Modern-day technical system deployments generally follow SOA or a microservice-based architecture that allows for clearer separation of concerns, ownership, well-defined dependencies, and abstracts out a single unit of business logic.
Uber has thousands of services coordinating to power up the platform that drives the company at scale. To offer a great experience to customers, developers have to ensure that their service is meeting its functional requirements. Building confidence in meeting functional requirements requires testing of a service.
At Uber, the service is tested in multiple ways. Each testing approach has its own value and trade-offs:
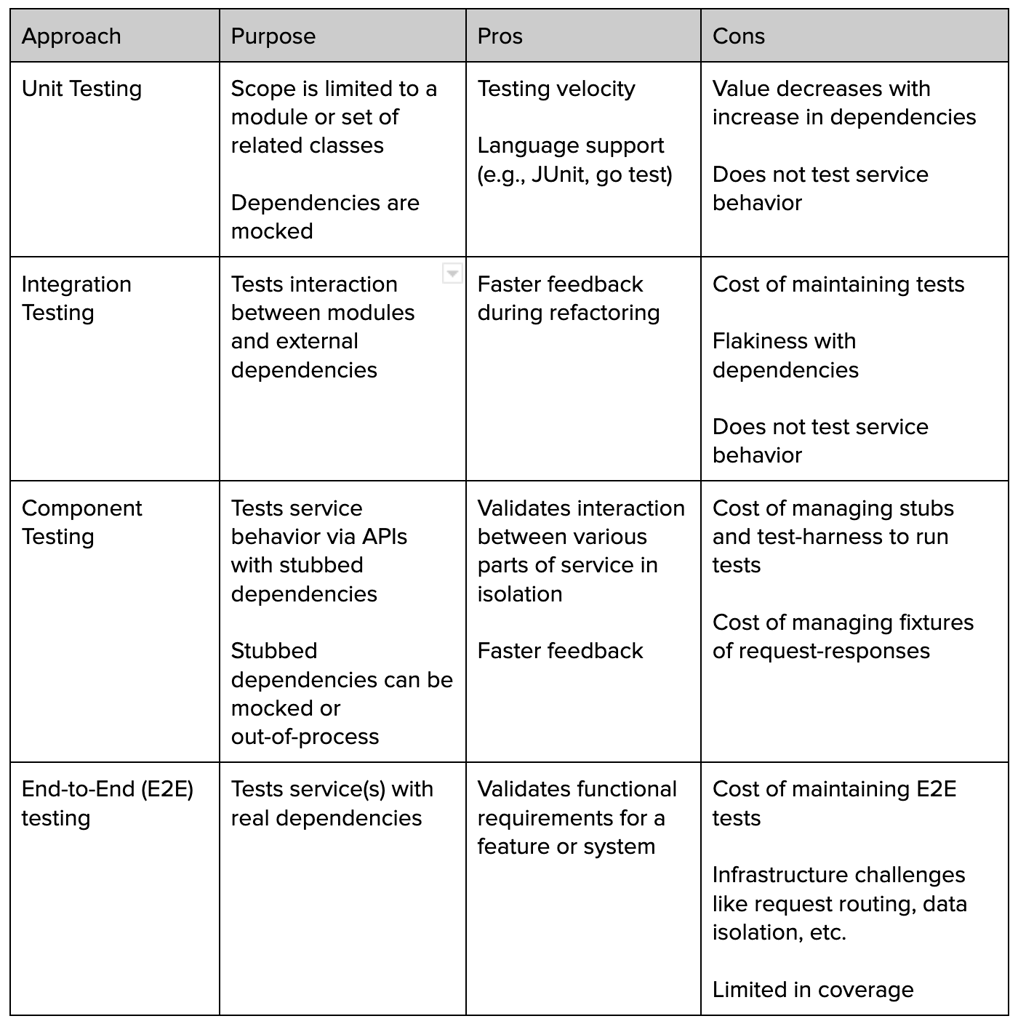
Testing a service in isolation (i.e., unit, integration, component tests) is important as it gives faster feedback to developers. But to validate whether the requirements for a service are met with the current state of dependencies and get confidence, developers rely on E2E testing.
This article describes how we safely enabled E2E tests for developers with improved developer experience.
Service Dependency
A service can have upstream and downstream dependencies. Upstream dependencies are callers of the service that expect stable contracts (API) from the service. Downstream dependencies are what the service calls to fulfill a request. These dependencies can be another service, database, queuing systems, etc.
If we plot a service’s dependencies in Uber, it can range from simple to very dense tree. Below is an example snapshot of a service’s dependency tree.
