Optimizing HDFS with DataNode Local Cache for High-Density HDD Adoption
May 24, 2023 / Global
Overview
Uber has one of the largest Hadoop® Distributed File System (HDFS) deployments in the world, with exabytes of data across tens of clusters. It is important, but also challenging, to keep scaling our data infrastructure with the balance between efficiency, service reliability, and high performance. As a cost efficiency improvement effort that will save us tens of millions dollars every year, we aim to adopt higher density HDD (16+TB) SKUs to replace existing SKUs with 4TB HDDs that are still used by the majority of our HDFS clusters.
One of the biggest challenges when fully adopting high-density disk SKU comes from the disk IO bandwidth. While the capacity of each HDD increases by 2x to 4x, the I/O bandwidth of each HDD does not increase accordingly. This may cause IO throttling when DataNodes serve read/write requests. This can be seen from the chart below, which shows the trend of slow read packet read count from one DataNode. Given the persistent and sizable number of slow read occurrences, it is important to find new approaches to prevent performance degradation.

By analyzing traffic of our production clusters, we observed that the majority of I/O operations usually came from the read traffic and targeted only a small portion of the data stored on each DataNode. Specifically, we collected ~20 hours of read/write traces from DataNodes across multiple hot clusters, and we have the following observations based on numbers listed in the table below:
- The majority of the traffic is read (>10M read requests vs. write requests in the thousands).
- Among all the blocks stored in each host, only <20% blocks were read during the 16 to 20 hour time window.
- Most of the traffic focuses on a small group of extremely hot blocks. Looking into one-hour time windows, the top 10,000 blocks attracted ~90% or more read traffic.
| Host | Total reads | Total writes | Number of Blocks stored in the host | Number of blocks being read | Average Block Size | Capacity Usage | Read traffic on top 10k blocks (1 hour time window) |
| Host1 | 13.5M | 3.3 K | 1,074,622 | 84769 | 380 MB | 77% | 89% |
| Host2 | 12.8M | 4.7 K | 633,923 | 59376 | 330 MB | 79.89% | 94% |
| Host3 | 11.3M | 275 K | 479,544 | 49317 | 300 MB | 79.86% | 91% |
| Host4 | 8.5M | 4.6 K | 247,206 | 31048 | 300 MB | 82.85% | 99% |
| Host5 | 14.3M | 45 K | 463,819 | 79958 | 160 MB | 81.62% | 99% |
Based on the above observation, implementing a cache becomes an intuitive approach to reduce the I/O workload on HDD disks and improve performance. A 4TB SSD should be able to store ~10,000 blocks based on the average block size in hot clusters. Therefore a DataNode local cache built on top of the SSD drive should be able to effectively decrease the I/O workload on HDD.
In this blog post, we present our implementation of a read-only SSD cache within each DataNode to store frequently accessed data and serve read requests. This new feature has been deployed along with the 16TB HDD SKUs in production and the metrics show a significant reduction in IO workload on HDDs, taking over up to 60% of traffic from HDD disks, resulting in nearly 2x faster read performance, as well as reducing the chance of process blocking on read by about one-third.
Challenges
There are a number of key challenges we need to take into consideration as we adopt the local SSD cache, as discussed in this section below.
Cache Hit Rate
The available cache disk space is considerably smaller than the total disk space on a DataNode. Specifically, at Uber, a 16TB HDD SKU used by HDFS DataNode can have as many as ~500TBs of disk space, while the available SSD disk size is only 4 TBs (i.e., <1% of the disk space). The implication is that we need to be cautious about which bytes among the 500TBs of data should be considered eligible for writing to cache. A poor decision making can result in low cache hit rate, high cache eviction, and thus bad cache performance.
Write Race Condition
In HDFS, it is possible to have concurrent readers and writers on the same block. HDFS has implemented a series of mechanisms with clear consistency semantics to ensure the read and write do not interfere with each other. We need to make sure the cache read also follows the same mechanism, and make sure cache read does not introduce new read failure scenarios due to concurrent operations.
SSD Write Endurance
If written too frequently, the SSD disk can wear out faster and finally fail to serve. Therefore we need to design and implement approaches to limit and carefully control the cache write frequency.
Failure Handling
Introducing the cache read path also introduces new failure scenarios on the HDFS read path. We should implement sufficient failover and failure handling logic such that failures have minimal impact on HDFS read. Namely, when a cache read fails (or even the whole SSD drive fails), we should make sure that the read can fallback to regular non-cache read.
Production Readiness Validation
Since HDFS plays a critical role in Uber’s data infra stack, it is important to validate the performance, effectiveness, and robustness of the new caching feature before putting it to production. We need to have methodologies to quantify, monitor, and verify the feature from both reliability and performance perspectives, and develop necessary tooling to ensure production readiness of the feature.
Design
The diagram below presents an overview of the architecture. The DataNode local SSD cache is situated within the DataNode process, and remains entirely transparent to HDFS NameNode and clients. When a read request is received and the corresponding block is not in the cache, the DataNode’s cache rate limit module assesses whether the block should be loaded into the cache based on its historical access. If the block is unsuitable for caching, the DataNode proceeds with the standard read path. Conversely, if the block is deemed cache-worthy, the DataNode attempts to load it into the cache. The following sections delve into the design considerations in more detail.

