Revolutionizing Money Movements at Scale with Strong Data Consistency
Uber as a platform invites its users to leverage it, earn from it, and be delighted by it. Serving more than 18 million requests per day, in 10,000+ cities, has enabled people to move freely and to think broadly while earning a livelihood on it. As one of the underlying engines, Uber Money fulfills some of the most important aspects of people’s engagement in the Uber experience. A system like this should not only be robust, but should also be highly available with zero-tolerance to downtime, after our success mantra: “To collect and disburse on-time, accurately and in-compliance”.
While we expand to multiple lines of businesses, and strategize the next best, the engineers in Uber Money also thrive on building the next generation’s Payments Platform which extends Uber’s growth. In this blog, we introduce you to this platform and provide insights into our learnings. This includes migrating hundreds of millions customers between two asynchronous systems while maintaining data-consistency with a goal of zero impact on our users.
Introduction and motivation
Gulfstream, Uber’s fifth generation collection and disbursement payment platform, is our latest. It is a single, integrated, SOX-compliant system built on the principles of double-entry accounting and can reconcile itself. We discuss some short-comings in the older model which we fixed in the new model in this article.
The legacy system had two internal systems. One provided collections from riders and eaters and the other provided disbursements to restaurants and partner-drivers. This had a lot of shortcomings such as no holistic view of end-to-end money movements. It also slowed the process to build more generic features such as Cash Trips, where Uber needed to collect commissions from its driver partners and so on. So we wanted to build a role-agnostic system which could collect and disburse money from any user. This enables faster onboarding for multiple lines of businesses.
Advantages of the new system and architecture
Job/Order based system
Transaction-based systems are hard to extend for running balances and accounting for user entities. Tracking and enforcing the zero-sum principle is difficult.
Our new architecture now uses Job/Order based systems. Each Job represents a ridesharing trip or eats/food delivery. There could be multiple orders that belong to the same Job due to adjustments, incentives, tips, etc. Each order contains multiple order entries and each order entry represents an amount of money moving in or out of a user’s account. Together it represents the money movement from a payer’s account and to a payee’s account. The sum of all the entries is zero (the system cannot create or destroy money). It flows from one account to another. The money movement, order-based system creates an analogy to the real world double-entry accounting system.
This table illustrates a simple example of a ridesharing trip with a $20 total fare including a $2 service fee and a $18 trip fare. The sum of all the order entries is zero.
| Trip fare | -18 | Payer Escrow |
| Service fee | -2 | Payer Escrow |
| Trip fare | 18 | Payee Escrow |
| Service fee | 2 | Uber Escrow |
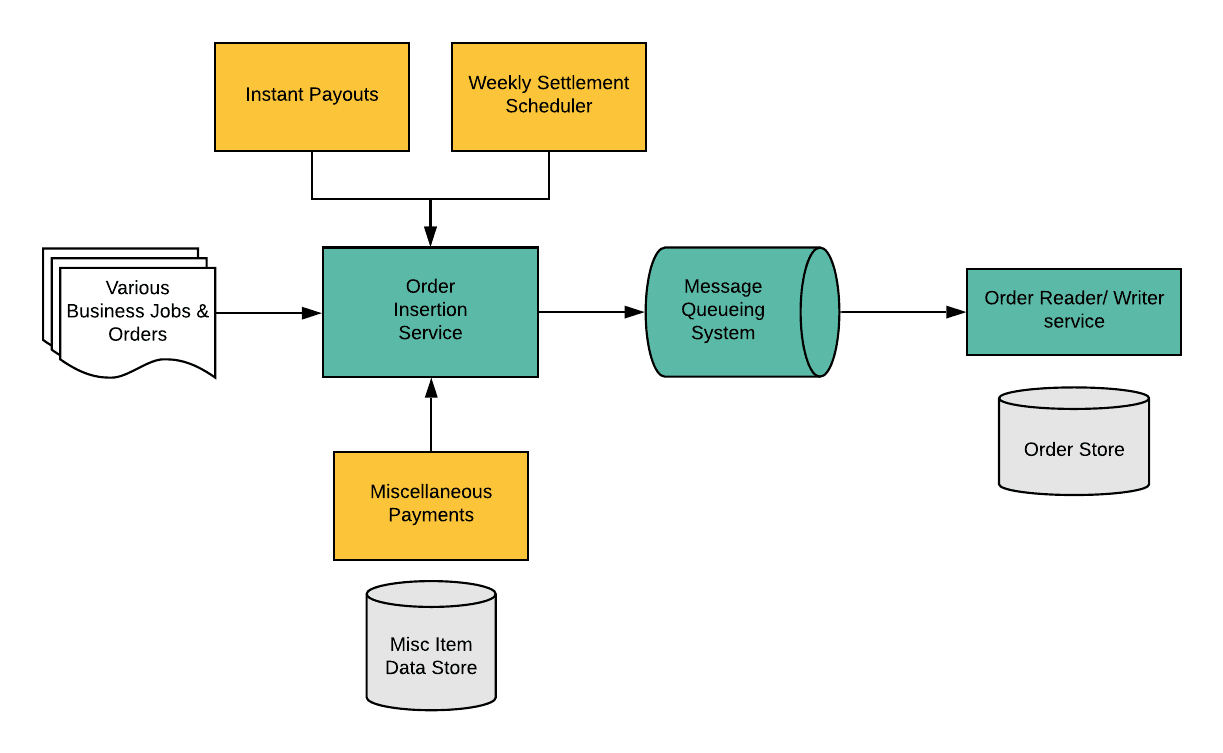
We decouple creating an order and processing it by leveraging message queueing system:
- The order insertion service handles the request to create a Payment order. It then creates the payment orders, publishes the order data to messaging topics and persists it to OrderStore.
