Enabling Seamless Kafka Async Queuing with Consumer Proxy
Senior Software Engineer
Uber has one of the largest deployments of Apache Kafka in the world, processing trillions of messages and multiple petabytes of data per day. As Figure 1 shows, today we position Apache Kafka as a cornerstone of our technology stack. It empowers a large number of different workflows, including pub-sub message buses for passing event data from the rider and driver apps, streaming analytics (e.g., Apache Flink, Apache Samza), streaming database changelogs to the downstream subscribers, and ingesting all sorts of data into Uber’s Apache Hadoop data lake.

More than 300 microservices at Uber are leveraging Kafka for pub-sub message queueing between microservices. In the following article we will go in depth on this particular use case, and discuss both how we arrived at the Consumer Proxy, and what it has enabled.
Streaming vs. Messaging
Apache Kafka is a stream-oriented system: message ordering is assumed in the design of the system and is a fundamental semantic property provided by the system to consumers (i.e., consumers see messages in the same order that they are received by the streaming system). To ensure that any happens-before relationship encoded in the ordering is respected:
- Messages of the same topic partition are consumed exclusively by only one consumer of the same group (shown in Figure 2).
- The Kafka consumer recommends the following pattern:
a. Reads a single message from a partition
b. Processes that message
c. Does not process the next message from that partition until the previous one has been processed and committed. (Note: Most message queueing use cases at Uber do not enable autocommit, because at-least-once message processing is semantically required.)

Message queueing focuses on unordered, point-to-point, asynchronous messaging where there is no significance to the ordering between any given pair of messages. Messages can be consumed by any consumer of the same group (shown in Figure 3).

Problem Statement
After scaling Kafka as a pub-sub message queuing system for 5 years from 1 million msgs/sec to 12 million msgs/sec, we encountered several growing pains specific to message queueing on Kafka: Partition Scalability and Head-of-Line Blocking.
To explain them, let’s imagine a hypothetical async task queue (Note: this example is hypothetical and may not reflect the actual billing system’s architecture) that handles billing after an Uber ride:
- There exists a Kafka topic for trip completion events
- When a trip is completed, a trip completion event is produced to the Kafka topic
- A billing service subscribes to the Kafka topic and charges the third-party payment providers, e.g., Visa and Mastercard
- Suppose that there are two messages (trip_1 and trip_2) in the same topic-partition
- trip_1 should be charged to Visa and trip_2 to Mastercard
Partition Scalability
We run a small number of mix-usage Kafka clusters at Uber, and an individual Kafka cluster might have more than one hundred brokers. Consider the above hypothetical Uber ride use case, and assume that an RPC from the billing service to a payment provider takes on average 1 second. With the recommended native Kafka consumer coding pattern, in order to achieve reasonable consumer processing throughput (e.g., 1000 events/s), we would need a 1000-partition Kafka topic (each partition delivers 1 event/s).
- Since a Kafka cluster can sustain about 200k topic partitions, this bounds the number of topics on the Kafka cluster to about 200.
- Moreover, a single Kafka topic partition, depending on hardware configuration, should be able to sustain 10MB/s throughput. Assuming 1KB average message size, a single Kafka partition should be able to sustain 10K messages/s, but our use case only uses it at 1 message/s.
By underutilizing Kafka cluster resources, we reduce the efficiency of system resources.
Head-of-Line Blocking
For pub-sub message queueing use cases, the recommended Apache Kafka consumer coding pattern does not handle the following two scenarios well:
- Non-uniform processing latency
- Poison pill messages
Let’s examine these 2 scenarios with our hypothetical Uber ride use case.
Non-uniform processing latency: Suppose that Visa processing latency is elevated. When the billing service is processing trip_1, it will delay the processing for trip_2, even though there is no spike in Mastercard processing latency.

Poison pill messages: A poison pill message is a message that cannot be processed or takes a long time (e.g., 10 minutes) to process due to non-transient errors. Suppose that trip_1 is a poison pill message. Then the billing service will be stuck in handling trip_1 and cannot process trip_2, even though trip_2 is unaffected by the issue.

Apache Kafka Solutions
With the Apache Kafka consumer, there are two ways to address the above two challenges, but each of them has its own problems:
- Autocommit: fetched messages can be auto-committed to Kafka before it is successfully processed by Kafka consumers. However, this would cause potential data loss. For example, if a consumer is restarted, it will resume from largest committed offsets; those auto-committed but unprocessed messages, which previously sit in the consumer’s memory, will not be re-fetched or reprocessed. For many business-critical message queueing applications, such as billing, data loss is not tenable.
- Reduce message processing latencies: Particularly when the callee is another internal service, it is reasonable to ask why the RPC latencies are as high as 1 second. However, in practice, 100ms response latencies are not unreasonable when calling an external service. With 100ms request latencies, a single partition can still only handle 10 messages/s, which is very low.
Introducing Consumer Proxy
We developed Consumer Proxy, a novel push proxy to solve the above-mentioned challenges. At a high level, the Consumer Proxy cluster:
- Fetches messages from Kafka using Kafka binary protocol
- Sends/pushes each message separately to a consumer service instance that exposes a gRPC® service endpoint
- The consumer service processes each message separately, and sends the result back to the Consumer Proxy cluster
- Receives gRPC status code from the consumer service
- Aggregates the consumer service’s message processing results
- Commits proper offsets to Kafka when it’s safe to do so

