LeakProf: Featherlight In-Production Goroutine Leak Detection
November 10, 2022 / Global
Go is a popular programming language used in microservice development, with one of the key features being first-class support for concurrency. Given its burgeoning popularity, it is no surprise that Uber adopted it: the Go monorepo is a centerpiece of its development platform, housing a significant portion of Uber’s codebase in the form of critical business logic, support libraries, or key components of the infrastructure.
Go’s concurrency model is built on goroutines–lightweight threads. Any function call prefixed with the “go” keyword launches the function asynchronously. Goroutines are used abundantly in Go codebases owing to low syntactical overhead and resource requirements, with programs often involving tens to hundreds or thousands of goroutines simultaneously. Two or more goroutines can communicate with each other via message passing over channels, a paradigm inspired by Hoare’s Communicating Sequential Processes. While traditional shared-memory communication is still an option, the development team behind Go encourages users to favor channels, arguing for higher tolerance against data races when used properly.
Goroutine Leaks
An unfortunate side effect of goroutines is goroutine leaks. A key component of channel semantics is blocking, where a channel operation stalls execution of a goroutine until a rendezvous is achieved (i.e., a communication partner is found). More specifically, for an unbuffered channel, the sender blocks until the receiver arrives at the channel and vice versa. A goroutine may be blocked forever trying to send or receive on a channel; such a situation where a blocked goroutine never gets unblocked is referred to as a goroutine leak. When too many goroutines leak, the consequences can be severe. Leaking goroutines consume resources such as memory from being released or reclaimed. Note, buffered channels can also cause a goroutine leak once the buffer is full.
Programmatic errors (e.g., complex control flow, early returns, timeouts), can lead to mismatch in communication between goroutines, where one or more goroutines may block but no other goroutine will ever create the necessary conditions for unblocking. Goroutine leaks prevent the garbage collector from reclaiming the associated channel, goroutine stack, and all reachable objects of the permanently blocked goroutine. Long-running services where small leaks accumulate over time exacerbate the problem.
Go distribution does not offer any out-of-the-box solution for detecting goroutine leaks, whether during compilation or at runtime. Detecting goroutine leaks is non-trivial as they may depend on complex interactions/interleavings between several goroutines, or otherwise rare runtime conditions. Several proposed static analysis techniques [1, 2, 3] are prone to imprecision, both reporting false positives or incurring false negatives. Other proposals such as goleak employ dynamic analysis during testing, which may reveal several blocking errors, but their efficacy depends on the comprehensive coverage of code paths and thread schedules. Exhaustive coverage is infeasible at a large scale; for example, certain configuration flags changing code paths in production are not necessarily tested by unit-tests.
Detecting goroutine leaks is complicated, especially in complex production codes using numerous libraries with thousands of goroutines at runtime employing numerous channels. There is a dire need to detect these leaks in production code. Such a tool needs to meet the following requirements:
- It should not introduce high overheads because it will be used in production workloads. High overhead both hurts SLAs and consumes more computational resources.
- It should have a low false positive rate; false leaks waste developer time.
A Practical, Lightweight Solution to In-Production Goroutine Leaks
We take a practical approach to detecting goroutine leaks for long-running programs in production that meets the aforementioned criterion. Our premise and critical observation are the following:
- If a programs has a non-trivial amount of goroutine leaks, it will be eventually visible via a high number of goroutine count blocked on some channel operation
