
Abstract
Uber uses a system called SubmitQueue to verify all changes before landing them on the main branch. SubmitQueue solves the same problem as Github’s “merge queue” and GitLab’s “merge train” features, speculatively executing CI in parallel and ensuring our main branch stays green while landing thousands of commits per day. Some changes take a long time to build and test (a.k.a., large diffs) and thus block many other changes from landing during that time. Large diffs occur more frequently as the size of Uber’s codebase and the change rate increased. Reducing the build and test time only helped to a certain extent, prompting us to look for better solutions.
In this article, we prove that it is safe to land changes out of order as long as SubmitQueue verifies all paths in the speculation tree, and all paths have the same outcome. With this capability, the impact of large diffs is reduced, leading to a 74% improvement in the wait time to land code, while continuing to keep the main branch green.
Introduction
At Uber, we strive to make sure that the main branch of a monorepo can be build, with all tests passing, at all times. With this approach, when developers see an error locally or on CI, they have high confidence that it is caused by their own change, instead of a pre-existing error on the main branch. It also allows us to continuously deploy from the main branch, and roll out new features quickly. Conversely, a broken main branch in a large codebase with thousands of changes a day makes it difficult to find the root cause of an issue and reduces the confidence to roll out changes safely.
In order to make sure the main branch of a monorepo is always green, we build and test all packages affected by a change, before landing it onto the main branch. As the change rate of a repository increases, verifying changes sequentially would eventually lead to a large backlog of changes waiting to be verified. To speed up the verification, we use SubmitQueue [5] to verify changes in parallel.
SubmitQueue has a conflict analyzer to decide whether two changes are independent or conflicting. When two changes affect two disjoint sets of packages, they are independent; otherwise, they are conflicting. Note that “conflict” in this context is not the same as Git merge conflict. All changes described in this article are assumed to have no Git merge conflict, because any changes with merge conflict with preceding changes would have been rejected by SubmitQueue before the verification starts.
For independent changes, SubmitQueue verifies and lands them independently regardless of the order in which they come to SubmitQueue. For conflicting changes, however, SubmitQueue uses a speculation tree to verify different landing sequences. As an example, when SubmitQueue receives 3 conflicting changes C1, C2, and C3 in this order, and by the time C3 arrives, the builds for C1 and C2 have not finished, SubmitQueue can start builds to verify C3, speculating the 4 possible outcomes for C1 and C2:
- both C1 and C2 are rejected
- C1 is rejected but C2 commits
- C1 commits but C2 is rejected
- both C1 and C2 commit
This leads to 4 different builds, namely B3, B2,3, B1,3 and B1,2,3, as shown in Figure 1. When B1 finishes, SubmitQueue then waits for either B2 or B1,2, and cancels the other, depending on the outcome of B1. As more builds finish, SubmitQueue eventually decides one build out of B3, B2,3, B1,3 and B1,2,3, and decides to commit and reject C3 based on the outcome of that build. Therefore, SubmitQueue can verify C1, C2, and C3 concurrently, but it has to make the decision of whether to commit or reject the conflicting changes in the order it receives them.

This becomes a problem when there is a change affecting a very large number of packages (a.k.a., large diff), and thus it conflicts with almost all other changes that SubmitQueue receives afterwards. What’s worse, because SubmitQueue has to build and test all packages affected by large diffs, the verification is slow. Therefore, all conflicting changes behind it have to wait even though they have finished their verifications (Figure 2).

Large diffs affect the developer experience and productivity, because changes sent to SubmitQueue right after a large diff have to wait for as long as two hours to land on the main branch. To reduce the land time for most developers, as discussed in a previous article [1], we first established a policy that requires large diffs to be landed outside the US business hours, which is suboptimal, so we improved our CI build time. Faster build time means large diffs spend less time on SubmitQueue and thus blocking less diffs. We no longer need a special policy for large diffs, allowing people to land them anytime when they are ready. It worked…until it didn’t.
New Problem
As Uber grew, the size of the codebase grew as well. Bigger codebase means SubmitQueue has to build and test more packages affected by a large diff. Figure 3 shows that the number of root targets (defined in [1]) affected by the largest change in a month grew 2.5 times over 2 years. Figure 3 also shows that the change rate increases by more than 2 times in the same period. Higher change rate means proportionally more large diffs. Because of the work we did in [1], we managed to decrease the build and test time in the second half of 2021, but it has since grown back due to the growth of the codebase (Figure 4). As a result, the wait time grew back to the level of May 2021 too. Further scaling out build machines becomes more and more expensive, with diminishing returns because of the overhead of parallelism. To reduce the wait time, we needed to look for new solutions.