Alluxio Caching Library
For the implementation of the local cache, we decided to leverage Alluxio, based on our prior experience. Alluxio is an open-source project designed to address diverse data orchestration needs. Frequently utilized as a data caching layer, Alluxio provides Hadoop-compatible file system APIs that seamlessly integrate with Hadoop-compatible compute engines. Additionally, Alluxio implements Java standard file I/O APIs, enabling smooth integration with HDFS. We used Alluxio as a caching library in this project.
Integration of Local Cache in HDFS
This section introduces several decision points when integrating the local cache into HDFS datanodes.
Caching Both Block and Its Checksum
HDFS DataNodes manages data in the form of HDFS blocks. Specifically, a HDFS block on one DN is composed of two files on its disk: a block file and a meta file. For instance:
| -rw-r–r– 1 275M Nov 17 09:49 blk_1234567890-rw-r–r��– 1 2.2M Nov 17 09:49 blk_1234567890_1122334455.meta |
Here blk_1234567890 is the data block file and blk_1234567890_1122334455.meta is the corresponding metadata file. The metadata file contains checksum info of the block file and therefore it has to match the corresponding block file all the time.
Upon caching a block on disk, both the block and meta files are stored separately on the local SSD disk, maintaining the same format as the original files. The crux of this design is ensuring that caching occurs at the block level rather than the individual file level. We guarantee that either both the block and meta files are read from the cache or both are read from their original non-cache locations, but never any form of mix. This block-level caching design simplifies reasoning and enhances reliability, forming the basis for subsequent design decisions discussed below.
Exclude Non-Client Reads
Read requests landing on DataNode HDDs may be triggered by various scenarios other than regular clients. For example:
- The DataNode internal block scanner process periodically scans all the disks on the DataNode and verifies the integrity of the data blocks.
- The block re-replication or recovery caused by a dead or decommissioning DataNode will also generate read traffic.
- HDFS balancer or mover may also trigger block movement thus reading data from the source DataNodes.
Within the data transfer protocol, the above scenarios also call the same read API on DataNode thus sharing code paths as a client read. We exclude these traffic from cache checking, because these reads have no reuse pattern and therefore close-to-none cache value.
Block-to-Age Mapping
In HDFS at Uber, a single block can be up to 512MB, so is the single block file to be cached. Through the Alluxio® library our implementation manages caching in the form of “pages”, with 1MB in size by default. For instance, if a read requests byte in the offset range of [500, 1MB + 500], two 1MB page files will be created and stored on the SSD volume, one for range [0, 1MB) and one for [1MB, 2MB). If another read of range [500, 600) comes, the cache will simply serve the [0, 1MB) range page from the local SSD.
Changing the page size can have performance effects: larger page size means fewer pages and thus less in-memory metadata overhead, and potentially better local cache listing performance. However this will lead to the cost of less efficient reading and less caching range coverage, since the reads in our production are not sequential across multi-MB range for most of the time.
The ideal page size is a function of traffic patterns, file format, and desired metadata size. We currently found the 1MB default value a good enough choice based on empirical experience. We plan to further fine-tune this config in the future.
Support HDFS Write Operations
Although HDFS supports reading a being-written file/block through a series of mechanisms (max visible length calculation, “hflush” and “hsync” APIs), we currently only cache “finalized” block files (i.e., the write on the block has completed). This design choice matches our internal use cases and greatly simplifies the implementation.
However, there are still 3 HDFS operations that may modify the blocks (and correspondingly their cache): append to a block, delete a block, and truncate a block. We will discuss how to handle append and delete in this section. HDFS truncate is not being used at Uber and has little support in the HDFS community so we ignore it here.
Append to a Block
In HDFS, a client uses append to add new content to the end of an existing file. In order to differentiate from the original block before the append call, HDFS assigns each block a version number called generation stamp. For each append call HDFS will bump the original generation stamp to indicate the new version of the block.
Our cache implementation depends on the generation stamp to achieve snapshot isolation. When we load a block and its checksum to the cache, we keep the generation stamp and use the concatenation of blockID and generationStamp as the cache key. In this way we actually capture a snapshot of the block in the cache. When an append is happening, since we never load a being-written block into the cache, readers continue reading the original version of the block from the cache. When the append finishes, the block with the new generation stamp is treated as separate cache entries, allowing the latest version of the block to be loaded into the cache and accessed by subsequent reads.

