Building Uber’s Fulfillment Platform for Planet-Scale using Google Cloud Spanner
September 29, 2021 / Global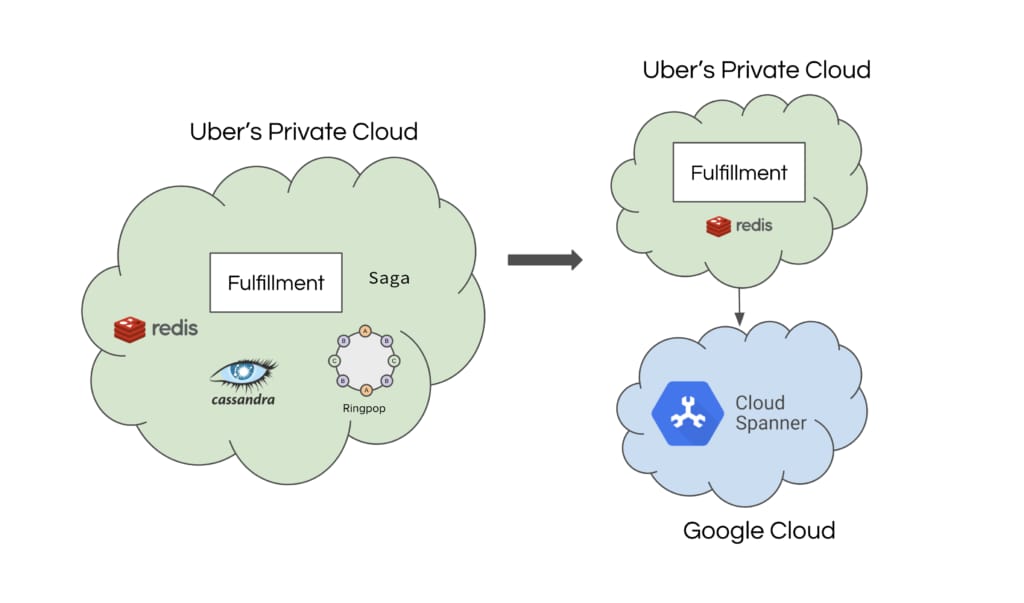
Introduction
The Fulfillment Platform is a foundational Uber domain that enables the rapid scaling of new verticals. The platform handles billions of database transactions each day, ranging from user actions (e.g., a driver starting a trip) and system actions (e.g., creating an offer to match a trip with a driver) to periodic location updates (e.g., recalculating eligible products for a driver when their location changes). The platform handles millions of concurrent users and billions of trips per month across over ten thousand cities and billions of database transactions a day.
In the previous article, we introduced the Fulfillment domain, highlighted challenges in the previous architecture, and outlined the new architecture.
When designing the new architecture, we converged on leveraging Google’s Cloud Spanner, a NewSQL storage engine to satisfy the requirements of transactional consistency, horizontal scalability, and low operational overhead. This article describes how we leveraged Cloud Spanner for planet-scale architecture without sacrificing consistency guarantees and with low operational overhead.
Fulfillment Storage Evolution
Since the inception of Uber, the Fulfillment stack went through fundamental transitions that completely changed how the application and storage layer is designed to support the growing needs of Uber. To introduce Cloud Spanner into Uber’s environment, we had to solve three main challenges:
- How do we design our application workload that assumes NoSQL paradigms to work with a NewSQL-based architecture?
- How do we build resilient and scalable networking architecture so that we can leverage Cloud Spanner, irrespective of where Uber’s operational regions are located (Uber On-Prem, AWS, or GCP)?
- How do we optimize and operationalize a completely new cloud database that can handle Uber’s scale?
Transitioning from NoSQL to a NewSQL Paradigm
In the first article of this series, we described the previous architecture that leveraged a NoSQL based database and all the challenges it posed. They can be summarized into three main categories:
- Leaky abstractions between the database & application layers: In order to achieve high scale from our underlying storage layer, we leveraged Ringpop for application level sharding with an in-memory serial queue. While a unique identifier based sharding scheme is theoretically uniformly distributed, in practice it resulted in hotspots especially with highly active jobs & supplies. The problem exacerbated with the launch of new products that were launched, e.g. Uber Eats that required a single merchant to have multiple jobs, Uber Bus that required a single bus driver having 10+ active jobs, etc.
- Operational Complexity: Handling all the infrastructure concerns at the application layer made the application extremely inefficient, it was able to handle only 20 online drivers/couriers per core. With limited hardware budget caps, scaling an inefficient system starts posing vertical limits. Additionally, the scalability challenges were compounded with the negative effect of gossip coordination on ringpop cluster performance as we added more & more nodes to the cluster. To reduce the impact of ringpop cluster membership changes, we also had long deployment cycles which significantly affected the developer productivity.
- Developer Productivity: The ringpop-based architecture provided an AP guarantee (availability and partition tolerance in CAP Theorem), and traded consistency to achieve high availability. This made it really difficult to debug issues in production and reason about them. Additionally, when working with the Saga pattern to coordinate writes across multiple entities, developers often had to think about compensating actions especially when the writes fail due to system failures. In some cases, the failure of a Saga might also result in an inconsistent state of entities that often required manual intervention.
When thinking about the next chapter for Uber’s Fulfillment Platform, the focus on consistency became one of the primary evaluation criteria, along with high resilience and availability. Based on our requirements and using benchmarks, we evaluated various NewSQL storage engines: CockroachDB, FoundationDB, sharded MySQL, and Cloud Spanner. Cloud Spanner provided all the functional requirements, scaled horizontally with our benchmarks, and provided us with a managed solution for cluster management and maintenance.
Spanner – A Cheat Sheet
Google’s Cloud Spanner is a globally distributed and strongly consistent database that combines the semantics of a relational database with non-relational horizontal scalability. Cloud Spanner supports multi-row, multi-table transactions, with external consistency.
External Consistency
External Consistency provides the strictest concurrency control model, where the system behaves as if all transactions were executed sequentially, even though the system actually runs them across multiple servers (for higher throughput and performance).
Data Modeling
In addition to the strong consistency, Cloud Spanner provides relational semantics by offering:
- Support for one or more tables with structured rows and column semantics with strict typing
- Enforcement of primary key per table, which can be a composition of one or more columns
- Support for scalar or array column data types
- A Data Definition Language for schema updates
- In-built support for secondary indexes
- In-built support for foreign keys to provide referential integrity across multiple tables
Transactions
A transaction in Cloud Spanner is a set of reads and writes that execute atomically at a single logical point in time across columns, rows, and tables in a database.
Read-Write transactions can be multi-column, multi-row, and multi-table with external consistency. These transactions rely on pessimistic locking or 2-phase commits, if necessary. These transactions appear as if they were executed in serial order, thereby guaranteeing serializability, even though some of the distinct transactions can execute in parallel.
Read-Only transactions provide external consistency across several reads but do not allow writes. These transactions do not acquire locks and allow reading data based on timestamps in the past.
Failure Tolerance and Replication
Cloud Spanner offers 2 topology modes with preconfigured configurations across existing GCP Cloud Regions:
- Single-Region: Data is automatically replicated between multiple zones within a single region.
- Multi-Region: Data is automatically replicated across multiple regions. The additional replicas can be leveraged to serve low-latency reads while offering higher availability guarantees and protection against regional failures.
While Cloud Spanner’s underlying distributed file system provides redundancy by default, it also provides data replication for the additional benefits of data availability and geographic locality. It leverages a Paxos-based replication scheme in which voting replicas across multiple geographic regions vote on every commit issued to Cloud Spanner.
Application Architecture
The new fulfillment architecture builds upon a layered architecture, keeping the benefits of a multi-tier approach. From the storage perspective, the primary component that interfaces with Cloud Spanner is the ORM layer.

