Uber’s Highly Scalable and Distributed Shuffle as a Service
July 7, 2022 / GlobalUber is a data-driven company that heavily relies on offline and online analytics for decision-making. As Uber’s data grows exponentially every year, it’s crucial to process this data very efficiently and with minimum cost. Over the years, Apache Spark™ has become the primary compute engine at Uber to satisfy such data needs. Spark empowers many business-critical use cases at Uber with its unique features, including Uber rides, Uber Eats, autonomous vehicles, ETAs, Maps, and many more. Spark is the primary engine for data warehousing, data science, and AI/ML. In the last few years, Uber’s Spark usage has grown exponentially year over year, running on more than 10,000 nodes in production. Spark jobs now account for more than 95% of analytics cluster compute resources which process hundreds of petabytes of data every day.
Although Apache Spark has many benefits that contribute to its popularity at Uber and in the industry, we’ve still experienced several challenges in operating Spark at our scale. A Spark job consists of multiple stages in the current architecture, and shuffle is a well-known methodology to transfer the data between two stages. As outlined in our Spark + AI Summit 2020 talk, currently, shuffle is being done locally in each machine, which poses reliability and stability issues, and other challenges such as hardware stability, compute resource management, and user productivity. We will focus on Spark shuffle scalability challenges in this blog post. We propose a new Remote Shuffle Service, codenamed RSS, which will move the shuffle from local to remote machines. RSS will force all local disk writes to a remote shuffle cluster, allowing us to be more efficient in computing data in base machines and removing the hard dependency of having persistent disk on compute machines. RSS will help us move to Cloud more efficiently and, most importantly, make Data Batch and microservices colocation on the same machines much more effortless.
The Current State of Shuffle
A shuffle involves two sets of tasks: tasks from the stage producing the shuffle data and tasks from the stage consuming it. For historical reasons, the tasks writing out shuffle data are known as map tasks, and the tasks reading the shuffle data are known as reduce tasks. These roles are for a particular shuffle within a job. A task might be a reduce task in one shuffle where it’s reading data, and then a map task for the next shuffle, where it’s writing data to be consumed by a subsequent stage.

