Jupiter: Config Driven Adtech Batch Ingestion Platform
6 February 2024 / Global
Introduction
Uber’s mission is to reimagine the way the world moves for the better and provide earning opportunities globally through its marketplace. One effective approach to bring the Uber brand and marketplace closer to people is to invest in paid marketing strategies.
Achieving an optimal equilibrium in the marketplace necessitates the continuous activity of a balance between supply and demand. This requires creating an environment that is affordable for spenders while remaining a great earning opportunity for earners. One approach to accomplishing this goal is by consistently introducing new users to the marketplace, an ongoing process that involves promoting Uber’s marketplace offerings across diverse marketing platforms such as Google, Meta, Apple, and others.
Given that these are paid advertisements, our marketing teams continuously develop strategies to rapidly onboard more users to the platform. Therefore, receiving timely signals from these vendors is crucial for us to refine our approach effectively.
This blog post aims to explore the constraints and difficulties encountered by our legacy ingestion system, MaRS (Marketing Reporting Service), responsible for gathering ad signals from external ad partners at fixed intervals. Furthermore, we will address how we enhanced our marketing operations through technological advancements and attained scalability by implementing our new system, Jupiter.
In this blog, we have described paid marketing as a domain, while ad tech represents the systems within that same domain. These terms can be used interchangeably within this context.
What Is The Performance Marketing User Flow?
On a general scale, the subsequent sequence offers a thorough outline of the complete user journey: starting from engaging with the ads, navigating to the Uber platform, and culminating in a conversion. This action, valuable to our business, in our context could involve signing up on Uber, placing an order via Uber Eats, or taking a ride.
Following the aforementioned action, the subsequent events are triggered:
Conversion event: When a user clicks on the ad to download the Uber app, marking a conversion specific to that ad. This is one type of conversion event linked to downloading.
Spend event: When a user views an ad, signifying expenditure to display that ad to the user.
These spend events from the advertising partner need to be ingested, processed, and transmitted downstream. This is done to measure and optimize the ad’s performance.

Sample User Flow
- Step 1: The User Clicks on the Uber Ad on the Partner Page
- Step 2: The User Arrives on the Uber App [Conversion Events]
- Step 3: Adtech System Retrieves Data from Partner [Ingestion Platform]
- Step 4: Compute Performance Metrics (ROAS)
- Step 5: Optimization Engine enhances Bidding Algorithms by adjusting them according to computed Metrics.
Why Is Timely Ingestion Critical?
The prompt and precise ingestion of these advertising signals is crucial for Uber’s overall Performance Marketing. Even the smallest delay or inaccurate processing of timely ad signals from external partners can affect Uber’s capability to advertise on those platforms. As a result, this could influence the influx of users being onboarded onto the platform.
To illustrate, during an outage lasting two days in which we were unable to ingest data from a single partner, the creation of key performance indicators (KPIs), specifically ROAS, downstream was delayed. This delay led to our machine learning algorithms in the bidding and optimization systems erroneously concluding that our ads were underperforming, causing a halt in ad spending.
As a consequence, our ability to onboard new users was compromised, resulting in an imbalance in supply & demand. All this occurred due to an outage in one integration.
Problem Statement
As Uber operates across numerous countries worldwide, we engage with various local and global advertising partners or advertisers for our paid marketing efforts. This has resulted in the integration of multiple diverse technological systems at different levels of technological maturity, featuring heterogeneous data schemas, formats, varied transmission protocols, and discrepancies in data freshness, lineage, and completeness.
The AdTech industry is undergoing a substantial transformation where partners, Mobile Measurement Platforms (MMPs), and external ad tech platforms are transitioning from user-based ad-tracking to a spectrum of privacy-centric alternatives. This shift has given rise to a diverse ecosystem with varying standards among partners, introducing complexities such as frequent and unpredictable changes in data schemas that challenge historical assumptions in the marketing and advertising domain.
This complexity has presented a compounded challenge for the ingestion system due to its rapid evolution, scale, and the diverse nature of the datasets involved.
Here’s a breakdown of issue categories and the time dedicated by the ingestion team previously:

