Personalized Marketing at Scale: Uber’s Out-of-App Recommendation System
June 13, 2024 / Global
Introduction
Out-of-app (OOA) communication (such as email, push, and SMS) is an important growth lever at Uber. It allows marketers, product owners, and operation teams to connect with users on a plethora of topics, including user promotions, new and favorite restaurants, etc. Building a system to personalize these communications presents unique and exciting challenges. In this blog post, we walk through these challenges and our journey in tackling them.
Challenges
Lack of Recommendation Context
The first challenge is the lack of user context in OOA communications. At the core of these personalized communications are restaurant recommendations and merchant offer recommendations. These recommendations are highly local (i.e., users can only order from nearby restaurants). In standard product recommendation systems, users are shown recommendations as they enter the app. Both the user’s location and intentions are often known. On the other hand, recommendations in OOA communications are pushed proactively to users for nondeterministic future viewing. Ensuring that recommendations stay relevant, even in the absence of critical user context, is a major challenge for our system.
Incorporating Campaign Objectives
The second challenge is that recommendations in OOA communications need to be relevant to both the end users and the context of the communications. An email on membership benefits should include exclusive restaurant’s promotions, while an email celebrating the city’s neighborhoods should highlight locals’ favorite restaurants.
System Costs
Lastly, being able to tackle the above challenges at scale and in a cost-effective manner is another challenge to us. The system is currently responsible for over 4 billion personalized messages to our users across all geographic areas and lines of business. There are three major cost areas for producing OOA recommendations:
- Online Feature Store: This involves expenses related to the storage, retrieval, and management of features used in the recommendation system. The online feature store facilitates the quick access and processing of user, item, and interaction features, which is critical for real-time personalization. The costs here are driven by the need for scalable, high-performance databases that can handle large volumes of data with low latency.
- Online Prediction: Running complex models for real-time predictions incurs significant costs. These models, which are more sophisticated than those in our previous architecture, require substantial computational resources for continuous data processing and analysis. The expenses associated with the computing power necessary to run these models, including server costs, and the maintenance and scaling of additional computational resources for experiment’s purpose.
- High Throughput and Broad Audiences: The expansion to cater to a larger audience and handle higher message throughput further escalates costs. As the system scales to accommodate more users and a wider range of marketing scenarios, the infrastructure must also scale. To process the real-time personalization of more than billions of messages, the necessary throughput can reach 10 times that of in-app recommendation systems.
Managing these costs effectively is crucial for the sustainability of our new architecture, necessitating a balance between performance, scalability, and cost-efficiency. Techniques like optimizing algorithms for better performance, utilizing cost-effective auto-scaling infrastructure, and optimizing feature strategies can significantly aid controlling these expenses.
Architecture Overview