To effectively leverage Cloud Spanner in our application infrastructure, we built various components, described below, to optimize for our use case or because some functionalities were missing out of the box.
Spanner Client
When we started building the application infrastructure, the out-of-the-box Spanner client didn’t provide asynchronous IO support that would seamlessly integrate with our programming model. Further, the support for DMLs hadn’t fully matured. As a result, we built a custom implementation of the Spanner client leveraging Google’s GAPIC generator and Gax library.
Some of the features we built are:
- Session Management: A Session is the underlying communication channel to the Spanner database and the client maintains a session’s lifecycle and a pool of sessions to optimize transaction execution, based on the best practices defined by Google.
- Observability: We leveraged gRPC ClientInterceptors for RPC-level observability, tracking per-entity or per-request payload size. The improved observability allowed us to track finer-level SLA and tune the parameters like retries and timeouts for each RPC separately to improve resilience.
- Transaction Categorization: Until recently, Cloud Spanner didn’t have an API for customers to specify which transactions should have a higher priority. To build this functionality, we categorized each transaction into foreground which are customer facing vs background which are system-initiated. We prioritize foreground transactions over background transactions by tuning the timeouts and retries.
- Transaction Coalescing: A typical transaction can have multiple operations on Spanner—usually, a read followed by write for each entity touched in the transaction. Since Spanner provides a read-your-writes guarantee within a transaction, they all have to be serialized. As Uber’s requests are generated from its on-prem data centers, each Spanner operation within a transaction can add to the network latency. To optimize this, we built a transaction coalescer to batch multiple operations intelligently within a transaction in a single RPC.
Physical Modelling
Our database’s schema modeling was dependent on 2 primary principles: ease of extensibility and data schema safety. We followed these tenets to get the maximum performance and provide an extensible schema modeling that reduces the number of schema updates developers have to make:
- For CRUD-like Operations: it’s important to have evenly distributed keys to avoid overloading a certain key range causing hotspots in the system.
- For Scan Operations: The scans should not result in a full table scan and instead use an index to reduce the impact of each scan query on Cloud Spanner CPU utilization. The scans should also not go over the same rows or deleted rows repeatedly. This can happen because of tombstones caused by deletes in the table.
Based on the above access patterns, we designed our schema with 2 sets of tables:
- Entity Tables: Each entity in the application layer has a corresponding entity table modeled as key-value storage, where each row represents a unique entity and the value is the byte representation of the current statechart representation.
- Relationship Table: For modeling relationships between entities, we explicitly defined a relationship table that stores relationships between entities. The advantage here is that entities and their relationships can be updated independently and relationships can be enforced at the application layer based on the product feature requirements.
One benefit of the above modeling choices is that adding new entities or relationships between existing entities doesn’t require any DDL updates. We also leveraged protobuf for managing entity definitions. Given the type safety provided by protobuf, we could relax the type safety in the storage layer, reducing the need for any DDL changes when adding new attributes to an existing entity.
In addition to the above:
- Creation and Updation Timestamp: Each table in the database has an explicit creation and last updated timestamp that leverages Spanner’s commit timestamp for auditing.
- Expirations: When we started building on top of Cloud Spanner, there was no TTL support. So, we built the functionality to clean up the rows post expiration. To implement this, we tracked expiration timestamps associated with each of the rows on a secondary index. When indexing timestamps, it can lead to hot spots, so we prefixed the index with randomly generated shard IDs. We set up periodic scan and delete operations to run in the background and garbage collect expired entities and their associated relationships.
A sample entity in the database looks like this:

