Building a Large-scale Transactional Data Lake at Uber Using Apache Hudi
June 9, 2020 / Global
From ensuring accurate ETAs to predicting optimal traffic routes, providing safe, seamless transportation and delivery experiences on the Uber platform requires reliable, performant large-scale data storage and analysis. In 2016, Uber developed Apache Hudi, an incremental processing framework, to power business critical data pipelines at low latency and high efficiency. A year later, we chose to open source the solution to allow other data-reliant organizations to leverage its benefits, and then, in 2019, we took this commitment a step further by donating it to the Apache Software Foundation. Now, almost a year and a half later, Apache Hudi has graduated to a Top Level Project under The Apache Software Foundation. As we mark this milestone, we’d like to share our journey to building, releasing, optimizing, and graduating Apache Hudi for the benefit of the larger Big Data community.
What’s Apache Hudi?
Apache Hudi is a storage abstraction framework that helps distributed organizations build and manage petabyte-scale data lakes. Using primitives such as upserts and incremental pulls, Hudi brings stream style processing to batch-like big data. These features help surface faster, fresher data for our services with a unified serving layer having data latencies in the order of minutes, avoiding any added overhead of maintaining multiple systems. Adding to its flexibility, Apache Hudi can be operated on the Hadoop Distributed File System (HDFS) or cloud stores.
Hudi enables Atomicity, Consistency, Isolation & Durability (ACID) semantics on a data lake. Hudi’s two most widely used features are upserts and incremental pull, which give users the ability to absorb change data captures and apply them to the data lake at scale. Hudi provides a wide range of pluggable indexing capabilities in order to achieve this, along with its own data index implementation. Hudi’s ability to control and manage file layouts in the data lake is extremely important not only for overcoming HDFS namenode and other cloud store limitations, but also for maintaining a healthy data ecosystem by improving reliability and query performance. To this end, Hudi supports multiple query engine integrations such as Presto, Apache Hive, Apache Spark, and Apache Impala.