New Idea: BLRD
When SubmitQueue receives a change A, it needs to test it on top of the main branch (A|main, or A given main). If another conflicting change B comes before A is merged into main, as SubmitQueue is not sure whether the verification of A would succeed or not, it would test B on top of main and A (B|main+A) in case A succeeds, and B on top of main (B|main) in case A fails. If verification of both B|main+A and B|main have finished successfully before the verification of A|main, which may take a very long time if A is a large diff, we know B can be merged onto the main branch regardless of the result of verification of A. Currently, B would still have to wait for A to land first.

Can we bypass the large diff (referred to later as BLRD) A and land B first? If A fails later, we would end up with main+B, which is already tested. If A passes and lands, we would end up with main+B+A, which is a new path (Figure 5). We need to prove that all targets and their exact versions (represented by target hashes) that need to build and test for path main+B+A have been verified during previous speculations, i.e., A|main, B|main+A and B|main+A.
Proof: Simple Case
Definitions
T: a target in the repo.
T0: the version of target T on the main branch. The version is represented by a hash combining all input files to T and the hashes from other targets that T depends on. When a change affects T either directly or indirectly, the version of T would change.
Tmain+A or TA for short: the version of target T after applying A on main branch.
Tmain+A+B or TAB: the version of target T after applying A and B sequentially on main branch.
Tmain+B+A or TBA: the version of target T after applying B and A sequentially on main branch.
CT(A|main+B) or CT(A|B): the set of targets with their hashes changed after applying A on top of B.
CT(B|main+A) or CT(B|A): the set of targets with their hashes changed after applying B on top of A.
CT(A|main) or CT(A): the set of targets with their hashes changed after applying A on the main branch.
CT(B|main) or CT(B): the set of targets with their hashes changed after applying B on the main branch.
Assumption
Let’s assume the builds are hermetic (i.e., same input and configuration produce the same output) and tests are deterministic (i.e., not flaky) so the target hash encodes everything that affects the state of T. Furthermore, the target hash is only affected by the current state of T, it is not affected by how this state is reached. In other words, as long as both A and B are applied on top of main, the version of T will be the same no matter whether A is applied first or B. So TAB == TBA. Non-hermetic builds and flaky tests will be discussed in the Discussion section.
Hypothesis
If B arrives at the SubmitQueue before A and lands the main branch to first, SubmitQueue needs to build and test CT(B) and CT(A|B) in order to guarantee that the main branch is green after landing those two changes. If A arrives before B, SubmitQueue instead tests CT(A), CT(B) and CT(B|A). When B ends up landing before A and all targets in CT(A), CT(B) and CT(B|A) pass the verification, we need to prove that all targets in CT(B) and CT(A|B), which should be verified if B arrives at the SubmitQueue first, should also pass. In other words: CT(B) ∪ CT(A|B) ⊆ CT(A) ∪ CT(B) ∪ CT(B|A). Since CT(B) ⊆ CT(A) ∪ CT(B) ∪ CT(B|A), we only need to prove:
Theorem 1: CT(A|B) ⊆ CT(A) ∪ CT(B) ∪ CT(B|A)
Scenarios
Case 1
For any target T, if TBA ∈CT(A|B) but TA∉CT(A), it means B either adds T to the graph, or adds a new item to the deps attribute of T or one of its transitive dependencies. In either case, the target hash of T should have been changed by B, making TB ∈CT(B). If TB is in CT(B), but TAB is not in CT(B|A), it means either:
- A deletes T, which means TBA ∉ CT(A|B); Or
- A removes an item from the deps attribute of T or one of its transitive dependencies, which means TA ∈ CT(A).
Both contradict the premise. So TAB must be in CT(B|A). If TAB passes during the speculation path main+A+B, TBA should pass too.
Case 2
For any target T, if TBA ∈CT(A|B) but TA∉ CT(B), it means B doesn’t affect T, so TB == T0 and TBA == TA. In addition, TA must be in CT(A) otherwise it would fall into Case 1, which means TB ∈CT(B), contradicting the premise. If TA passes during speculation path main+A, TBA should pass too.
Case 3
For any target T, if TBA ∈CT(A|B), but TAB∉ CT(B|A), it means B doesn’t affect T after applying on top of A, and TA == TAB. According to Case 1, if TA is not in CT(A), TAB should be in CT(B|A), contradicting the premise. So T must be in CT(A). When TA passes, TAB and TBA should pass too.
Summary
When change A arrives before change B and all targets in CT(B) and CT(B|A) have passed the build and test, it is safe to land B before A finishes its verification. After B is landed, the same verifications used to decide whether to land A before B can also be used to decide whether to land A after B. This is a very nice feature, because SubmitQueue doesn’t need to perform additional work for A.
We have been assuming the builds are hermetic and tests are deterministic to this point. In practice, they may not, which means that target hash doesn’t encode everything that affects the state of T. When this happens, TAB may pass on one machine but TBA fails on a different machine, even though their target hashes are the same. Although this is an undesirable situation, BLRD doesn’t make this situation better or worse. Non-hermetic builds and flaky tests make the verification unreliable even without BLRD. For example, TAB may pass on one machine but fails on a different machine too. Separate efforts have been made to address non-hermetic builds and flaky tests (e.g., [2]).
Proof: General Cases
Bypassing Multiple Changes
When there are several conflicting changes ahead in the queue, can a late-comer bypass those changes ahead with similar conditions?
Bypassing 2 Changes
Let’s start with a simple case when A and B came to SubmitQueue before C and there is no other changes between A, B and C, but C finished its validation before A and B, and all targets in CT(C|AB), CT(C|A), CT(C|B) and CT(C) pass. Is it safe to land C before A and B?