Query Modeling
Given the complexities of our business needs and application semantics, referential integrity cannot be purely guaranteed by the database schema definitions, and with ever-evolving relational semantics, it gets complicated to do so by forcing it down to the schema definition. To achieve flexibility and still maintain referential integrity at the application level, we leverage a centralized relationship schema table that maintains relationships between any 2 entities at the snapshot of time. This leads to obvious performance degradation at the query time, especially when the query involves multiple entity reads.
We tuned the performance of read queries by building a query planner that:
- Builds the hierarchy of the entities by leveraging the centralized relationship table and then performs a left join with individual entities. This requires a custom query generator that understands the number of entities being queried to generate SQL for each runtime query.
- Leveraging Cloud Spanner’s with clause to build temporary tables for subqueries.
- Leveraging the APPLY_JOIN method that optimizes the query to provide inputs to the subqueries.
These optimizations achieve a low compute footprint on the server-side, reduce the number of joins required, and eventually reduce repeated payloads in the query to reduce the network bandwidth utilization.
Post-Commit Events
In the absence of a change data capture solution from Cloud Spanner, we built a system to execute tasks asynchronously once the transaction is committed. This system is primarily leveraged for the at-least-once guarantee, delayed, and recurring tasks. We call this system LATE (Late Async Task Execution), and it consumes async tasks scheduled in Cloud Spanner and executes them per the scheduling policy. LATE consists of these components:
- Data Model: The data model is optimized to reduce the scan compute footprint as much as possible. Following the best practices for building an efficient scanner, we defined the data model as:

