
Introduction
Uber’s business runs on a myriad of microservices. Ensuring that changes to all of these services are deployed safely and in a timely manner is critical. By utilizing continuous deployment to automate this process, we ensure that new features, library updates, and security patches are all delivered to production without unnecessary delays, improving the overall quality of code serving our business.
In this article, we share how we reimagined continuous deployment of microservices at Uber to improve our deployment automation and the user experience of managing microservices, while tackling some of the peculiar challenges of working with large monorepos with increasing commit volumes.
Background
Over the last few years we have invested heavily in maturing our tools to accommodate the continued growth of our business, while reducing production incidents. With a steady growth in code output, and more than 50% of all incidents being caused directly by code changes, our ability to enable continuous, safe deployments without impeding productivity as the business scales, is crucial for Uber’s success.
It is commonly known and evident in the industry [1] [2] that continuous deployment (CD) of code to production intrinsically reduces the risk of introducing bugs or defects. This is not only due to the use of CD itself ensuring that bugs and vulnerabilities are patched in a timely manner, but more so the best practices, culture, and discipline that must be in place before engineers gain enough confidence to let a machine automatically deploy their code. Before enabling CD, engineers tend to ensure they have adopted good engineering practices, such as:
- Code reviews
- Continuous integration (unit- integration- and load tests)
- Detection (continuous monitoring and alerting, automated rollback mechanisms)
What constitutes good code reviews, sufficient unit/integration test coverage, etc, is a heavily debated topic, which is beyond the scope of this article
Uber has a vast platform of engineering and dev tools (e.g., Ballast, SLATE), supporting good practices for engineers to adopt. However, historically, there have been a multitude of deployment processes in place, with limited company-wide standards or best practices for individuals and teams to adhere to. With our recent migration of all microservices to our internal cloud platform, Up, we identified the opportunity to change this for the better.
When we kicked off this project in 2022, we had approximately:
- 4,500 microservices distributed across 3 monorepos (Go, Java, and Web)
- 5,600 commits per week, with many commits affecting >1 service
- 7,000 production deployments per week
- 34% manually triggered (not using any kind of CD at all)
- 7% of services deploying automatically to production using CD
The prior state of CD at Uber
CD is not a new discipline at Uber. Historically, Uber’s CD system ran as a standalone and separate CD system, making it opt-in and left to each individual team to configure.
It was highly flexible and offered the ability to build completely customized CD pipelines in a YAML-based DSL. With this flexibility, we inevitably ended up with more than 100 unique pipeline templates for deploying microservices, with no enforcement of testing, monitoring, or what else it might (or might not) be doing, outside of running a sequence of actions as illustrated below:

As a consequence, the lack of standardization in CD pipelines impeded our ability to improve deployment safety and reliability company-wide, which carries significant risk when managing a microservice fleet at Uber’s scale, with a large number of changes going into production every day.
Besides these shortcomings, having two separate deployment systems was, in itself, confusing and undesirable. Therefore, with the recent migration to Up, and given its maturity and adoption, we decided to sunset the existing CD system in favor of a new, integrated CD experience: Up CD.
Goals
Built from the ground up to continuously apply changes in a repeatable and safe way, we sought to automate deployments to prevent human errors, converge on existing tooling for testing, and ensure monitoring of regressions as changes are being applied.
To this end, Up CD provides:
- Standardized and automated deployments to production
- Safety at its core, integrating closely with Uber’s observability and testing stacks
- A CD experience integrated tightly with the Up platform, and enabled by default
- UI/UX tailored to the needs of Uber engineers, with built-in support for monorepo-based development
By building a CD system with these features, our expectation was that we could increase the adoption of automation and allow more services to be automatically deployed to production. Additionally, it was crucial that we could do so while decreasing (or at least not increasing) the rate of incidents in production.
Designing for automation
In order to realize our vision, we set out with the goal of designing the most streamlined deployment experience possible. The system should safely advance every service’s production environments to run a build with all relevant changes on the Git repository’s main branch.