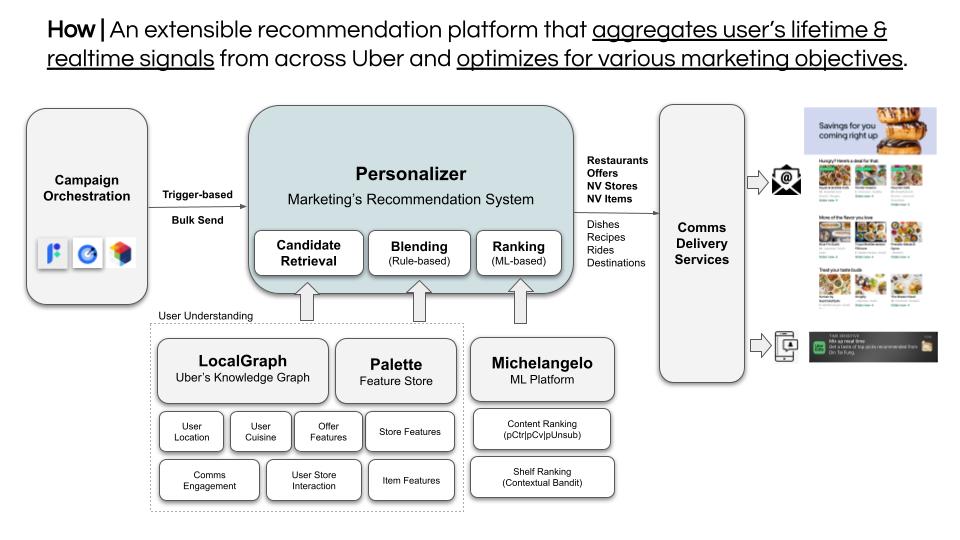
Candidate Retrieval: This process involves identifying a broad set of potential recommendations for each user. Using a first-pass ranking algorithm based on location, the system scans through a vast pool of items, considering various factors like user history, store popularity, and contextual data to retrieve a preliminary list of candidate recommendations.
Core technology: Local Graph (Uber’s Knowledge Graph)
Blending: Once candidates are retrieved, they undergo a filtering and blending process. The step weeds out less relevant or undesirable options based on predefined business rules and criteria. It ensures that the final recommendations align with both the user’s preferences and any business constraints.
Ranking: In the ranking stage, the candidates are ranked to determine their order of presentation to the user. This ranking is based on a full set of ranking features that evaluate the relevance of each item to the user’s context and preferences. The aim is to position the most pertinent and appealing recommendations at the top, maximizing the likelihood of user engagement.
Core technology: Palette Feature Store, Michelangelo
Solution Formulation
To address our three primary challenges, we introduced enhancements to each portion of our architecture to provide relevant and thematically consistent content to users in an efficient and scalable system. We discuss each of these enhancements in detail below.
Candidate List Generation
A unique portion of recommendations on Uber Eats is candidate lists that are highly localized to a user’s location. When users open the Uber Eats app, they are recommended restaurants, grocery, and retail stores that can deliver to either their current location or their most recent order location. For our OOA recommendation system, this crucial context is missing from our candidate list generation. We developed two solutions to overcome this impediment.
For general recommendation use cases, we developed an ML solution to determine which neighborhood a user was most likely to receive an order in next. As our system supports marketing campaigns for frequent, infrequent, and new Uber Eats users, this ML solution required integration of high and low throughput signals from both the Uber Eats and Uber apps over multiple-year time horizons. To ensure the scalability of this solution to the hundreds of millions of Uber users campaign owners communicate with, we focused on reducing these signals to a small set of ~10 features which the ML solution utilized to define a user’s next likely order location. With this likely location, user’s candidate lists are generated by finding all restaurants, grocery, or retail stores that deliver to this location.
While this base solution provides crucial context for our OOA recommendation system, it does not always provide the correct context for every campaign. In campaign settings where the user is likely traveling (e.g., Airport Trips, Uber Reserve, Uber for Business) the aforementioned ML solution will likely not have the necessary context to reflect the user’s recent behavioral changes. In this setting, we utilize an event-based override which updates the user’s candidate list to contain restaurants, grocery, and retail stores that deliver to their most recent neighborhood. By updating this candidate list, we increase the relevancy of communications for users and provide campaign owners the flexibility to control these candidate lists to ensure thematic consistency for their campaigns.
Together, these solutions inject critical user metadata into the user’s candidate list, ensuring our recommendations are relevant to users and reflect their recent behavior. By providing a general ML solution for all Uber users, campaign owners can have confidence that user’s candidate lists are accurate and can accommodate their campaign objectives.