Fundamentally, the schema is a combination of TaskId and the rest of the fields. But to consume tasks efficiently in a scan, we also need the CreatedAt timestamp, which is the Truetime timestamp populated by Spanner on a successful transaction commit. Since CreatedAt is a monotonically increasing value, it causes hot spots if it’s the first column in the primary key. To alleviate this, the timestamps are prefixed with a ShardId in the primary key.
- Tailer: This component polls the Task table to consume new tasks. A single tailer works on a single shard to avoid a full table scan. Within a shard, it scans for new tasks by scanning from the last seen CreatedAt, which is stored in application memory. Leveraging the monotonically increasing commit timestamp capability, we avoid scanning already-consumed rows.
- Sharding: Each tailer works on a single shard. To distribute trailers across N tailer workers, we use a combination of Rendezvous-Hashing and a master peer list of tailer workers to distribute work uniformly.
- Scheduler: All tasks are scheduled in memory and dispatched based on the task configuration. A task can be dispatched immediately, after a certain delay, or periodically. To avoid issues with local clock drifts, the scheduler only uses Spanner timestamps and a relative delay to identify the exact timestamp for the task to be scheduled.
- Dispatching: The dispatcher ensures that the task is dispatched appropriately with the corresponding service and respects the configured retries and timeouts. We built multiple operational knobs to avoid thundering herd and prevent cascading failures.

Moving to a Hybrid Cloud Environment
Uber leverages a hybrid of on-premise and cloud providers to enable seamless infrastructure growth and support diverse use cases. In this section, we describe the Networking architecture that enabled seamless integration between the Fulfillment application layer and Cloud Spanner.
Hybrid Network Architecture
Fulfillment’s use case to leverage Cloud Spanner is categorized as High-Availability, Optimal-Latency, and High-Bandwidth. To achieve maximum availability, Fulfillment leverages Cloud Spanner using a multi-region configuration designed for 99.999% availability. As described above, a multi-region configuration is optimized for low-latency, high-throughput stale reads, and incurs extra latency cost for writes to provide high-availability guarantees.
To support multiple cloud vendors including Fulfillment’s Spanner use case, Uber’s Cloud network architecture has 2 major components:
- Physical Layer consisting of the interconnections between Uber and the Cloud vendors.
- Logical Layer that includes the virtual connections created on top of the physical layer to achieve redundancy.
To provide optimal reliability at the physical layer, we provide 2 layers of N+1 physical redundancy with:
- In each of Uber’s Network Point-of-Presence (PoP), Uber-Cloud interconnects are set up with the same capacity from 2 Uber peering routers, backing each other up
- 2 Uber Network PoPs serve Uber-Cloud interconnections with the same capacity built-in to each PoP, providing N+1 redundancy
By leveraging GCP’s guidelines to achieve 99.99% availability with a dedicated interconnect and capacity mapped flexible VLAN attachment modeling, the logical layer also aligns to meet N+1 logical redundancy and 99.99% reliability requirements. For example, if Uber-GCP network capacity requirements are 200Gbps per PoP, it translates to 8x 50G VLAN attachments per PoP i.e. 4x 50G VLAN attachments per router in a single PoP.

The primary guiding principles of Uber’s managed network backbone routing policy are:
- A cloud vendor controls optimal routes to Cloud-managed resources via Cloud network
- Uber controls optimal routes to all Uber-managed resources via the Uber-managed network.
As such, our general Uber-GCP routing setup is:
- In the GCP-to-Uber direction, preserve GCP’s BGP MED value(s) for the GCP region(s)
- In the Uber-to-GCP direction, announce Uber’s internal metric setting as BGP MED values to GCP
Private Google Access
To increase reliability, remove throughput bottlenecks, and leverage existing dedicated interconnect architecture, we use Private Google Access to enable on-prem services for communicating with Google’s API and Services from Uber’s on-prem infrastructure. Network traffic to different Google APIs and services are routed through the private.googleapis.com and restricted.googleapis.com domains. The Cloud routers in the VPC network advertise the routes for both GCP private access endpoints towards Uber PoP routers.
Benchmarking
In Cloud Spanner’s multi-region configuration, the primary way to reduce latency overhead for writes is to ensure that the traffic is always routed from Uber’s on-prem regions to Cloud Spanner’s Leader Read-Write region, which may not be the closest to all of Uber’s on-prem regions under all connectivity paths. Hence, application latency during the failed-over state can be very different from a stable operation state.

