
Introduction
Apache HadoopⓇ Distributed File System (HDFS) is a distributed file system designed to store large files across multiple machines in a reliable and fault-tolerant manner. It is part of the Apache Hadoop framework and is one of the main components of Uber’s data stack.
Uber has one of the largest HDFS deployments in the world, with exabytes of data across tens of clusters. It is important, but also challenging, to keep scaling our data infrastructure with the balance between efficiency, service reliability, and high performance.
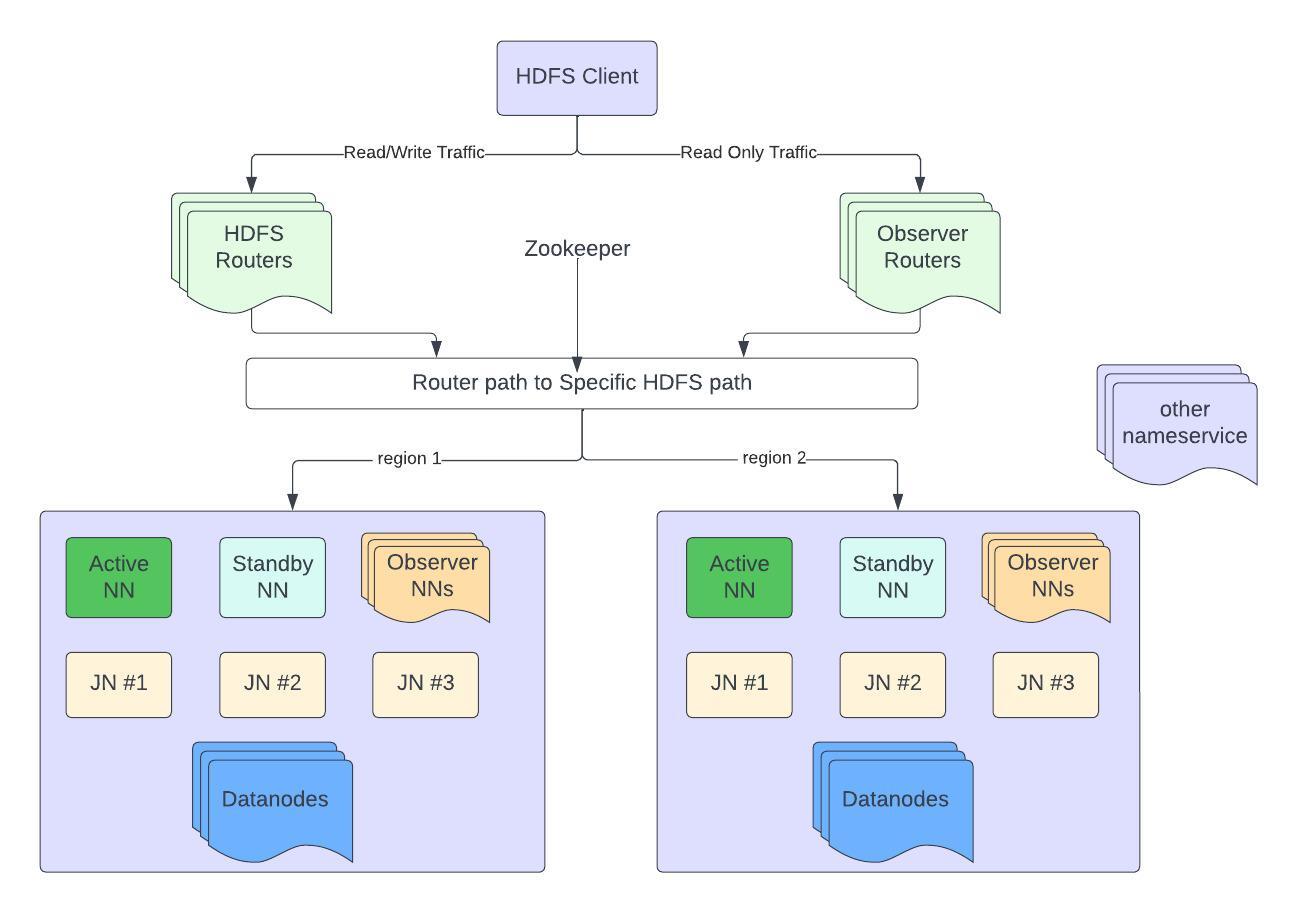
Figure 1: HDFS Infrastructure at Uber.