First Pass Ranking
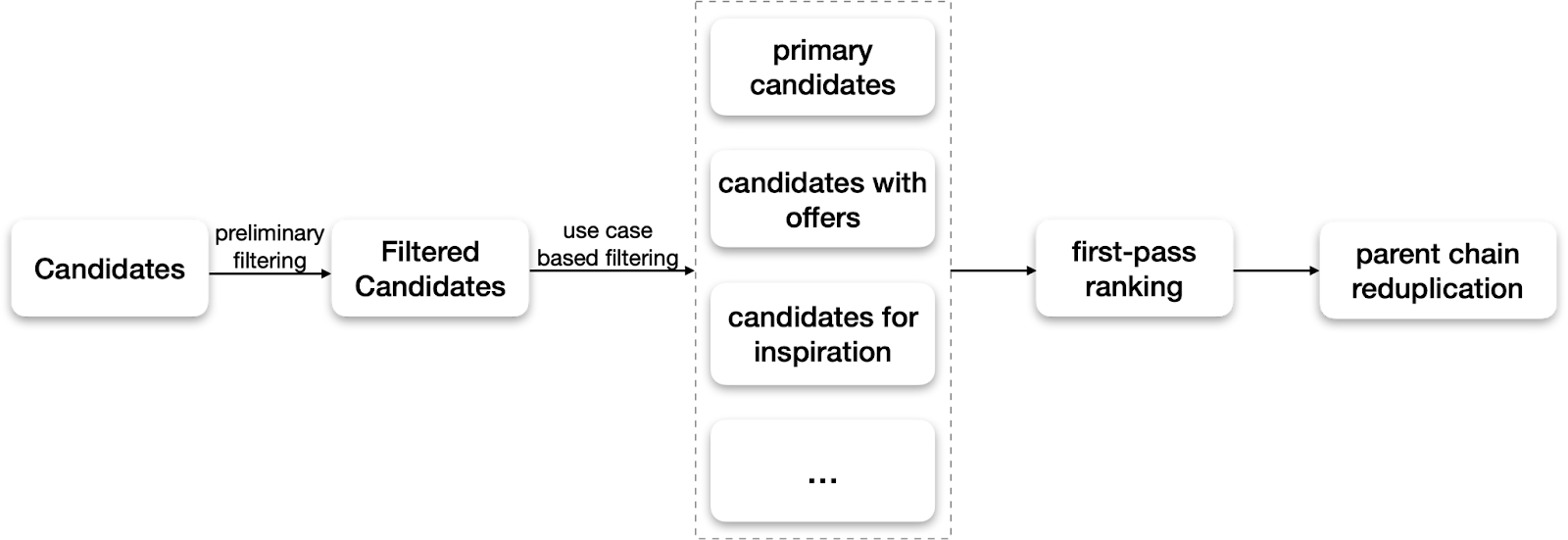
The primary goal of the first-pass ranking is to quickly reduce the set of all eligible candidate merchants to a smaller set of potential merchants for each user. This helps conserve system bandwidth and reduces machine learning-related costs.
After retrieving all the candidates based on the user’s location, we initiate a preliminary filtering process. This phase excludes candidates based on criteria like unavailability and invalid deliverability (such as cross-border merchants).
In certain campaigns, we display a variety of restaurant types. To refine our selection, candidates undergo additional filtering tailored to specific use cases. For example, our primary recommendation strategy is to assess the relevance of candidates based on the user’s past interactions with Uber Eats. We also introduce candidates that are offering promotions, and inspire users by recommending candidates from restaurants they haven’t ordered from but might find appealing.
For each of these use cases, we apply a low-cost scoring function to all eligible candidate merchants. The function is a simple linear combination over a small set of features, including past interactions between the user and merchant. The weights are tuned to maximize the recall metrics.
Finally, to ensure a varied selection for the user, we run a deduplication process. This step removes candidates belonging to the same parent chain, avoiding repetitive recommendations.
Second Pass Ranking
The objective of the second ranking stage is to rank the small set of merchants retrieved from the first-pass ranking to maximize the likelihood of user engagement. To do so, we utilize features that capture a user’s past order history, in-app and out-of-app engagement, and the merchant’s quality, reliability, and affordability. Many of these features are also utilized by the home feed ranking system and are shared via Uber’s Online Feature Store, Palette. By sharing feature sets across recommendation services, we promote parity in the user experience across in-app and out-of-app surfaces. These features are utilized inside a learning-to-rank LTR modeling framework with custom relevancy weights to encourage desirable user behaviors.
While user-centric features are rich for frequent users, they are often not available for new and churned users. As the OOA system caters heavily to the infrequent user segment, we have to rely on long-dated user signals in order to provide good recommendations. Moreover, we need to be able to store and use such signals in a cost-efficient manner. To overcome this challenge with restaurant recommendations, we constructed a lightweight feature set summarizing a user’s cuisine preferences over the entirety of their Uber Eats history. At Uber, we label each restaurant with a set of cuisines that the merchant serves, which we utilize to create a feature vector summarizing the user’s cuisine preferences. We update this feature daily with a Bayesian update logic and upweight recent orders to reflect the user’s recent behavioral changes. Incorporating this feature in our second pass ranking system drove a 4% lift in email’s CTR in recent online experimentation.
