
Introduction
Machine Learning (ML) is celebrating its 8th year at Uber since we first started using complex rule-based machine learning models for driver-rider matching and pricing teams in 2016. Since then, our progression has been significant, with a shift towards employing deep learning models at the core of most business-critical applications today, while actively exploring the possibilities offered by Generative AI models. As the complexity and scale of AI/ML models continue to surge, there’s a growing demand for highly efficient infrastructure to support these models effectively. Over the past few years, we’ve strategically implemented a range of infrastructure solutions, both CPU- and GPU-centric, to scale our systems dynamically and cater to the evolving landscape of ML use cases. This evolution has involved tailored hardware SKUs, software library enhancements, integration of diverse distributed training frameworks, and continual refinements to our end-to-end Michaelangelo platform. These iterative improvements have been driven by our learnings along the way, and continuous realignment with industry trends and Uber’s trajectory, all aimed at meeting the evolving requirements of our partners and customers.
Goal and Key Metrics
As we embarked on the transition from on-premise to cloud infrastructure that we announced in February 2023, our HW/SW co-design and collaboration across teams was driven by the specific objectives of:
- Maximizing the utilization of current infrastructure
- Establishing new systems for emerging workloads, such as Generative AI
In pursuit of these goals, we outlined distinct key results and metrics that guide our progress.
Feasibility and Reliability: ML users expect successful convergence of their training tasks without errors within an expected time frame (either weeks or months based on complexity). For instance, training larger and more complex models like Falcon 180B™ can take many months, and longer training durations heightened the likelihood of reliability issues. Hence, our target is to achieve 99% uptime SLA for all training dependencies to ensure consistent and reliable outcomes.
Efficiency: Our focus on efficiency involves thorough benchmarking of diverse GPU configurations and assessing price-performance ratios of on-prem and cloud SKUs tailored to specific workloads. We gauge training efficiency using metrics like Model Flops Utilization (MFU) to guarantee optimal GPU utilization. Our aim is to prevent idle GPUs, opportunistically using training jobs during serving’s off-peak hours through reactive scaling, and upholding high utilization rates to maximize resource efficiency. We want to do this while also maintaining fairness of resource sharing between different users.
Developer Velocity: This metric is quantified by the number of experiments our engineers can conduct within a specific timeframe. We prioritize a mature ecosystem to bolster developer velocity, ensuring our teams work efficiently to deliver optimal solutions. This approach not only streamlines our state-of-the-art model to production but also reduces the time taken for this transition.
What follows next is a summary of results from various initiatives that we are taking to make training and serving deployments efficient and scalable, across both on-prem and cloud infrastructure:
Optimizing Existing On-prem Infrastructure
Federation of Batch Jobs:
Our GPU assets are distributed over multiple Kubernetes™ clusters in various Availability Zones and Regions. This distribution is primarily due to GPU availability and the node count limitation within a single Kubernetes cluster. This arrangement presents two primary challenges:
- Exposure of infrastructure specifics to Machine Learning Engineers.
- Inconsistent resource utilization across clusters due to static allocation. Although we have an effective resource-sharing system within each cluster, we lacked the capability for inter-cluster scheduling.
To address these issues, we created a unified federation layer for our batch workloads, including Ray™ and Apache Spark™, called Michelangelo Job Controller. This component serves as a centralized interface for all workload scheduling, conceals the underlying Kubernetes clusters, and allocates workloads based on various policies (load aware, bin-pack), including compute and data affinity considerations. We plan to share more technical details on this in a subsequent blog post.