Overview
HDFS balancer is a key component to keep DataNodes healthy by redistributing data evenly in the cluster. The HDFS balancer has to balance data more effectively to prevent DataNode skew as our HDFS clusters have more and more intensive node decommissioning. The node decommission requirement comes from projects such as zone decommissioning, automatic cluster turnover for security patch, and also DataNode colocation.
However, the balancer that comes with HDFS open source did not meet this requirement out of the box. We have seen issues of one DataNode being skewed (i.e., storing more data compared to other nodes in the same cluster), which has multiple side effects:
- Leads to high I/O bandwidth on the host containing too much data
- Highly utilized nodes have a higher probability of slowness, higher risk of node failure, data loss
- Cluster has fewer active and healthy nodes to serve writing traffic for customers
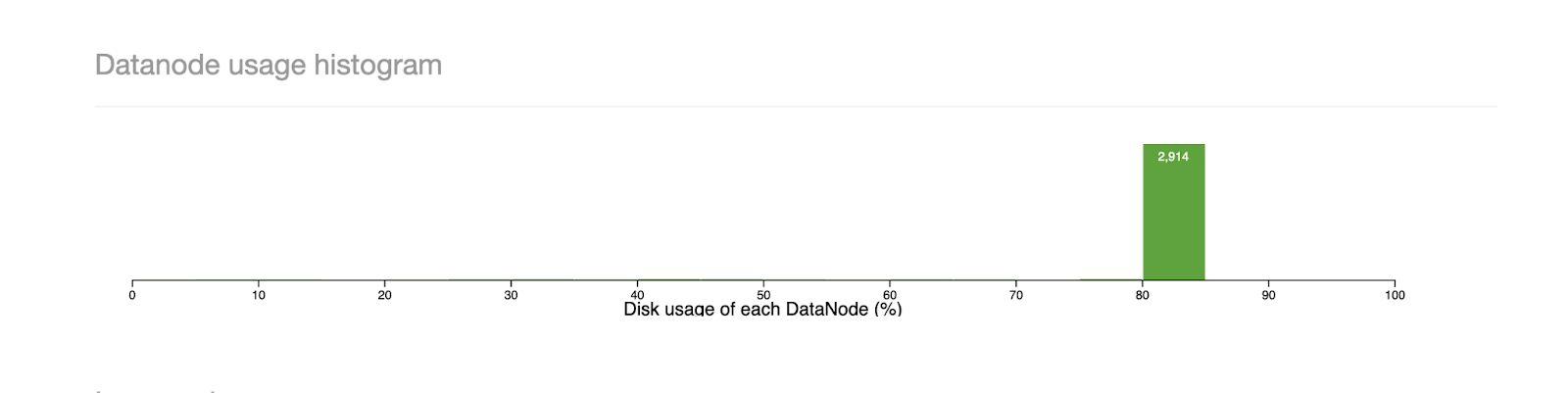
Below is an example of unbalanced data: thousands of nodes are near 95% disk utilization in our largest cluster composed of thousands of DataNodes with hundred PBs of capacity, while the balancing throughput can’t move data effectively to the other newly added DataNode. Such unbalanced data distribution is caused by bursty write traffic from warm tiering and EC conversion[1], intensive node decommission from zone decom/cluster turnover for security patch. As the write reliability is the first priority, all DataNodes serve write traffic together with an available capacity-weighted algorithm. With more write traffic, data skews more as well.

Thus, we need to optimize the HDFS balancer to increase the data balance from the high-usage DataNode to another, less occupied DataNode.
Given the scale of data storage at Uber, there would be more than 20 PB of data-unbalanced nodes in a single cluster, with 7-8 clusters. To tackle this problem of balancing HDFS DataNodes in the Uber DataLake, we devised a new algorithm to increase the number of pairs formed between DataNodes, which would increase parallel block movements while balancing data. Also, we did sort DataNodes based on utilization such that the datanode pairs formed are optimized and no recursive balancing takes place.