The Consumer Proxy addresses the impedance mismatch of Kafka partitions for message queueing use cases by presenting consumers with a simple-to-use gRPC protocol. At the same time, Consumer Proxy prevents consumer misconfigurations and improper consumer group management by hiding them from consumer services.
Proxy vs. Client Library
The most obvious solution to address the challenges of Kafka as a pub-sub message queueing system is to implement the features we need by way of a client-side SDK. Indeed, we explored this option earlier by building a wrapper on top of the open-source Go and Java Kafka client libraries. However, we discovered that there are challenges with the client library, which can be solved by a proxy-based approach:
- Multiple programming languages support: Uber is a polyglot engineering organization with Go, Java, Python, and NodeJS services. Building and maintaining complex Kafka client libraries for services written in different programming languages results in non-trivial maintenance overhead, while Consumer Proxy only needs to be implemented in only one programming language and can be applied to all services.
- Upgrading client libraries: Uber runs over 1000 microservices. Managing Kafka client versions and upgrades at Uber is a large challenge, which requires wide cooperation across teams and usually takes months to complete. The Consumer Proxy is fully controlled by the Kafka team, as long as the message pushing protocol keeps unchanged, the Kafka team can upgrade the proxy at any time without affecting other services.
- Consumer group rebalance: Rolling restart is a common practice to avoid service downtime. Prior to KIP-429, rolling restart may result in a “consumer group rebalance storm” as members leave and join the consumer group continuously during the duration of the rolling restart. This is exasperated for services that run hundreds of instances. In Consumer Proxy, by decoupling message consuming nodes, which are a small number of Consumer Proxy instances, from the message processing service, which may consist of tens to hundreds of instances, we can limit the blasting radius of rebalance storms; moreover, by implementing our own group rebalance logic (instead of relying on Kafka’s built-in group rebalance logic), we can further eliminate the effects of rebalance storms.
- Load across service instances: For a Kafka consumer group reading a 4-partition Kafka topic, the message consuming logic can be distributed to at most 4 instances. When this message consuming logic is integrated directly into a service that runs more than 4 instances, it results in hotspots in the service where 4 instances are doing more work. As a contrast, with Consumer Proxy, we can consume messages using 4 nodes and distribute them (almost evenly) to all service instances.
Detailed Design
The following sections dive deeper into how we overcame the limitations imposed by partitions for non-ordered message consumption, and achieved:
- Partition parallel processing to address the partition scalability problem
- Out-of-order commit to guarantee at-least-once message delivery and address the non-uniform processing latency problem
- Dead Letter Queue (DLQ) to address the poison pill message problem
Parallel Processing within Partitions
With the high-level architecture described above, parallel processing of messages within a single partition can be achieved by simply consuming a batch of messages in the Consumer Proxy cluster, and then sending them parallelly to multiple instances of the Consumer Service. As shown in Figure 7, although a single Kafka topic partition is still consumed by a single Consumer Proxy node, this single node can send messages to any number of consumer service instances. Therefore, the number of consumer service instances is not limited by the number of Kafka topic partitions anymore.

