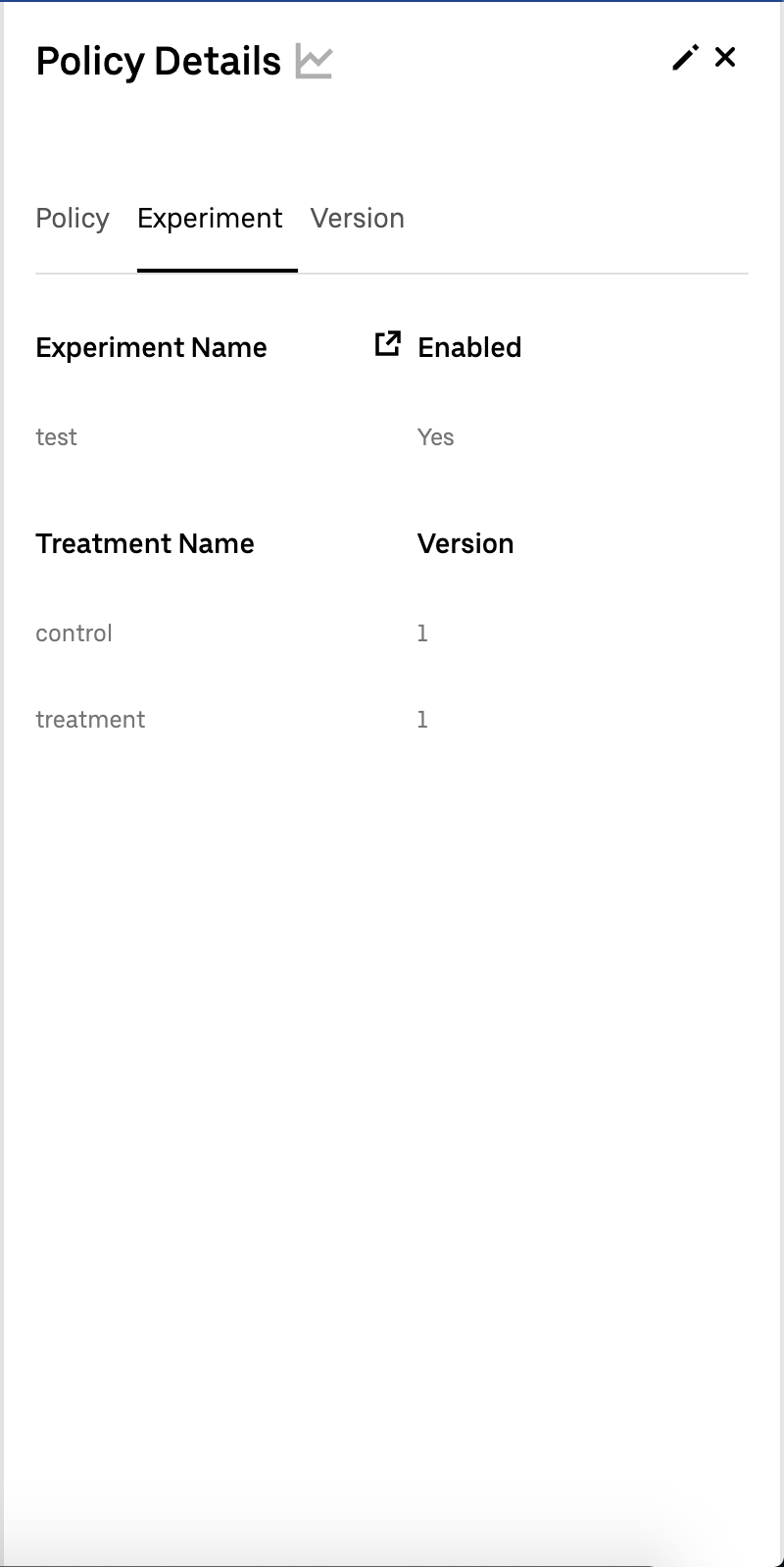
Experimentation
Policy engine leverages Uber’s experimentation service for mapping experiments to policy versions. Based on experiment segments, Policy Engine will execute configured versions. The only difference between experimental and non-experimental setups is that during experimentation, more than one version of a policy will be running in production, however only designated final versions can be associated with experiments.

Analytics
A policy consists of an ordered set of policy nodes. Policy execution invokes a subset of nodes, which may result in resolving the policy by performing actions. Contact resolution quality in turn is rated by CSAT, which is associated with terminal nodes.


Audit Logs
To increase compliance and accountability, every action against a policy will have to be logged. This change management log should be available via Policy Studio in a read-only interface at the individual policy level.
The following data fields are available in every change logged:
- Date and timestamp
- Action
- Username
Here is a list of actions that should be logged:
- New policy created
- Policy metadata field (name, description, CT, country, channel) updated
- New policy version created, including version number
- Policy version updated, including version number
- Policy state changed (draft to shadow to draft)
- Policy deployment actions
- Experiment changes (creation, enabling, disabling)
Test Executor
Executors are the decision logic to our automation. Workflow authors will need to develop corresponding logic in each automation decision node. For expediting executor development, we created functionality to test the logic.