This algorithm would go on to increase our throughput for balancing i.e. size of data moved per second from a higher occupied datanode to a lower occupied datanode considered for balancing.
Architecture & Design
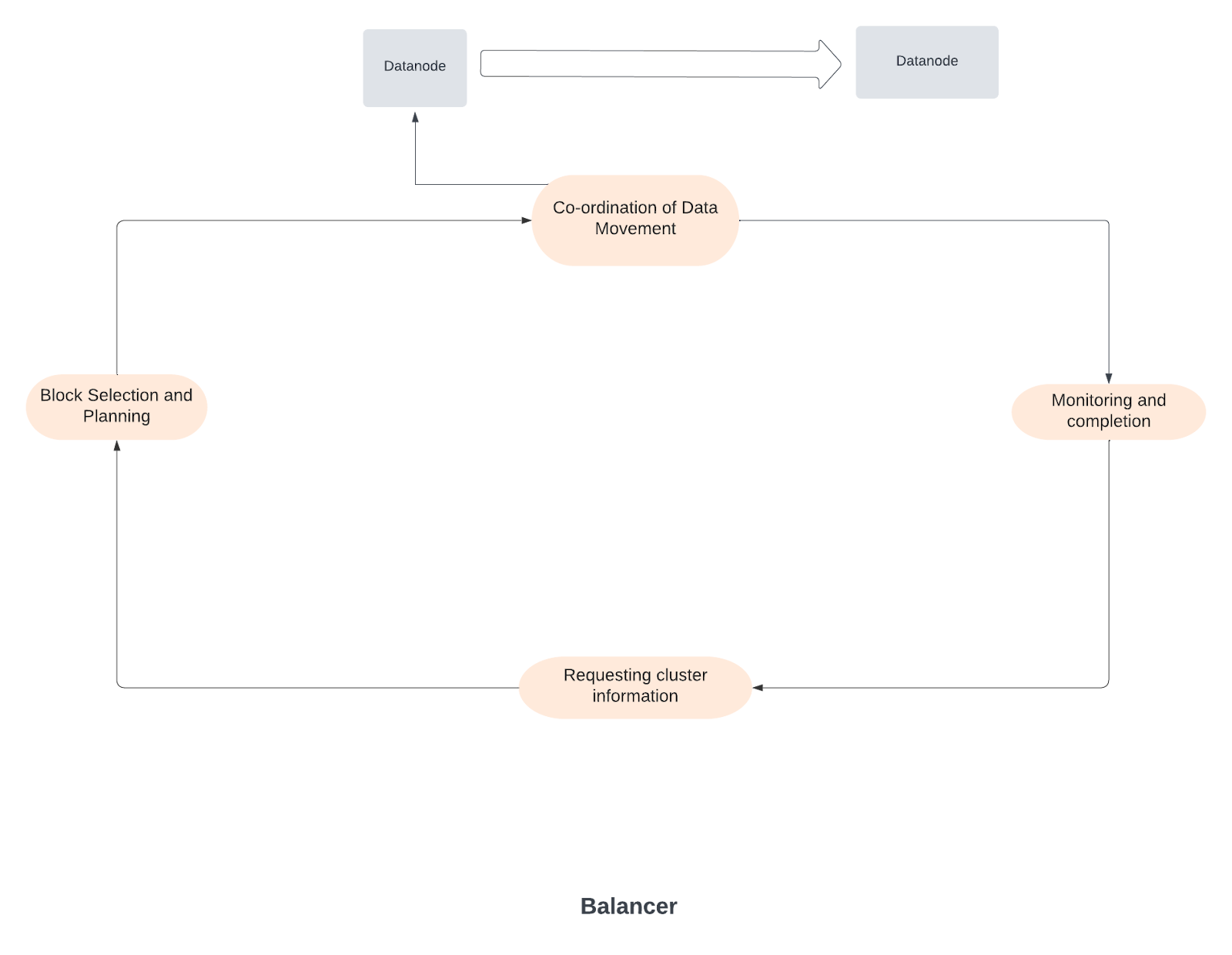
- Initialization and Setup:
- The HDFS balancer is run on a host as a service within the Hadoop cluster.