In the following section, we highlight some of the most important principles for our revamped CD system.
Simple core data structures
As is evident in many of Uber’s blog posts, one challenge was the scale of our monorepos. For example, at time of writing in 2024 our Go monorepo sees more than 1,000 commits per day, and is the source for almost 3,000 microservices, which could all be affected by a single commit. It is clear that building and deploying every service in the repository for every commit would be extremely inefficient. More importantly, there’s also little advantage to doing so, as most commits only impact a small subset of services. The set of services that actually have their code binaries impacted by a commit could be computed via the repository’s Bazel graph.
With this in mind, we determined that while our CD system had to understand the entire history of a Git repository to ensure that commits were deployed in the correct order, for individual services we could–and should–reduce the scope dramatically. By scoping each service to the subset of commits that actually changed the code binary, it is also much easier for service owners to identify what exact changes their service is picking up with each deployment, compared to diving into the voluminous Git log for the monorepo.
This allowed us to settle on a relatively simple data structure, where each service would be linked to all the commits in the history that are actually associated with it. This is illustrated in the following figure:
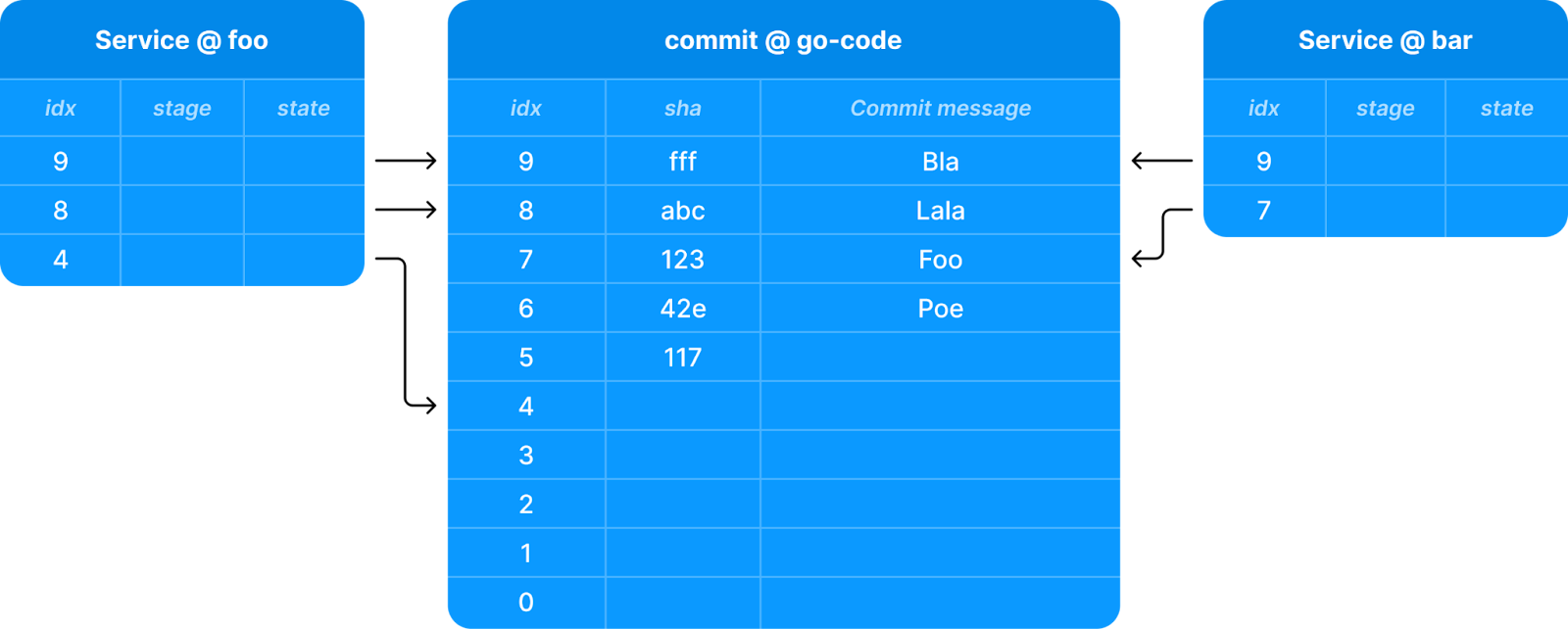
A unified commit flow model for all services
To get to this point, we decided to utilize Uber’s Kafka Consumer Proxy to consume a Kafka topic emitting an event when a commit is pushed to a Git repository. Whenever this occurs, an analysis phase is conducted to organize the commit into the appropriate structure, and determine the set of services that were impacted (changed) by the commit:

Obviously, the first step for each service impacted by a commit, would have to be to build it into a deployable container image. Afterwards, we allow engineers to customize a series of deployment stages relevant for their service. For an arbitrary service, the flow of a single commit might then be represented as the following figure shows:

Given our experience with the prior, highly customizable, CD system, we knew that the flow had to be opinionated. Thus, we decided that the stages themselves had to be fairly simple. The configurability was primarily limited to the gating conditions, where users could combine a variety of predefined options to express what must be satisfied before a deployment stage is started. These conditions could include:
