Automated Audit Framework For Internet Scale Financial Transactions
June 15, 2023 / Global
Introduction
Uber, like most companies that charge customers for services, needs to record the financial interactions with its riders, eaters, earners, and other customers. The systems we have built ensure that every internal and external money movement (payments, promotion grants/redemption or expiry, credits, tolls, taxes) is completely accounted for. This is a complex compliance computation activity at an internet scale of millions of trips per day. We have already written about this, and you can read this blog to understand Uber’s financial computation platform in depth.
As a financial system of record, it needs to meet the stringent requirements of an external audit that is conducted at regular cadence. Financial Audit is a process that occurs periodically (every month or quarter) to ensure completeness, accuracy, and traceability of financial transactions. This validates the accuracy of financial reports published to regulators and the street.
Motivation
As an example, let’s try to understand the challenges of auditing historical transactions related to a trip.

Let us assume a rider takes a trip from their home to the airport in Jan 2022 and is charged $60. After 6-7 months, the rider takes another trip from their home to the airport, but is now charged $50. On both rides, the rider used UberX with the same origin and destination. Now, the user is concerned about discrepancies in charge, and raises a dispute.
There could be a lot of things that could be different now:
- The pricing for the same service (e.g., UberX) could have changed due to fuel pricing or some other factors.
- There could be new state taxes that were removed or introduced for specific services. The state may have subsidized/removed some tolls for some period.
- There could be congestion due to rain or other factors, causing the trip to take longer. Also, some roads could be blocked due to maintenance work.
- There could be city-wide or personal promotions that were applied on your trip.
Apart from the factors mentioned, there could be other business logic changes as well. Now think of doing this for millions of trips (in the past quarter, year, or years).
From a software engineering perspective, for a given input (source events) and output (generated internal transactions), we can think of it as having enough logs to debug what exactly happened (and why) for a given instance of execution, including but not limited to the source and execution logic logs.
Two major challenges that need to be addressed here are the reproducibility and traceability of financial transactions.
Reproducibility
We follow a zero-proof double-entry bookkeeping system (for GAAP compliance), so a corresponding entry is made for every movement; debit and credit.
Given the facts (e.g., route, pricing, promotions, accounting rules, and flow) at that time we should be able to generate the exact same financial entries. This ability to transform facts into target entries or reports is called reproducibility.
Traceability
Given a report or journal entry, auditors may want to know why we had booked them, or may want to know what trips or movements resulted in these journal entries. From a report or an entry in a report, the ability to map it back to the trips/orders, accounting rules, and facts that were used to generate the particular journal entry is called traceability.
The ability to trace which transactions were affected by a given bug or faulty accounting rules helps in impact analysis as well as in correction of those transactions. Without traceability, the task of finding the set of affected transactions among millions of transactions would be like finding a needle in a haystack.
External Audit Process