Delete Block
When deleting a block, it is essential to remove the cached copy as well. Although Alluxio can purge outdated content over time through its cache policy, active deletion of cached copies is necessary for compliance reasons. The main challenge is that Alluxio is unaware of which DataNode blocks are currently cached on disk. Thus, when deleting a block, it is impossible to determine which page files on the cache disk correspond to that block. To resolve this issue, we introduced in-memory mapping within DataNode to track the currently cached blocks. When a deletion occurs, DataNode looks up the mapping to identify the relevant page files on disk and instructs Alluxio to remove them. To minimize memory usage, this in-memory mapping takes the form of <blockId → (cacheId, fileLength)>. The actual page files are calculated based on the fileLength field, thus as long as the calculation aligns with Alluxio’s method of generating its page IDs, Alluxio can locate and delete the disk page files.
Since the mapping is in memory, DataNode loses all mapping information upon restarting. To address this, DataNode can simply clear all cache content and rebuild the cache from scratch every time it restarts. This approach may reduce cache efficiency, but we consider it an acceptable trade-off, given that DataNode restarts are infrequent at Uber. In the longer term, we can consider supporting cache meta reconstruction on DataNode restart (e.g., by persisting cache metadata to disk).
Rate Limiter
A significant challenge in DataNode caching is the limited cache disk space compared to the total data volume stored on a DataNode. With 500TB of data storage capacity on a DataNode and only a few TBs of cache space available, it is essential to be selective about the data stored in the cache. Most blocks are accessed infrequently; caching all data reads indiscriminately would result in constant cache evictions, increasing read overhead and reducing cache hit rate. Therefore, it is crucial to prioritize caching data that is accessed frequently within a specific time window, rather than data accessed only once in a while.
To accomplish this, we create a rate limiter that determines whether a block should be cached based on its historical access pattern. Only when a block’s previous accesses meet a certain threshold will the block read be directed to the cache path. Otherwise, the block read will bypass the cache and proceed along the regular non-caching path.
In other words, the high level goal of the rate limiter is to allow frequently accessed blocks into cache while limiting the less accessed blocks with best effort. There are a few key considerations when implementing the rate limiter:
- Minimize memory footprint
- Minimize usage of locking
- Robust to errors (i.e., any error internal to rate limiter should not fail DataNode read, the read should proceed on the non-cache read path)
- Plugable and tunable: there can be different implementations of the rate limiter with different configuration parameters
We implemented multiple different versions of the rate limiter, each with its pros and cons. We also developed a simulation test to evaluate different designs and implementations. Currently, we decided to go with what we call BucketTimeRateLimit.
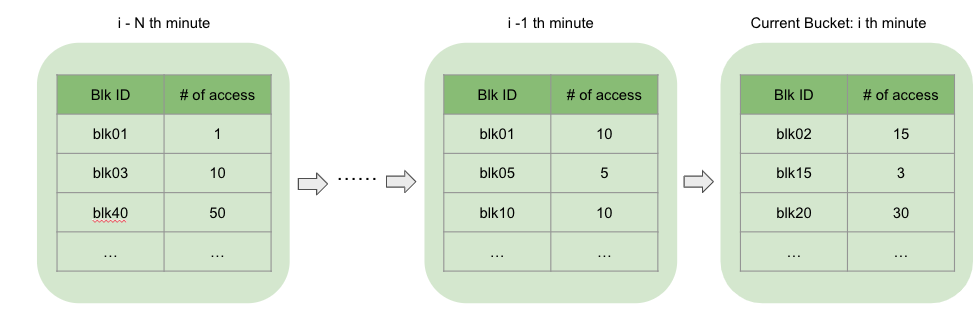
On the high level, BucketTimeRateLimit checks whether a block has been accessed more than X times in the past Y time interval. A page can be loaded into the cache only when the block that the page belongs to can pass the check. More specifically, BucketTimeRateLimit maintains an ordered list of buckets as a sliding window. Each bucket represents a one-minute time window and records the number of accesses for each block during this time period. BucketTimeRateLimit keeps a fixed number of outstanding buckets, and drops the oldest bucket every minute. When checking if a block should be rate limited, BucketTimeRateLimit checks all the existing buckets and accumulates the total number of accesses for this block. If the number of accesses is greater than the threshold, the block is considered a high frequency block and is allowed to cache.
Based on the traffic pattern and workload of a cluster, we fine tune the threshold values so that we can achieve the balance between:
- The effectiveness of the cache (i.e., how much traffic we offload from HDD) and
- The SSD write endurance requirement (i.e., the maximum amount of data that is written into SSD cache each day)
Shadow Cache
Alluxio has a built-in feature called shadow cache which is a simulated cache mode. Specifically, when using shadow cache, there is no actual disk cache write, the “cache write” is only an in-memory simulation that captures metrics. This feature is particularly useful for experimenting with different caching configurations, as it allows deployment of different configurations to multiple different DataNodes to collect metrics without having any production performance impact. We leveraged the shadow cache feature to find the best configuration values for the rate limiter.
Failure Handling
In case of hitting any exception during cache read, we always guarantee that our implementation can correctly fallback to the non-cache read path. This applies to errors caused by the rate limiter, the Alluxio internal errors, cache data corruption, and/or errors caused by SSD failure (e.g., SSD becomes read-only). In case the SSD drive fails, in our current implementation the DataNode also reports the failure to NameNode so that we can leverage the existing HDFS disk volume failure handling mechanism for reporting and monitoring.
Operational Improvements
One tool we developed was a new HDFS admin command to enable/disable caching on any specific DataNode at runtime. On the one hand, during testing this allowed us to easily switch between caching and non-caching code paths to verify correctness and performance, without having to deploy. On the other hand, for production this allows us to disable caching in a few seconds in case of any issues detected.
In addition to the command, we also integrated caching related metrics into current Uber’s HDFS metrics. We implemented more caching metrics and also integrated Alluxio’s own caching metrics into HDFS’s Grafana® board.
Performance Benchmark
To evaluate the performance before putting caching into production, we also developed various ways to perform benchmark, this section discusses some benchmark tools we leveraged.
Baseline Benchmark
The baseline benchmark measures the performance by writing a single file to one single DataNode, then reading it multiple times to track the throughput. We implemented the functionality of writing the file to one specific DataNodes using HDFS’s favoredNodes flag. This benchmark provides a baseline end-to-end throughput measurement.
Scale Benchmark
The main limitation of baseline benchmark is it is a single client, with parallelism limited by the host, and is always from the same node. To address this, we implemented a scalable benchmark tool, which runs as a YARN MapReduce job. After first writing some number of files on HDFS, the scale benchmark can launch an arbitrary number of readers to stress test. The readers perform either random or sequential reads, and then output the aggregated throughput.