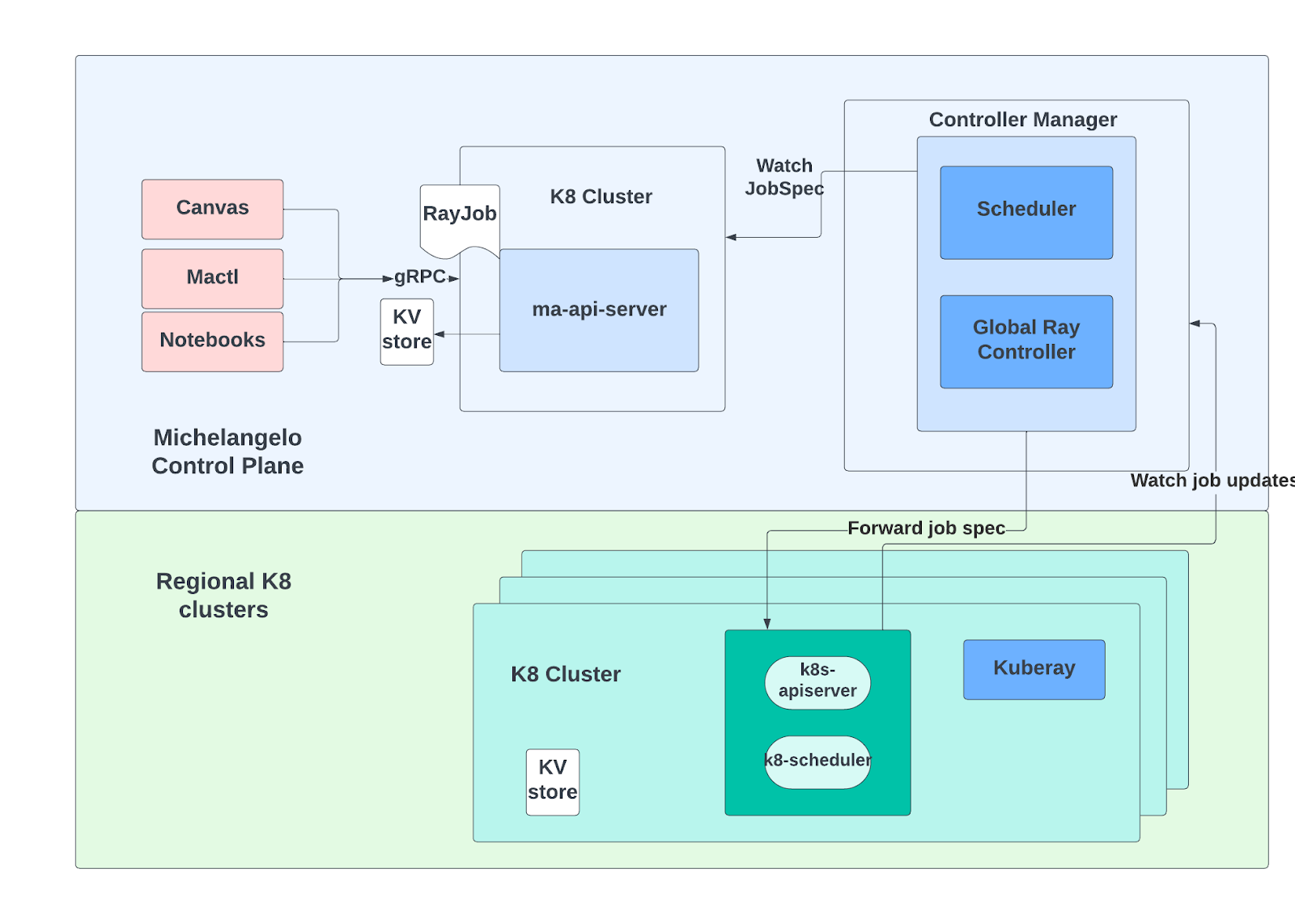
Network Upgrade for LLM training efficiency
When expanding infrastructure to accommodate Generative AI applications and enhancing the efficiency of distributed training while fine-tuning open-source LLMs, it is important to focus on scaling network bandwidth across both scale-up and scale-out configurations. This necessitates implementing critical features such as full mesh NVlink™ connectivity among GPUs, upgrades in network link speeds, proficient congestion control management, QoS controls, and the establishment of dedicated rack and network topologies, among other essential features.