- To initiate the balancing process, a node with a balancer role needs to be present in the cluster. No two balancers can run concurrently.
- Requesting Cluster Information:
- The balancer first contacts the NameNode to request information about the data distribution within the cluster. It sends a request to the NameNode to obtain details about the distribution of data blocks across DataNodes.
- The NameNode responds with a list of DataNodes and the blocks they contain, along with their storage capacities and other relevant information.
- Block Selection and Planning:
- Based on the information received from the NameNode, the balancer algorithm selects blocks that need to be moved to achieve a more balanced distribution.
- The balancer takes into consideration factors such as DataNode utilization, rack information, threads, and storage capacity while planning block movements.
- Coordination of Data Movement:
- After determining which blocks to move, the balancer coordinates the actual data movement between DataNodes.
- It communicates with the NameNode regarding the blocks moved with the help of heartbeats.
- Block Migration:
- The balancer initiates block migration by communicating directly with the source and destination DataNodes.
- It instructs the source DataNode to transfer the selected block to the destination DataNode, moving the data block directly.
- Monitoring Progress:
- Throughout the data movement process, the balancer continuously monitors progress. It keeps track of how many blocks have been successfully transferred and ensures that the data movement is proceeding according to the plan.
- Completion and Reporting:
- Once the balancing operation is complete, the balancer reports the data transferred and data left to transfer in logs and through metrics.
- It may also provide statistics and metrics about the balancing process, including the number of blocks moved and the time taken.
- Termination:
- In the host, the balancer runs as a service. So, until the cluster is balanced, it won’t stop moving the data.
Initial Optimizations
Since we had the objective to increase the throughput to balance DataNodes at a greater speed to balance them faster, we optimized our HDFS balancers with the existing DataNode properties to increase the throughput.
Although we increased the speed of the balancer up to 3x, the throughput still wasn’t sufficient. We had too many highly occupied nodes and the number of DataNode pairs to which the data would be transferred in the existing algorithm would be significantly less. Also, we couldn’t improve the throughput from each node through balancer threads, as increasing it would increase the slowness of the node and affect read/write traffic. Thus, we needed to increase the number of DataNode pairs, which would ultimately lead to an increase in balancing throughput.
DataNode and Balancer Configs that we used are mentioned below. Configurations for your workloads may be different based on your situation.
DataNode configuration properties:
| Property | Default | Fast Mode |
| dfs.DataNode.balance.max.concurrent.moves | 5 | 250 |
| dfs.DataNode.balance.bandwidthPerSec | 1048576 (1MB) | 1073741824 (1GB) |
Balancer configuration properties:
| Property | Default | Fast Mode |
| dfs.DataNode.balance.max.concurrent.moves | 5 | 250 |
| dfs.balancer.moverThreads | 1000 | 2000 |
| dfs.balancer.max-size-to-move | 10737418240 (10GB) | 107374182400 (100GB) |
| dfs.balancer.getBlocks.min-block-size | 10485760 (10MB) | 104857600 (100MB) |
Algorithm Optimizations
Increasing DataNode pairs for high throughput
More DataNode pairs meant that we could have more concurrent block transmission, hence a key improvement is to construct more pairs. Due to the existing algorithm, a highly skewed cluster formed fewer DataNode pairs.