Reliability
As evident from the data, the predominant portion of time is dedicated to ensuring the reliability of the ingestion system. The primary factors contributing to this can be classified as follows:
High Latency
Ensuring prompt availability of data in the warehouse was essential for reducing our Mean Time to Detect (MTTD) anomalies and enhancing the overall performance of our ad tech systems.
Due to incomplete data or data latency issues, marketers struggled to distinguish between seasonality and actual ad performance.
No Partial Data Availability
As marketing data evolves with time (such as spend data exceeding 24 hours and conversions data extending beyond 28 days), it becomes highly important to provide partial data to downstream systems. This is especially crucial in cases where issues arise from the partner’s end at specific ad account levels. Given the frequency of such issues, having this capability could have prevented numerous data outages.
Enhancements in Technology Stack
The legacy systems MaRS was designed to be tightly coupled to older advertising formats/domains. Making minor improvements to MaRS used to result in extended engineering cycles or cause multiple technology regressions. Consequently, accommodating new use cases within the system resulted in its becoming unwieldy and difficult to manage.
Moreover, our outdated Python®-based technology stack was causing a slowdown. Taking advantage of this situation, we initiated an upgrade.
Third-Party Dependencies
Standardization
Out of our global and local ad partners, some have advanced APIs for data sharing. However, there are smaller partners who, due to their limited maturity, share data through more manual methods like email and SFTP, etc. Therefore, it is imperative that a single system be able to handle data ingestion from this diverse array of sources.
Moreover, the data formats and Service Level Agreements (SLAs) were not consistent among all partners. This lack of standardization posed challenges for maintenance. Consequently, it was necessary to establish uniform data standards across all partners for seamless consumption by downstream systems.
Rate Limits
Introducing new partner data, onboarding new data for an existing partner, or encountering a bug in the data processing layer, requires the ingestion system to import years of historical data (backfill). This process incurred significant latency, often taking multiple days to weeks, and it also impeded the normal flow of day-to-day pipelines, due to partner rate limiting.
High Maintenance
Sustaining partner-specific SDKs/APIs required substantial maintenance expenses, including dedicated headcount allocation, for frequent updates and bug fixes, which ultimately reduced developer productivity.
Scale
Huge Lead Time To Market
Due to a substantial backlog, we could only attend to the P0 marketing requests. The backlog primarily stemmed from the fact that onboarding a new partner used to take multiple weeks, hindering our capacity for swift experimentation.
For instance, in the case of an emerging partner, if we wanted to run ads on their platform, we would have to wait for several months before we had the resources to complete the onboarding process.
High Dependency on Eng
At present, the onboarding of any partner heavily relies on engineering resources to write boilerplate code for API integration, data transformation, validation, and testing. This consumes a significant portion of the onboarding process.
Solution Strategies
At first, MaRS was constructed with constraints tied to limited advertising spending. As Uber expanded globally, the demand for increasingly personalized marketing grew in both local and global markets. This necessitated a system that could swiftly adapt and incorporate specific nuances.
Marketers needed a swifter onboarding process for new partners in our measurement pipelines to facilitate experimentation. They also sought data at a higher frequency to accelerate results, enabling them to fine-tune marketing strategies accordingly.
Therefore, we developed a system to address gaps in the tech stack and accommodate future business requirements by employing a highly loosely coupled architecture.
Build vs. Buy
We conducted an assessment of external third-party vendors for ad signal ingestion rather than relying solely on in-house solutions. This was primarily to streamline maintenance costs.
Additionally, there was a strong business directive from the marketing team to gain greater flexibility and control over primary channels (the top channels with higher spending) like Google, Apple, and Meta.
As a result, we opted for a hybrid architecture that allows for a combination of external vendor data and direct in-house retrieval from partners. The decision on which approach to adopt during onboarding will be contingent on the business criticality of the integration.
Plug and Play Architecture
We had requirements to ingest data other than existing categories of data inside adtech for various internal use cases and many short-gap solutions have been built in silo. We needed to envision a single ingestion system that is ad hoc for data sets, and we needed to do it with ease as well as with minimum effort.
We incorporated plug-and-play architecture for all the components so any ingestion can change its internal component to something else with minimal effort.
Domain Agnostic Data Ingestion
In our pursuit of creating an inclusive ingestion system for a diverse range of data, we needed to separate domain-specific intricacies and enable configurability through a fully self-service, config-based architecture.
Reliability
Dealing with a diverse range of partners, our system had to handle numerous immature data formats, inconsistent SLAs, and unexpected scenarios. The sizes of these ad signals also varied significantly, spanning from several gigabytes to terabytes in specific cases. Jupiter was specifically designed to adeptly manage these varied scenarios in a resilient manner.
Architecture