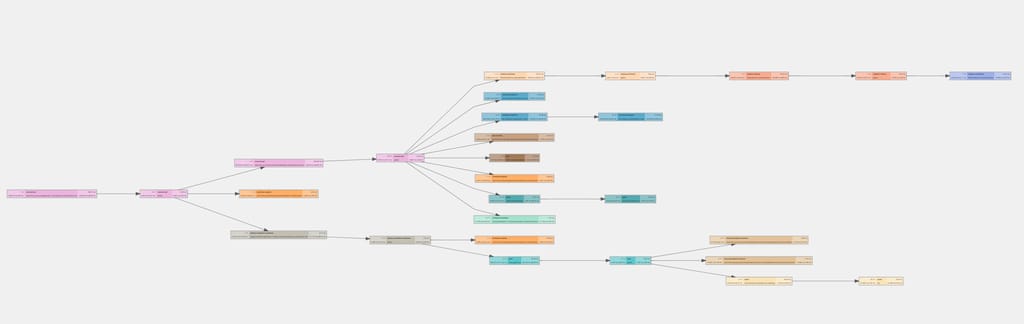
An E2E test for a service should run against the same version of dependencies as deployed in production for correctness.
One option is to bring up required versions of dependencies on a single host. But based on how dense the dependency call-tree is, it might not be feasible due to resource constraints on a single host.
Staging Environment for E2E Testing
We can leverage the staging environment of a service to run E2E tests. But there are some challenges with testing in a staging environment.
Test Flakiness
Each service has their own deployment pipeline and deployment timings. Some services keep staging deployment as a step in the deployment pipeline so that staging deployment is up to date with production. But many don’t, based on their use cases. So dependencies in staging environments may not be as updated as production. As a result, E2E testing in staging environments is not reliable and can be flaky.
Sharing Environment Among Developers
Staging environment also limits how many developers can test at once. Every developer might have different changes to be tested. They have to claim the staging environments of not only their service, but also of dependencies, which might not be feasible.
Production Safety
We can deploy a service-under-test (SUT) in staging with its own datastores. Rest of dependencies can be in production. But without any isolation, it is hard to make sure that the test will not impact data maintained by dependencies.
Cost
There is a cost of managing the staging environment. Staging databases, queues, computing resources etc. and their management, for every service adds to the bill.
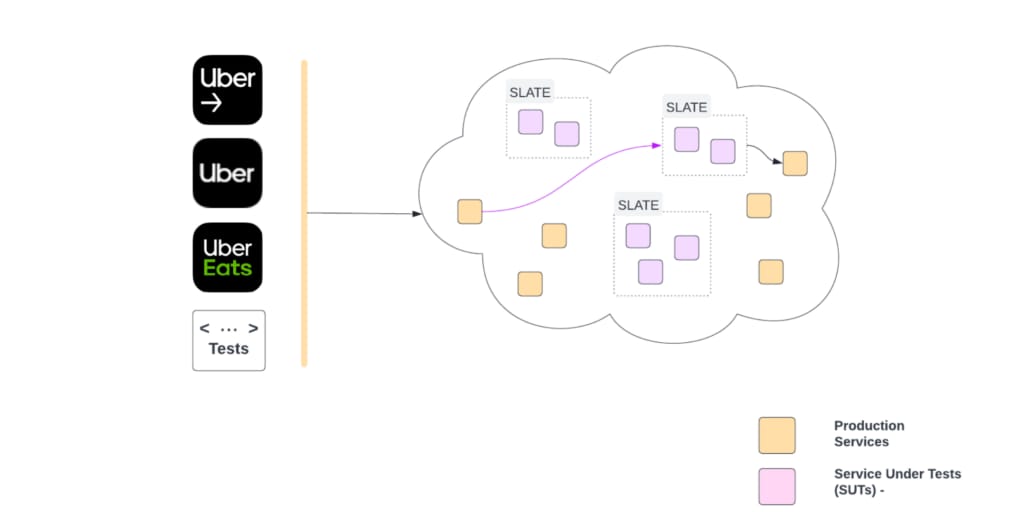
Short-Lived Application Testing Environment (SLATE)
In order to reduce the shortcomings of a shared staging environment for testing, we built a system that lets developers create on-demand, ephemeral testing environments called SLATE and deploy services in them. Services deployed in SLATE are called service-under-test (SUT).
SUT uses production instances of dependencies by default, for guaranteeing the best fidelity while ensuring production safety. SUT can also use isolated resources like databases, work queues that are configurable per service as described in Isolation of Resources.