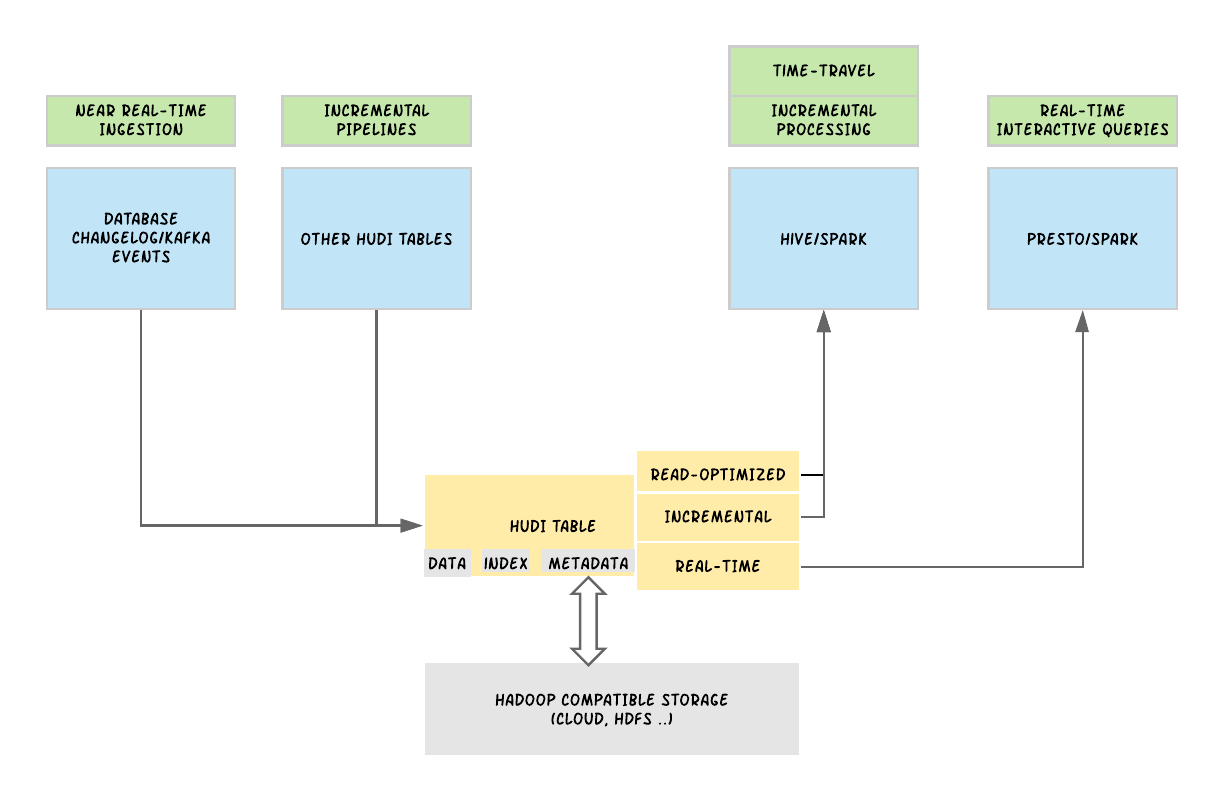
At a high level, Hudi is conceptually divided into 3 main components: the raw data that needs to be stored, the data indexes that are used to provide upsert capability, and the metadata used to manage the dataset. At its core, Hudi maintains a timeline of all actions performed on the table at different points in time, referred to as instants in Hudi. This offers instantaneous views of the table, while also efficiently supporting retrieval of data in the order of arrival. Hudi guarantees that the actions performed on the timeline are atomic & consistent based on the instant time, in other words, the time at which the change was made in the database. With this information, Hudi provides different views of the same Hudi table, including a read-optimized view for fast columnar performance, a real-time view for fast data ingestion, and an incremental view to read Hudi tables as a stream of changelogs, depicted in Figure 1, above.
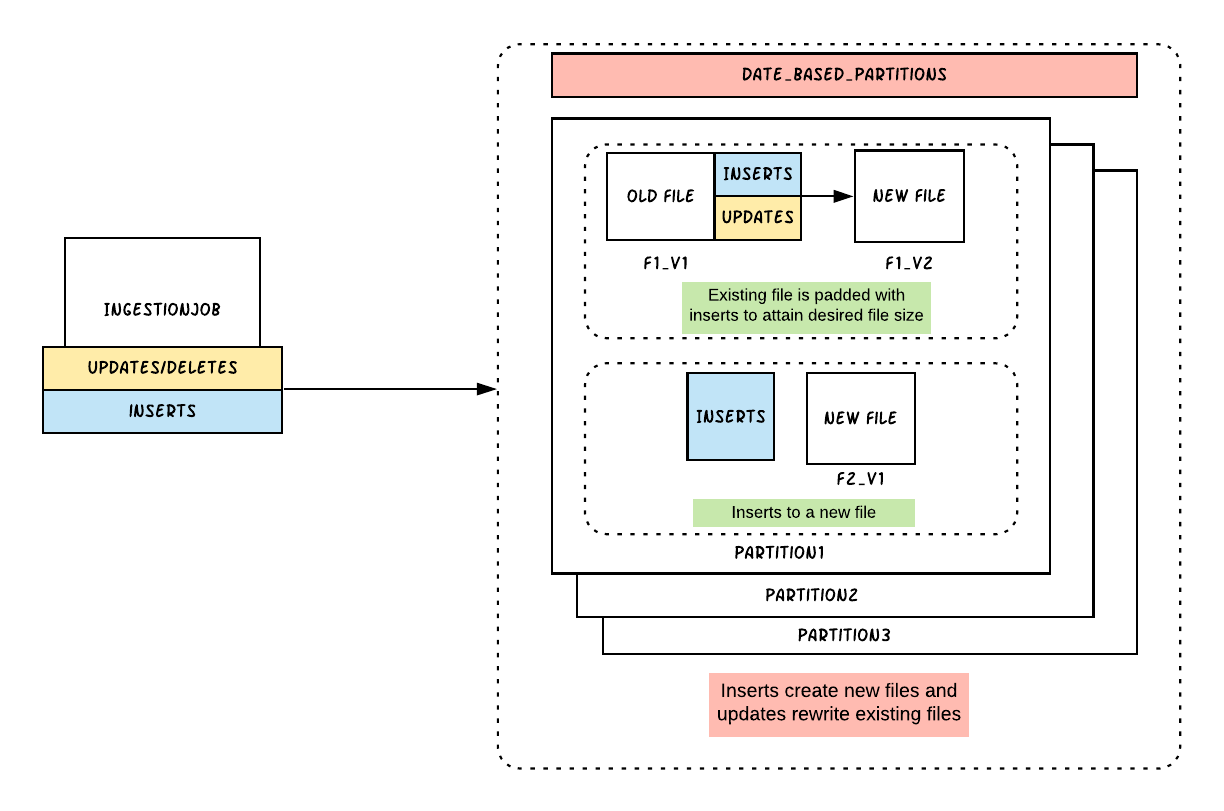
Hudi organizes data tables into a directory structure under a base path on a distributed file system. Tables are broken up into partitions, and within each partition, files are organized into file groups, uniquely identified by a file ID. Each file group contains several file slices, where each slice contains a base file (*.parquet) produced at a certain commit/compaction instant time, along with set of log files (*.log.*) that contain inserts/updates to the base file since the base file was produced. Hudi adopts Multiversion Concurrency Control (MVCC), where compaction action merges logs and base files to produce new file slices and cleaning action gets rid of unused/older file slices to reclaim space on the file system.