Access Controls
We leveraged Uber’s internal RBAC systems.
Composable executors
Executors typically contain two kinds of logic: decisions on how to navigate a particular node in the policy, or calculators that compute certain values to be used as arguments for any actions. Over time, the executors have continued to become more complex, but large portions have been copied and pasted. There’s a request now to store the results of the executor so that the result can be reused.
Our decision logic/executor consist of two main components:
- Selector
- Outcome Logic
Selector
Selector is to pick required data from SuperSchema. We will provide abilities for users to select required data the decision needs from exhaustive field lists. The fields are defined in thrift/proto. We can leverage the type generation process (mapper or typed-rpc-cli) to get exhaustive lists.
Outcome Logic
Unit Executor
Unit executors are to break down logic to single purposes, like isEqual, has and includes. During authoring, users will select required variables from selectors or arbitrary values like string or number. So the decision logic could be much more descriptive, like a isEqual 1, b includes “PENDING”, etc.
Concat Statement
We can also concat each operation with logical operators AND and OR.
E.g., a isEqual 1 AND b includes “PENDING”.
Chaining Unit Executor
Some statements can be fulfilled by a single unit executor. Like find size of userType rider Contact messages will be
| size(filter($Root.Contact.Messages, {userType: “rider”})) |
or
| filter($Root.Contact.Messages, {userType: “rider”}).size() |
Author Unit Executor
As we observe in existing executors, some of them include very sophisticated logic like “within radius” or “last 5 hours”. We will grant authoring access for certain users to author unit executors which can fulfill sophisticated logic and can fit in the composition framework.
Omni-Channel Integration
Across the products offered by Uber, we provide multiple different means of reaching out to customer support. For instance, a customer can reach out via the help section of the Uber app for various issues to get self-served, via real-time chat or telephony for an ongoing Uber Eats order, they can reach out asynchronously via help.uber.com or email, or through one of our in-person greenlight centers. The Policy Engine allows for automated execution of SOPs across all channels. This requires being able to support different communication media or client channels.
PE currently powers the following channel automations:
- In-app self-serve: Screens in our mobile app that guide users to help themselves
- Messaging: Non-real-time automation for support emails and in-app messages
- Chat: Real-time automation via chat bots
- Telephony & IVR: Real-time automation for inbound phone calls
- Agent (CSR) Assistant: UI widget guiding flow traversals and resolutions for CSRs
Presentation Layer
In order to achieve policy execution across different channels, we allow authors to distinguish flows by channel, to identify which presentation layer it is executed for. For instance, if the flow is meant to be executed for in-app self-service, we need to provide a means to dictate how to collect additional input from the user, as well as inform the client which screen to show next.

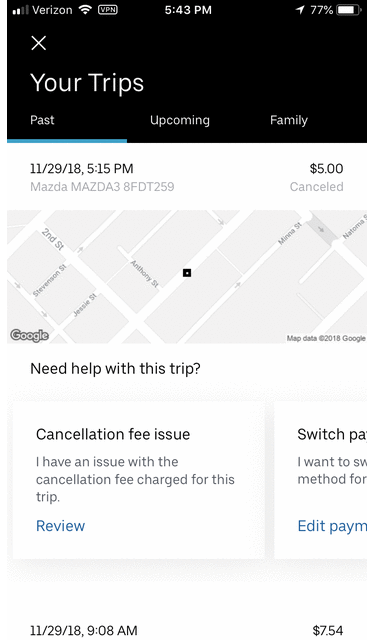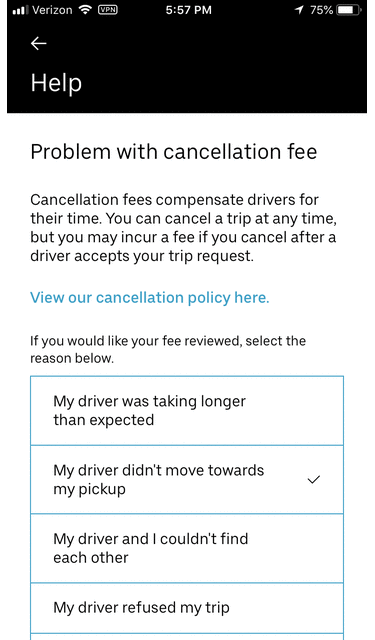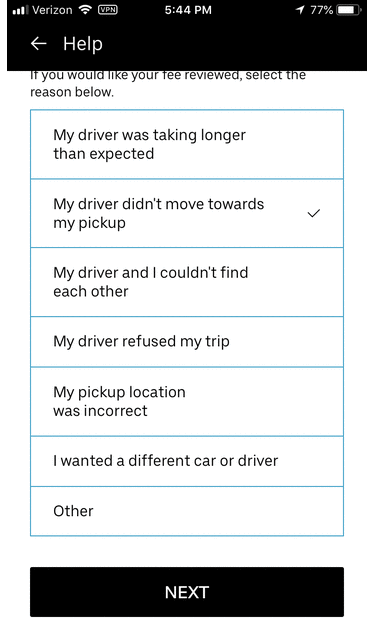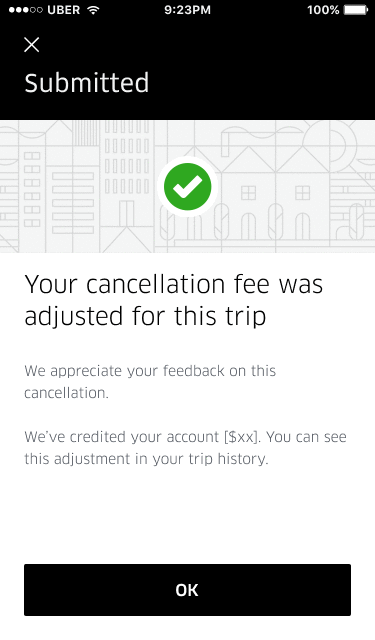
The above is invokable from Google Dialogflow for real-time chat flows as well.
Similarly, if a flow is meant to be executed for a phone-based interaction, the author can specify the audio snippets to be played as part of the flow resolution. These flows are integrated with Genesys for IVR-based voice automation.