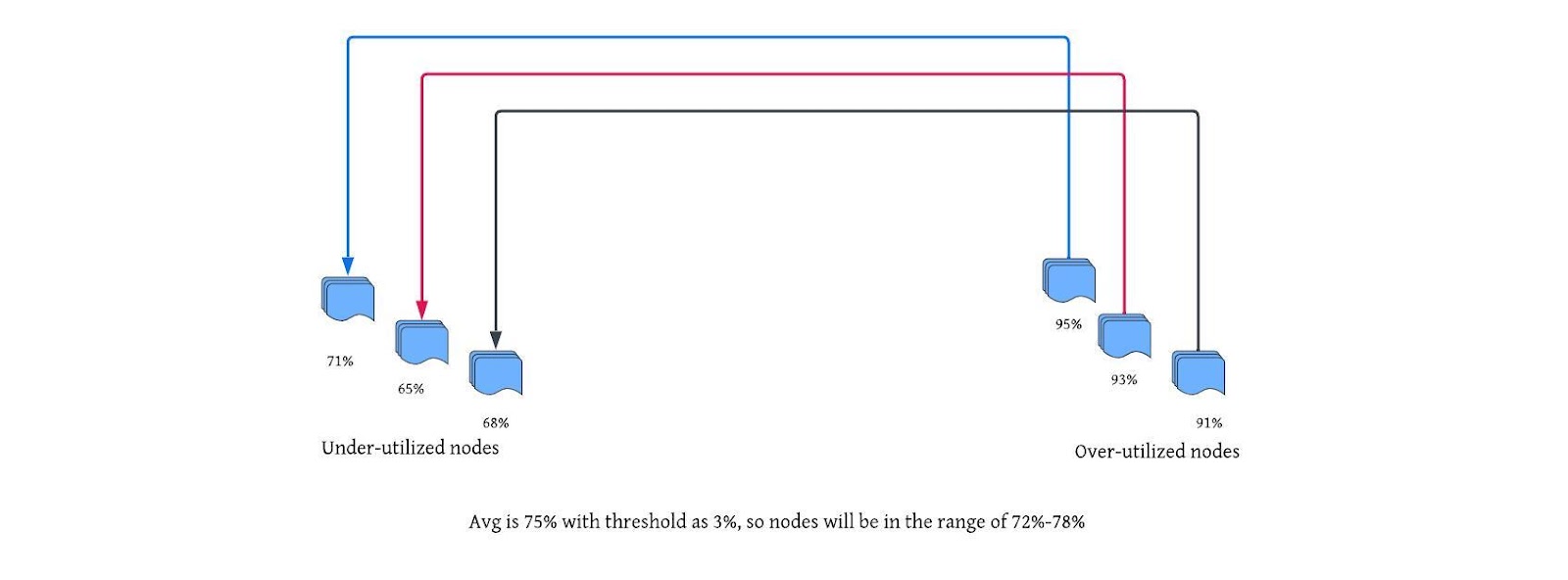
In the existing algorithm for HDFS Balancer, DataNodes above a cluster’s average utilization (i.e., above-average utilized and over-utilized nodes) had much higher numbers compared to below-average utilized and under-utilized nodes. Thus, we faced the problem of scarcity of the nodes to move the data from highly utilized DataNodes, which resulted in highly utilized DataNodes not coming down speedily.
In the above diagram, there are 8 DataNodes above average and 4 DataNodes below average utilization, which would lead to 4 targets where data could be moved.
The aim was to modify the HDFS algorithm such that more pairs are formed for DataNodes, thus leading to more throughput from high-usage DataNodes, resulting in uniform utilization as well as a speedy bump down of usage with more coverage of DataNodes.
Our idea was to use a percentile-based algorithm for creating more DataNode pairs.
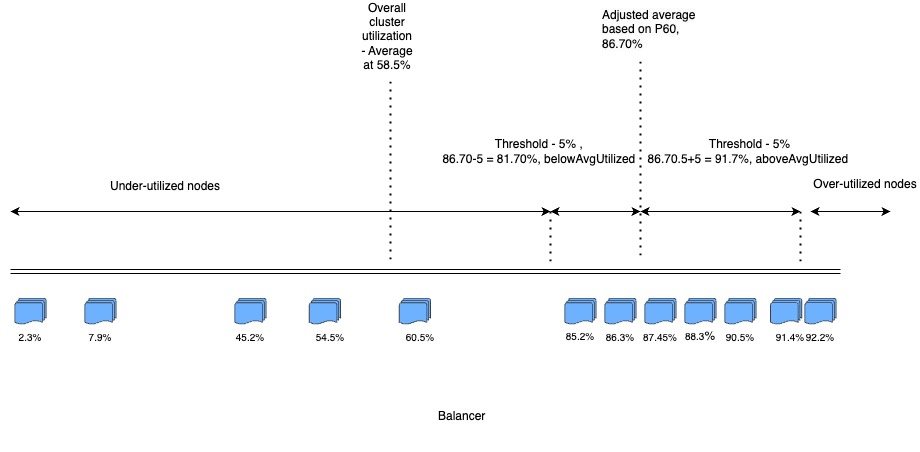
In the new algorithm, we created an adjusted average based on percentile, which would increase the number of nodes to which the data could be moved. Above average/over-utilized DataNodes would try to come near to overall cluster utilization, whereas under-utilized/below average utilized nodes would try to come near adjusted average of percentile. With a percentile-based algorithm, we would aim to bring our adjusted average near overall cluster utilization.