Many of the features utilized in our second pass ranking system effectively summarize a user’s past order behavior but do not reveal which restaurants a user may be interested in trying next. Due to the geographic constraints of orders on Uber Eats, it can be difficult for collaborative recommendation system techniques to learn restaurant similarity. For example, two restaurants in different neighborhoods may serve similar dishes at similar prices but have no common customers due to their geographic differences. While learning restaurant similarity is difficult through collaborative based approaches, utilizing content based recommendation approaches with the restaurant’s cuisine labels provides an opportunity to learn restaurant similarities and encourages users to explore new restaurants on Uber Eats. We posit that users will be interested in new restaurants that serve cuisines that are similar to cuisines they have ordered in the past. Building on this premise, we conducted an analysis to quantify the similarity between cuisines. We performed spectral clustering on a regularized cuisine co-occurrence matrix that captured which cuisines were frequently served by the same restaurant. From this clustering exercise we found that while there are hundreds of cuisines a merchant can serve, these cuisines fall into a small number of natural groupings. In Figure 3, we visualize the embedding vectors for each cuisine mapped to a two-dimensional space via t-SNE, which highlights these natural cuisine clusters.
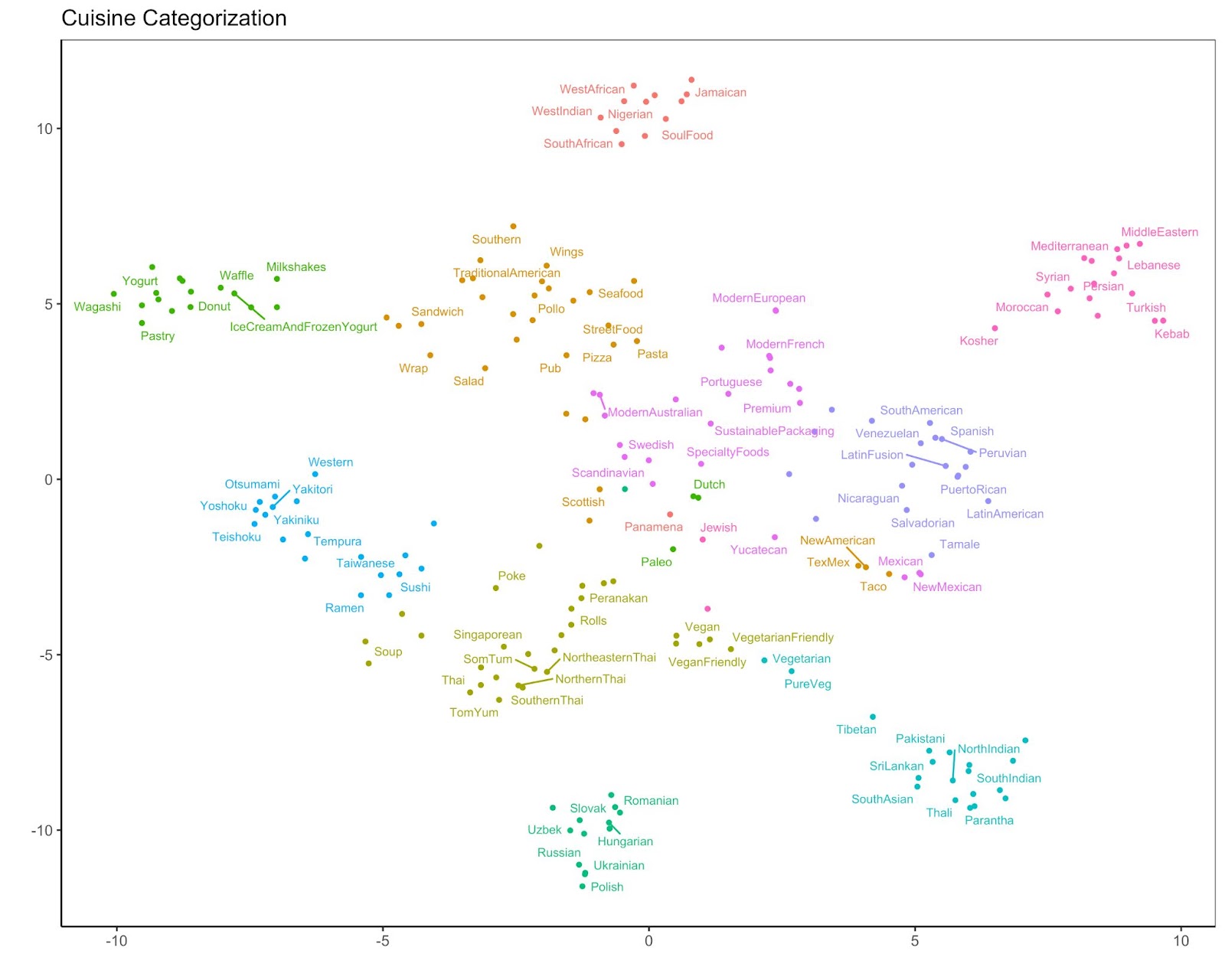
These groupings motivated us to smooth each user’s cuisine preference feature according to these cuisine similarities. Utilizing this smoothed feature vector in our second pass ranking system provided our system an exploration lever, encouraging users to try new cuisines similar to cuisines they enjoy while maintaining recommendation relevancy. In addition to this exploration lever, these groupings also provided us an opportunity to reduce system costs. By embedding the cuisine preference feature according to these cuisine groupings, we reduced the size of this feature 10x, mitigating online storage costs while maintaining the majority of the feature’s signal. Moreover, by utilizing a lightweight embedding scheme, we are able to perform this feature embedding efficiently through simple distributed matrix multiplication, which can be carried out in any standard ETL pipeline framework.
By building a lightweight feature set summarizing a user’s cuisine preferences across their entire Uber Eats history, we provide crucial context to our second pass ranking model. This context provides our recommendation system with an exploration lever, encouraging users to explore new cuisines and merchants, and ensures that infrequent Uber Eats users receive relevant restaurant recommendations. By embedding these cuisine preference features, we can greatly reduce online storage costs and ensure that the recommendation system can support campaigns targeting any cohort of the Uber user base.
Re-Ranking & Blending
As CRM communication comes from different internal stakeholders, the system needs a mechanism to tailor the embedded recommendations toward different brand strategies and marketing priorities. Hence, we introduce a re-ranking and blending layer post the ML-based second-pass ranking. For example, we allow stakeholders to enhance merchants’ visibility (Figure 4) based on specific marketing strategies.
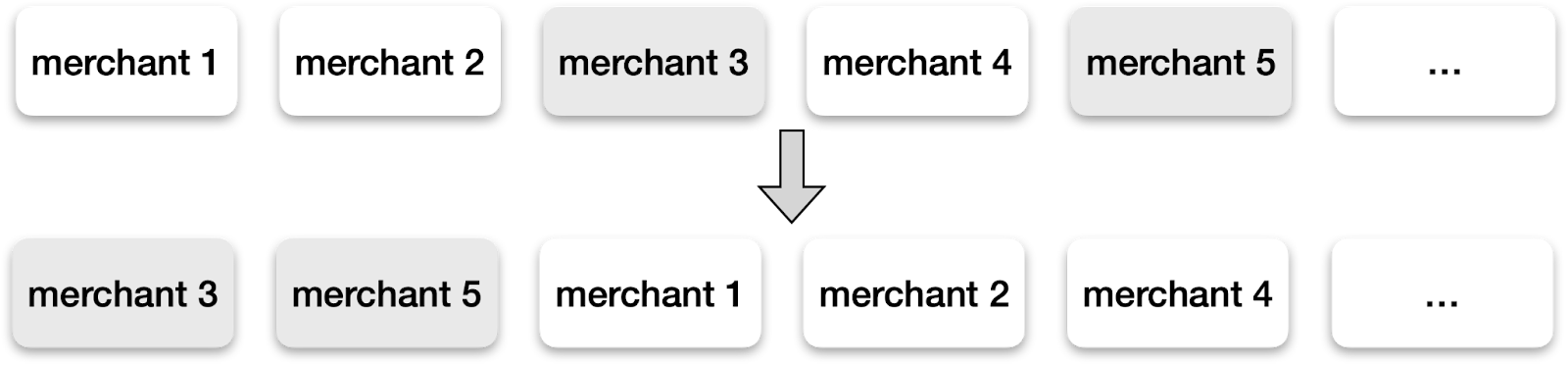
Through our configuration engine, local marketing teams can define their own strategies flexibly and with minimal work. This is enabled by the automated hierarchical configuration merge and override at different geographical region levels. For example, New York City can inherit most of the re-ranking strategies with the US, but the NYC local marketing team can apply some partial overrides on specific parameters. Figure 5 demonstrates the configurations to enhance the selected merchants shown in Figure 4.