- Only a few source code locations (involved in channel operations) account for most leaking goroutines
- Rare goroutine leaks, while not ideal, incur low overhead and may be ignored
Point #1 is justified by a spike in the number of goroutines for programs with leaks. Point #2 simply states that not all channel operations are leaky, but the source location of significant leak causes must be exercised frequently to expose the leak. Since any leaked goroutine persists for the remainder of a service’s lifetime, repeatedly encountering leaky scenarios eventually contributes to a large build-up of blocked goroutines. This is especially true for leaks caused by concurrency operations reachable via many different execution paths and/or in loops. Finally, point #3 is a practical consideration. If a leak-inducing operation is rarely encountered, the impact it has on memory build-up is less likely to be severe. Based on these pragmatic observations, we designed LeakProf, a reliable leak indicator with few false positives and a minimum runtime overhead.
Implementation of LeakProf
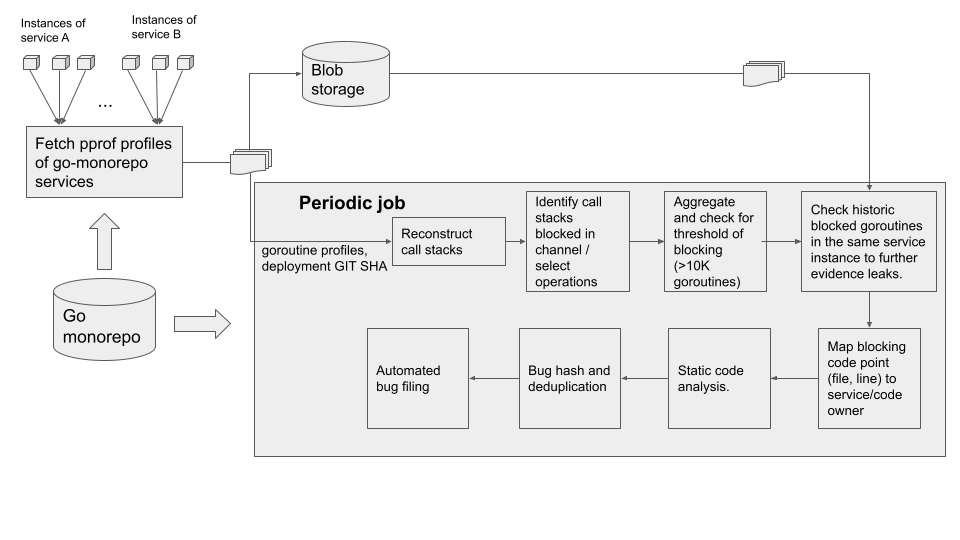
LeakProf periodically profiles the call stacks of currently running goroutines (obtained with pprof). Inspecting the call stacks for particular configurations indicates whether a goroutine is blocked on specific operations such as channel send, channel receive, and select. These are relatively straightforward to recognize as well-known blocking functions in the Go runtime. After aggregating blocked goroutines by the source locations of channel operations, an egregious number of blocked goroutines at a single source location, determined by a configurable threshold, is treated as a potential goroutine leak.
Our approach is neither sound nor complete. It, respectively, incurs both false negatives (i.e., not all leaks are guaranteed to be found), and false positives (i.e., reports may not represent a real leak). False negatives are caused whenever a program does not exercise leaky scenarios at runtime, or if the number of leaks does not exceed the configurable threshold. Conversely, false positives lead to spurious reports whenever a high number of goroutines are deliberately blocked as a natural consequence of the intended program semantics, and not due to a leak (e.g., heartbeat operations with high latency). To improve filtering of potential false positives, we are continuously developing complementary lightweight heuristics based on static analysis. For example, reporting a suspicious select statement involves analyzing its AST to determine whether one of the case branches involves waiting on known non-blocking operations (e.g., involving tickers or timers provided by the Go standard library); if this property is satisfied, the supposed leak will not be reported, regardless of the number of blocked goroutines, as it is a definite false positive. It may also feature a configurable list of known false positives. Regardless, the approach works very well in practice to detect non-trivial leaks with a large impact on production services, as evidenced below.
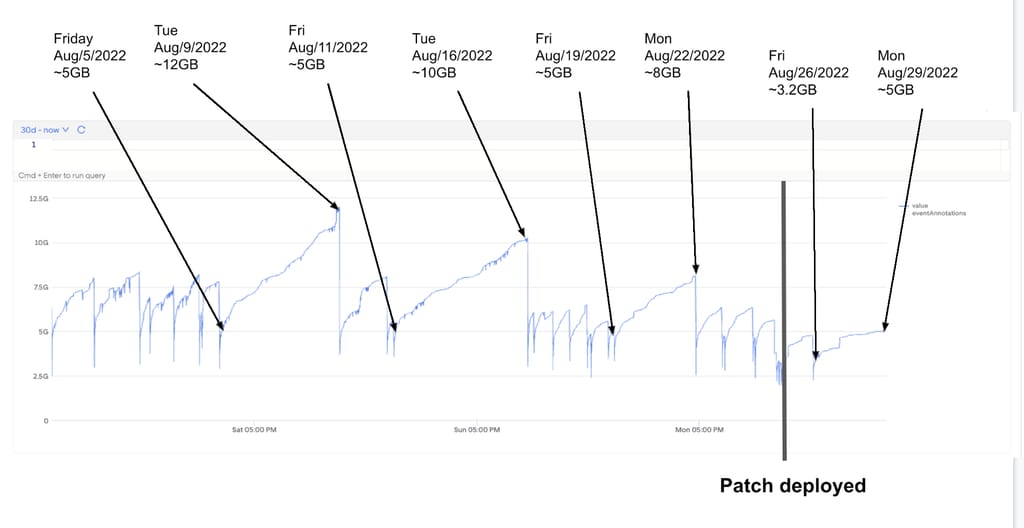
When deployed at Uber, LeakProf leverages profiling information to collect blocked goroutine information and automatically notifies service owners for suspicious concurrency operations. Operations are deemed suspicious if the number of blocked goroutines exceeds a given threshold, and only if they are part of the Uber code base. The efficacy of this approach was proven quickly, finding 10 critical leaking goroutines, and only 1 false positive. Addressing 2 of the defects each resulted in a 2.5x and a 5x reduction in the service’s peak memory, with the service owners voluntarily reducing the container memory requirements by 25%.
Leaky Go Program Patterns
An analysis of goroutine leaks found in production has relieved the following common patterns of leaky code patterns.
Premature Function Return
This leak pattern is caused whenever several goroutines are expected to communicate, but some code paths return prematurely without participating in the channel communication, leaving the other participant waiting forever. This occurs when communication partners do not account for all of each other’s possible execution paths.
Example