Fig: Pipeline for creating orders
- The order processing service consumes and processes payment orders. The service also produces successive orders when it processes the initial payment orders. It also routes collection and disbursement requests to the corresponding payment service providers. Finally it produces the payment result orders with the success or failure status of the collection or disbursement.
Figure: Pipeline for order processing

Highly available and active in all regions
- Services exchange order messages on lossless Messaging Queueing System clusters that are available in multiple regions. We have standby cross-region consumer instances in our deployment pools. If one region goes down, service instances in other regions can still consume and process order messages.
- Our systems persist the payment account and balance data in a storage system with multiple zone quorum.
How do we achieve idempotency?
- We use unique identifiers as identifiers of users, jobs, and orders. And we generate the unique identifiers determiniscally.
- The processed order unique identifiers are used to guarantee exactly once order processing.
- The money movement is based on order processing that atomically alters user’s payment accounts.
- Our systems guarantee orders to be immutable.
- We process orders after we persist them.
Data consistency between asynchronous platforms
Due to the complexity of the legacy payment system and the scale of Uber’s user base as well as payment data, it took multiple years for us to migrate to the new payment platform. During the migration, we need to maintain both platforms and high data consistency across them. In order to achieve that, we persist every transactional change to the user’s payment accounts in entity change log so that our system serializes writebacks by the entity change log’s version number per user. We dual-write each transaction in the legacy system with a field including the version number. This way, the writeback is never out of order and the end result is always consistent even if we have multiple concurrent adjustments of the same job.
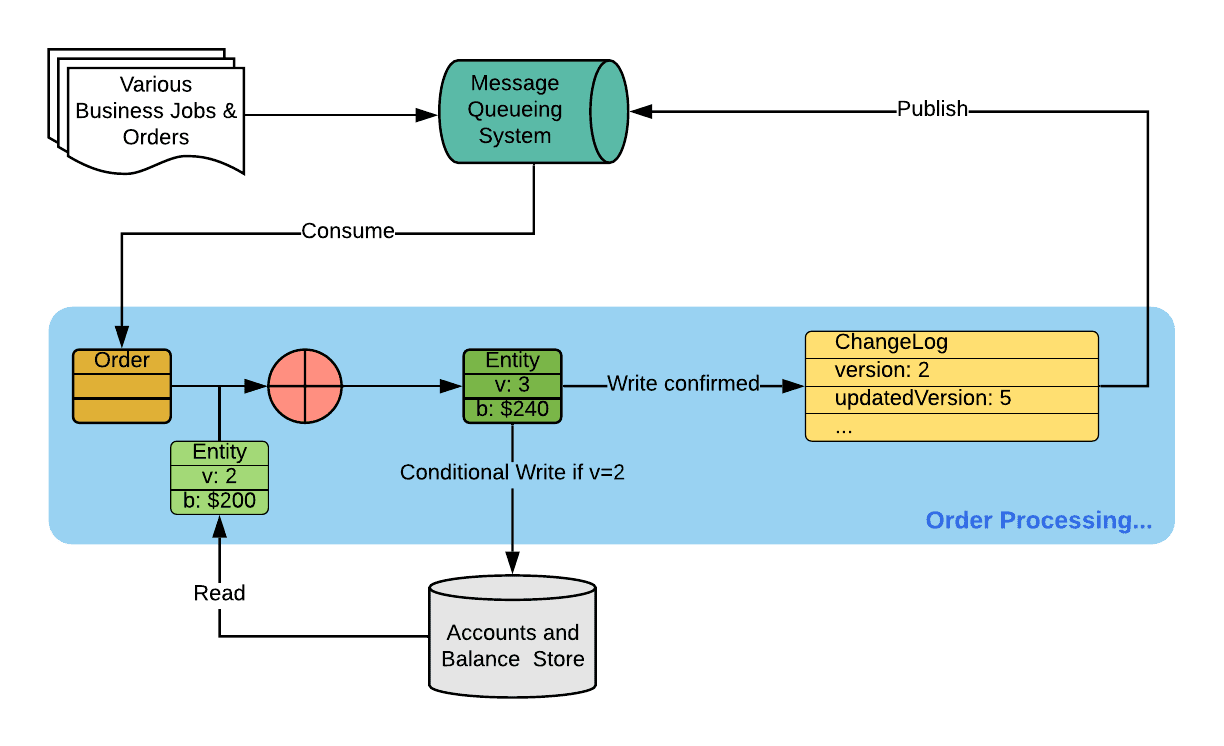
Migration and writebacks
With our experience undertaking migration initiatives at Uber, we learned to:
- Build the right dashboards to track business metrics.