Hudi supports two table types: copy-on-write and merge-on-read. The copy-on-write table type stores data using exclusively columnar file formats (e.g., Apache Parquet). Via copy-on-write, updates simply version and rewrite the files by performing a synchronous merge during write.
The merge-on-read table type stores data using a combination of columnar (e.g., Apache parquet) and row based (e.g., Apache Avro) file formats. Updates are logged to delta files and later compacted to produce new versions of columnar files synchronously or asynchronously.
Hudi also supports two query types: snapshot and incremental queries. Snapshot queries are requests that take a “snapshot” of the table as of a given commit or compaction action. When leveraging snapshot queries, the copy-on-write table type exposes only the base/columnar files in the latest file slices and guarantees the same columnar query performance compared to a non-Hudi columnar table. Copy-on-write provides a drop-in replacement for existing Parquet tables, while offering upsert/delete and other features. In the case of merge-on-read tables, the snapshot queries expose near-real time data (order of minutes) by merging the base and delta files of the latest file slice on-the-fly is provided. For copy-on-write tables, incremental queries provide new data written to the table since a given commit or compaction, providing change streams to enable incremental data pipelines.
Using Apache Hudi at Uber
At Uber, we leverage Hudi for a variety of use cases, from providing fast, accurate data about trips on the Uber platform, from detecting fraud to making restaurant and food recommendations on our UberEats platform. To demonstrate how Hudi works, let’s walk through how we ensure trip data in the Uber Marketplace is fresh and up-to-date on the data lake, leading to improved user experiences for riders and drivers on the Uber platform. A trip’s typical life cycle begins when a rider requests a trip, continues as the trip progresses, and finishes when the trip ends and the rider reaches their final destination. Uber’s core trip data is stored as tables in Schemaless, Uber’s scalable datastore. A single trip entry in a trips table can experience many updates during the lifecycle of a trip. Before Hudi was implemented at Uber, large Apache Spark jobs periodically rewrote entire datasets to Apache HDFS to absorb upstream online table inserts, updates, and deletes, reflecting changes in the trip status. For context, in early 2016 (before we built Hudi), some of our largest jobs were using more than 1,000 executors and processing over 20 TB of data. This process was not only inefficient, but also harder to scale. Various teams across the company relied on fast, accurate data analytics to deliver high quality user experiences, and to meet these requirements, it became apparent that our current solutions would not scale to facilitate incremental processing for our data lakes. With the snapshot and reload solution to move data to HDFS, these inefficiencies were leaking to all pipelines, including downstream ETLs consuming this raw data. We could see these problems only exacerbate with the growing scale.
With no other viable open source solution to use, we built and launched Hudi for Uber in late 2016 to build a transactional data lake that would facilitate quick, reliable data updates at scale. The first generation of Hudi at Uber exclusively leveraged the copy-on-write table type, which sped up job processing to 20GB every 30 minutes, reducing I/O and write amplification by 100 times. By the end of 2017, all raw data tables at Uber leveraged the Hudi format, running one of the largest transactional data lakes on the planet.
Improving Apache Hudi for Uber–and beyond
As Uber’s data processing and storage demands grew, we began hitting limitations of Hudi’s copy-on-write functionality, primarily the need to continue to improve the surfacing speed and freshness of our data. Even using Hudi’s copy-on-write functionality, some of our tables received updates that were spread across 90 percent of the files, resulting in data rewrites of around 100 TB for any given large-scale table in the data lake. Since copy-on-rewrite rewrites the entire file for even a single modified record, the copy-on-write functionality led to high write amplifications and compromised freshness, causing unnecessary I/O on our HDFS clusters and degrading disks much faster. Moreover, more data table updates meant more file versions and an explosion of our HDFS file count. In turn, these demands incurred HDFS namenode instability and higher compute costs.
