Up: Portable Microservices Ready for the Cloud
Introduction
Each and every week, Uber’s 4,500 stateless microservices are deployed more than 100,000 times by 4,000 engineers and many autonomous systems. These services are developed, deployed, and operated by hundreds of individual teams working independently across the globe. The services vary in size, shape, and functionality; some are small and used for internal operations, and some are large and used for massive, real-time computation.
While all these services are different, they share common characteristics, and there are many aspects that could be consolidated for simplicity. The aspects we focused on were deployments, capacity management, compliance, and day-to-day operations. This article will cover how we consolidated and streamlined our underlying configuration and rollout mechanisms, including some of the interesting challenges we solved along the way, and the efficiencies we achieved by doing so.
History of Stateless Services at Uber
In 2014, Uber was a monolithic application that was written in Python® and stored data in a single PostgreSQL® database. As the system grew, and the company started to hire more engineers, eventually Uber transitioned to a microservice architecture. Still there was a lot of variance in how people deploy code, from random bash scripts to a set of dedicated Jenkins jobs. As the number of services started to grow into the hundreds, Uber built µDeploy to centrally deploy code at scale. With µDeploy, we containerized all stateless services and abstracted away host management and placement so the infrastructure group could manage the host fleet independently of the business level microservices. Service management and placement was, however, still highly manual.
Regions and Zones
Uber’s infrastructure follows a model where a group of zones form a region. Latencies between zones in a region are low enough that synchronous communication is efficient between the services within the same region. Zones may either be clusters of machines owned by Uber or it may be capacity from a public cloud provider but a specific zone would always only be backed by a single provider. Generally, any microservice should be able to call any other service without latency issues as long as they are located within the same region.
With µDeploy, engineers were still required to manage physical placement at the level of availability zones, meaning that the geographical placement of workloads was not centralized in the system. This meant that service engineers would still have to decide not only whether to run their services in an on-prem zone, but also in which specific zone it would run.
Decision to Move to Cloud
Operating our on-prem data centers, we experienced long lead times due to chip shortages and supply chain issues. On February 13, 2023 Uber partnered with Oracle and Google, aiming to diversify and decrease the company’s exposure to supply chain issues. Executing on this strategy would be impossible without having a system in place to abstract away the underlying infrastructure from thousands of Uber engineers working on hundreds of various services powering the business.
Making Uber Ready for Cloud Migration
It was clear from the beginning that migrating 4,500 stateless services to the cloud while keeping the business running would require an enormous amount of coordination and effort, and that the work would be both highly error prone and nearly impossible to manage through manual, orchestrated efforts. To make maintenance and management of stateless microservices work at scale, we needed to transform our services to make them automatically manageable by our centralized deployment system without human involvement.
Beyond Stateless: Portability
Building on our model for zones and regions, we came up with the concept of portability. A portable service is one that can run in any zone within a region and can be moved to a new zone automatically by the infrastructure platform without any human involvement. This includes movement across public cloud providers, as well as in or out of our in-prem zones. Our services did not generally have this property, as some of them depended on zone-specific configuration as well as affinity of zone-specific resources. It became clear that we needed this property to hold for all services in order to do an automated migration to the cloud.
Making Uber Portable
Over the course of 2021 and 2022, we ran a program across all of engineering to ensure that all services were portable. In many cases, violation of portability was possible to detect through code inspection, simply by looking at the use of string consts and file names in the code. For these simple cases, we built linter rules to highlight code that appeared hardcoded to run in specific physical locations. To really test that the services were indeed portable, we had to actually move them around between zones without human involvement. We built a suite of test tools that would let the owner of the service initiate the first movement of the service. This tooling was based on the existing tooling for safe and incremental code rollout, meaning that the owner of the service could always revert placement back to the original zone to address any problems that were detected. Once a movement had been done successfully, the service was marked for automatic movement going forward. Over the following couple of years, we went through this process for every single service at Uber and eventually reached full completion of all services. With this work done, we could start making changes to the zone topology without any involvement from service engineers.
To ensure that services remain portable over time, we regularly exercise their ability to move by continuously migrating all services between zones every few weeks. This makes it easy to discover regressions in services, and over time engineers have gotten used to not assuming any specific zone placement for their service.
Up: Multi-Cloud Multi-Tenant Federation Control Plane
Based on what we had determined as the most time consuming and error prone service operations, we set the following initial goals for the system:
- Present a single point of entry for engineers to interact with infrastructure systems
- Manage and enforce best practices for services deployed directly in the system to give a high degree of safety during code rollout
- Automate placement of services into availability zones; this included changing placement to new zones as new availability zones became available so that the placement is centrally coordinated to support high availability for Uber in general
- Automate cumbersome infrastructure level migrations so service engineers don’t have to get involved in them
High-Level Architecture
Up is structured into three architectural layers that each have their own responsibilities.