- Strategize rollouts so that we can catch and fix issues quickly, without impacting a lot of customers.
- Monitor traffic between systems to validate that the new system behaves as we expect and has no customer impact.
- The payment data writeback from the new system to the legacy system is serialized according to each entity change log version to address race condition issues between the two asynchronous systems.
Dashboards and metrics
Before we could put the new system into production, we added various different metrics. This includes tracking counts, results, latency, and observability-based metrics for each flow. We set up various alerts for the production versus shadow traffic. This helped us track business metrics on the system. In addition, we set up various dashboards to validate our service. We could also use these dashboards to understand how many successful business events we performed per active user and how many anomalies we detected between different systems. Our oncall engineer and rollout in-charge engineer tracked the dashboards on a daily basis.
Smart rollout strategy
We designed the rollouts to migrate the system in multi-step fashion. We divided the rollouts broadly into:
- Intra-team service rollout to synchronize the systems
- The Order data model has a property RolloutData that is passed across the whole payment flow and we use it to decide whether any of the payers or payees are primary in the new payment system. The structure of RolloutData looks like this:
- The Order data model has a property RolloutData that is passed across the whole payment flow and we use it to decide whether any of the payers or payees are primary in the new payment system. The structure of RolloutData looks like this:

- External rollout actually migrates the entire functionality to the new system and deprecates the old system.
- The actual rollout is an incremental slow rollout with multiple strategies.
- We defined the control group and experimental group with hundreds of users and partners in each group.
- We picked a country with a limited number of users and partners for initial rollout
- We based our rollout on a percentage in each country, starting from 1% and gradually increasing to 5%, 10%, 20%, 50%, 100%.
- We controlled the rollout by dynamic configurations so that we did not need to deploy code during the rollout.
- The actual rollout is an incremental slow rollout with multiple strategies.
Sequential writebacks
We update the payer and payee accounts when we process each order. Our services produce an EntityChangeLog to reflect the sequence of the account changes. Each changeLog entry has a version number and we increment the number per user. The service uses the version number to enforce the sequence of the writeback of orders.
The writeback service consumes EntityChangeLog events from the Messaging Queueing System. If it consumes an event that is not in sequence, our processing logic identifies the version mismatch and we retry the event a number of times. If it still fails, we publish a reconciliation event to another Messaging Queueing System topic. The service that consumes the reconciliation of the writeback service ingests the events. It checks the version number against what we recorded last in the legacy system. We fetch all the orders with versions in the gap from OrderStore and write them back to the legacy system, one after another.