Auditors want to ensure that the accounting books are correct and in accordance with existing laws and regulations. Given the limited time they have, they cannot really verify accounting for each transaction. Hence, as part of Audit sampling they pick a varied set of a few hundred trips from different regions and lines of business (e.g., UberX, Pool, Eats), and manually generate financial entries for the sample. Based on the comparison of expected journal entries and booked journal entries, the total variance gets extrapolated. It is therefore important to have reproducibility and traceability of transactions.
To give a perspective, from a few random trips, if the difference between expected and reported accounting was found to be 1 cent/trip, the extrapolation would be 15 million dollars for a quarter. The company may need to pay a hefty penalty for a discrepancy like this.
High or frequent discrepancies and failure to conclude an audit on time would be a trust-buster and also have legal implications.
How do Events and Business Rules Change Over Time?
Here are some key design considerations:
Logic Changes:
Some of you may be wondering: why is this complex? It is not as simple as taking the facts for each trip as mentioned in the earlier example, repeating the same process for all trips, and executing the rules on it. This is because business rules and flows also change with time and need to be accounted for.
Uber operates in over 70 countries, each having their own regulations. Modifications and updates are not really that uncommon. Moreover, as we expand and enhance our business model, we need to onboard business changes and also update business flows. So you may need to use different logic for different trips depending on when it occurred (or more accurately, when it was processed by our system). Specifically, we should be able to map each transaction back to facts, specific business rules, and flow used.
Environment Changes:
Now based on the need for reproducibility, one may conclude that for a given change in logic or code there can be a lot of rules to take into account, but they are still finite. If we can assume we have a service binary for each of these changes, based on the need, we can process all events through appropriate service binaries, and reproduce the exact same entries. Unfortunately, that isn’t the whole picture. Services by design interact with different systems like datastores, queues, caches, as well as other services. This ever-changing environment of peripheral systems and technologies makes it all but impossible to consistently reproduce the exact conditions that would allow you to run the same binary and achieve the same outcome. So, apart from the maintenance of binaries for each code/rule change, any change in peripheral systems could need additional manual efforts to set up the sandbox infrastructure to execute the same binary again.
Scale:
We need to ensure that the solution can scale to internet-scale operations.
Cost:
While designing a system, we need to keep in mind the manual effort as well as the storage and maintenance cost it brings with it.
Execution Time:
The total cost of the audit operation is dependent on execution time. Also, based on regulations for public companies, financial reporting is a time-critical and time-bound process.
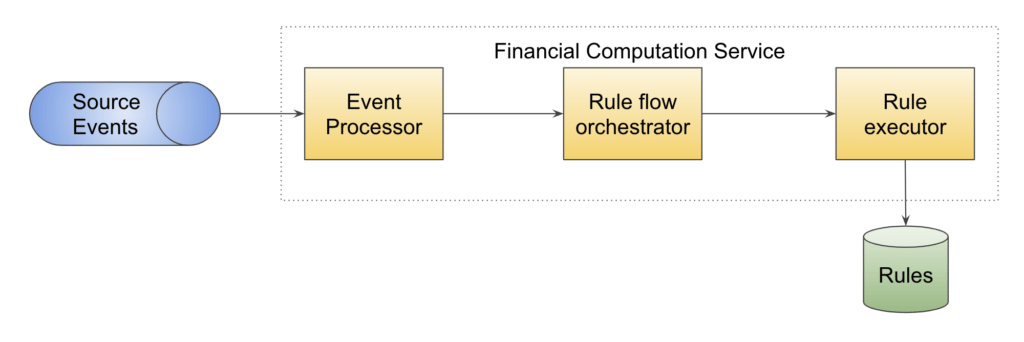
Bird’s-Eye View
Events from multiple sources reach the event processor through a message queue (Apache Kafka® in our case). Based on the type of event and entities involved in it, an execution plan is created.
An execution plan orchestrates which rules need to get executed and in which order. The plan can get extended during execution based on additional parameters, and hence is dynamic in nature.
Each step is executed in the rule executor, which executes appropriate rules from the rules repository. The audit events are captured for the financial transactions on a daily basis.
Rule Execution Example
Here, let’s take an example to understand it better.

The process function here takes an input and runs a series of rulesets on it to generate final journal entries. Ruleset1 and ruleset2 are different rulesets being executed through the rule executor. Each step or every call to the rule executor provides a specific result. It queries the rules repository, and from a series of rules, executes appropriate rules based on the input parameters. The output of each step is either part of the final accounting journal entry or is used by the next steps/rulesets.
For example, ruleset1 here could be a step responsible for determining the entity to be used (e.g., Uber India is considered a different entity than Uber US). The entity may depend on fields like city or product used. And there could be other steps that depend on the entity for rule execution. So, here the rule executor runs the input through rulesets, picks up appropriate rules and returns an entity post rule evaluation.
As can be seen here, the flow and steps change based on the result of the previous step.
Now, if we consider the execution steps as nodes, we observe that the whole execution plan is nothing but a directed acyclic graph (DAG). Please note that this is not a dependency graph–it just shows the execution of rules in a particular order.

Here, when executing ruleset1, the r1 rule was picked based on the input parameters. Similarly r2 represents the rule picked when ruleset2 was run.
The graph here tells that r1 was executed first followed by r2, and based on the result of r2, for different entries, r31(a), r32, r33 and r31(b) were executed. Note that, based on the entry different rules r31(a) and r31(b) were picked for the same rule set based on the input.
After a series of such steps, the final results at the end of each branch would be an accounting journal entry.
So, if we can store this DAG for each transaction along with the specific rule executed at each node, we do not need the code anymore for reproducibility and traceability. We can refactor or add or remove new methods/conditions in the code and it will be automatically taken care of, because we are maintaining the graph of which rules are getting executed and in what order.
Data Model