Multi-Vendor Integration
We had various business scenarios requiring the integration of distinct data sets from different vendors into our platform. These integrations needed to account for specific factors such as data formats, ingestion frequencies, and data maturity levels.
Consequently, the platform was architected to accommodate any vendor for any of the data ingestion processes, allowing for seamless changes with minimal configuration.
Integrating a new vendor involves configuring its specific integration details, after which the rest of the platform will seamlessly connect with it.
Multi-Source Integrations
Given our interactions with numerous vendors, we naturally encountered diverse data sources that required ingestion. To address this, we implemented configurable data sources with their specific attributes defined through configuration. Just as with vendors, these data sources can be switched at any time with minimal configuration effort.
Currently, we have integrations with sources like Amazon Web Services, Google Drive, email, APIs, and more. The addition of a new source involves configuring its integration details, after which the rest of the platform will seamlessly adapt to it.
Non-Transformed Data Sets
In order to meet our business requirements, we found it necessary to ingest data over longer intervals without being constrained by partner capabilities. Additionally, our crucial need to swiftly detect any anomaly trends (MTTD) prompted us to implement a data copying process without applying any transformations.
This approach enabled us to expedite debugging for any issues and efficiently backfill data when necessary.
Config Driven Transformation Layer
Due to the various data schemas we manage, customized transformations were crucial for standardization.
A substantial part of the boilerplate code was dedicated to this particular component. To achieve a fully self-service ingestion system, we aimed to configure this component for each distinct use case.
Consequently, we developed an internal library for this transformation layer. This library incorporates user-defined transformations, ranging from row-to-row, and column-to-column, to aggregate transformations. We’ve leveraged this library across internal systems and similar use cases for reusability purposes. Attached is a sample configuration.