As shown in Figure 1, The Spark shuffles use a “pull” model. Every map task writes out data to the local disk and then reduce tasks making remote requests to fetch that data. As shuffles sit underneath all-to-all operations, any map task may have some records meant for any reduce task. The job of the map side of the shuffle is to write out records so that all records headed for the same reduce task are grouped next to each other for easy fetching.
At Uber, we run Spark on top of Apache YARN™ and Peloton and leverage Spark’s External Shuffle Service (ESS) to operate its shuffle. There are two basic operations for Shuffle, which are as follows:
Write Shuffle File
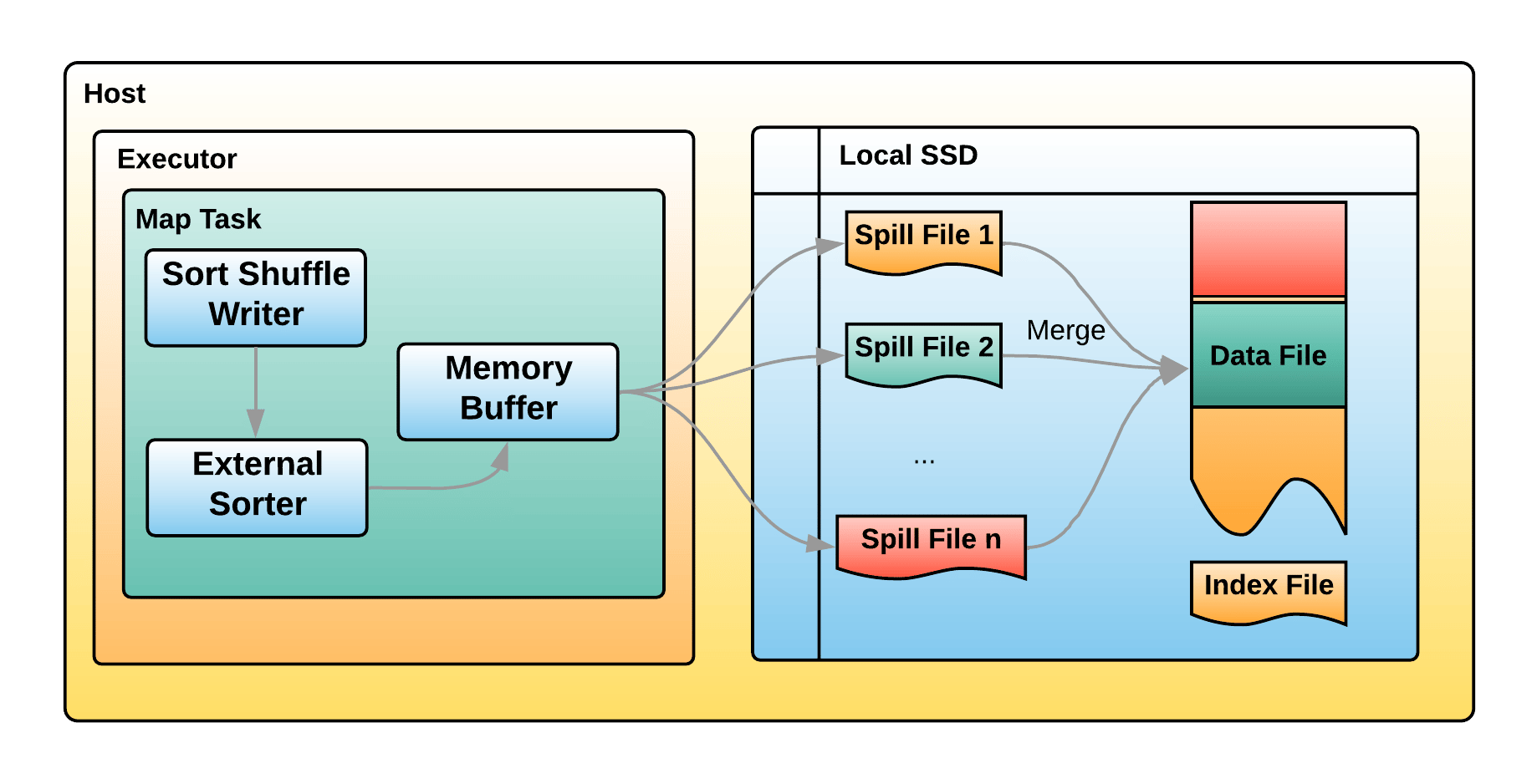
The current Spark shuffle implementation writes shuffle data to the executor’s local disk. Figure 2 illustrates how a Spark Map Task writes shuffle data at a very high level. The Map Task writes data to a memory buffer and spills data to temporary files when the buffer is full. Then it merges all spill files and generates final shuffle files. This shuffle process is not optimized and has a lot of inefficiencies. We write and read spill files multiple times in many cases, leading to many read and write latencies. These inefficiencies often get hidden in local shuffle writes due to data being written locally, but this still generates many disk writes.
Read Shuffle File
Figure 3 illustrates how a Spark reduce task reads shuffle data from a map task’s output. Each reduce task talks to the external shuffle service running on each mapper host to get the map task partition output stored on that host. Map tasks generate data files, containing data from multiple different partitions, and an index file that keeps the partition offset. When a reducer task asks the external shuffle service for data from a partition, it reads the offset from the index file and seeks within the data file to get the reducer-specific data, then returns it. Then the reducer task puts this data into a memory buffer, sorts it (if needed), and then generates the iterator for the reducer process to consume. This process is inefficient because the reducer process has to talk to many mapper hosts to get a partition’s data, which causes many disks to seek on those hosts.