We present a synopsis of findings derived from a Large Language Model (LLM) case study, emphasizing the considerable impact of enhanced network bandwidth and congestion control mechanisms on training effectiveness and price-performance efficiency. Our observations revealed nearly a two-fold increase in training speed and substantial reductions in training duration when employing higher networking bandwidth and better congestion control mechanisms compared to our existing network interconnect. During multi-node training, duplicating data across nodes heightens local memory demands and adds to IO workload. Our analysis prompted a recommendation to augment network link capacity by 4x (25GB/s to 100GB/s) on each GPU server, potentially doubling the available training capacity. While building these we also need to make sure the “Elephant Flows” generated by the large training runs don’t negatively impact the other high-priority service by proper isolation and QoS controls.
Memory Upgrade to improve GPU allocation rates
Newer AI/ML workloads are demanding more system memory per GPU worker than what we had designed for. The inherent physical constraints, such as the limited number of memory channels on each server, and DIMM capacities deployed during NPI (new product introduction) restricted our ability to scale up GPU allocations. To improve our GPU allocation rates, we have initiated an effort to double the amount of memory on these servers (16GB to 32GB per DIMM channel). Additionally, we are also building a framework to repurpose and reuse the DIMM’s when older racks are decommissioned. Such optimizations allow us to maximize utilization of existing ML infrastructure and make the most of our current resources. We will detail the efficiency gains achieved through this initiative in an upcoming post. In parallel, we have kicked off efforts to help rightsize the training jobs’ resource requirements. As demonstrated by others [ref], manually requesting the optimal resources is a hard problem, and automating it would help in increasing the allocation efficiency.
Building New Infrastructure
Price-performance evaluations across various cloud SKUs