If all targets in CT(A) and CT(B|A) are passing and A and B are landed successfully, we end up with main+C+A+B. Landing A and B sequentially is equivalent to landing a bigger change combining A and B. Treating AB as one change, we need to prove that all targets in CT(AB|C) have been verified. From Theorem 1, we know that:
CT(AB|C) ⊆ CT(AB) ∪ CT(C) ∪ CT(C|AB).
It’s easy to prove that:
CT(AB) ⊆ CT(A) ∪ CT(B|A)
So:
Theorem 2: CT(AB|C) ⊆ CT(AB) ∪ CT(C) ∪ CT(C|AB) ⊆ CT(A) ∪ CT(B|A) ∪ CT(C) ∪ CT(C|AB)
It means that when C is landed after all targets in CT(C) and CT(C|AB) pass, it’s safe to land A and B afterwards after targets in CT(A) and CT(B|A) pass, which is the same requirement to land A and B before C.
- If A fails and B succeeds, targets in CT(B) must have passed. It is equivalent to not having A at all and Theorem 1 applies: CT(B|C) ⊆ CT(B) ∪ CT(C) ∪ CT(C|B).
- If A succeeds and B fails, CT(A) must have passed. It is equivalent to not having B at all and Theorem 1 applies too: CT(A|C) ⊆ CT(A) ∪ CT(C) ∪ CT(C|A).
- If both A and B fail, it is equivalent to not having A or B at all. It’s also safe to bypass them.
By the time when C finished its validation, not all targets in CT(A), CT(B|A) and CT(B) are verified. However, as long as all targets in CT(C), CT(C|A), CT(C|B), CT(C|AB) are verified, it’s safe to land C first and decide later whether to land A, B, or both, or none depending on the outcome of the verifications of A and B. The precondition of bypassing A and B includes and only includes all speculation paths from main to C. After C is landed, the requirement to land A, or B, or both, or none is exactly the same as landing them before C.
Bypassing More Changes
If we can bypass two changes, can we bypass three consecutive changes with similar conditions? If all changes are landed successfully later, using similar logic of Theorem 2, we can prove that:
CT(ABC|D) ⊆ CT(ABC) ∪ CT(D) ∪ CT(D|ABC) ⊆ CT(A) ∪ CT(B|A) ∪ CT(C|AB) ∪ CT(D) ∪ CT(D|ABC)
If one of A, B, or C fails, the scenario will become Theorem 2; if two of A, B, C fail, the scenario will become Theorem 1. In any case, it’s safe to bypass three consecutive changes given all speculation paths of D pass. With similar induction logic, we can prove that it’s safe to bypass multiple consecutive changes given all speculation paths pass.
Multiple Bypassings
So far, we have been considering a change bypassing other changes in the queue. Can more than one change bypass other changes?
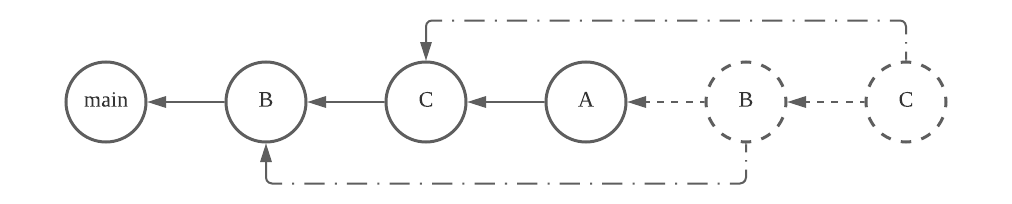
Starting with a simple case, after B bypasses A and lands, can another change C bypass A again and land? If A passes verifications after C is landed (i.e., CT(A) pass), we need to prove all targets in CT(A|BC) are already verified before landing A. Because CT(A|BC) ⊆ CT(BC) ∪ CT(A) ∪ CT(BC|A) ⊆ CT(B) ∪ CT(C|B) ∪ CT(A) ∪ CT(B|A) ∪ CT(C|AB), as long as all targets in CT(B), CT(C|B), CT(A), CT(B|A) and CT(C|AB) passes, it is safe for A to land after B and C. If A fails to land, it would become a trivial case as if A doesn’t exist at all and no bypassing happened. Therefore, at the time when B is landed, C can be landed as long as all targets in CT(C|AB) and CT(C|B) pass. Because B is already landed, the speculation paths involving B failing the verification are not necessary. After B is landed, one can treat it as the new main branch. Landing C after B and before A requires the same condition as if B comes and lands before A.
Moving to a similar case: if C bypasses A and B to land first, can B bypass A? In other words, if changes come to SubmitQueue in the order of A, B, C, can they land in the order of C, B, A? In this case, we need to make sure all targets in CT(A|CB) are verified. Because CT(A|CB) = CT(A|BC), A can be landed on top of C and B given the same conditions of the previous case. It means that after C is landed, B can bypass A as long as CT(B) and CT(B|A) pass. Although C changed the main branch before B lands, B can still bypass A with the same condition as if the main branch didn’t change. Similarly, we can prove that more changes can bypass A with similar conditions.
Multiple Changes Bypassing Multiple Changes
In previous discussions, we either considered one change bypassing multiple consecutive changes, or multiple changes bypass one change. When multiple changes bypass multiple changes, there is one case not covered by previous discussions. When there are changes A, B, C, D in the queue, and B bypasses A to land, can D bypass A and C to land? After B lands, it creates a “bubble” between A and C. Would this “bubble” block later changes?