So, with the initial inputs (let us call it rule params, because those are just parameters used in rules) and rule execution flow we can actually build a self-sufficient event that could be used for audit purposes.
This audit event contains everything (rule params are data and DAG being the logic) needed to reproduce the same journal entries. Also, if we just keep mapping audit events for each booked accounting transaction, we can actually trace specific transactions or entries back to the business flow and rules (stored as part of DAG) as well as the facts that caused it. Hence, the same audit event solves both reproducibility as well as traceability.
Here, as observed in the diagram, an audit event may have multiple items like promotions, credits, taxes, tolls; and each item may have separate rule params and rule execution flow. So, an audit event is not always a single rule params and rule execution flow.
Apart from multiple items, there are cases where we have multiple parties involved for a specific line item (e.g., airport, tolls, rider, driver, Uber for airport pickup).
For example, airport fees need to be collected from riders, and are paid to the authority. Also, it is adding to gross booking and then offsetting our revenue, as it is not something we would keep.

If we put a decorator over the rule flow orchestrator, that ensures the execution flow is captured appropriately; for each transaction generated, we will have a corresponding audit event. Also, we are only storing relevant data attributes from source events as rule params in the audit event. These events are then pushed to a secure queue (secure Kafka in our case).
The queue can be consumed by a service, Apache Flink® job, or any other type of consumer to continuously listen to the audit events. This queue enables us to do a lot of things.
As a fintech platform, we want to continuously consume the audit event, and verify that for each generated transaction we have corresponding audit events to prove completeness of audit events. The consumer can utilize a generic logic (depth-first search traversal of a Directed Acyclic Graph) to process an audit event. The accuracy of the audit event can be validated by comparing it to the actual recorded transaction. In this context, the logic can be viewed as a plug-in, allowing us to incorporate code developed by financial auditors and demonstrate that our systems are functioning as intended without revealing our underlying codebase to the auditors.
The audit events are stored in HDFS for long-term retention, facilitating audit queries and other use cases.
Recomputation and Reconciliation

The JSON blob on the left contains an audit event item related to airport fees. It includes the audit UUID, transaction UUID, input parameters, and the execution flow itself.
In this context, the rulePlan describes the process where input parameters are passed through the business ruleset. It specifies the exact rule that was executed. This is followed by the entity ruleset and a series of other related flows. Essentially, the rulePlan is a JSON representation of the directed tree mentioned earlier.
By running the input parameters through the execution plans, journal entries similar to those mentioned on the right are generated. These entries can be compared or linked to the actual booked transactions and entries to ensure reproducibility.
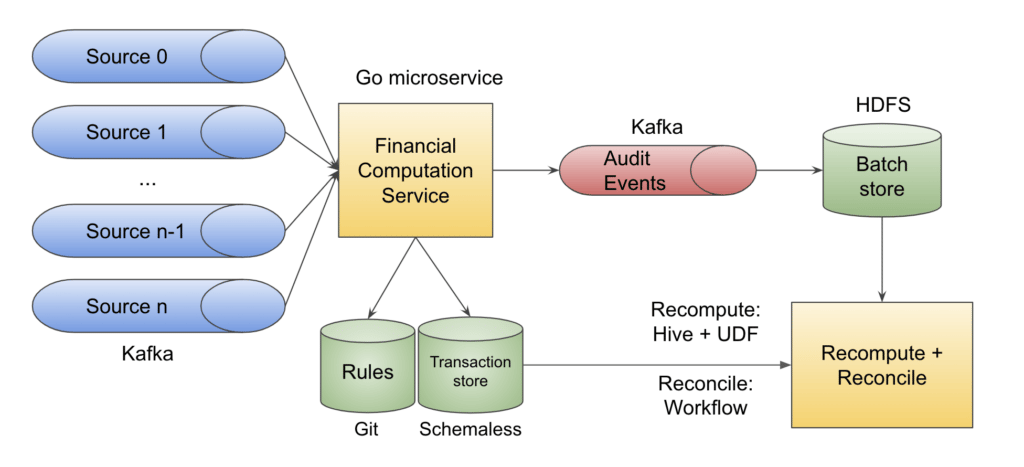
Holistically, we have multiple upstreams emitting all types of different money movements (e.g., trip completion, charge failed, promotion and credit grants, or redemption). Our service (Financial Computation Service) consumes all these Kafka messages and processes them as mentioned in the previous flow. Hence, each upstream event gets converted into one or more transactions, each containing some journal lines and some event-related metadata.
Our service uses the appropriate accounting rules committed in Git to generate these transactions. As a financial control, all these commits are approved by the accounting team, and hence adhere to SOX compliances and controls.
Transactions are written into an immutable, append-only transaction store. We use our in-house NoSQL datastore Schemaless as our transaction store. For each transaction written, we publish a compressed audit event to a secure and lossless Kafka topic. HDFS here is used as a persistent storage for the audit events, so we can query the data or run recompute on it for our use cases. These Hive tables can be queried to support ad hoc audit requests and to provide traceability.
We have daily jobs on this batch store to read daily data and run recompute on it to verify whether the transactions written in Schemaless are in sync with the data generated by recompute. The recompute method is a pluggable module, and we have implemented it in Java as a Hive User-Defined-Function. So, recompute can be executed just like another hive query without any engineering support.
The recompute function is written in different languages using different rule engine libraries. So, in case of any bugs or unwanted changes in the actual library used by the Go service, we can detect potential regressions early. Also, if auditors want, they can provide their own function, and run the same events through their library to ensure that rule execution is working as expected.
Results
With this framework, we are able to scale the solution for over 1 billion accounting transactions per day, with the ability to scale horizontally as well in the future.
Financial Audit sometimes asks us to reproduce all the transactions related to a given trip. Each trip is composed of multiple events and hence does not always occur on the same day or month. With queryable data in Hive through transactionUUID, data analysts and auditors are able to easily slice and dice data to measure impact as well as ensure reproducibility and traceability of trip samples. We have reduced overall manual effort by 60%.
We are able to recompute every audit event occurring in the quarter within SLA of just a few hours using standard Hive configurations, but this can be horizontally scaled by adding more compute to it.
This capability supports hundreds of rules as well as code changes, without any change needed in any of the audit components, recompute methods, or engines.
Additionally, the ability to audit continuously helps us in monitoring the health of the system on a daily basis. This enabled us to run an audit every day on our financial systems, identifying and remediating any issues in time for the audit.
Conclusion
With Tesseract audit framework, we can ensure that each and every event processed by Uber’s financial system is auditable and traceable even at internet scale. Architecture is extensible to support onboarding of new data sources without having to modify the framework. Accounting Operations team could modify rules to serve business needs without having to worry about future audit discrepancy concerns. In terms of what’s next, we are looking to continuously improve cost optimization, reliability, and storage footprint, making life easier for Accounting Operations with self-serve capabilities and other improvements.