To ensure application performance doesn’t suffer during a failed over state, we benchmarked normal operations and failover scenarios of Uber-GCP connectivity to guarantee no impact to the production latency requirements.
Optimizing and Operating Spanner at Uber scale
Cost Modeling and Tracking
Given that Cloud Spanner is a hosted solution in GCP, we had to understand our cloud footprint and continuously optimize inefficiency across the architecture. To achieve this, we analyzed our existing workload and speculated the cost variables:
- Node Cost: Roughly contributes to 80% of the entire cost. Multi-region configurations are 3-4x costlier than single-region clusters and require a deep understanding of availability guarantees to choose between either.
- Networking Cost: The remaining 20% cost that primarily stems from the ingress and egress of data from GCP regions. Since our applications run on-prem, each read/write access incurs the cost of transferring data.
- Storage Cost: In addition to per-hour node costs, there is a storage cost that is trivial for our workload, given that most data is transient and scoped within the lifecycle of a single trip. Once the trip is completed and snapshotted in on-prem, long-term storage, the data is deleted from Cloud Spanner.
- Interconnect Cost: The minuscule cost of sending and receiving data over the interconnect between Uber and GCP networks.
To monitor the cost impact of any new feature rollout or product launch, we defined metrics that help us benchmark the performance of our Cloud Spanner cluster and ensure that we aren’t adding degradations. Some of these metrics are:
- Queries per second per utilized core (compared with max feasible utilization)
- Concurrent users per utilized core (compared with max feasible utilization)
- Read to write ratio (total number of reads issued in the system compared to the writes)
- CPU utilization by leader and replica regions
Production Monitoring
End-to-End Observability
To correlate client-side and server-side metrics in one place, we built a micro-service to import Cloud Spanner and Network metrics from Google Cloud’s Operation Suite to Uber’s M3 stack. Having end-to-end observability early on allowed us to track SLA between the Client, Network, and Cloud Spanner, and detect anomalies at various layers.
Transaction Analyzer
We modeled our operations to leverage DML to push transaction state management to Cloud Spanner and get rich in-transaction management at scale for reads and writes. However, this meant that we had transaction conflicts which manifested mostly with ABORTED or DEADLINE_EXCEEDED errors. To get deeper insights into these conflicts to help remove or reduce them, we built an automated way of analyzing conflicting transactions through a Transaction Analyzer tool.

gRPC Optimization
Due to the scale and size of our Cloud Spanner deployment along with traffic volume and criticality, any small network failure can result in increased error rates for Cloud Spanner Read-Write transactions. Because individual operations cannot be retried within the scope of a single Read-Write operation and require entire transactions to be retried, we needed to provide high reliability at the network protocol layer.
Some of the improvements at the gRPC protocol layer are:
TCP RST: Any Spanner client’s request over the network can be affected when the underlying TCP connection receives a TCP RESET due to intermittent failures. In this case, the Spanner session needs to be re-established for the requests to be forwarded.
- By optimizing gRPC’s channel pool, when a channel is affected by TCP resets, the requests are automatically forwarded temporarily to a backup healthy gRPC channel. This allows for the requests to be forwarded instantly without having to wait for a new Spanner session.
- In a contained environment, we see an improvement from 1.7x-7x with an average of 2.5x decreased errors.

Packet Loss: Another common cause of sub-optimal availability guarantees is intermittent packet loss in the network. Intermittent packet loss results in the gRPC channels becoming unresponsive and the Spanner sessions getting stuck, causing ongoing transactions to fail.
- Recovering from these conditions can sometimes be in the order of minutes, further degrading the application performance. With frequent health checks, we can detect broken TCP connections after 5 seconds and initiate a graceful reconnect on broken gRPC channels.
- With the improvements, we decreased the number of errors and their duration by 4x.