- Has the commit soaked in the previous stage for the desired time?
- Are we within a user-defined deployment window (e.g., during the team’s business hours)?
- Are there any other operations running for the service (e.g., a manually triggered deployment, or an automatic horizontal scaling)?
- Are there any firing service alerts that would cause a deployment to roll back?
Each stage is run independently of any other. For each stage, the newest commit that has successfully completed the prior stage, and is satisfying all gating conditions (if any), is thus immediately advanced to the next stage.
To implement these mechanisms, we utilized Cadence, an open-source workflow orchestration engine built at Uber. It was straightforward to implement build and deployment workflows to be started on demand. Moreover, we implemented the gating mechanisms as workflows. Each deployment stage has its own gate workflow, which runs periodically to check whether any commit has passed the prior stage. If that is the case, it then considers its gate conditions to determine if a deployment should be triggered now.
Intuitive user experience
To ensure we got the product design right, we conducted user research and outreach in order to understand what our engineers would actually need from a CD system, given our existing tooling and monorepo scale. Based on this, we designed a user experience around a service’s commit history, where engineers can easily see the complete list of commits that were determined to impact their service, along with the current state of the service.
Given the commit volume of the monorepos, it was also clear that even with automatic deployments, not every commit impacting the service could–nor should–be deployed to production stages. To make it simple to reason about what exactly had been serving production traffic or other commits deemed “interesting,” we collapsed in-between commits to provide a clearer view, addressing a key pain point of our engineers. This means that if an issue is discovered for a given production deployment, it would be very easy to expand the section down to the prior deployment to see the exact set of changes that were made to the service with that deployment. It should be immediately apparent how this view is backed by the service-level data structure of the commit history.