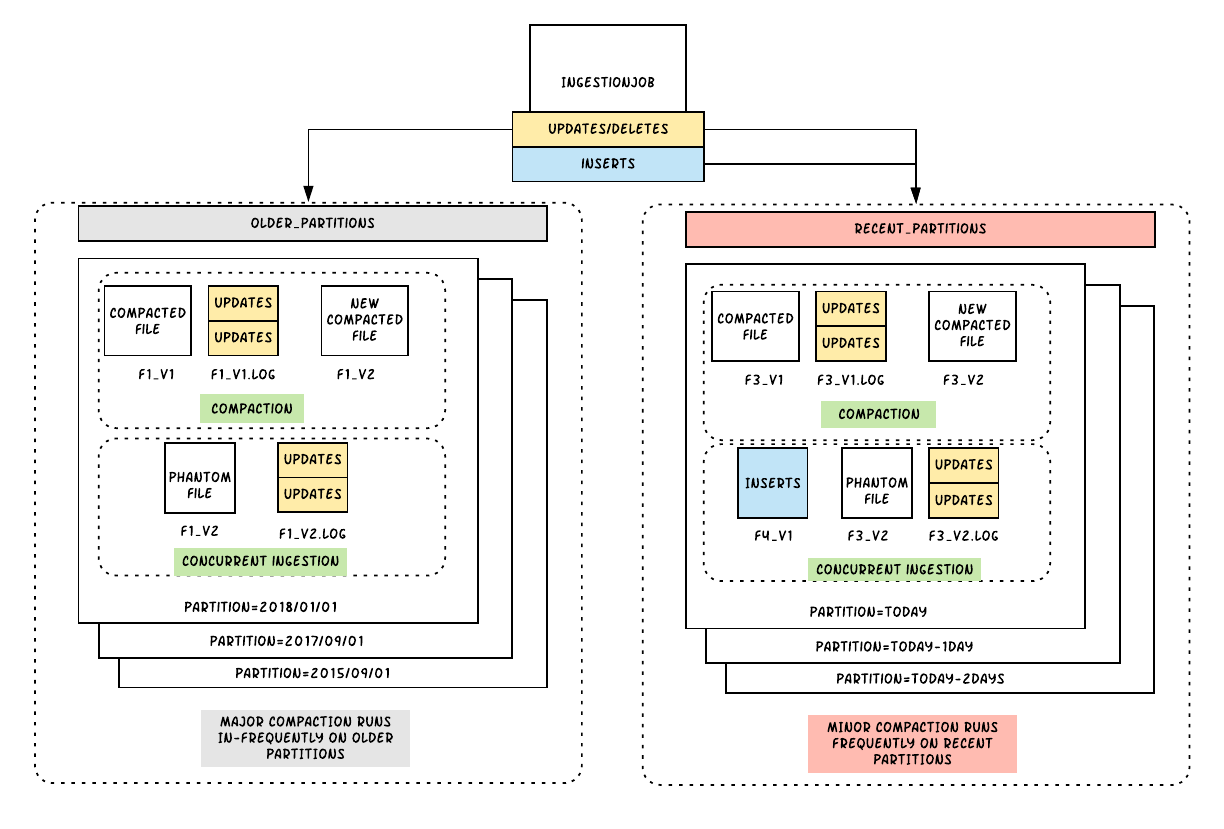
To address these growing concerns, we implemented the second table type, merge-on-read. Since merge-on-read leverages near real-time data by merging data on the fly, we use this feature cautiously to avoid query-side compute costs. Our merge-on-read deployment model consists of three independent jobs, including an ingestion job that brings in new data consisting of inserts, updates, and deletes, a minor compaction job that asynchronously and aggressively compacts updates/deletes in a small number of recent partitions, and a major compaction job that slowly and steadily compacts updates/deletes in a large number of older partitions. Each of these jobs run at different frequencies, with the minor and ingestion jobs running more frequently than the major to ensure that the data in its latest partitions are quickly available in columnar format. With such a deployment model, we are able to provide fresh data in columnar format to thousands of queries and bound our query-side merge cost on the recent partitions. Using merge-on-read, we are able to solve all the three issues noted above and Hudi tables become almost in-susceptible to any amount of incoming updates or deletes to our data lake. Now, at Uber, we leverage both Apache Hudi’s copy-on-write and merge-on-read capabilities depending on the use case.