SLATE offers the following:
- a developer can have multiple SLATE environments active at a time
- developers can deploy multiple services in a SLATE environment from git-branches or git-refs
- a service can be redeployed on SLATE multiple times
- new deployment replaces older deployment of a service
- there can be only one version and one instance of a service deployed on SLATE
- each SLATE environment has TTL (default: 2 days) associated, after which all service deployments are terminated and resources are freed up
Following is the deployment view of SLATE:
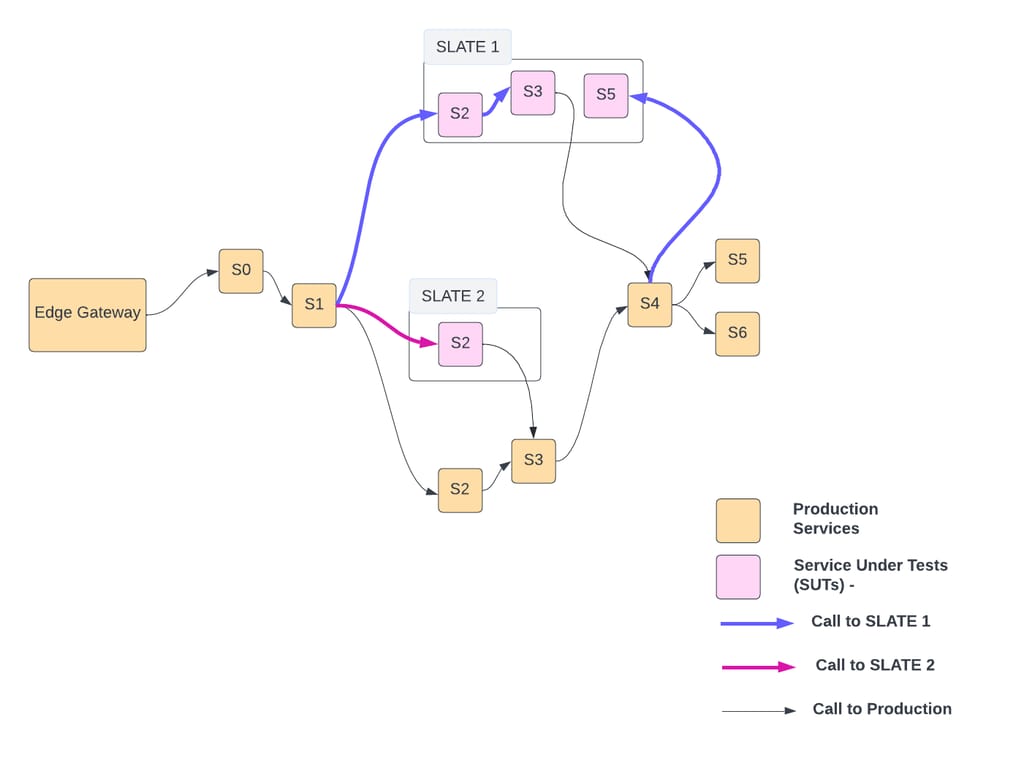
As shown above, there can be multiple SLATE environments active at a time (e.g., SLATE1 , SLATE2). They might belong to one or many developers. Each SLATE has one or more services deployed.
For example in SLATE1, S2, S3, S5 are deployed as SUTs. The blue line shows the call-path of a request hitting SUTs deployed in SLATE1. A header in request contains information to identify a SLATE. In the example above, when the request is supposed to be served by S2, S3, or S5, it will be served by the respective SUT in SLATE1.
Routing Requests
In Uber, we primarily have production and staging as runtime environments. SLATE is essentially an isolation created inside a production environment, where test instances of services (SUT) can be deployed. The runtime environment of a SUT is always production.
Tenancy-Based Routing
Since runtime environments of SUTs in SLATE and dependencies are production, the concept of Tenancy is introduced to distinguish the test requests from the production requests.
Tenancy is added in the request header as Jaeger Baggage (key: request-tenancy).
Jaeger Baggage is transparently propagated in a request call-tree, across services without being dropped. Availability of Jaeger Baggage and request-tenancy at every hop in the call-tree enables request routing to SUT instances of any service in call-tree. It makes SLATE available for E2E testing for most of the services.