Cost Optimizations
AutoScaler
As Uber’s traffic pattern is variable by the time of day and week, being provisioned for max capacity at all times wastes resources. To take advantage of Cloud Spanner’s elasticity, we built an autoscaler that constantly tunes the number of nodes based on a CPU utilization target.

Replica Utilization
In the case of a multi-region configuration, a read can be issued to the leader or a replica. If a strong read is issued to a replica, it incurs the extra cost in latency until the replica has the latest snapshot to serve the strong read. To reduce the impact on latency, by leveraging Google’s Private Service Connect we route our strong reads to the leader region, and all stale reads are routed to the replica-only region, maximizing the utilization of nodes across the leader-region and replica-only region.
On-Prem Cache
Given a read-heavy workload, we built an on-prem cache to improve latency and cost. To maintain the same consistency as Spanner, the cache had to give the same snapshot isolation based on Spanner’s Truetime. We built a query-caching functionality to serve stale reads from the cache that’s hydrated by strong reads and writes.

Closing
We’ve solved deep technical issues in our network routing infrastructure, productionized our application workload against Cloud Spanner infrastructure, and continuously optimized the architecture to improve the latency, availability, and database performance. This lays the foundation for our next chapter, where we’re working on scaling our storage and networking infrastructure by 10x and building and modeling complex business features on top. We are truly on day one of this journey and hope you’ll join us.

Ankit Srivastava
Ankit Srivastava is a Principal Engineer at Uber. He has led and contributed to building software that scales to millions of users of Uber across the world. During the past 2 years, he led the ground-up redesign of Uber's Fulfillment Platform that powers the logistics of physical fulfillment for all Uber verticals. His interests include building distributed systems and extensible frameworks and formulating testing strategies for complex business workflows.

Fabin Jose
Fabin Jose is a Senior Network Engineer II on the Global Network Infrastructure team at Uber. He has led and contributed to Datacenter Network Design, Datacenter builds and Network Software Automation efforts. His current focus areas include Cloud Networking and Network reliability improvement initiatives at Uber.

Jean He
Jean He is a Senior Staff Network Engineer at Uber. She has led, drove, and contributed to the technology roadmap, architecture, and design of Uber’s data center, backbone, and cloud network infrastructure to provide cost-effective, reliable, and optimal production network foundation to serve Uber business across the world. In the last two years, she has led the hybrid network architecture serving the rewrite of the Fulfillment architecture.

Nandakumar Gopalakrishnan
Nandakumar Gopalakrishnan is a Senior Software Engineer II at Uber. He is currently leading multiple projects in the Fulfillment Framework and Persistence; building some of the foundational components that are responsible for fulfilling an Uber trip at scale. Over the past two years, he has driven and contributed to building Uber's fulfillment platform on top of Spanner using Uber’s network topology.

Ramachandran Iyer
Ramachandran Iyer is an Engineering Manager at Uber. He is a technical architect with experience in designing and delivering large-scale, mission-critical platforms and distributed systems. He has led the development of Spanner Client and Fulfillment integration, re-architecting real-time search and indexing platforms and is currently working on the storage infrastructure at Uber. His interests include distributed systems, databases, storage, and search platforms.

Uday Kiran Medisetty
Uday Kiran Medisetty is a Principal Engineer at Uber. He has led, bootstrapped, and scaled major real-time platform initiatives in his tenure at Uber. He worked on revamping the overall Mobile API architecture from a monolithic polling-based flow to a bidirectional streaming-based flow. In the last 2 years, he led the re-write of the Fulfillment architecture that powers mission-critical business flows for all Uber verticals applications in the company. In the last couple of years, he led the re-architecture of Uber’s core fulfillment platform.
Posted by Ankit Srivastava, Fabin Jose, Jean He, Nandakumar Gopalakrishnan, bowie@uber.com, Ramachandran Iyer, Uday Kiran Medisetty
Related articles





Most popular

Uber’s Journey to Ray on Kubernetes: Resource Management

Advancing Invoice Document Processing at Uber using GenAI

Migrating Uber’s Compute Platform to Kubernetes: A Technical Journey