Next Steps
While much of the early work focused on surfacing merchant recommendations, the need for personalized marketing at Uber extends beyond our delivery business. The next steps for our platform to bring the same personalization capabilities to the other lines of business, particularly Rider and Earner communications. To better serve these new business surfaces, the team has plans to expand, as well as sourcing from partner teams at Uber, our personalized content repository. The new developments include dynamic creatives to unify the personalized recommendations and other marketing creatives; personalized travel recommendations; and personalized earning opportunities to drive marketplace demand and supply.
Acknowledgements
This would not have been possible without the contribution of multiple Growth and Marketing teams. We’d like to thank the following folks for their contributions: Isabella Huang, Ajit Pawar, Apoorv Sharma, Jennifer Li, Hari Thadakamalla, Cameron Kalegi, Nikhil Anantharaman, Vladimir Schipunov, Denis Perino, Shelley Hatting, April Chu, Nora Murphy, Fernanda Gomes, Abby Blecker, Carolina Aprea, Marie Oquet, Ann Parden, Michael Tam.
Special thanks to our tech partners on the LocalGraph team (Jiaxin Lin, Kaymyar Arbabifard, Santosh Golecha), Delivery Intelligence team (Yifan Ma, Tiejun Wang), Michelangelo team (Jin Sun, Paarth Chothani, Nicholas Marcott, Victoria Wu), and Offers & Affordability team (Shirley Ye, Boyang Li, Jun Yao) for helping us design the system and leverage Uber-wide AI building blocks.