By default, all requests have production tenancy. But for E2E test requests, tenancy is typically in form of uber/test*. Every SLATE environment has an associated tenancy of format uber/test/slate/<slate_env_uuid>. A request having uber/test/slate/SLATE1 will be routed to SUTs deployed in the SLATE1 environment as shown below:
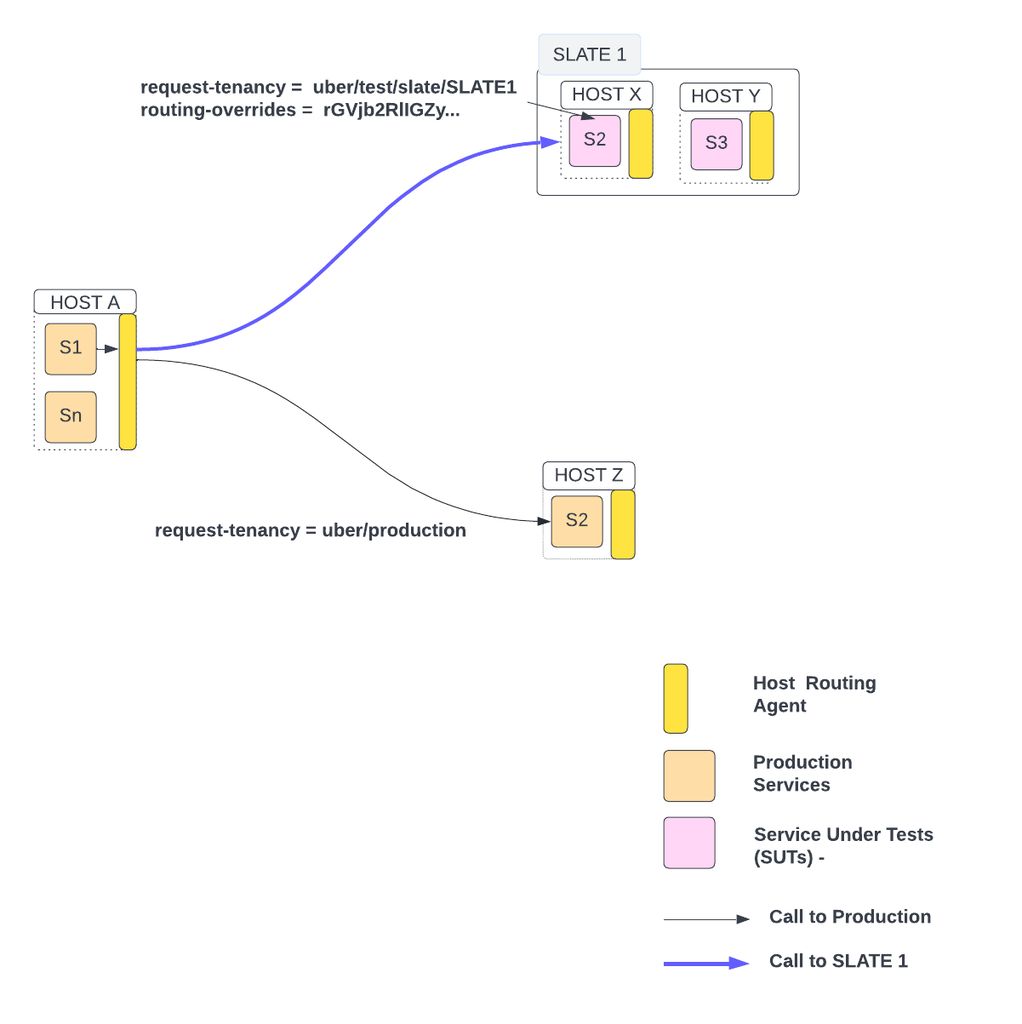
As shown above, routing-override derived from tenancy is used by the host-routing-agent to route the request between SUT and its production instances.
Services treat every request equally whether it’s production or test. There is no routing logic in services to decide between SUT and its production instances.
Our core infrastructure systems also understands tenancy:
- Logging and metrics systems recognize and allow isolation of test-triggered data
- Messaging systems (Kafka) route non-production streams appropriately
- Our alerting systems recognizes test traffic and does not page in case of failure
Tenancy Injection
Tenancy can be injected in a request’s Jaeger Baggage in following ways:
- A E2E test can explicitly set the tenancy header in the requests
- Edge-Gateway can inject test tenancy as described in User Association
Routing Override
Every SLATE environment is associated with a unique tenancy. When a SUT is deployed in SLATE environment, a mapping is created between the tenancy and routing info of SUT(s) in a config-cache, as shown below:

The routing info is called routing-override. It contains information about SUT(s), IP, and protocol-specific (tchannel, HTTP2, HTTP) PORTs supported by SUT. It is only created for SUT(s) deployed in SLATE.
Whenever a SUT is deployed, routing-override gets updated with new address information. If a SUT is redeployed, old routing information of SUT is replaced by new information.
When the SLATE environment is terminated, manually or after TTL expiration, routing-override mapping, SUT instances, and other resources are unclaimed or deleted.
Config-Cache
Config-cache is an in-memory and is synced on the hosts which subscribe for entries in config-cache. Since mappings are cached locally on a host, lookups in config-cache are extremely fast.