If D bypasses A and C, and both A and C pass verifications, we need to make sure A and C can be safely landed after D. In order words, all targets in CT(AC|BD) should be verified. Thinking B as the new main branch by the time D finishes its verifications, applying Theorem 1, we get:
CT(AC|BD) ⊆ CT(AC|B) ∪ CT(D|B) ∪ CT(D|ABC) ………………………………………..(1)
Again, if we treat B as the new main branch, we get:
CT(AC|B) ⊆ CT(A|B) ∪ CT(C|AB) ……………………………………………………………………(2)
and according to Theorem 1:
CT(A|B) ⊆ CT(A) ∪ CT(B) ∪ CT(B|A) ………….…………………………………………………(3)
Plugging (3) into (2), we get:
CT(AC|B) ⊆ CT(A) ∪ CT(B) ∪ CT(B|A) ∪ CT(C|AB) …………………………………….(4)
Plugging (4) into (1), we get:
CT(AC|BD) ⊆ CT(A) ∪ CT(B) ∪ CT(B|A) ∪ CT(C|AB) ∪ CT(D|B) ∪ CT(D|ABC)
As a precondition for landing B before A, all targets in CT(B|A) and CT(B) have passed. When all targets in CT(A), CT(C|AB), CT(D|B) and CT(D|ABC) also pass, then we can safely land both A and C after B and D.
If A fails the verification, it becomes a simple case covered by Theorem 1: if all targets in CT(D|BC) and CT(D|B) pass, D can be landed before C.
If C fails the verification, it reduces to the multiple bypassing case discussed in the previous section, in which D is allowed to bypass A as long as all targets in CT(D|AB) and CT(D|B) pass.
To sum up, regardless of the outcome of the verifications of A and C, they can be bypassed by D as long as all targets in D’s speculation paths with B passing, namely CT(D|B), CT(D|AB), CT(D|BC) and CT(D|ABC). The same reasoning can be extended to more changes with more “bubbles.”
Summary
In general, a change can bypass several changes and land as long as it passes the verifications of all speculation paths involving those changes. On the other hand, if all speculation paths fail, can SubmitQueue reject a change without waiting for conflicting changes ahead? Because the change doesn’t land, there is no impact to the changes ahead. For changes that came after the bad change but bypassed it, they must have verified the paths that include the bad change being rejected. For changes behind that have not bypassed the bad change, the rejection of the bad change eliminates some speculation paths that assume the bad change landing successfully. SubmitQueue just continues to verify the rest of the paths as usual. So rejecting a change when all speculation paths fail is also safe.
Summarizing both success and failure cases: if all paths in the speculation tree of a change are verified and have the same result, either success or failure, SubmitQueue can bypass all conflicting changes ahead and land or reject the change.
Result
After enabling BLRD in the SubmitQueue for Uber’s Go monorepo [3] in late May 2023, the P95 wait time of June is 74% less than that of April (Figure 9). It is currently at a similar level to that of January 2022, when the large diffs were 20% faster to build and test, and we had 60% fewer changes in a month. This is achieved without any significant change in build and test time.