We would use a percentile-based algorithm to increase the DataNode pairs. In the highly skewed cluster, the percentile was quite high. Taking an example of the above diagram, we took percentile as P60, our adjusted average is now 86.7%. In this case, the count of over-utilized/above-average utilized nodes decreases, and under-utilized/under-average utilized nodes increase.
Now, there would be 5 over-utilized and above-average utilized nodes and 7 under-utilized and under-average nodes, which will lead to the formation of 7 pairs max from 4 pairs.
We had a new Hadoop configuration property, dfs.balancer.separate-percentile,
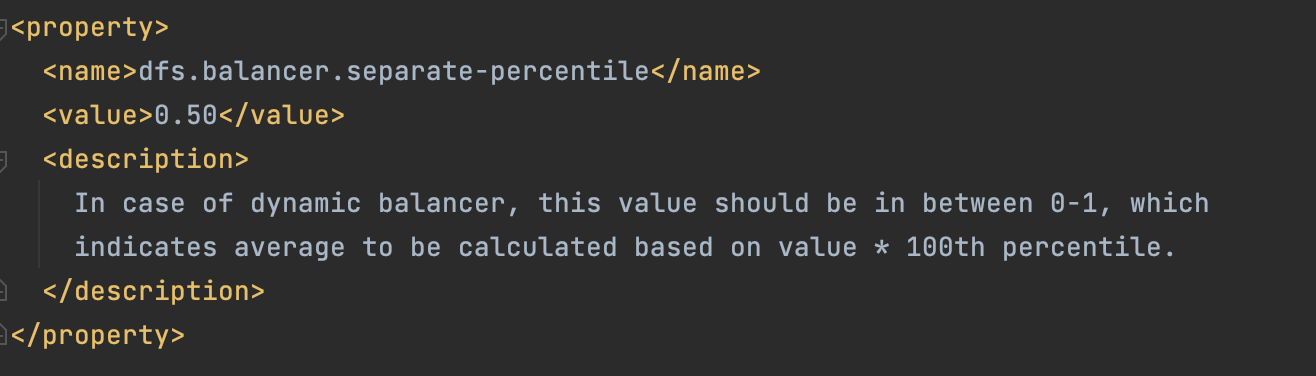
which was by default 0.5, denoting the 50th percentile. If we deployed the balancer command with -dynamicBalancer, this percentile algorithm would take effect and the adjusted average would come into the picture with more throughput.
We could also use this threshold to balance dynamically. For example, if DataNodes would go above 90%, we would balance them aggressively (i.e., with increased speed). Thus, we would balance the top 20% of DataNodes, which would lead to concentrating moverThreads on the top 20% of highly utilized sources, and data would move faster from highly utilized DataNodes and bring usage down faster.

Moving data to lower occupied DataNodes
Due to automation (i.e., automatic removal of data from DataNodes to other DataNodes to send it for maintenance), frequent decommission happened to DataNodes in a large cluster, in which data from a decommissioned node was moved to other nodes, increasing the occupied percentage on those nodes. The new nodes that came up got slowly balanced, as they were not given priority.
Also, for example, if average utilization was 83% with a threshold as 3% and the DataNode of 90% moved some part of its data to a 79% node which becomes 81%. Now if the new client dumped data at 81%, it became 87%, which may require further balancing of this node, thus distributing the dispatcher and mover threads.