Reliability of config-cache: Config-cache is a highly available cache. If due to some reason mappings are not stored in config-cache or not synced on hosts, requests will fallback to production instances. This is not a concern due multiple levels of isolation in-place. Also, routing coverage observability gives clear insight in such edge-cases.
Routing Override Injection
As shown below, Edge-Gateway inspects tenancy (request-tenancy header) of a request. If its schema matches “uber/test*”, it looks into the config-cache to find the corresponding routing-override. Routing-overrides are added in the request header as Jaeger Baggage (key: routing-overrides).
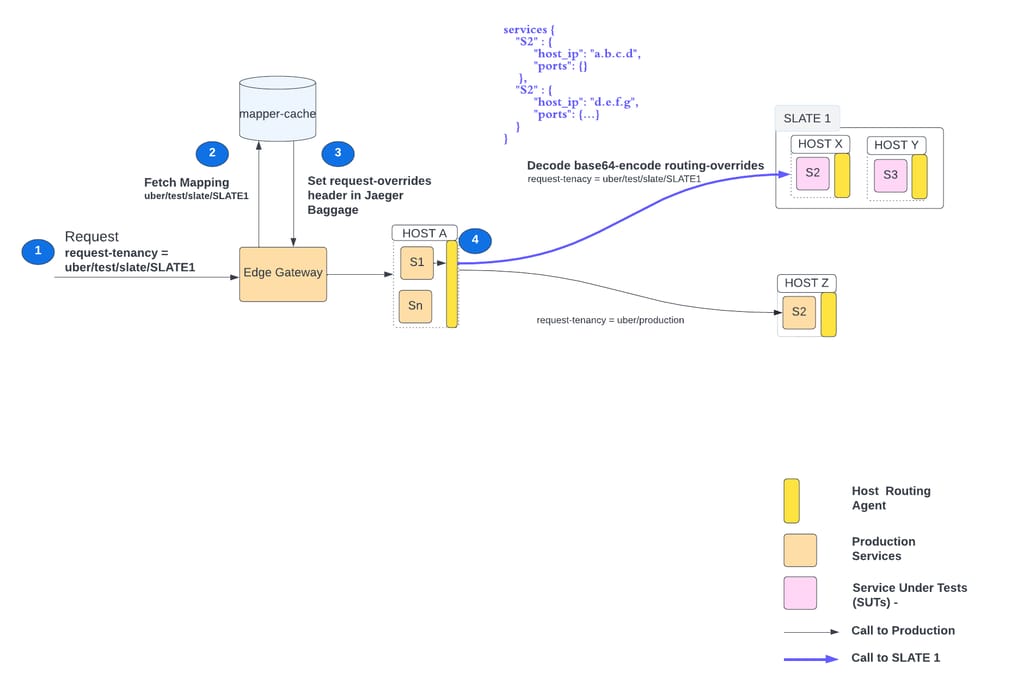
If the routing-overrides header is present in the request and it contains SUT info of the production instance (S2 in Figure 6), the host-routing-agent forwards the request to SUT (S2 in Blue in Figure 6) instead of a production instance.
Associating Users with SLATE Environment
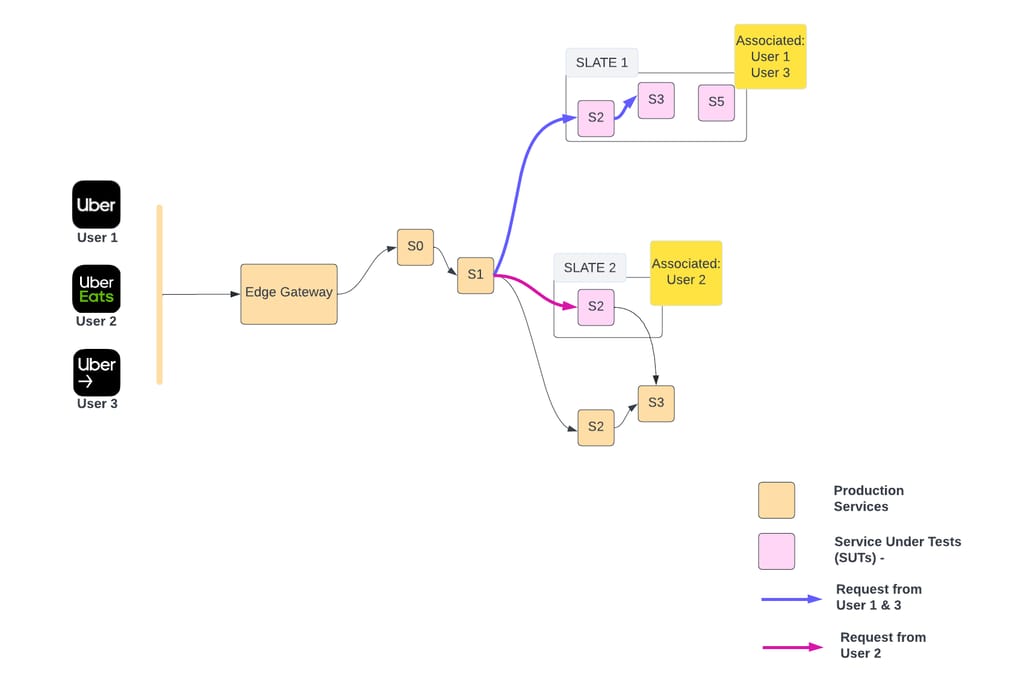
When a SLATE environment is created, the developer can associate a set of user accounts (TestAccounts). Once associated, only requests from the associated cohort of users will reach the SUTs. Association creates a mapping between test-accounts and tenancy of the SLATE environment in config-cache.