Future Work
For BLRD to work, SubmitQueue has to verify all paths in the speculation tree. The number of paths grows exponentially with the number of conflicting changes ahead. As we can see in Figure 1, the number of builds (tree nodes) doubles every time a new conflicting change comes to the SubmitQueue. It quickly becomes very costly to verify all paths as the depth of the tree increases. The original SubmitQueue paper [5] proposed a probabilistic model to predict the outcome of a build to avoid speculating all. This model only predicts the chance of a change being accepted, which is not enough for BLRD to work. For example, if SubmitQueue decides that a large diff is likely to be rejected and only speculate its failure path for all subsequent changes, these changes won’t be able to bypass the large diff. Therefore, we need to develop another model to predict the build and test time for a change. So if we know that a conflicting change ahead is likely to take a long time to verify, SubmitQueue will speculate all paths for it and allow subsequent changes to bypass it and reduce the wait time; otherwise, it will only speculate the most likely paths to reduce the cost. This is the next big problem we are going to tackle.
References
- T. French, M. Rukas, X. Tan: How We Halved Go Monorepo CI Build Time
- L. Lybus: Making Uber’s hermetic C++ toolchain. BazelCon 2022
- Z. Lin: Building Uber’s Go Monorepo with Bazel
- A. Zeino: Faster Together: Uber Engineering’s iOS Monorepo
- S. Ananthanarayanan, M. Ardekani, et. al.: Keeping master green at scale. EuroSys 2019

Zhongpeng Lin
Zhongpeng Lin is a Staff Software Engineer for Developer Platform. He is one of the founding members of Uber’s Go Monorepo, and has been the Tech Lead of its build system since then. Over the years, he also worked on various areas that improved the developer experience for Go Monorepo, such as code coverage, Git sparse checkout, and dependency management. He is also a maintainer of Bazel’s Go rule set (a.k.a. rules_go) and Gazelle, as well as a frequent contributor to open source projects used by Uber.

Matthew Williams
Matthew Williams is a Staff Software Engineer for Developer Platform. He is the Technical Lead for SubmitQueue, and especially interested in improving performance and reliability for large monorepos. Matthew is also the Technical Lead for TargetAnalyzer, a service that computes changed targets in both Buck and Bazel based monorepos.
Posted by Zhongpeng Lin, Matthew Williams
Related articles




Most popular

Advancing Invoice Document Processing at Uber using GenAI

Migrating Uber’s Compute Platform to Kubernetes: A Technical Journey

Fixrleak: Fixing Java Resource Leaks with GenAI