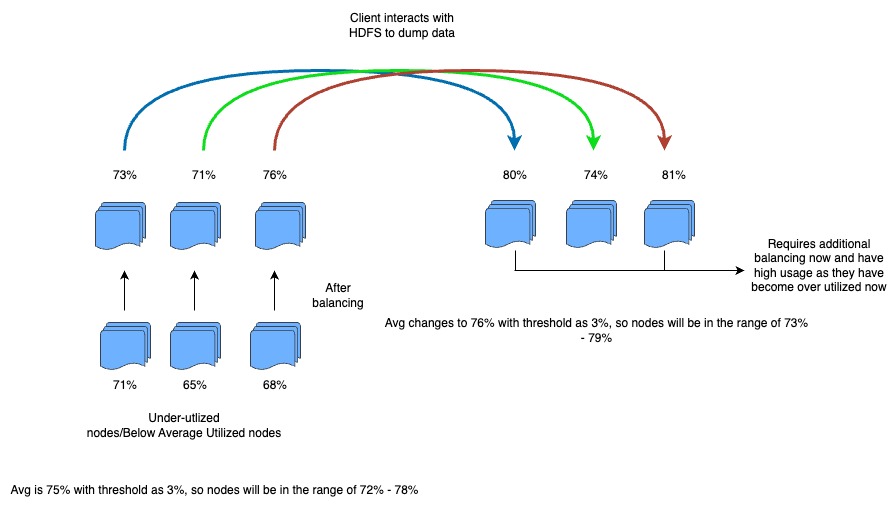
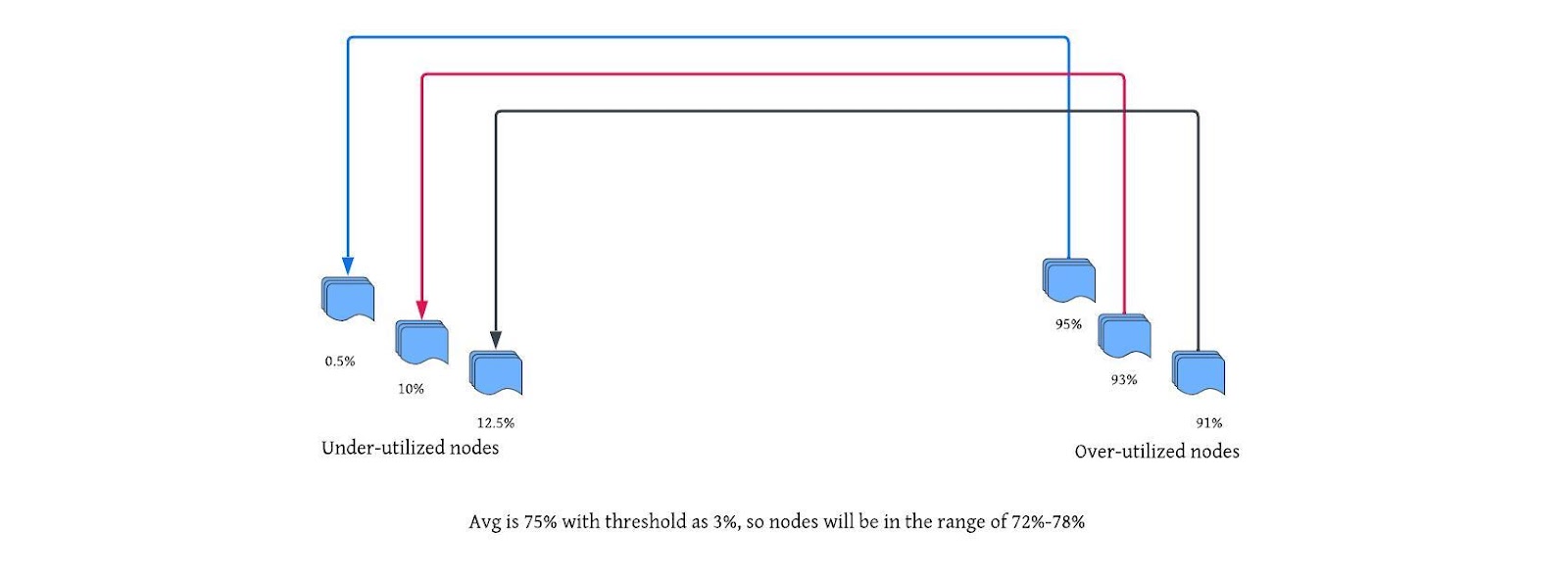
Our enhancement was to prioritize smaller occupied DataNodes by sorting in ascending order nodes in under-utilized nodes or below-average nodes, to balance the data first from over-utilized nodes, then above-average utilized nodes sorted in descending order, so that the nodes in between do not come into the picture, when balancing to prevent recursive balancing.