The channel c (line 2) is used by the child goroutine (line 3) to send an error (lines 5 or 8). The corresponding receive operation on the parent thread (line 18) is preceded by several if statements which may return (lines 13 and 15) prior to waiting to receive from the channel on line 18. If the parent goroutine follows any of these returns, the child goroutine will block forever, irrespective of which send operation it performs.
A possible solution to prevent the goroutine leak where a child goroutine sends a message on channel and the parent may not want to ignore it is to create the channel with a buffer size of 1. This allows the child sender to unblock on the communication operation, irrespective of the behavior of the parent receiver goroutine.
The Timeout Leak
While this bug may be framed as a special case of the premature function return pattern, it deserves its own entry due to sheer ubiquity. This leak often appears when combining unbuffered channel usage with either timers or contexts, and select statements. The timer or context is often used to short-circuit the execution of the parent goroutine and abort early. However, if the child goroutine is not designed to consider this scenario, it may lead to a leak.
Example
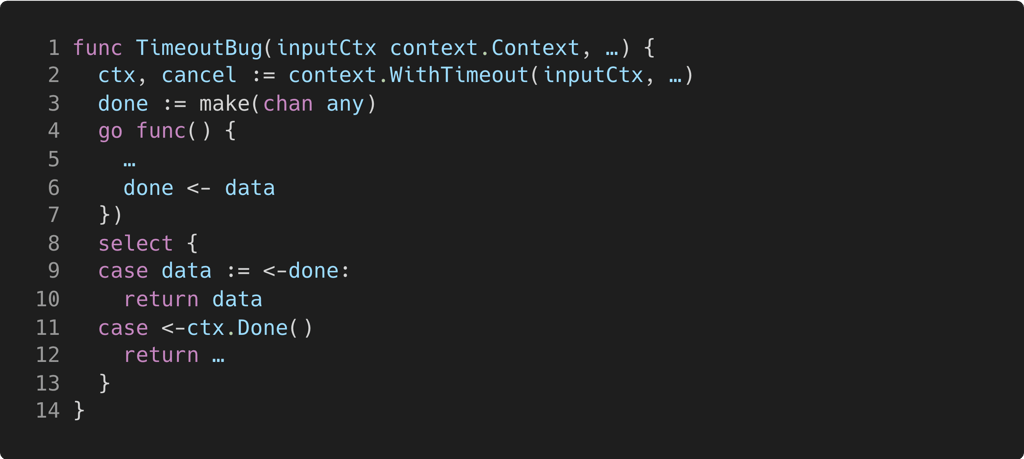
Channel done (line 3) is used with a child goroutine (line 4). When the child goroutine sends a message (line 6), it blocks until another goroutine (ostensibly the parent) reads from done. Meanwhile, the parent waits at the select statement on line 8, until it synchronizes with the child (line 9), or when ctx times out (line 11). In the event of a context timeout, the parent goroutines returns through the case on line 11; as a result, there is no waiting receiver when the child sends. Consequently, the child will leak, as no other goroutine will ever receive from done.
This leak can similarly be averted by increasing the capacity of done to 1.
The NCast Leak
This kind of leak occurs whenever the concurrent system is framed as a communication between many senders and a single receiver on the same channel. Moreover, if the receiver performs only one receive on the channel, all but one of the senders will block forever on the channel.
Example