Edge-gateway inspects user-id in config-cache. If the user-id maps to a SLATE tenancy, respective routing-overrides information is injected into the request. Host-routing-agent takes care of the rest of routing as described in Figure 6.
User association allows developers to seamlessly test from mobile apps.
Routing in Asynchronous Flows
Flows or requests which are triggered by asynchronous events, there is no direct injection of request-tenancy or routing-override keys in Jaeger baggage as it happens in synchronous requests. As a result, routing to SUT can break for such asynchronous requests. The common pattern followed to mitigate this is to store the Jaeger Baggage info in the event payload, which can be later used to trigger the async request. One example of this is described at Isolation in Kafka.
Data Isolation
Since the runtime environment of SUTs in SLATE is production, they access their respective production dependencies. SUT and dependencies process requests as if they are production requests. They also use production datastores like databases, caches, kafka queues, etc.
As a result, extra care is needed such that entities like riders and drivers created for an E2E test are not matched with production requests. For example, a ride request created for the E2E test in SLATE should not match with an actual cab driver. Similarly a test-driver should not be matched with a ride request in production.
Isolation of Entities with Test-Accounts
To isolate entities like riders, drivers, trips, etc. from production entities, SLATE uses Test-Accounts.
Test-Accounts is a service that allows developers to create test riders, drivers, and other profiles. Any child entities like trips or orders created by test riders and drivers will also be test entities.
SLATE only allows to associate a test user. As a result, it enforces that a SUT can only receive requests for test entities and never for production entities.
Test entities are created and updated in production databases or Kafka queues. But they are individually isolated from production entities and can be easily identified as test entities. Any mutations on test entities do not affect production entities.
Isolation in Kafka
SUT deployed in SLATE has production configuration by default, and they publish and subscribe to the production Kafka topics. As a result, there is a risk that a SUT can consume production data from Kafka, or that a production Kafka consumer can consume test messages produced by SUTs.
We modified our Kafka client, which is now tenancy-aware. What this means for Kafka use cases is that all messages flowing in or out from Kafka will have tenancy associated.
- For producers, messages will be auto-tagged with proper tenancy info (based on the jaeger baggage in the request) routed to proper clusters automatically
- For consumers:
- If it’s an SUT, production instances won’t receive any test traffic, test instances will only receive traffic that matches its tenancy
- If it’s not an SUT, production instances will receive both production and test traffic, the expectation is it should be able to handle that traffic
Isolation in Asynchronous Workflows
Many product flows and use cases are asynchronous in nature. Async workflow can be simple enough to read a job from Kafka and process it. These cases are handled by isolation provided by Kafka.
But as the number of steps increases in an asynchronous workflow, like interacting with multiple systems, requeuing, etc., handling faults and providing guarantees becomes very hard. To solve this problem, Uber built Cadence. It is a workflow orchestrator that simplifies executing complex workflows by providing fault-tolerant abstractions. Internally, it maintains task-lists to add or fetch jobs to execute.
Since SUTs are deployed with production config by default, Cadence can fetch jobs from the production task-lists. This is not desirable.
We made the Cadence task-list configurable via the config file or environment variables. Environment variables can be injected when a service instance is launched. When an SUT is launched, we can set the task-lists in environment variables.
Isolation of Resources
Most services use their production resources like databases, queues, etc. Isolation approaches described above are sufficient for the majority of use cases. However there are services that need isolation of resources for E2E testing. They don’t want to share their production resources for E2E testing for reasons like compliance, security, etc. Their rest of upstream and downstream service dependencies are production only.
To provide isolation of resources per service, SLATE uses environment-based configuration overrides. In Uber, a service can define its base configuration in a YAML file. The base configuration is available in all the environments of a service. However, service can override some of the configuration for an environment by creating an environment specific configuration file like production.yaml, staging.yaml, etc.