Challenges
Spark’s existing shuffle mechanism achieves a good balance between performance and fault tolerance. However, when we operate Spark shuffle at our scale, we have experienced multiple challenges, which have made the shuffle operation a scaling and performance bottleneck in our infrastructure.
Reliability
The first and most crucial challenge is the reliability of the overall compute Infrastructure. In our production clusters, due to the sheer volume of compute nodes and the scale of the shuffle workload, we are facing two-dimensional issues, which are as follows:
Hardware Reliability
At Uber Compute, we are moving towards disaggregated storage and compute, and for compute, we are using base servers and specialized High I/O for storage machines. Compute base servers have 1 terabyte SSD disk with DWPD (disk writes per day) as 1. 95% of Uber’s data compute runs through Spark; as a result, these base machines are running all Spark workloads, generating thousands of terabytes of shuffle data per day. However, the nature of the disks we use and the number of base servers in the cluster is causing our SSD to wear out faster than they are designed for. Generally, these machines are designed to be sustained for 3 years; however, by writing this much data on these machines, they wear out in 6 months.

Figure 4 demonstrates the writing pattern for the YARN fleet at Uber; here, it is evident that each machine is doing I/O 2 to 3X more than what the current DWPD supports for the SSD. Interestingly, the writing pattern is not uniform across the whole fleet. Some machines are getting a lot more writes than others because some Spark applications write a lot more data to disk than other applications.
Application Reliability
The other challenge is the reliability of the applications. Due to the number of compute nodes and the scale of the shuffle workload in our production clusters, we have noticed shuffle service availability problems during cluster peak hours. Below are the 3 categories of issues:
Shuffle Failures
In the current Spark framework, shuffle operation is not as reliable as it should be. Its distributed nature assumes all the machines, networks, and services are available during shuffle operation. However, when the reducer fetches the data from all mappers on the same machine, the service becomes unavailable, which causes a lot of shuffle failures, causing stages and jobs to fail.

Noisy Neighbor Issue
All spark jobs run on and share the same machines in the current compute environment. At Uber, we have limited disk space on the device, which gets filled by any application that produces a lot more shuffle data which causes other applications which are running on those machines to fail with disk full exceptions.
Shuffle Service Unreliability on YARN and Mesos®
At Uber, we were using an external shuffle service in YARN and Mesos; however, we often experienced the shuffle service being unavailable in a set of nodes, which causes jobs to run on those machines to fail. We had to spend a lot of time and effort to run these services in our production environment.
Scalability
The other challenge with external shuffle service is scalability. Currently, the disk size has capped data on the local machines, and there are use cases to write a lot more data than what we could write today. These use cases can not run due to these limitations. Another challenge is that our machines are getting upgraded to newer hardware with more CPU and Memory, but disk sizes are not growing in the same proportion. This leads to competition over storage resources in the individual machines, and the current architecture cannot scale based on applications and hardware needs.
Different Approaches Considered
To address the above issues, we tried multiple approaches to storing shuffle data on the remote machines rather than having it on the local machines. We have done a lot of experiments to come up with the current architecture. Some of the approaches we took are as follows:
Plugin Different Storage
Spark has the abstraction of the shuffle manager, which facilitates shuffling on local disks with internal or external shuffle service on the local machine. We wrote a shuffle manager for Spark that supports different storage plugins and developed plugins to write shuffle files to HDFS or NFS. However, our testing shows the run time of Spark jobs increased by 2 to 5 times.
Streaming Writes
We also built a streaming server that could directly receive streams from Spark executors. We experimented with HDFS and local storage as a backend for those streams; however, job latencies increased by 1.5 to 3 times.
RSS Overview
After the above experiments, we figured out that streaming writes on the local disk would help, as those were the least expensive. However, those were not on par with the current local machine performance. We had to reverse the map-reduce paradigm for remote writes, which helped us achieve the performance on par with local writes, though we were writing on the network to achieve the performance.
Reverse Map Reduce Paradigm
In the Spark framework, as shown in Figure 1, we have map tasks that write data locally on the machine and then reduce tasks, talk to all the mapper machines, and fetch data for a single partition. Then, after reduce side operations, the reducer combines the output of all mapper tasks to produce results.
In this model, reducers spent a lot of time going to each map output machine, fetching data, and then combining them to produce data for the reducer. To improve on remote latencies, we reversed the Map-Reduce paradigm.
For Remote Shuffle Service, mappers have to write to remote servers. Instead, they write randomly anywhere. We are coordinating at the mapper side to write to the unique RSS Server for the same partition, and the reducer will have to fetch data only from one RSS server.