The channel dataChan (line 2) is passed as an argument to the goroutines created in the for-loop on line 4. Each of the child goroutines attempts to send a result to dataChan, but the parent only receives from dataChan once, and then exits the scope of its current function, at which point it loses the reference to dataChan. Since dataChan is unbuffered, any child which did not synchronize with the parent will block forever.
The solution is to increase the buffer of dataChan to the length of items. This preserves the property that only the first result sent to dataChan will be received by the parent thread, while allowing remaining child goroutines to unblock and terminate.
A more general form of this problem occurs when there are N senders and M receivers, N > M, and each receiver only performs one receive operation.
Channel Iteration Misuse
This leaky pattern may occur when using the range construct with channels. Understanding this leak requires some familiarity with the close operation and how range works with channels. The leak is caused whenever a channel is iterated over, but the channel is never closed. This causes the for loop iterating over the channel to block indefinitely because the loop does not terminate unless the channel is closed; the for loop blocks once all items are received from the channel.
Example

For brevity, we will borrow the producer-consumer dichotomy introduced in Communication contention. A channel, queueJobs, is allocated at line 3. The producers are the goroutines spawned in the for loop (line 3), where each sends a message (line 5). The consumer (line 8) reads the messages by ranging over queueJobs. As long as an unconsumed message exists, the loop at line 9 will perform an iteration of the loop. The expectation is that once the producers no longer send messages, the consumer will exit the loop and terminate. However, in the absence of a close operation on the channel, range will simply block once no more messages are sent which leads to a leak.
Since the parent of the producers and consumers waits until all messages are delivered (via the WaitGroup construct), the solution is to add close(queueJobs) after wg.Wait(), or as a deferred statement immediately after queueJobs is defined. Once all messages are sent, the parent thread closes queueJobs, signaling to the consumer to stop iterating over queueJobs, and therefore terminate and be garbage collected.
Conclusions and Future Work
Goroutine leaks are a pervasive problem that are difficult to detect statically and can lead to a large waste in terms of computational resources. LeakProf identifies those goroutine leaks that are egregious or accumulate over time in long-running production services. It detects goroutines blocked on channel operations via profiling programs followed by aggregating the goroutines blocked at the same source location, which is often a symptom of leak. When the number of leaking goroutines is large, LeakProf works well in raising an alarm.
LeakProf’s efficacy was demonstrated quickly, given the number of leaks it found in a relatively short time frame. Another critical component is the insight gained by inspecting the code causing the reported leaks, which led to the discovery and synthesis of several problematic coding patterns. Notably, the discovered patterns showcase potential opportunities for the development of linters tailored for reporting and preventing leaks that would be caused by code conforming to the outlined patterns. Other future work includes devising better heuristics for determining the blocking goroutine threshold on a per-profile basis, with the intent to more effectively detect leaks in smaller programs, and further enhancements to the supplementary static analysis suite performed post-detection.
Main image by Magnus Dahlgren under the Creative Commons license

Georgian-Vlad Saioc
Georgian-Vlad Saioc is a Ph.D. Software Engineering Intern in the Programming Systems Research team at Uber, and PhD student at Aarhus University, Denmark. His interests involve programming language design and analysis, with a focus on developing automated tools tailored towards improving code quality.

Milind Chabbi
Milind Chabbi is a Staff Researcher in the Programming Systems Research team at Uber. He leads research initiatives across Uber in the areas of compiler optimizations, high-performance parallel computing, synchronization techniques, and performance analysis tools to make large, complex computing systems reliable and efficient.
Posted by Georgian-Vlad Saioc, Milind Chabbi
Related articles


Most popular

Migrating Large-Scale Interactive Compute Workloads to Kubernetes Without Disruption

Building Uber’s Multi-Cloud Secrets Management Platform to Enhance Security

Robust Database Backup Recovery at Uber