SLATE allows service owners to override E2E resources in a config file called slate.yaml. Runtime environment of SUT for such services is set to SLATE rather than production. As a result, the slate.yaml config is automatically applied for SUT of these services, which defines their isolated resources.
Most of these services share common resources like databases, queues, etc., across multiple SLATE environments or developers. But this approach enables developers to have environment-specific resources as well as based on use cases.
SLATE CLI
SLATE provides a very simple CLI for developers to manage the E2E testing environment.

SLATE Server
SLATE server exposes APIs to manage environments, services, and users. These APIs are used by SLATE CLI (command-line interface).
Following is the high-level architecture of a SLATE server:
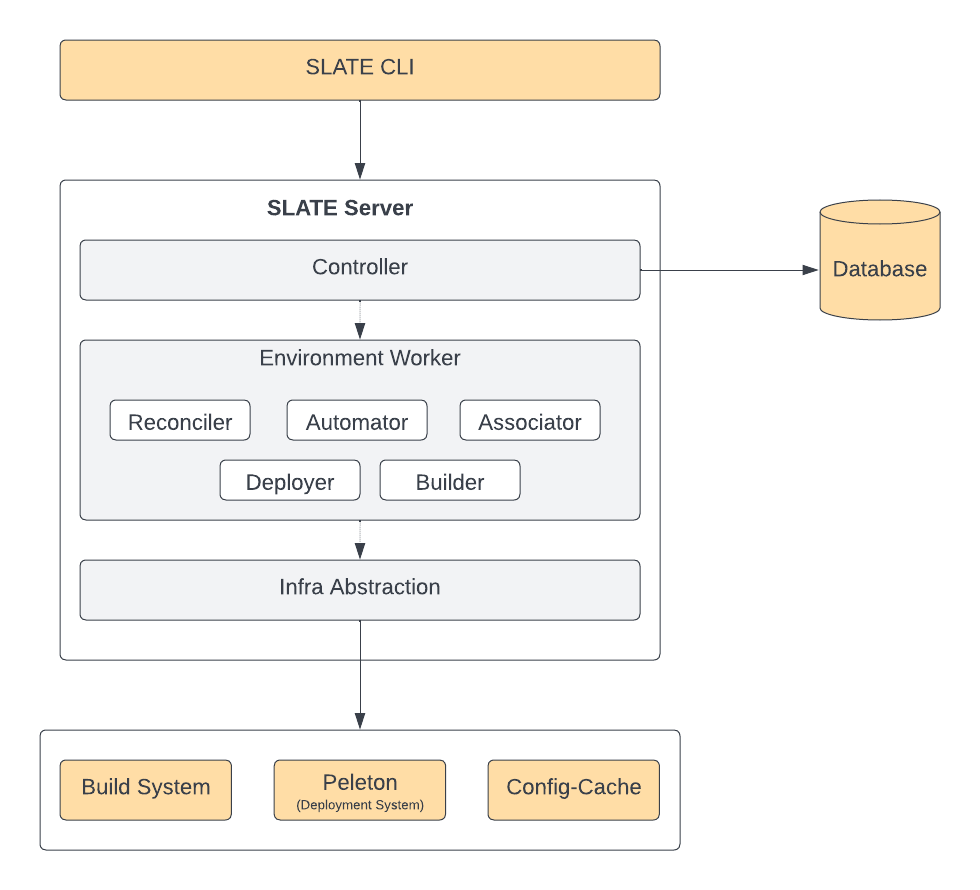
Controller
It implements APIs to manage the environment. These APIs are used to manage few of the following resources:
- Environment – CRUD, Clone APIs to manage the environment
- Services – APIs to deploy service(s), status of deployments etc.
- User – APIs to associate/dissociate users, list associated users
These APIs are used by SLATE CLI.
Environment Worker
Every SLATE environment is managed by a dedicated Environment-worker. It is a Cadence worker. Cadence workers are fault-tolerant and distributed. Each environment-worker has the following components:
- Builder: It uses the build-system in Uber’s infrastructure to build the service’s image.
- Deployer: It uses Peloton (a resource scheduler), to claim an instance to deploy a service image.
- Associator: This component is used to associate/dissociate users in an environment. It creates or removes user-ID mapping in config-cache.
- Reconciler: Developers can run commands for service deployments, associate or dissociate user-IDs concurrently, which can mutate the state of the SLATE environment. Once a command is successful, it might update entries like in config-cache.
- If these updates in config-cache are not done carefully, config-cache can contain stale entries. For example: Concurrent deployments of a service in a SLATE environment can cause stale updates of SUT addresses in routing-override. This can break the routing of the request to the SUT.