Scale DataNode Trace Replay Benchmark
To further simulate real production HDFS traffic, we also developed a scale DataNode trace replay benchmark. DataNode traces contain all the read info (timestamp, blockID, bytes, and offset) that happened on a production DataNode. We collected tens of hours of DataNode traces. Then we break the traces down by top reader IP addresses.

Then we launch the benchmark MapReduce job, where one mapper simulates a reader by selecting only the traces from the reader IP. The mapper then replicates the traces by attempting to read specific bytes and offsets from the blockID, maintaining the same time intervals as in the original traces. Throughout the read process, the mapper measures the throughput and records the results to HDFS. These values are later aggregated. The DataNode trace replay benchmark offers a simulated environment closely resembling actual production conditions.

Performance Improvement
We deployed the DataNode local cache in Uber’s production environment, and observed noticeable improvements. It’s important to note that these enhancements are highly dependent on the HDFS cluster’s traffic patterns, and varying traffic patterns may yield different performance outcomes.
Cache Hit Rate
With some tuning of the rate limiter, we managed to hit a cache ratio of consistently around 99.5%. Essentially, for the data blocks getting cached, there is a 99.5% chance it gets reused soon later. This validates the effectiveness of caching.

Cache Read vs. Total Read
The chart below illustrates the percentage of client read traffic from the cache compared to the total read volume on a cache-enabled DataNode. This DataNode is equipped with 525TB of HDD disk space with roughly 50% utilization and 3200GB of SSD disk cache space. It consistently processes nearly 60% of the total read traffic. Put another way, on this DataNode, the SSD cache, accounting for only 0.6% of the total disk space, handles 60% of the overall client traffic.