As shown in Figure 6, all mappers from the same partition write to the same shuffle server, and so reducers only have to go to one shuffle server machine and fetch the partition file. By doing this, we could substantially improve the Spark job latencies on the remote shuffle server, and we could get similar performances as local shuffle and, in some cases, even better than local writes.
RSS Architecture
Figure 7 shows the overall architecture of RSS. At a high level, we have three components: Client, Server, and Service Registry.
All Spark executors will use clients to talk to the service registry and remote shuffle servers. At a high level, the Spark driver will identify the unique shuffle server instances for the same partition with the help of a zookeeper and will pass that information to all mappers and reducer tasks. As in Figure 6, all the hosts with the same partition data are writing to the same shuffle server; once all mappers are finished writing, the reducer task for the same partition will go to a specific shuffle server partition and fetch the partition data.

RSS Client
RSS has a client-side jar that implements the shuffle manager interface exposed by Spark. Driver picks a list of RSS servers to be used for executing the shuffle by querying the service registry and encodes this information within the custom implementation of the shuffle handle. Spark machinery takes care of passing the shuffle handle to map-reduce tasks.
Both mappers and reducers derive the list of RSS servers to be used from the shuffle handle. By design, all the mappers send the shuffle data corresponding to a given partition to a single RSS server in RSS. So unlike pull-based shuffles, reducers only need to reach out to a single RSS server for reading shuffle data for a given partition. RSS clients also have a provision to replicate the shuffle data for all partitions to multiple RSS servers, in order to add fault tolerance against servers going down.
The entire implementation is within the shuffle manager interface, so there are no code changes required in the Spark codebase. From the Spark perspective, everything is the same, with the only difference being that instead of mappers writing the shuffle data to a local disk, RSS clients (mappers) send the shuffle data to remote RSS servers. The selection of the RSS servers per shuffle happens within the driver in the registerShuffle interface. A service registry is used to get a list of all available RSS servers. Let’s explore these components in a bit more detail.
Service Registry
In RSS, a service registry is used to maintain a list of available RSS servers. The service registry interface is open, so Redis®, ZooKeeper™ MySQL®, etc., or any other state store can be easily plugged in. In our production environment, we are using Zookeeper as a service registry. Even though ZooKeeper is not ideal for a short-lived connection, it has worked out quite well for us, as ZooKeeper is getting queried only from the Spark driver.
Each RSS server maintains a long-running connection with the ZooKeeper, over which it periodically updates its liveliness status. During register shuffle, the driver gets a list of all available RSS servers from ZK and picks up servers based on the latency, several shuffle partitions, and active connections. After checking each server for connectivity, a list of available servers is passed to mappers and reducers within the shuffle handle.
So the individual processes each access the service registry to communicate with a remote shuffle service.
Our approach requires that each shuffle service instance register itself to the startup’s service registry. It is automatically deregistered if a shuffle service instance fails and loses its connection to the service registry. The executors communicate with the service registry to query the available instances and communicate about the location of data and the state of their job.
Shuffle Manager
Shuffle Manager is the component that implements Spark’s shuffle manager interface. It is responsible for selecting and tracking which remote shuffle service instances to communicate with, then uploading data to and downloading data from them.
When the Spark driver does shuffle registration, it connects with the service registry, gets a list of available servers, checks their connectivity, and picks RSS servers based on the number of shuffle partitions and the replication factor. The driver then checks these servers for connectivity and then picks up the available servers with the least load. Servers are assigned to each partition in a round-robin manner from the ordered list of final RSS servers so that the mapping of RSS server to partition is consistent across all mappers and reducers. This information is encoded within the shuffle handle and passed to map and reduce tasks by the driver before execution. This process is summarized in Figure 8.