Vincent Pham
Vincent is a Staff Applied Scientist, TLM on the Marketing Personalization team based in New York City. He specializes in scalable recommendation systems and reinforcement learning.

Benjamin Draves
Ben is a Senior Applied Scientist based in New York City focusing on Marketing Personalization and Targeting. He specializes in developing scalable and theoretically principled recommendation and targeting systems.

Hao Fu
Hao Fu is a Staff Software Engineer on the Marketing Personalization team with a focus on developing scalable and reliable recommendation systems. He is passionate about building AI powered applications using big data, backend and machine learning technologies.

Duoduo Yu
Duoduo Yu is a Senior Software Engineer on the Marketing Personalization team, with a strong passion for building large-scale backend systems using Java and Go. His expertise extends to big data technologies, particularly in Spark, and developing efficient pipelines and data warehouses.

Nick Papadakis
Nick Papadakis is a Software Engineer on the Marketing Personalization team, with a focus on building scalable and reliable backend systems. He is passionate about improving compute efficiency and enjoys profiling Go code to identify opportunities for, and validate, performance optimizations.

Ankush Prakash
Ankush is an Applied Scientist at Uber who has been on the Marketing Personalization team for three years. He has worked on the recommendation system on both the Eater and Grocery/Retail side during his time at the company.

Isabella Huang
Isabella Huang is an Engineering Manager on the Growth and Marketing team at Uber, based in Seattle. During her time at Uber, she has evangelized and led multiple AI projects in the Marketing domain. Her recent focus is building AI-powered content generation and optimization platforms that empower Uber to drive business growth ten times faster.
Posted by Vincent Pham, Benjamin Draves, Hao Fu, Duoduo Yu, Nick Papadakis, Ankush Prakash, Isabella Huang
Related articles




Most popular

Advancing Invoice Document Processing at Uber using GenAI

Migrating Uber’s Compute Platform to Kubernetes: A Technical Journey

Fixrleak: Fixing Java Resource Leaks with GenAI