If however, instead of fully automating the execution of the flow, the CSR prefers to interactively navigate the flow manually and enter inputs to the flow themselves, that can also be configured by the author.

Challenges and Future Scope
Synchronous vs. Asynchronous Execution
Wanting to support both real-time and non-real-time automated execution comes with dynamic latency considerations. If a user is engaging via real-time chat or telephony, to guarantee a positive customer experience where the user is not left waiting too long, it is important to minimize latency, and notify the user of the progress being made in executing their resolution. Conversely, for asynchronous/email based interactions, latency is less of a concern. Today, we expect the user to wait while the flow is executing, with a visual indicator letting them know execution is in progress, and retries are seen as the responsibility of the clients.
However, in order to allow the same flow to be used across channels, we will need to invest in a mechanism by which to execute policies asynchronously with platform-level retries, and push updates to the client (rather than having it be a blocking call. as it is today).
Channel-Agnostic Policies
At present there is contextual coupling between policies and the presentation layers they support. In order to enable more efficient re-use of policies across channels, we would need to further decouple the presentation layer from the flow business logic, such that it can be modified independently without impacting the client side experience. This would also enable efficiency on the authoring side and reduce duplication. The challenge here is whether to have this decoupling at a decision tree level, or a more granular decision node level.
Knowledge Base CRM
Not all policies can be auto-executed. When Ops are constructing new policies, or for policies which require human auditing/verification, this system can still be used to author policies in a standardized format, which allows the collection of standard operating procedures in the knowledge base to be consistent. This reduces ramp up time for new CSRs and enables automation on these policies on subsequent iterations, without having to perform any migrations.
Machine Learning to Suggest Improvements
As we scale, we have observed there are specific patterns that emerge as invariants or prerequisite conditions. As such, it is hypothesized that training on existing policies might yield insights on how to construct new policies, or improve existing policies by analyzing hot and cold paths within the decision tree or incorporating customer feedback. Static analysis of policies could also be performed to help identify similar policies that can be reconciled.
No Code Authoring
At present, due to the use of JavaScript as our “DSL”, authoring policies requires some understanding of how to formulate predicates and construct the decision tree via JSON. We plan on providing a richer UI interface, which avoids needing to understand the underlying flow JSON or JavaScript execution snippets, so no technical skills are required to be able to construct new policies.
Generic Rules Engine?
The Policy Engine was originally built to solve for the support-specific use cases for authoring SOPs and providing a framework to automate their execution. However, it is possible to extend its use beyond support, as there is nothing inherently domain-specific about its design. The key challenge in extending it to support other use cases would require expanding the scope of requirements that the platform currently supports. For example, at present we do not support parallel execution, and have a limited set of constraints for which an SOP can be configured. These aspects will need to be expanded to support more generic use cases.
Conclusion
Impact
By democratizing the process of creating and maintaining the customer support policies, we were able to increase efficiency, increase and maintain CSAT, and standardize the adherence of agents to standard procedures.
Moreover, standardization of policies now opens the door for us to gain better visibility into how customers respond to specific interactions. This, in turn, allows us to make data-driven decisions, and continuously improve customer support interactions.
Finally, versioning capabilities, used together with Uber’s experimentation platform, allows us to experiment with variations of policies, and come up with better and more efficient flow versions. If you would like to join our team or learn more, apply here.
Monis Khan
Monis Khan is a Backend Software Engineer with the Customer Obsession team at Uber, based in San Francisco. When he is not coding, he enjoys playing board games and reading science fiction.
Chia Yen Hung
Chia Yen Hung is a Senior Fullstack Software Engineer with the Customer Obsession team at Uber, based in Sunnyvale. After work, he enjoys swimming and playing basketball.
Norm Usenkanov
Norm Usenkanov is a former Engineering Manager with the Customer Obsession team at Uber, based in Sunnyvale. In his spare time, he can be found hiking or reading books on history and philosophy.