In late 2022 as we embarked on our journey towards transitioning to the cloud, we assessed various CPU and GPU models offered by different cloud providers. Our aim was to compare their price-performance ratios using established benchmarks ranging from tree-based and deep learning to large language models alongside proprietary datasets and Uber’s models such as deepETA and deepCVR. These assessments, conducted for both training and serving purposes, enabled us to select the most suitable SKUs optimized for our specific workloads, considering factors like feasibility, cost, throughput, and latency. Throughout 2023, we extensively tested 17 different GPU and CPU SKUs, employing various libraries and optimizers, including Nvidia’s TensorRT™(TRT) and TRT-LLM optimizations. For instance, as depicted in figures 4 and 5, we found that while A10 GPUs might not offer the most cost-effective throughput for training tasks, they prove to be the optimal choice for our serving use cases, delivering the best throughput while maintaining acceptable SLA using TRT.
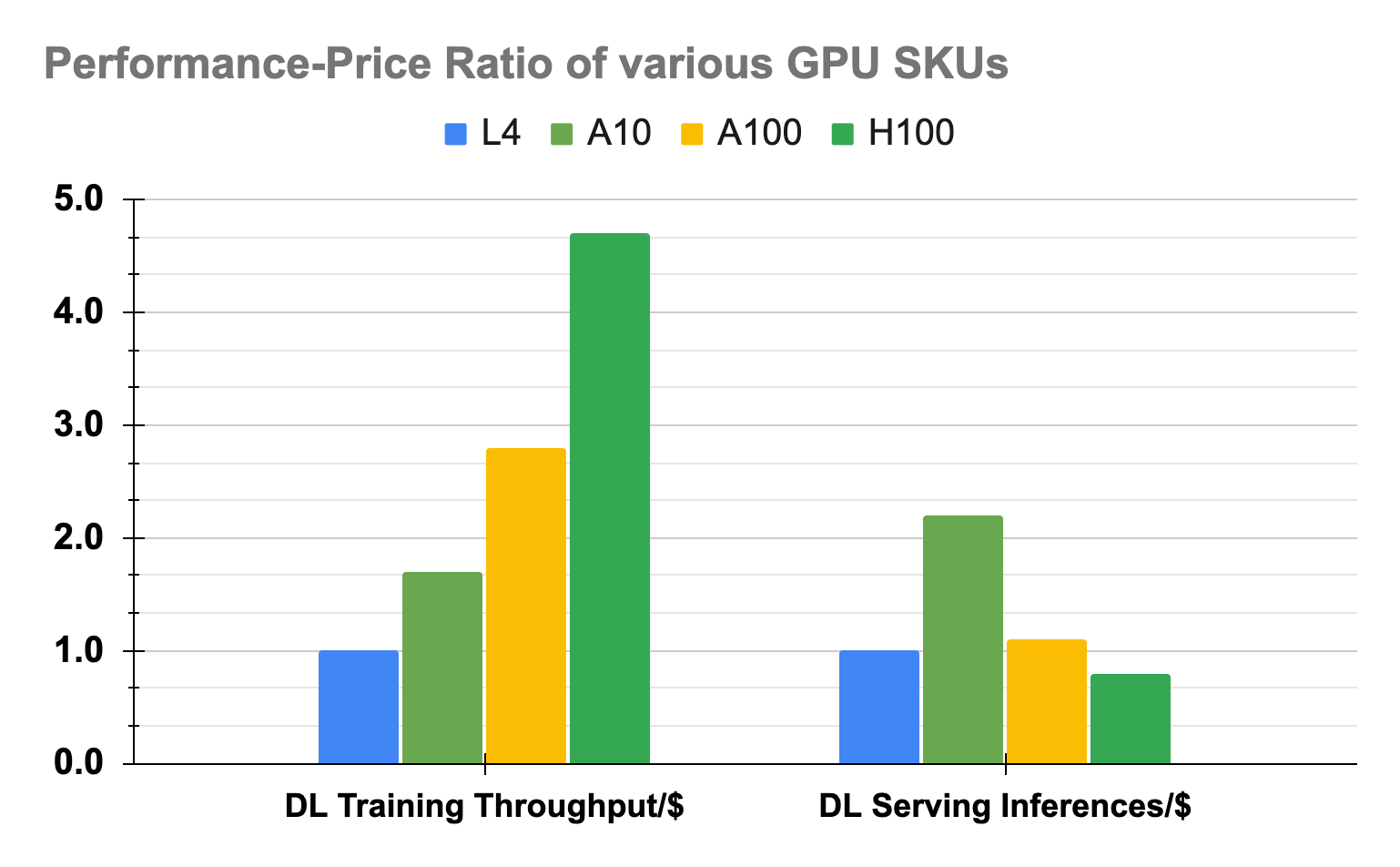
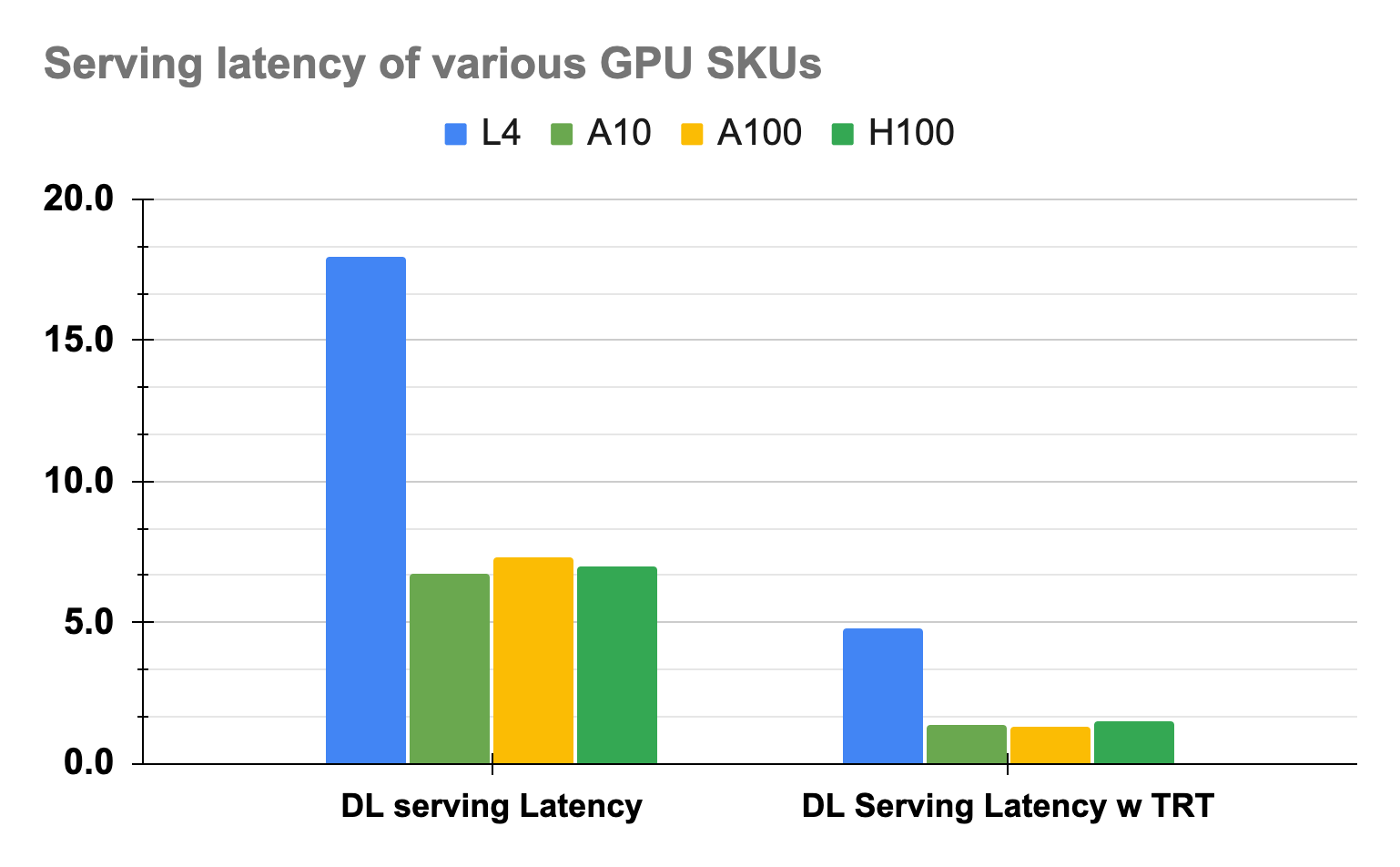