Self-Serve Ingestion Onboarding
We’ve optimized the entire onboarding process for the ingestion flow onto the platform, transitioning it into a self-service model with essential safeguards. This transformation involved implementing trigger-based mechanisms that operate seamlessly between all components, starting from fetching data from sources, initiating transformations, conducting tests, validating and promoting after all checks, and triggering post-validation procedures. Here’s the high-level flow attached for reference.
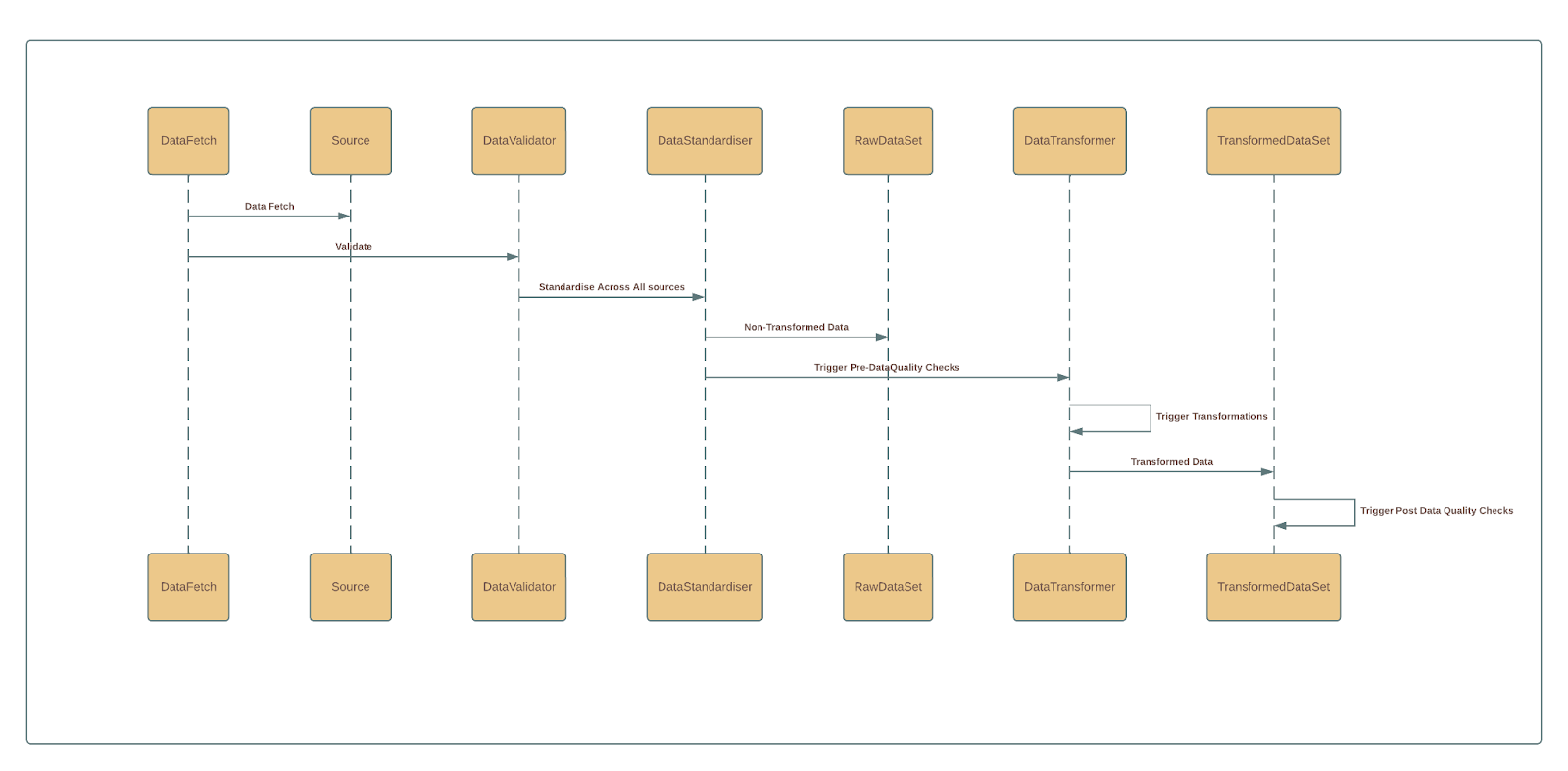
As a result of these improvements, the responsibility for this process has been transferred to the operations team, eliminating the necessity for continual engineering involvement.
Impact
At present, the prior system has been completely phased out and transitioned to Jupiter. Below, we present an overview of the metrics for both systems:
| Metric | Improvement % |
| Onboarding Time – New Ingestion | > 90% |
| Onboarding Time – New Vendor | > 75% |
| Onboarding Time – New Source | > 75% |
| Data Ingestion Frequency | > 75% |
| Data Ingestion Latency | > 70% |
Conclusion
We’ve outlined the difficulties and potential advantages linked with ad tech domain networks, along with the process of obtaining dependable data from them and implementing intricate transformations to address various business needs. At present, we’ve retired the previous system and transitioned all use cases to the new platform, incorporating fresh data enhancements wherever feasible.
We’ve successfully met our primary objective, accelerating the onboarding process for new partners and ensuring data reliability through a self-service approach for our stakeholders. However, there are still more intricate use cases to address. For instance, we’ve thus far focused on downloading a single report structure and applying transformations. Our next challenge is to download multiple structures, amalgamate them, and provide either a single or multiple datasets through a unified workflow. The next significant step is to expand this platform beyond its current specific-use-case support and transition it into a multi-tenant system.
Acknowledgments
We extend our special appreciation to both the core engineering and the product team, which includes Prathamesh Gabale (Engineering Manager), Akshit Jain (Software Engineer), Sarthak Chhillar (Software Engineer), Saurav Pradhan (Software Engineer), and Piyush Choudhary (Product Manager), for their pivotal roles in ensuring the success of this journey.
We would also like to express our gratitude to Devesh Kumar, Diwakar Bhatia, and Vijayasaradhi Uppaluri for their invaluable feedback and unwavering support.
Amazon Web Services, AWS, the Powered by AWS logo, and S3 are trademarks of Amazon.com, Inc. or its affiliates.

Barani Subramanian
Barani serves as the Technical Lead for the ad tech ingestion platform. She established the groundwork for the existing ingestion platform and devised a comprehensive long-term plan. Her main role involves comprehending business requirements and addressing stakeholder challenges, translating them into a tangible roadmap for the team to implement.

Manaswini Lakshmikanth Sugatoor
Manaswini served as the former Engineering Lead for the ad tech systems. She oversaw various sub-teams within the ad tech domain, including Ingestion, Sharing, Mobile, and Reliability Platforms. She spearheaded a transformative shift in the ad tech function, transitioning from a build-per-request model to a self-serve platform paradigm.
Posted by Barani Subramanian, Manaswini Lakshmikanth Sugatoor
Related articles





Most popular

Slashing CI Costs at Uber

How medical schools support the next generation of doctors with Uber

Uber’s Journey to Ray on Kubernetes: Ray Setup