Hasit Bhatt
Hasit Bhatt is a Sr. Software Engineer on the Cognitive Platform team at Uber. He was one of the lead engineers who conceptualized the Tesseract framework, implemented proof of concept on how audit events can be designed and replayed in future to simplify the audit process. He was a core contributor to the design and execution of audit event capturing and republishing, as well as setting up automated completeness pipelines for audit.

Saurabh Kathpalia
Saurabh Kathpalia is a Sr. Software Engineer on the Delivery team at Uber. He was one of the lead engineers who conceptualized the Tesseract framework while working on the Fintech team. He was a core contributor to the design and execution of audit event generation, setting up automated audit pipelines, working with the audit agencies for the approval of the audit process, etc.

Shashank Agarwal
Shashank Agarwal is a Senior Staff Software Engineer and has been with Uber for more than 5 years. Shashank Agarwal played a pivotal role in initiating the project's vision, providing invaluable guidance to the team on crucial design decisions. He has led multiple architectural contributions within Fintech at Uber. Currently, he is leading the efforts to standardize Fares at Uber and increase operational efficiency. He has more than 16 years of experience in Software Development, and outside of Uber he has built messaging platforms as well as mobile and desktop applications.

Jayram Kumar
Jayram Kumar is a Staff Software Engineer and lead on the FinTech team at Uber. He has led and built reliable and efficient transaction processing services for Uber’s Financial systems. Currently, his work focuses on scaling and enhancing the Financial Accounting and Reporting platforms, supporting generic auditing capabilities at an internet scale.

Hari Srinivasan
Hari Srinivasan is the Director of Engineering—Fintech at Uber. Leading a technically skilled team of engineers, he oversees the development of the platform that facilitates seamless financial accounting of all transactions and money movement within Uber.
Posted by Hasit Bhatt, Saurabh Kathpalia, Shashank Agarwal, Jayram Kumar, Hari Srinivasan
Related articles




Most popular

Robust Database Backup Recovery at Uber

Enhanced Agentic-RAG: What If Chatbots Could Deliver Near-Human Precision?

From Archival to Access: Config-Driven Data Pipelines