Numerous Generative AI applications at Uber necessitate the use of Nvidia’s newest H100 GPUs to satisfy their stringent latency requirements. This requirement stems from the H100 GPUs’ capabilities, which include up to 4x TFlops and double the memory bandwidth compared to the earlier generation A100 GPUs. While experimenting with Meta™ Llama2™ model series, involving various batch sizes, quantizations, and model parameters, we evaluated various open- and closed-source frameworks to further optimize for LLM serving performance. In Figures 6 and 7, we present a specific case where we employ two metrics: per-token latency (ms/token) and tokens/sec/gpu, to evaluate and compare the model’s performance across two of the top-performing frameworks (TRT-LLM and a currently confidential framework), keeping all other parameters constant and using FP16 quantization.
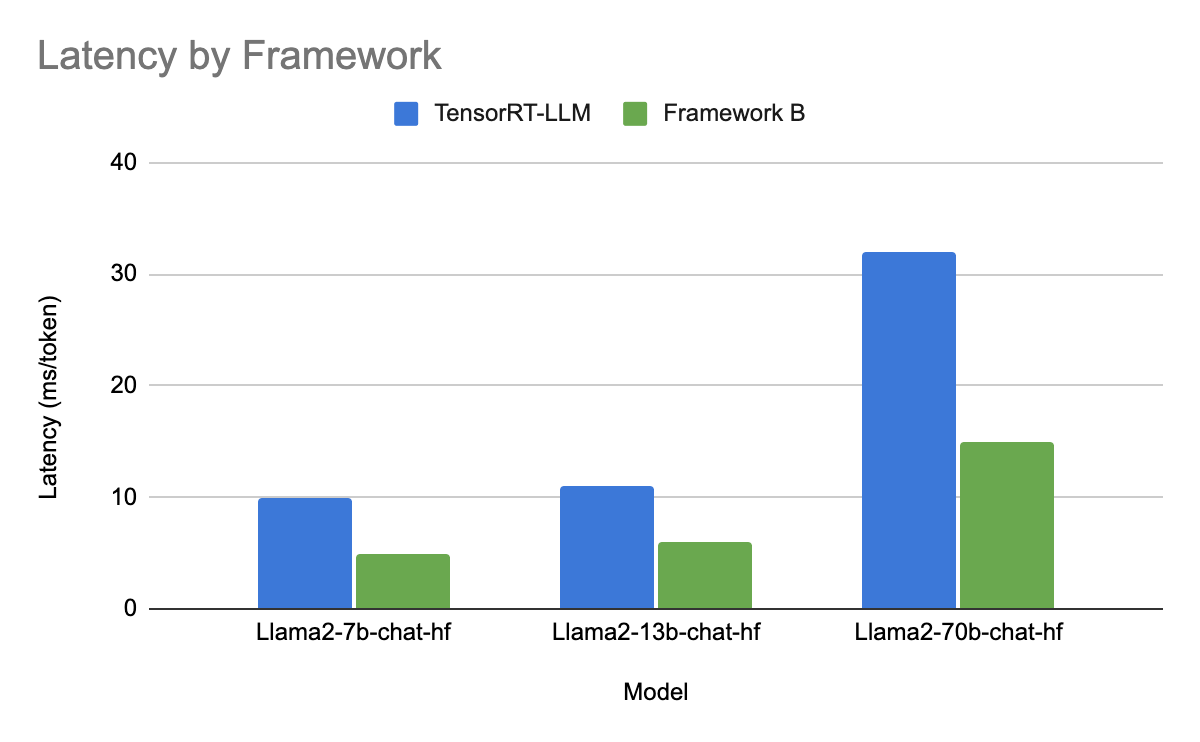
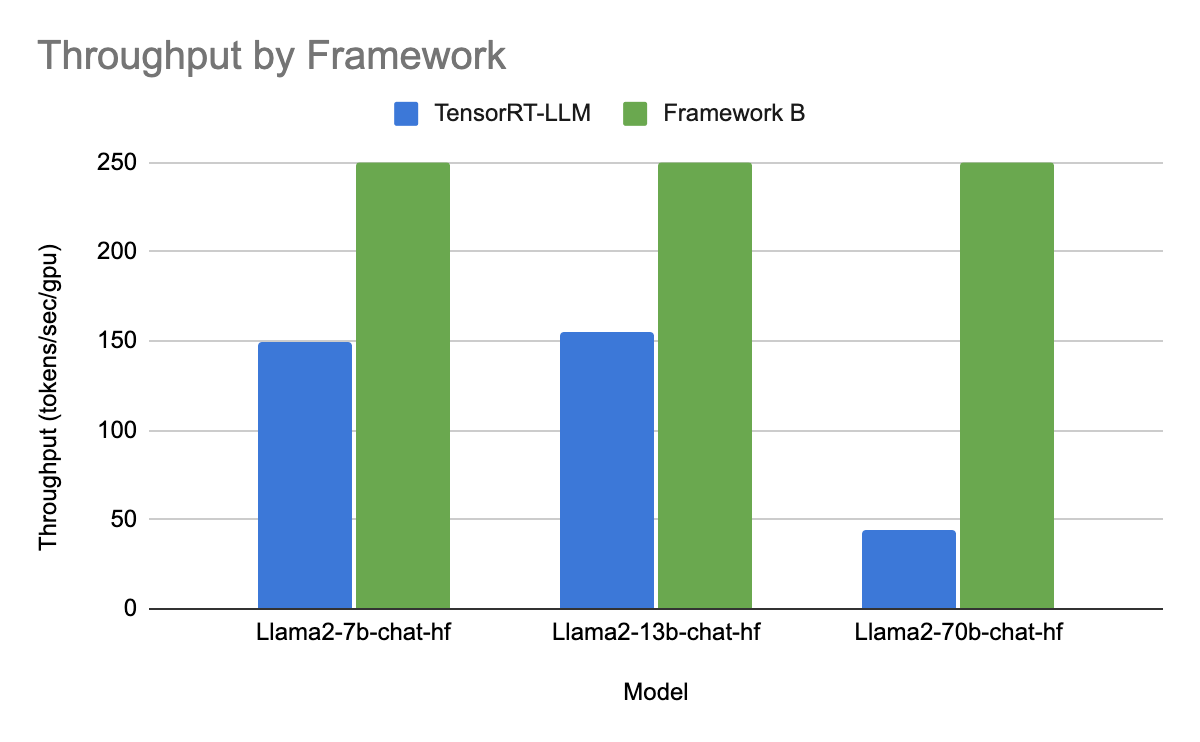
These experiment results clearly demonstrate that Framework B delivers a two-fold increase in latency and a six-fold improvement in throughput compared to TRT-LLM. It further underscores the significance of HW/SW co-design and that to fully leverage hardware capabilities, it is essential to have the right solutions across the entire stack.