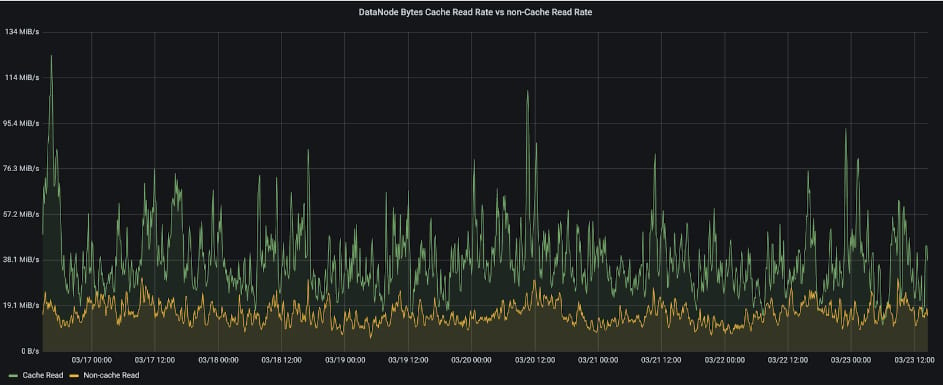
Cache Read Throughput vs. Non-Cache Read Throughput
The chart below compares cache read throughput with non-cache read throughput. It is evident that cache read throughput is significantly higher, nearly twice that of non-cache read throughput.
Slow Reads
The enhancement is also evident in reducing slow read. The chart below compares slow packet reads from two DataNodes within the same cluster—one with cache enabled and the other without cache. Our experience has shown that slow reads on the DataNode can cause an increase in the number of processes that are blocked on reads. After we enabled cache to accelerate the overall reads on this DataNode, we observed a noticeable decrease in terms of the number of blocked processes on this DataNode.

Future Work
Traffic/Dataset Tier-Based Caching
Instead of DataNodes making decisions based solely on historical access of blocks, the caching can also potentially be based on traffic/data tiers. For instance, caching can be enabled for all traffic on certain files belonging to certain tables. This would open the opportunity for optimizing HDFS performance specifically for high tiered use cases. This change would involve NameNode side changes and potentially upstream compute engines such as Presto or Spark.
Performance Optimization
We have seen promising initial performance improvements, but there is still room for improvements, such as fine tuning ratelimit and Alluxio configurations based on different cluster traffic patterns, looking into further optimizing memory usage, etc.
Conclusion
This article delves into the design and implementation of Uber’s HDFS DataNode local caching solution. The goal was to overcome IO bandwidth limitations while accommodating high SKU hosts. We describe how we integrated the open source solution Alluxio into HDFS and how we tackled the various challenges that arose during the integration process. Additionally, we present the performance improvements we observed through our deployment in Uber’s real production cluster workload. Overall, the local caching solution has proven to be effective in improving HDFS’s efficiency and enhancing the overall performance.
Apache®, Apache Hadoop, Hadoop®, Apache Alluxio™, Alluxio™ are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. ‘
The Grafana Labs Marks are trademarks of Grafana Labs, and are used with Grafana Labs’ permission. We are not affiliated with, endorsed or sponsored by Grafana Labs or its affiliates.
The headline image: “Wiring closet (fisheye)” by ChrisDag is licensed under CC BY 2.0. © by ChrisDag . Material unmodified.

Chen Liang
Chen Liang is a Senior Software Engineer on Uber's Interactive Analytics team working with Presto and Alluxio integration. Before joining Uber, Chen was a Staff Software Engineer on LinkedIn's Big Data Platform team. Chen is also a committer and PMC member of Apache Hadoop. Chen holds master degrees from Duke University and Brown University.

Jing Zhao
Jing Zhao is a Principal Engineer on the Data team at Uber. He is a committer and PMC member of Apache Hadoop and Apache Ratis.

Yangjun Zhang
Yangjun is a Staff Software Engineer with the Data storage team at Uber. He has been working on the reliability, efficiency, and modernization improvement for the HDFS dataplane.

Junyan Guo
Junyan Guo is a Senior Software Engineer on the Data Security team at Uber. He currently leads development on Uber’s Kerberos infrastructure and also works on AI Security and Compliance at Uber.

Fengnan Li
Fengnan Li is an Engineer Manager with the Data Infrastructure team at Uber. He is an Apache Hadoop Committer.
Posted by Chen Liang, Jing Zhao, Yangjun Zhang, Junyan Guo, Fengnan Li
Related articles


Most popular

Enhanced Agentic-RAG: What If Chatbots Could Deliver Near-Human Precision?

From Archival to Access: Config-Driven Data Pipelines

How Uber Migrated from Hive to Spark SQL for ETL Workloads