Out-of-Order Commit
The naive implementation of parallel processing a batch of messages addresses the partition scalability problem, but it does not address the non-uniform processing latency problem. If the first message in a batch has not been committed to Kafka, Consumer Proxy cannot fetch the next batch, which blocks the consumer from making progress.
To address this problem, we introduced out-of-order commit from consumer services to Consumer Proxy. In other words, consumer services can commit a single message to Consumer Proxy. Unlike Kafka, where a commit indicates that all messages with lower offsets are also committed, a Consumer Proxy commit only marks that single message as committed. In order to clearly distinguish these concepts, we call Consumer Proxy single message commit as “acknowledge” and Kafka commit as “commit”. Consumer Proxy tracks which offsets have been acknowledged, and only commits to Kafka when all previous messages have been acknowledged, but not yet committed (see Figure 8).
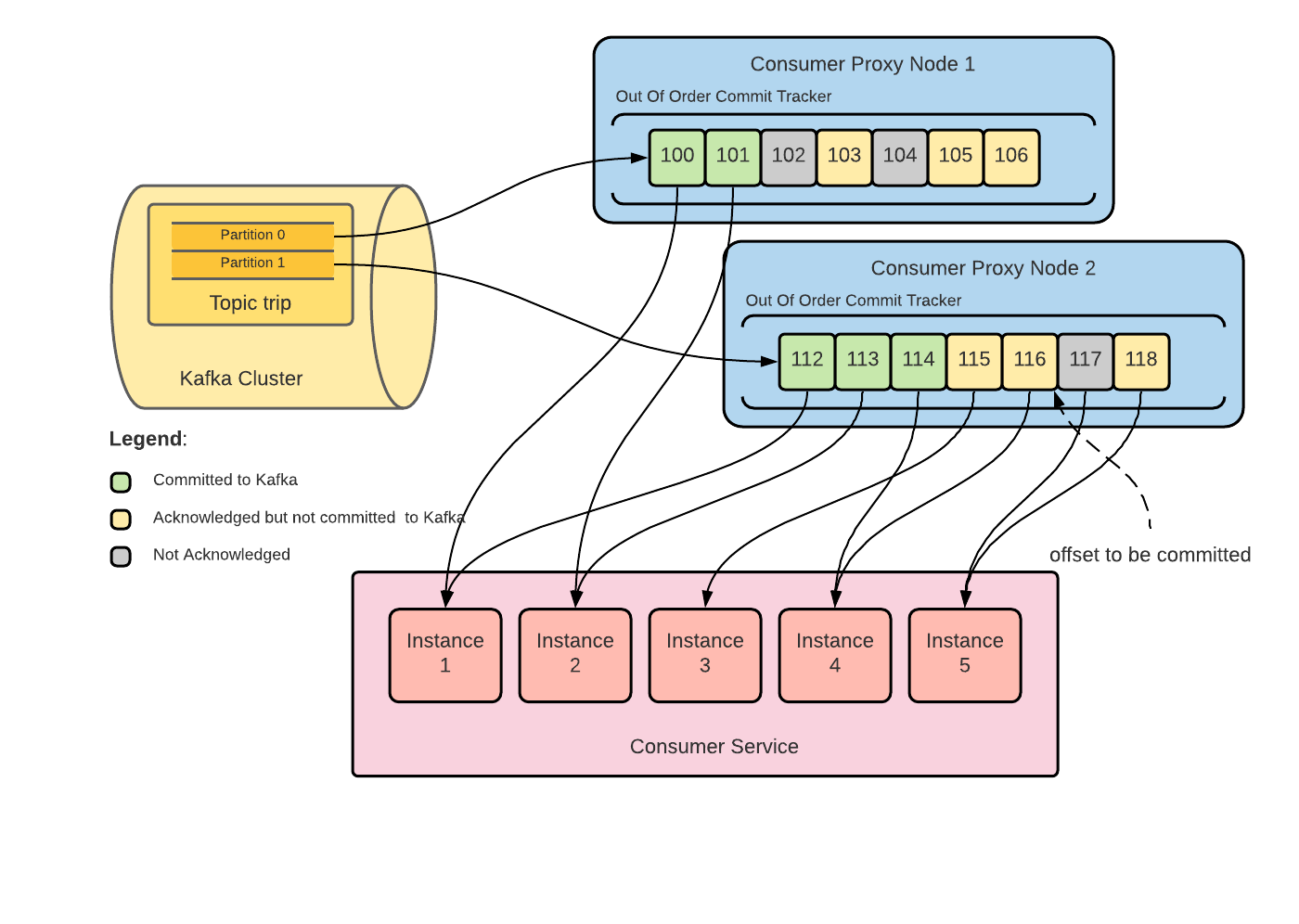
With out-of-order commit, Consumer Proxy fetches several batches of messages, inserts them into the out-of-order commit tracker, and sends them parallelly to consumer services. Starting from the last committed message, once a contiguous range of messages are acknowledged, Consumer Proxy commits them to Kafka and fetches another batch of messages. Therefore, Consumer Proxy makes progress, even when previously fetched messages have not been fully committed to Kafka.
This solution mitigates the transient head-of-line blocking issue; however, it still has some limitations:
- There may be message duplication on Kafka consumer group rebalance, when Consumer Proxy needs to fetch acknowledged but not committed messages again.
- Poison pill messages can never be acknowledged to the out-of-order commit tracker, which leads to the result that messages fetched after them can never be committed to Kafka. When a message commit is blocked, Consumer Proxy will not be able to fetch and dispatch more messages.
In practice, message duplication is not a problem at Uber, since consumer services usually have built-in deduplication mechanisms, regardless of whether Kafka messages are duplicated or not.
Dead Letter Queue
In many cases, consumer services don’t want to be blocked by poison pill messages; instead, they want to mark these messages for special handling, save them, and come back to revisit them later.
We added a dead letter queue (DLQ) topic that stores poison pill messages. Consumer services can explicitly instruct Consumer Proxy to persist messages to the DLQ topic by sending back a gRPC error code. After a poison pill message is persisted to the DLQ Kafka topic, it will be marked as “negative acknowledged” in the out-of-order commit tracker. With DLQ, Consumer Proxy tracks which offsets have been acknowledged or negative acknowledged, and only commits to Kafka when all previous messages have been acknowledged or negative acknowledged, but not yet committed (see figure 9).