LLM Training efficiency improvements with memory offload
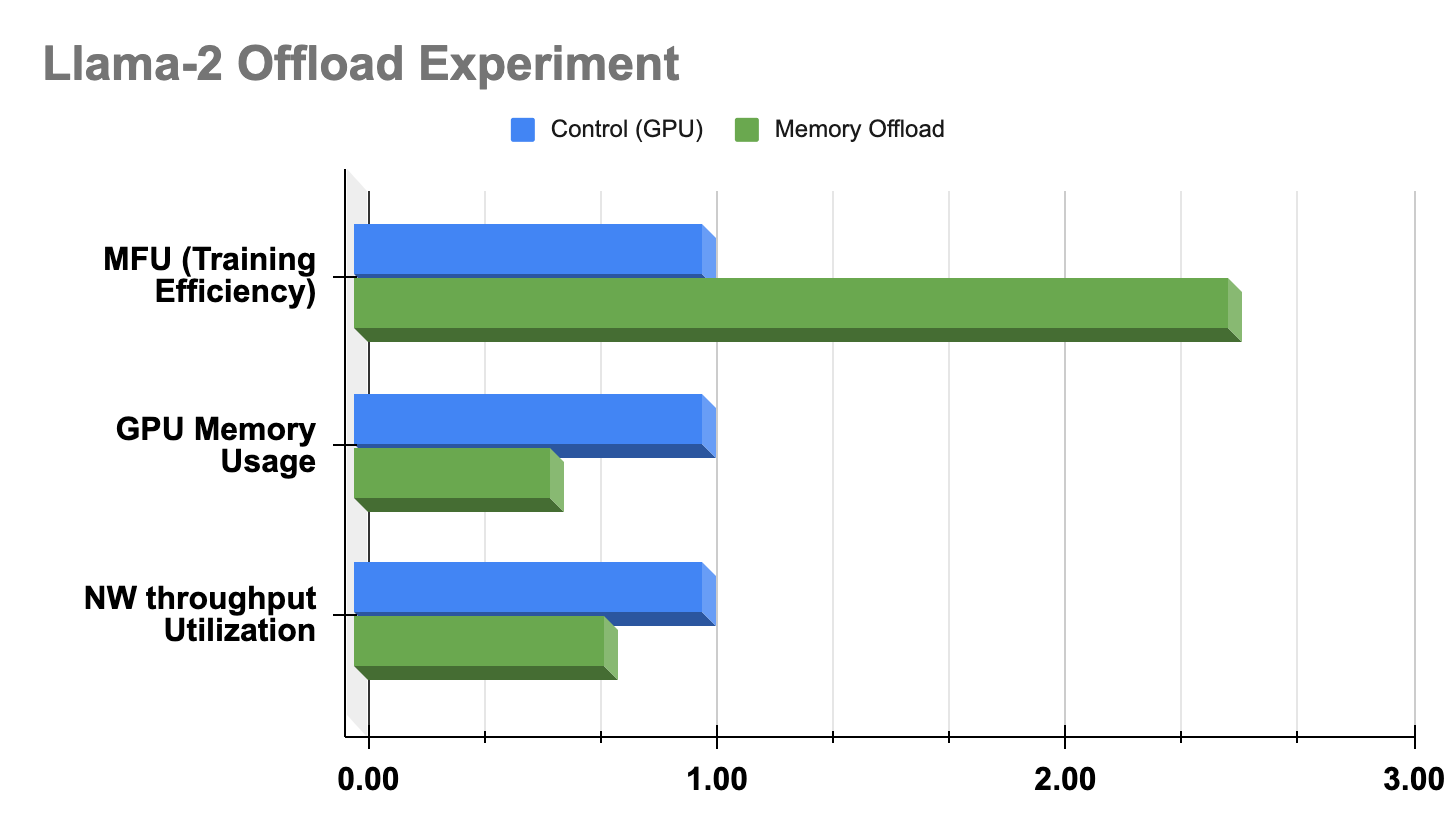
In this section, we outline our framework for design and experimentation regarding the placement of optimizer states, parameters and gradients from GPU memory to either CPU memory or NVMe devices for large language models. Our aim is to evaluate how this offload impacts GPU scalability, training efficiency, and a range of system metrics.