RSS Server
Shuffle is a “netty” based highly scalable asynchronous streaming server, which accepts a stream of shuffle data for a given partition from multiple mappers and directly writes these streams to a single file on a local disk. We run a 400-node RSS server cluster on dedicated hardware optimized for disk I/O. Each RSS server runs on a single custom configured node with an 80 vCores, 384GB memory, and 4*4 TB NVMe SSD.

Each map task streams the shuffle data to one or more RSS servers based on the replication factor. The shuffle data stream is a sequence of shuffle records, where each record contains a partition ID and record data (blob). When an RSS server gets a shuffle record from a map task, it inspects the record’s partition ID, chooses a different local file (based on that partition ID), and writes a record blob to the end of that file.
There are 2 mappers, 3 shuffle partitions, and 3 reducers in the example above. The replication factor is set to one, so each mapper will send shuffle data corresponding to each partition to only one RSS server. Server 1 handles Partition 1 and Partition 3, whereas Server 2 handles Partition 2. All shuffle data for Partition 1 and Partition 3 will be written to two separate files when all map tasks finish. Reducer connects to the appropriate RSS server to fetch the shuffle data based on the pre-determined mapping. RSS server will use the reducer ID (partition ID) to find the corresponding shuffle data file and send a stream of the records to the reducer.
A clean up thread running on each RSS server periodically looks for apps for which no shuffle data has been accessed in the last 36 hrs and deletes the shuffle data of such expired applications. Limiting the total number of concurrent connections per RSS server as well as maximum concurrent connections per application per server ensures that no RSS server is overloaded.
Fault Tolerance
Server Busy
RSS clients have retries during connection, uploading, and downloading the shuffle data from the RSS servers. During these retries, clients exponentially back off to not overwhelm the servers during the adverse time. Clients also have a provision to query ZK if the connection information of an RSS server gets updated because of a replacement/restart.
Server Restart
RSS server on a restart regains the prior state of application ID and partition mapping by reading the shuffle data files persisted onto the local disk. If map tasks fail under such circumstances, the Spark application will try to reattempt these failed tasks with a new task attempt ID. The RSS server maintains a task attempted in each shuffle record stored in the shuffle file and records the final successful task attempt ID. The reducer task will then accept the only shuffle records with the last successful task attempted and discards all others.
Server Goes Down
Even with the failsafes, in our production setup of a ~800 node cluster, there is a very high probability of one or more RSS servers becoming unavailable. Because of the multi-tenant nature of the RSS server, a single RSS application caters to a large number of Spark apps. Replication is useful under such circumstances so that the shuffle data can be served from one of the replicas. To inherently handle anomalies when shuffle data is available even on replicas, RSS clients send a FetchFailedException to the Spark driver. The Spark driver, under such circumstances, re-schedules the affected mapper/reducer stages and their parents if need be. We have added a small patch in the Spark codebase that triggers a register shuffle for the affected shuffle before retrying the required mapper stage so that a new list of available RSS servers is picked. Like the original stage attempt, a new set of RSS servers gets selected within the registerShuffle call and passed onto each mapper/reducer task.
Mitigating Reliability Issues
Hardware Reliability
We can offload ~9-10 PB disk writes to remote servers with dedicated I/O-optimized hardware with RSS. RSS has helped improve the wear-out time of the SSD on the YARN cluster from ~3 months to ~36 months.