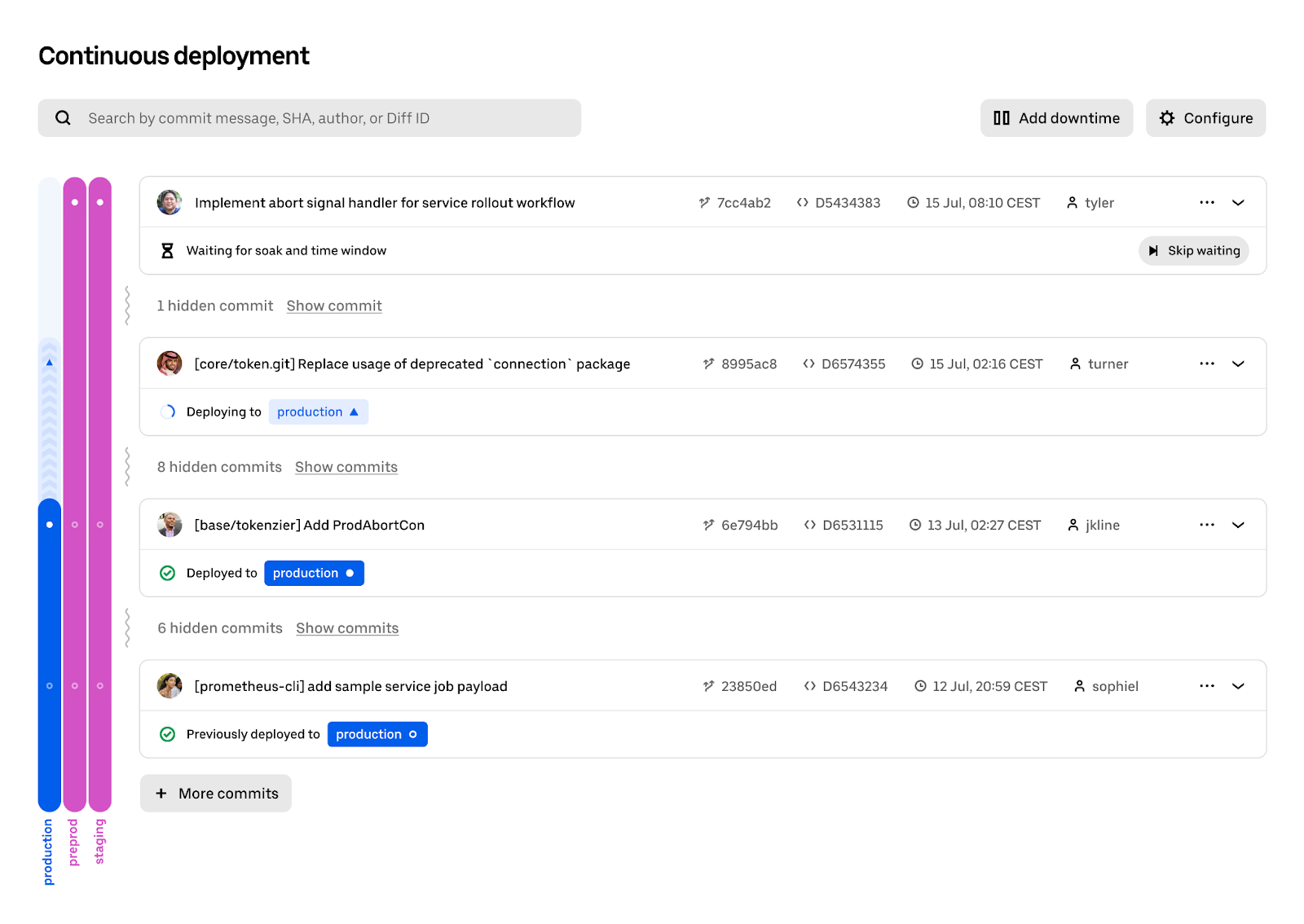
The current state of the world is concisely represented via the so-called “swimlanes” on the left of the commit history. Each of these lanes displays exactly what code is and has been deployed to the different service environments. By hovering over the lanes, details about the deployment status for that environment can be obtained. See the figure below:
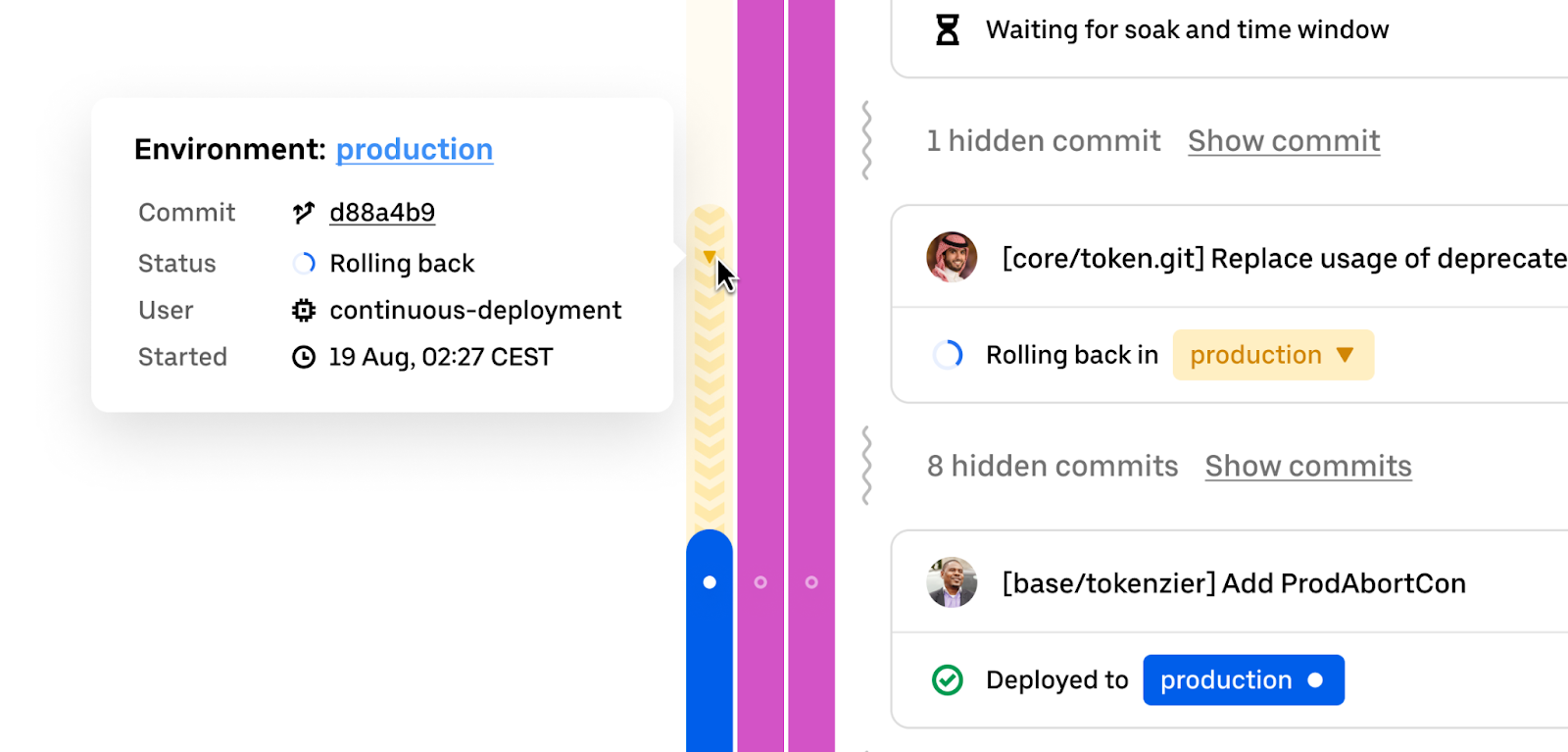
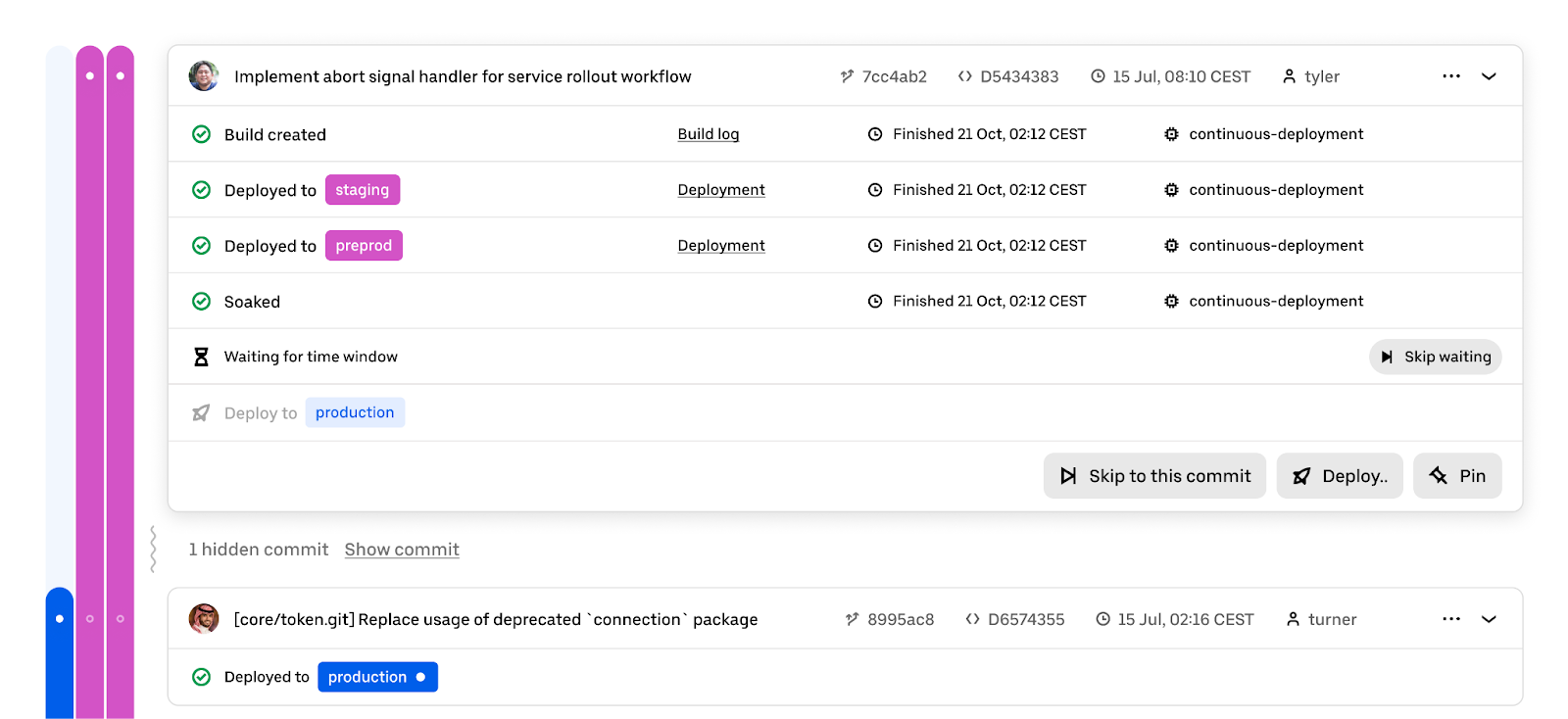
Furthermore, we associate a series of events with every commit. The top-level view shows the most relevant event for the commit, though every commit can be expanded to understand not only exactly what has happened to it already, but also what is going to happen for it in the future, given the deployment stages and gating events configured for the service.
Tight coupling
In order to provide trust in and increase adoption of automation, it was clear that we had to provide a unified, streamlined deployment experience; it would not be satisfactory to simply bolt a separate CD orchestration layer on top of the deployment system.
We built the new CD system to not only do its own thing, but to be tightly coupled to Up and mindful of other operations, guaranteeing that its actions would not catch users by surprise. For example, this means that if an engineer manually starts a deployment to a production environment outside the CD pipeline, then the CD UI will incorporate this deployment in the service’s commit history. Moreover, the system’s internal state is mutated to incorporate the fact that the commit (and anything prior to it in the Git history) was already deployed to the targeted environments.
This is also the case if an engineer builds a commit not strictly related to the service (e.g., by building from HEAD of main) and deploys that to their service, then that commit is added to the internal state, so the CD view is able to always represent the correct state of affairs and isn’t misleading to users who use this as the primary place to understand their service state.