Our experiment results demonstrated that our capacity to train expansive models previously hindered by restricted GPU memory has been significantly enhanced. Memory offloading from GPU memory to system memory or even NVMe devices helped in boosting training efficiency by enabling the utilization of larger batch sizes with the same number of GPUs. This shift has resulted in a 2x increase in MFU (model flops utilization) while concurrently reducing GPU usage by 34%. However, it’s noteworthy that this improvement comes with a corresponding reduction in network throughput. A detailed open-computer project (OCP) conference talk on this topic can be found here.
Conclusion
To conclude, we’d like to leave you with three key insights. Designing a singular AI/ML system amid rapid application and model advancements, spanning from XGboost to deep learning recommendation models and large language models, poses considerable challenges. For instance, while LLMs demand high TFlops, deep learning models can encounter memory limitations. To enhance the cost-effectiveness of these systems, exploring workload-optimized solutions based on efficiency metrics like cost-to-serve and performance per dollar within a given SLA becomes imperative. Maximizing infrastructure efficiency necessitates a collaborative hardware and software design approach across all layers of the system. Within this context, we’ve showcased various examples in this post, illustrating how to leverage existing infrastructure effectively while building new capabilities to efficiently scale the infrastructure. Lastly, we extend an invitation to foster industry partnerships, urging engagement in open-source optimizations to drive efficiency and exchange ideas and learnings on effectively scaling infrastructure to tackle the evolving demands of the AI landscape.
Acknowledgments
Many thanks for the collaboration on the above work to the UBER AI Infrastructure, OCI, GCP, and Nvidia team members.
Apache®, Apache Kafka, Kafka, Apache Spark, Spark, and the star logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Kubernetes® and its logo are registered trademarks of The Linux Foundation® in the United States and other countries. No endorsement by The Linux Foundation is implied by the use of these marks.
Falcon 180B® and its logo are registered trademarks of Technology Innovation Institute™ in the United States and other countries. No endorsement by Technology Innovation Institute is implied by the use of these marks.
LLaMA 2® and its logo are registered trademarks of Meta® in the United States and other countries. No endorsement by Meta is implied by the use of these marks.

Nav Kankani
Nav is a Platform Architect on Uber's infrastructure team. He has been working in the areas of AI/ML, hyperscale cloud platforms, storage systems, and the semiconductor industry for the past 21 years. He earned a Master’s degree in electrical and computer engineering from the University of Arizona and an MBA from Hamline University. He is also named inventor on 21+ US patents.

Rush Tehrani
Rush is an Engineering Manager on the AI Platform Team at Uber. He supports the teams responsible for deployment and serving of classical, deep learning, and generative AI models, machine learning on mobile, and generative AI API gateway. Before joining Uber, he was the founder of Onepanel, an open source, Kubernetes native computer vision platform.

Anant Vyas
Anant Vyas is a Senior Staff Engineer and the Tech Lead of AI Infrastructure at Uber. His focus is on maximizing the performance and reliability of their extensive computing resources for training and serving.
Posted by Nav Kankani, Rush Tehrani, Anant Vyas
Related articles




Most popular

How Uber Migrated from Hive to Spark SQL for ETL Workloads

Automating Kerberos Keytab Rotation at Uber

The Evolution of Uber’s Search Platform