Figure 10 above shows after RSS is deployed in production. Local writes are significantly reduced, which improves the overall reliability of the hardware. This has also reduced the disk I/O wait time/avg disk I/O on the YARN cluster, which improved the performance of the batch jobs.
Application Reliability
The failure for the Spark jobs reduced significantly compared to the previous number of failures after RSS was deployed to production.

Figure 11 indicates that the container failure rates due to shuffle failures are reduced to almost 95%. This improvement also improved the performance and overall run time of all the Spark applications in Uber.
With added fault tolerance for RSS servers going down, which was the single biggest contributor to RSS failures, we are able to achieve reliability of above 99.99% as shown in figure 12.
Considering the number of connections and latency before selecting RSS servers for each shuffle ensures that the workload is evenly distributed rather than inundating a few RSS servers.

Mitigating Scalability Issues
RSS currently handles ~220k applications, ~80k shuffles, and ~8-10 PB of data everyday. We have production jobs that process even ~40 TBs of data in a single shuffle. Such large shuffles can be easily accommodated within RSS by increasing a fanout. This was impossible with Spark’s native external shuffle, as that is bound by the size of the disk for each machine, which is usually a 1 TB SSD. This helped unlock a lot of use cases that were not possible before. Almost all of our business-critical batch pipelines are getting served by RSS with little or no impact on performance compared to ESS.
The entire traffic is served by a ~400 node RSS server cluster each in our two Data Centers and this can be very easily scaled horizontally in a very short duration without requiring any service interruption.
With Java®’s unsafe APIs-based shuffle writer, which is in line with Spark’s native unsafe shuffle writer, we will be able to iron out the performance issues we were having with large shuffles.

As shown in Figure 13, two representative servers from the RSS cluster depict the shuffle data read per second over the time from the file system and sent as a stream over the network to the reducers. The P99 for shuffle data read and written on an RSS cluster is around 2 TB/minute and 0.6 TB/minute.
Open Source
RSS is an open-source project in the Uber repo (https://github.com/uber/RemoteShuffleService)
The team at Uber is working toward donating this project to Apache Software Foundation.
Conclusion
As we rolled out RSS to production in Uber, all the analytics batch traffic is going through RSS. The RSS service is horizontally scalable, runs reliably, and serves one of the biggest Spark workloads in the industry while reducing the cost and improving the reliability of the applications as well as hardware. There are few people already using RSS on the public cloud and Kubernetes®. However, in the future, the RSS community is working towards making RSS run on Kubernetes and the Public cloud more seamlessly. The community is also working towards attaching multiple storage options and improving the reliability of the service.
Apache®, Apache Spark™, YARN, Mesos®, and Spark™ are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Redis is a registered trademark of Redis Ltd. Any rights therein are reserved to Redis Ltd. Any use by Uber is for referential purposes only and does not indicate any sponsorship, endorsement or affiliation between Redis and Uber.
Oracle, Java, and MySQL are registered trademarks of Oracle and/or its affiliates. Other names may be trademarks of their respective owners.

Mayank Bansal
Mayank Bansal is a staff engineer on Uber's Big Data team.

Bo Yang
Bo Yang was a Senior Software Engineer II at Uber. Bo worked in the Big Data area for 10+ years in various companies building large-scale systems including a Kafka-based streaming platform and Spark-based batch processing service.

Mayur Bhosale
Mayur Bhosale is a Senior Software Engineer on Uber’s Batch Data systems. He has been working on making Spark's offering at Uber performant, reliable, and cost-efficient.

Kai Jiang
Kai Jiang is a Senior Software Engineer on Uber’s Data Platform team. He has been working on Spark Ecosystem and Big Data file format encryption and efficiency. He is also a contributor to Apache Beam, Parquet, and Spark.
Posted by Mayank Bansal, Bo Yang, Mayur Bhosale, Kai Jiang
Related articles




Most popular

How Uber Migrated from Hive to Spark SQL for ETL Workloads

Automating Kerberos Keytab Rotation at Uber

The Evolution of Uber’s Search Platform