With DLQ, even if there are poison pill messages, Consumer Proxy can make progress.
Users can inspect poison pill messages persisted in the DLQ topic. Based on their needs, they:
- Merge the DLQ: Replay messages back to their consumer service
- Purge the DLQ: Discard messages in the DLQ
We provide tools for users to perform the above operations.
Flow Control
Consumer Proxy pushes messages to consumer services. In this push model, flow control is critical to ensure that consumer services receive neither too few nor too many push requests.
We offer some simple flow control mechanisms:
- Users can provide the size of the out-of-offset commit tracker and message processing timeout for each individual consumer service when onboarding to Consumer Proxy.
- After processing each message, consumer services send gRPC codes back to Consumer Proxy. Based on different gRPC codes, Consumer Proxy takes action to adjust message pushing speed.
- To prevent good messages being sent to the DLQ topic, Consumer Proxy uses a circuit breaker to stop pushing when the consumer service is totally down.
Comparison with Similar Systems
When we started investigating the problem space of Kafka for message queueing in late 2018 and early 2019, we evaluated the landscape of solutions that are already available in the Kafka community, and decided to build our own because no existing system supported the feature set that we needed. This is the summary of our evaluation of similar systems at that time.
Confluent® Kafka Rest Proxy
Confluent® Kafka Rest Proxy offers a consumer group API, and it mostly serves as a Rest-based passthrough to the binary Kafka consumer protocol. It doesn’t provide the features we want:
- It does not solve the partition scalability problem because each Kafka topic-partition is handled by at most one Kafka Rest Proxy instance
- Fat clients are still needed to discover and connect to the Kafka Rest Proxy server that serves a specific topic partition, rebalancing if necessary
- It does not support single message acknowledgements and out-of-order commits
- It does not support DLQ
Kafka Connect
Kafka Connect uses a similar push model to the one we implemented with Consumer Proxy. Most of the features described in this document could be implemented within a Kafka Connect SinkTask. We choose to use an internal clustering framework over Kafka Connect for several reasons:
- Tighter control over consumer group rebalance in order to serve P99 <10s E2E (from message producer to consumer) latency use cases, which was hard to achieve in Kafka Connect before KIP-415
- Support for bounded Kafka message consumption (i.e., consume up to a certain offset) in order to support redelivery of Kafka messages from DLQ
Next Steps
Moving forward, we intend to follow up in these areas:
- Implement Adaptive Flow Control Mechanisms: It is not easy to tune the flow control configurations of Consumer Proxy into appropriate values to achieve desired message pushing speed. We plan to implement Adaptive Flow Control mechanisms to eliminate the complexity of tuning these configurations and improve flow control.
- Support Kafka Cluster Federation: With Consumer Proxy, the Kafka team gains more control over Kafka consumers so we can move a topic between clusters without disrupting the consumer service.
Conclusion
Overall, Consumer Proxy provides great values for both Kafka’s users and its engineering team. It improves the development velocity for users by hiding all Kafka internal details and providing advanced built-in Kafka Consumer features. Meanwhile, it simplifies the Kafka team’s operational management process—we can configure, redeploy, and upgrade the Consumer Proxy without affecting users. As a result, within Uber, Consumer Proxy has become the primary solution for async queueing use cases—we have already onboarded hundreds of services.
Apache®, Apache Kafka®, Apache Hadoop®, Apache Hive™, Apache Samza™, Kafka®, and Hadoop® are registered trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Qichao Chu
Senior Software Engineer
Qichao Chu is a Senior Software Engineer on Uber’s Streaming Data Team. He has been working on highly available, fault resilient streaming systems, including Kafka Consumer Proxy and Uber internal Kafka client libraries.
George Teo
George Teo is a former Senior Software Engineer on Uber’s Streaming Data Team. He's worked on improving the user experience of Kafka as a reliable and scalable async message queue with projects such as Consumer Proxy, Kafka Dead Letter Queue, and Kafka Rest Proxy.
Haitao Zhang
Haitao Zhang is a former Software Engineer on Uber’s Streaming Data Team. He has worked on projects and tools to improve the user experience of Kafka as a reliable and scalable async message queue, as well as improve monitoring and alerting of Kafka ecosystem.
Zhifeng Chen
Zhifeng Chen is a Senior Staff Engineer, TLM on Uber’s Streaming Data team. He has been working on highly available, fault-resilient streaming systems, including resilient Kafka Rest Proxy and Kafka Consumer Proxy.