- The reconciler keeps the state of the SLATE environment safe. It runs as a control loop and brings the environment to the desired safe state, as shown below:
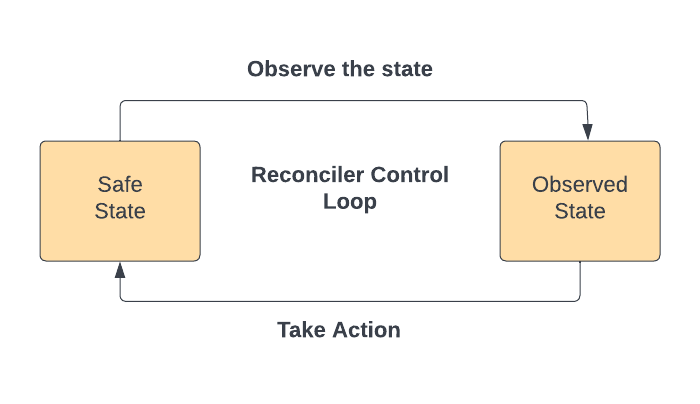
- Safe state is when following is met:
- The routing-override information is updated in config-cache with most recent address of healthy SUTs
- Associated and dissociated user-id are up to date in config-cache
- Duplicate, old, and unhealthy instances of a SUT are terminated
- Automator: SLATE CLI allows developers to apply a set of commands together, as shown below.
- Following is the example YAML definition specifying set of commands:

- Automator uses the YAML to keep the environment updated
- Same YAML file can be applied multiple times
- If there is any change in YAML, like a service or test added or removed, their configuration is changed, the automator applies those changes
- Automator can also run pre-defined tests or scripts periodically. This can be used for finding regressions over longer duration
- Automator can also send slack updates for the interesting events
Multiple Test Clients
Writing E2E tests for every feature is very time consuming for developers. SLATE allows the use of any API client like cURL, scripts, etc., to issue requests to SUTs. They can use mobile apps as well to test any feature. User association and tenancy routing enables this.
Freedom to use SLATE from multiple clients has significantly improved developer experience and testing velocity. Also it is enabling new use cases on SLATE apart from E2E testing, like a sandbox environment for third-party customers, shadow testing. etc.
Golden Environment
Many teams create golden SLATE environments, which can be used by team members to bootstrap the E2E testing environment faster. Golden SLATE environment can include:
- Custom test-user profiles (via TestAccounts) associated like drivers with documents verified, only cash payment, from New Delhi, India.
- Services which are supposed to be deployed together
- Sanity Tests, which needs to be run as environment is ready
- Periodic regression tests need to be run
Golden environment can be cloned by slate clone command.
Observability
Services deployed in a SLATE Environment have similar logging, tracing, and monitoring as compared to production instances. This enables developers to debug their features very quickly.
Routing-coverage observability is also provided to detect any edge-cases when a request does not hit SUT in SLATE but a production instance. Coverage information helps build confidence in developers on their E2E test.
Conclusion and Future Work
SLATE significantly improved the experience and velocity of E2E testing for developers. It allowed them to test their changes spread across multiple services and against production dependencies. Multiple clients like mobile, test-suites, and scripts can be used for testing services deployed in SLATE. A SLATE environment can be created on demand and can be reclaimed when not in reuse, resulting in efficient uses of infrastructure. While providing all this, it enforces data isolation and compliance requirements.
As SLATE is adopted across multiple developers, new use cases are emerging. We are experimenting to have multiple instances of a service deployed as a SUT rather than a single instance. This can help in load testing performance intensive features. Some teams are experimenting with deprecation of staging environments for their service in favor of SLATE. This will help in reducing costs and improving developer efficiency.

Alok Srivastava
Alok Srivastava is a Senior Staff Engineer on the Fulfillment team focused on systems enabling deep observability, improving reliability and developer experience.

Rohan Rathi
Rohan Rathi is a Software Engineer II on the Fulfillment team. Over the last 3 years he has contributed to scaling Uber’s Edge Platform and improving developer testing within Uber. He is currently solving challenges in Chaos Engineering.

Ankit Srivastava
Ankit Srivastava is a Principal Engineer at Uber. He has led and contributed to building software that scales to millions of users of Uber across the world. During the past 2 years, he led the ground-up redesign of Uber's Fulfillment Platform that powers the logistics of physical fulfillment for all Uber verticals. His interests include building distributed systems and extensible frameworks and formulating testing strategies for complex business workflows.
Posted by Alok Srivastava, Rohan Rathi, Ankit Srivastava
Related articles



Most popular

Automating Kerberos Keytab Rotation at Uber

The Evolution of Uber’s Search Platform

Slashing CI Costs at Uber