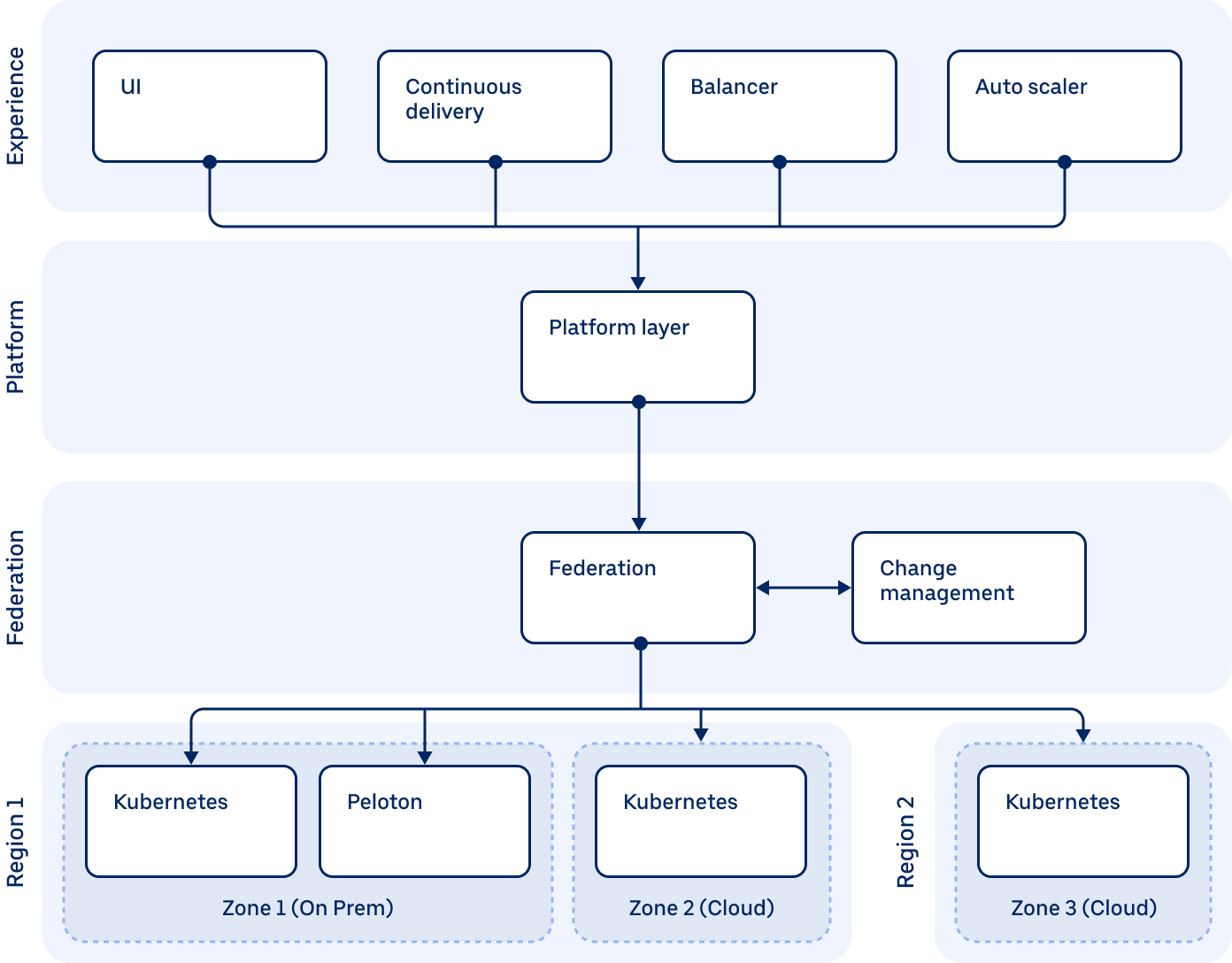
The Experience Layer at the top implements the various ways that our engineers interact with the system. This includes both a UI for direct control, a Continuous Delivery experience for automating day-to-day deployments, as well as robots that keep the system in a good state. This also includes the Balancer that continuously causes workloads to be moved to clusters and zones that are less utilized as well as our Auto Scaler that continuously optimizes capacity allocation for each workload.
