
Introduction
The Uber Eats system handles several hundred million product images and millions of image updates are performed every hour. We have implemented a content-addressable caching layer that very effectively detects duplicates and thereby reduces download times, processing times, and storage costs. This full system was developed and completely rolled out in the course of less than 2 months, which improved the latency and reliability of the image service and unblocked projects on our new catalog API development.
Images at Uber
When you buy something online you want to have the best possible impression of the product. In many cases, it would be optimal if you could actually see it with your own eyes and hold it in your hands before you decided to buy it. One way of getting close to the real-world experience is by having good images of dishes, drinks, groceries, and basically anything you buy online.
Uber Eats sells millions of different products. Following the great increase in selection associated with expanding the business to cover more verticals such as groceries, alcoholic beverages and domestic merchandise, we have seen the product catalogs growing from the hundreds of entities to the tens of thousands. Furthermore, the exact same product (e.g., a can of Coca Cola) will be sold in many different grocery stores. For restaurants most product images are unique. With the selection increasing, more duplicate images will appear and an efficient deduplication is needed to keep image processing, storage, and CDN costs down.
Our image service processes millions of images each day. It determines if the URL and the image is already known. If not, it downloads the image and checks that it is valid. We then reformat and scale it to our standard size before storing the final processed image. To ensure the best customer experience, we also validate that the images are of high quality and show the products clearly. This quality assurance is, however, not part of the automatic image processing that is focused on here. The image processing flow on catalog uploads is shown below.