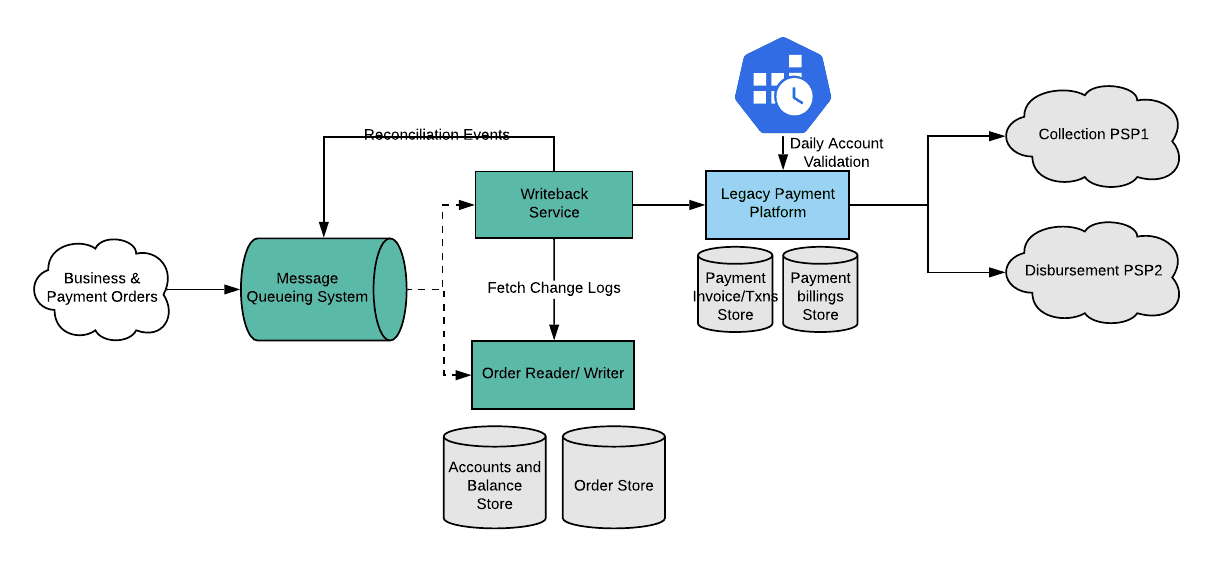
Validations and retries
Our pre-rollout phase had various validation strategies setup in our system:
- Asynchronous jobs run every 24hrs, which split the job runs for countries and further classified them down to the cityIDs.
- End-to-end debugging logged in hive to access the logs on a per-order basis.
- We perform validations on the state of an order in the system to check whether we processed the request end-to-end and whether] we collected and disbursed on every order.

During the rollout-phase, we started expanding to more and more countries, which exponentially increased the load on all the services. We found an important feature missing between the legacy system and the new system. Specifically we had to build a service to consume reconciliations replay orders in the version gap we discussed above in Sequential writebacks.
Along with the validations, we also set up replay request APIs so that we could re-run the data to collect real-time analysis and debug issues faster. Since we built the system to be idempotency, this helped us recover from service-based failures faster and to record data quickly.
Since this required manual interventions, we quickly built an ingester for retry queues. This enabled delayed replay mechanisms that could run basic validations before replaying orders. This helped to prevent loading our queues with bad data.
Lessons learnt
Migrations are a reality for any company scaling quickly and trying to expand the spectrum of products that they design. This complex project had multiple aspects, namely:
- Design choices to build an order-based system with double entry bookkeeping.
- Seamless migration between two asynchronous-systems with very high availability.
- Zero impacts to our customers internally and externally with the platform redesign.
We believe what we learned can help engineers across the globe trying to deal with problems at scale. And therefore we want to share some of the key concepts:
- Versioning is essential to promote consistency across two asynchronous systems.
- End-to-end integration tests with test tenancy and a staging environment so that we could expose and fix bugs.
- Continuous validation is essential for migration and rollout. With it, you can catch issues right after the rollout starts.
- Comprehensive monitoring and alerts shorten the time it takes to detect and mitigate issues.
- The foundation of a highly reliable payment system includes exponential retries of temporarily failing payments over a long period of time.
Acknowledgements
The project was a 2 year cross-team effort with more than 40 engineers, product managers and operations teams involved throughout the journey. Here, we are taking this opportunity to acknowledge all the engineers from the core Gulfstream team who invested heavily in the successful completion of the project.
Conclusion and what’s next
We went through a journey of extensive architecture design, implementation and well-thought through rollouts and active monitoring. And we successfully launched the platform with negligible downtime in all countries. We onboarded new lines of businesses, namely Uber Freight, NEMO, seamlessly and efficiently.
As part of our future projects, the team is already thinking about truly turning the system into a platform. This will reduce the engineering effort for newer use-case onboarding and migrate us away from payee-, payer-, and LOB- specific models to revolutionize the payments at Uber.
We hope these practices and architecture design prove useful for other engineers and teams performing migrations at scale.
Aakriti Singla
Software Engineer at Uber Payment Platform team since 2017, working on various money movement initiatives to help with Uber’s growing business needs.
Simon Wu
Software engineer at Uber since 2015, previously tech lead in the Payment Platform group and currently domain lead of the Financial Products group. Responsibilities include ensuring the engineering design and architecture quality, driving incident postmortem reviews, and leading cross-team project development in the areas of payments and financial products.