The Platform Layer implements the abstractions that are used by the experience layer to interact with the services. This includes the service and service environment abstractions that form the conceptual model for operating services as well as the service level API itself. At the Platform layer, services constraints are represented as high level goalstates that describe the desired properties of the actual service placement. This could be constraints for the capabilities of the machines to run on as well as overall compute capacity for the service per region.
The Federation Layer implements the integration to the compute clusters. This layer organizes all clusters according to their capabilities and physical placement to implement the region and zone abstractions used by the upper layers. This layer takes the high level service goalstate from the Platform and translates it into zone and cluster placement. This translation is based both on the constraints from the goalstate as well as the actual state of the clusters, including where capacity is currently available and in which clusters and auxiliary constraints can be met. This result of the translation may change over time and a different zone and cluster placement may be more desirable later. Any call from the Balancer as well as any other operation initiated by the experience layer may lead to this placement being recomputed and changed. To ensure that the system remains safe and that services remain in good condition, the Change Management component implements a rollout flow that changes the global state gradually, in small increments with integrations to all systems that monitor service health. This rollout process includes going through canarying and monitoring health signals from across the whole system. Any observed issue results in the system quickly reverting the service to the configuration and placement that it had prior to starting the change.
Finally, the Regions contain the actual cluster instances, including Peloton and Kubernetes® clusters. These are external to Up itself, but are the targets of the actual capacity placement and manage placement of containers on physical hosts.
Impact
We started working on Up in 2018, delivered a working prototype in early 2019, and made the platform generally available in mid-2020. Since then we’ve migrated more than 4,000 services across all of Uber’s lines of business from the old deployment platform to Up. A large bulk of this migration was automated, freeing the team to focus on the most advanced use cases, and helping other teams with the migration. The stability of the platform during this period was the utmost priority making sure we keep the business running under a substantial load with millions of people using Uber systems every day.
The full migration took us a good two years, moving about 2,000,000 compute cores to the new platform, and was successfully accomplished in 2022. With this migration we accomplished substantial monetary savings with autoscaling and efficiency efforts, returning tens of millions of dollars of extra capacity to the business, and tens of thousands of engineering hours previously spent on manual service updates, setting and filling up new zones, and learning to navigate Uber’s complex Infrastructure landscape.
What’s Next
After finishing the migration from µDeploy to Up, the team can now focus on building out solutions that could be applied to the entire fleet of services in a centralized and automated manner, and a user experience around those features.
Cloud Migration
Uber is moving a substantial proportion of its fleet to the cloud. With large scale automation, and an abstraction layer provided by Up, the service teams are largely distanced from the infrastructure detail of this transition.
Automated Continuous Delivery
We aim to fully automate code delivery all the way to production using automated pipelines, running various checks and tests before code hits production. A particular aspect the team plans to focus on in 2023 is to keep the services “fresh”, ensuring that all code running in production is up to date with the latest security and library updates.
Deployment Safety
Existing data shows that quite a substantial number of incidents we observe are related to code and configuration changes. We aim to substantially decrease the rate of defects that actually make it all the way to production by automating previously manual aspects of the service lifecycle, such as running pre-production tests or setting up incremental rollout policies.
Platform
Organizing all of Uber’s stateless service fleet under one umbrella platform allows us to more explicitly model dependencies and interactions between Infrastructure Platform offerings. This helps to provide both a uniform model in the code, and also a fully-integrated user experience for the rest of our Engineering organization. Being able to observe and operate all of your infrastructure in one place is the next big goal for the team.
Conclusion
The effort to build the Up platform represented a substantial cultural shift when all stateless services were now being incrementally deployed using the same set of best practices and automation. Making changes to rollout policies or building out more automation for large-scale library rollouts is now possible in a centralized way, which previously required months of work. We’re looking forward to continued collaboration with Up’s stakeholders and the service owners to ensure we achieve our vision: letting Uber engineers focus on code, instead of worrying about infrastructure.
Main Image Attribution: “Containers” by tsuna72 is licensed under CC BY 2.0
Mathias Schwarz
Mathias Schwarz is a Sr. Staff Engineer working on the Up team as one of its founding members. Mathias works in the stateless management space and drives deployment safety efforts at Uber. In addition to his role, he also works with local universities helping students connect with Uber to intern and acquire their first experience in the industry. He holds a Ph.D. in Computer Science from Aarhus University.
Andrew Neverov
Andrew Neverov is an Engineering Manager who manages the Up team. He’s been a part of the industry since monoliths and static web pages and part of the Up team since the very early days. Andrew’s primary focus is building teams that can successfully work and solve problems within the Core Infrastructure domain operating business-critical systems running 24/7.