Storing and Deduping Images Efficiently
An efficient image handler should be able to store the same image only once, thereby limiting the amount of reprocessing and storage needed. We have therefore created a simple solution that efficiently deduplicates images across merchants.
Previously our image processing would download, process, and store all URLs sent to the service without doing any deduplication. Furthermore, our catalog system was centered around always providing the full menu on every upload. Therefore, to avoid processing images on each upload, we made the limitation that one had to update the image URL to update the image. This has to a large extent limited reprocessing the same images, but only within a single store and merchant. The disadvantages of this system were:
- No reuse of images
- No reprocessing of updated images with unchanged URLs
To solve these issues we decided to make the image processing more intelligent by moving more functionality into the service and letting the service deduplicate images when possible and detect updated URLs.
Deduplicating Images
To deduplicate images we created this flow:
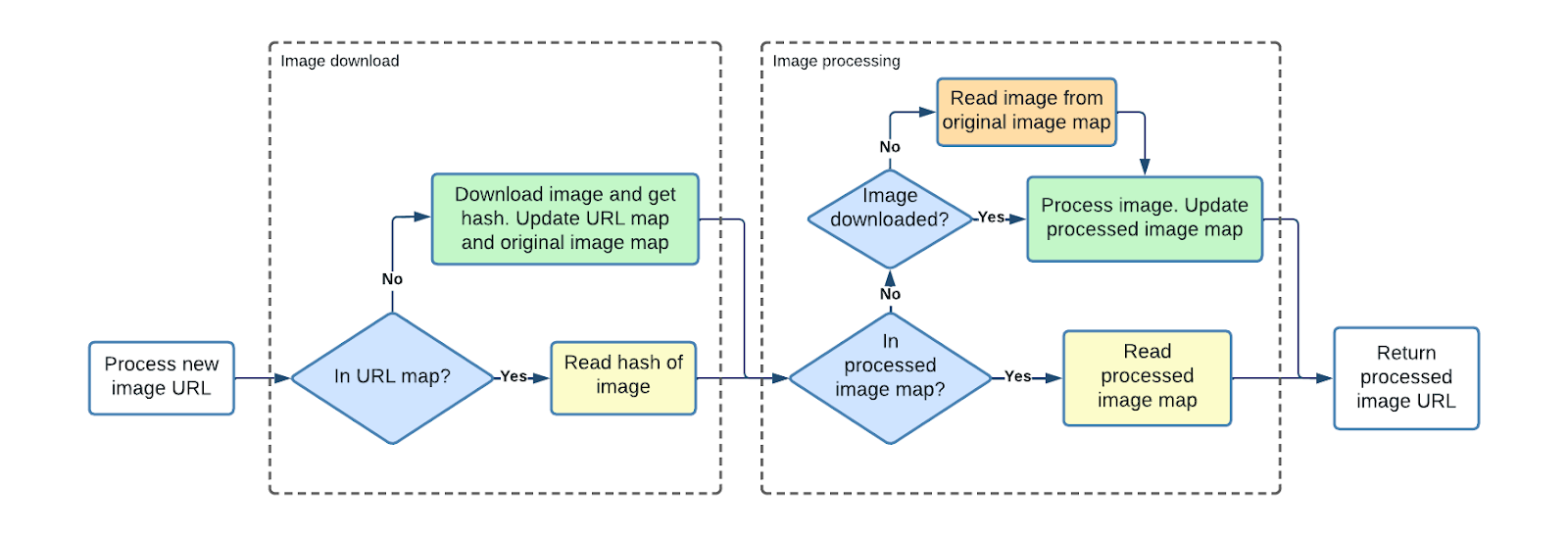
There are 3 main flows:
- Known, processed image: This flow goes through the 2 yellow boxes and is the simplest flow that just returns already stored values
- New, unprocessed image: This flow passes the 2 green boxes where the image is downloaded and processed
- Known image but not processed: This flow goes through the yellow box to the left and the orange box to the right. It covers the cases where the image is known but has not been processed before with the requested specification.
We use an architecture that has 3 maps, summarized in the table below. Basically, the URL map returns that hash of the input image. This hash, together with the processing specification, returns the processed image. The processing specification contains the input requirements (file format, image size, aspect ratio, etc.) and the output format and size. Finally, the original image map returns the original image based on the hash of this image.
The maps are stored using our blob storage system, Terrablob, which is similar to Amazon’s S3. Blob metadata is in our case stored in Docstore. The images (both the original and the processed) are stored as blobs, whereas the URL map is only storing metadata, and therefore only uses Docstore.
| Name | Key | Value |
| URL map | Image URL | Hash of image |
| Processed image map | Hash of image and processing specification | Processed image |
| Original image map | Hash of image | Image |
When an image processing is initiated with an image URL and a processing specification, we initially check if this URL has already been downloaded. If this is the case, we just read the hash of the bytes of the original image from our map. If it has not been downloaded before, we download it, update both the URL map, and store the original image in our system.
In the next step, we use both the hash of the image and the processing specification. If this image has both been downloaded and processed before, we just return the processed image’s URL to the requestor. If not, then we process the image, store it, and return the URL.
Furthermore, we also store client-side errors during the processing in the processed image map. An example probably explains this best: We set a minimum allowed size of the original image in the processing specification. If this is not met by the supplied image, then we store this error in the processed image map. Whenever a new job with the same URL and the same specification is performed, then we can immediately return the error. This makes handling the error cases very efficient also.
Stable URLs with Updated Images
The reader may have noticed at this point that the above system does not allow us to update the image with an unchanged URL, since this is stored in the URL map. One simple solution could be to set a fairly low TTL on the entries in the URL map. This would allow an uploader to change the image after the TTL has expired. However, this is inefficient and not very usable.
We have therefore created an addition to the flow above.

Once again, the unknown URL goes through the green flow and the known URL passes the yellow box and potentially also the green.
To determine if we need to download the image again (these are the cases where the URL is found in the URL map) we read the value of last-modified in the HTTP header. If this is newer than the value stored in the URL map, then we know that the image has been updated since we downloaded it the last time and we need to download it again. Once downloaded we update the URL map with the new hash of the image and the new last-modified. If it has not changed, then we can proceed with the hash we have already read from the URL map and do not need to download the image again. This solves the second issue.
Conclusion
The new content-addressable caching layer has been running successfully for the last 4 months now. The service has been downscaled several times without lowering the latency (median latency is 100 ms and P90 is 500 ms) and we currently process millions of images every day. Over a week, less than 1% of the calls need to be processed and can instead be directly returned. The new architecture has been a great improvement of our system.

Kristoffer Andersen
Kristoffer Andersen is a software engineer on the Uber Eats team in Aarhus. He is working with the current and future catalog system and has in particular focused on improving the image pipeline and the observability.
Posted by Kristoffer Andersen
Related articles





Most popular

Migrating Large-Scale Interactive Compute Workloads to Kubernetes Without Disruption

Building Uber’s Multi-Cloud Secrets Management Platform to Enhance Security

Robust Database Backup Recovery at Uber