Thanks to Hudi, Uber ingests more than 500 billion records per day into our 150 PB data lake, spanning over 10,000 tables and thousands of data pipelines, using more than 30,000 virtual cores per day. Hudi tables serve more than 1 million queries per week across our various services.
Reflecting on Apache Hudi
Uber open sourced Hudi in 2017 to give others the benefits of a solution that ingests and manages data storage at scale, bringing stream processing to Big Data. As Hudi graduates to a Top Level Project under the Apache Software Foundation, the Big Data team at Uber reflected back on the various considerations that inspired us to build Hudi in the first place, including:
-
- How can we be more efficient with our data storage and processing?
- How can we ensure that our data lakes contain high quality tables?
- How can we continue to provide data at low latency efficiently at scale as our operations grow?
- How do we unify serving layers for use-cases where latency of the order of a few minutes is acceptable?
Without good standardization and primitives, data lakes can quickly become unusable “data swamps.” Such swamps not only require lots of time and resources to reconcile, clean, and fix tables, but also forces individual service owners to build complex algorithms for tuning, shuffling, and transactions, introducing unnecessary complexities to your tech stack.
As described above, Hudi fixes these gaps by helping users take control of their data lakes via seamless ingestion and management of large analytical data sets over distributed file systems. Building a data lake is a multifaceted problem which needs investment in data standardization, storage techniques, file management practices, choosing the right performance trade-offs between ingesting data versus querying data and more. Talking to other members of the Big Data community as we built Hudi, we learnt that such problems were rampant in many engineering organizations. We hope that open sourcing and working with the Apache community to build upon Hudi over the last several years has given others greater insight into their own Big Data operations for improved applications across industries. Outside of Uber, Apache Hudi is used in production at several companies, including Alibaba Cloud, Udemy, and Tencent to name a few.
The road ahead
Hudi helps users build more robust and fresh data lakes providing high quality insights by enforcing schematization on data sets.
At Uber, having one of the world’s largest transactional data lakes gives us an opportunity to identify unique Apache Hudi use cases. Since solving problems and creating efficiency at this scale can have significant impact, there is direct incentive for us to look deeper. At Uber, we already use advanced Hudi primitives such as incremental pull to help build chained incremental pipelines reducing the compute footprint of jobs which would otherwise perform large scans and writes. We tune our compaction strategies for the merge-on-read tables based on our specific use-cases and requirements. In the recent months since we donated Hudi to the Apache foundation, Uber has contributed features such as embedded timeline service for efficient file system access, remove renames to support cloud friendly deployments and improve incremental pull performance to mention a few.
In the coming months, Uber intends to contribute many new features to the Apache Hudi community. Some of these features help reduce costs by optimizing compute usage along with improving the performance of data applications. We are also taking a deeper look into how we can improve storage management and query performance based on access patterns and data application requirements.
For more information on how we plan to achieve these goals, you can read some of the RFC’s (including, intelligent metadata to support column indexes and O(1) query planning, efficient-bootstrapping of tables into Hudi, record-index for blazing fast upserts) proposed by the Hudi team at Uber to the broader Apache community.
With Apache Hudi graduating to a Top Level Apache project, we are excited to contribute to the project’s ambitious roadmap. Hudi enables Uber and other companies to future proof their data lakes for speed, reliability and transaction capabilities using open source file formats, abstracting away many Big Data challenges and building rich and portable data applications.
Apache Hudi is a growing community with an exciting, ever-evolving development roadmap. If you are interested in contributing to this project, please connect here.

Nishith Agarwal
Nishith Agarwal currently leads the Hudi project at Uber and works largely on data ingestion. His interests lie in large scale distributed systems. Nishith is one of the initial engineers of Uber’s data team and helped scale Uber's data platform to over 100 petabytes while reducing data latency from hours to minutes.
Posted by Nishith Agarwal
Related articles



How LedgerStore Supports Trillions of Indexes at Uber
April 4 / Global
Most popular

Model Excellence Scores: A Framework for Enhancing the Quality of Machine Learning Systems at Scale

Scaling AI/ML Infrastructure at Uber
How LedgerStore Supports Trillions of Indexes at Uber

Migrating a Trillion Entries of Uber’s Ledger Data from DynamoDB to LedgerStore
Products
Company