This was an important strategic decision, as it allowed an incremental shift from manual deployments towards CD, instead of being an all-or-nothing approach. This also means that whenever an engineer takes some manual action to, for example, mitigate an incident, the CD system will be able to automatically do the right thing (which frequently is to not do anything, or pause), given the situation.
Post-release observations
In this section, we highlight some of the effects that we saw from the release of Up CD.
Increase in adoption of automation
After releasing our CD experience internally, we started seeing significant shifts in behavior. As we had hoped for, engineers started embracing it and we saw immediate adoption, which kept rising: Concretely, we saw the number of services being deployed automatically increase from less than 10% to almost 70% over a 12 month period.
As services are deployed more frequently, it has also become easier to attribute fault to specific commits, as fewer commits are going out with each deployment.
No increase in production incidents
While increasing the rate of deployments, we were happy to find that the overall rate of production incidents did not increase proportionally. In fact, during the same 12 month period where CD adoption climbed, we saw a decrease in reported incidents per 1,000 code changes of more than 50%.
As there were other efforts ongoing while this was carried out, which will be detailed in a separate blog post, we cannot claim causation for this feat. However, it is clear that we could in fact succeed in our vision to get our engineers to deploy their services to production automatically, without increasing the frequency or severity of incidents.
New challenges
However, we also started seeing new challenges. In particular, we found that the risk of making changes to monorepo code shared by many services (e.g., if someone changed a common RPC library shared by all services), had suddenly increased, as the changes would more rapidly get deployed to all the impacted services (and many of those deployments might happen in parallel). This meant that if such a change introduced a significant bug that wasn’t caught during CI, automation would be able to quickly break a lot of services simultaneously.
Generally, some services would have mechanisms in place to detect the issue and automatically roll the deployment back, but it is unlikely that the problem would be automatically detected for every service.
For this reason, we introduced the ability to utilize signals about a commit across services, so if some significant fraction of the services did not deploy successfully, the commit was considered to be problematic.
To get as clear a signal as possible, we stagger the deployment of risky, cross-cutting commits according to our internal service tiering. Initially, Up CD deploys it to our least important cohort of services, and, when a sufficient percentage of those are successfully deployed, it advances to the following tier. If a significant fraction of the services start experiencing problems, the deployment is halted and the commit author notified about a potential issue.
With this deployment strategy, we mitigated the risk of customer impact from such risky changes to acceptable levels and, just as importantly, increased trust in automated production deployments by providing additional guardrails for particularly risky changes.
Key metrics
To quantify the results of this project, we summarized how some of our key metrics changed during this project in the following table:
| Metric | Before Up CD (primo 2022) | Post Up CD (March 2024) |
| # services | 4,500 | 5,000 |
| Monorepo commits / week | 5,600 | 11,000 |
| Production deployments / week | 7,000 | 50,000 |
| % of deployments CD orchestrated (partially or fully to production) | 66% | 95% |
| % of services fully automated to production | 7% | 65% |
Conclusion
As we have detailed in the previous sections, our revamped CD system, Up CD, embodies a strategic shift towards automation as a core principle in our deployment methodology. We deem that this shift has been crucial for managing the complexity and scale of our operations with heightened safety and efficiency, shifting the burden of delivering code to production from our engineers to automation.

Rasmus Vestergaard
Rasmus is a Senior Software Engineer on the stateless deployment platform (Up) team. He works on microservice build and deployment systems, with recent efforts centralized around continuous deployment.

Kasper Munck
Kasper is an Engineering Manager who manages the stateless deployment platform (Up) and heads the Deployment Safety initiatives for all production changes at Uber.
Posted by Rasmus Vestergaard, Kasper Munck
Related articles





Most popular

Slashing CI Costs at Uber

Helping you stay informed about risks to your account status

Reinforcement Learning for Modeling Marketplace Balance