Better Observability
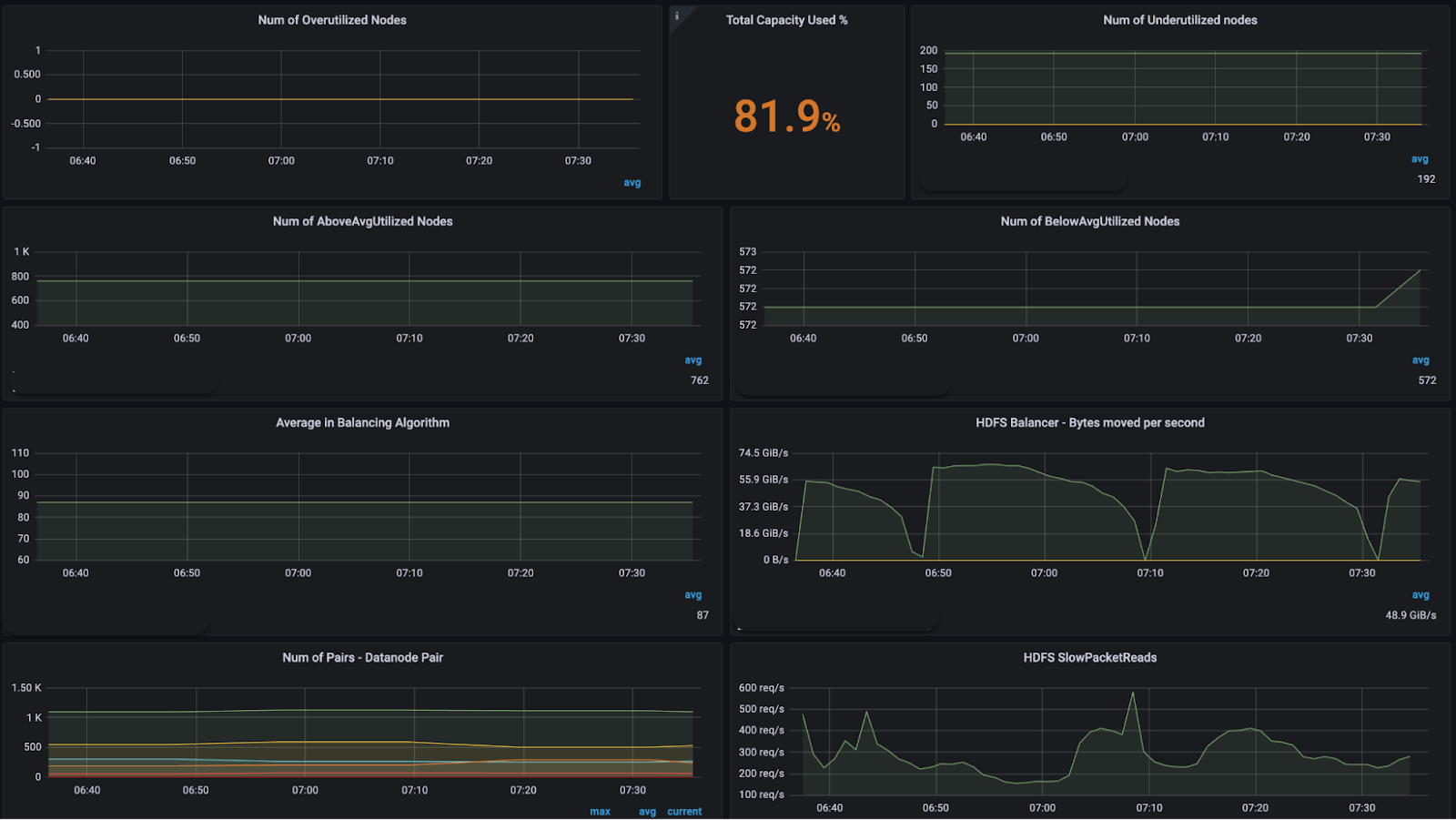
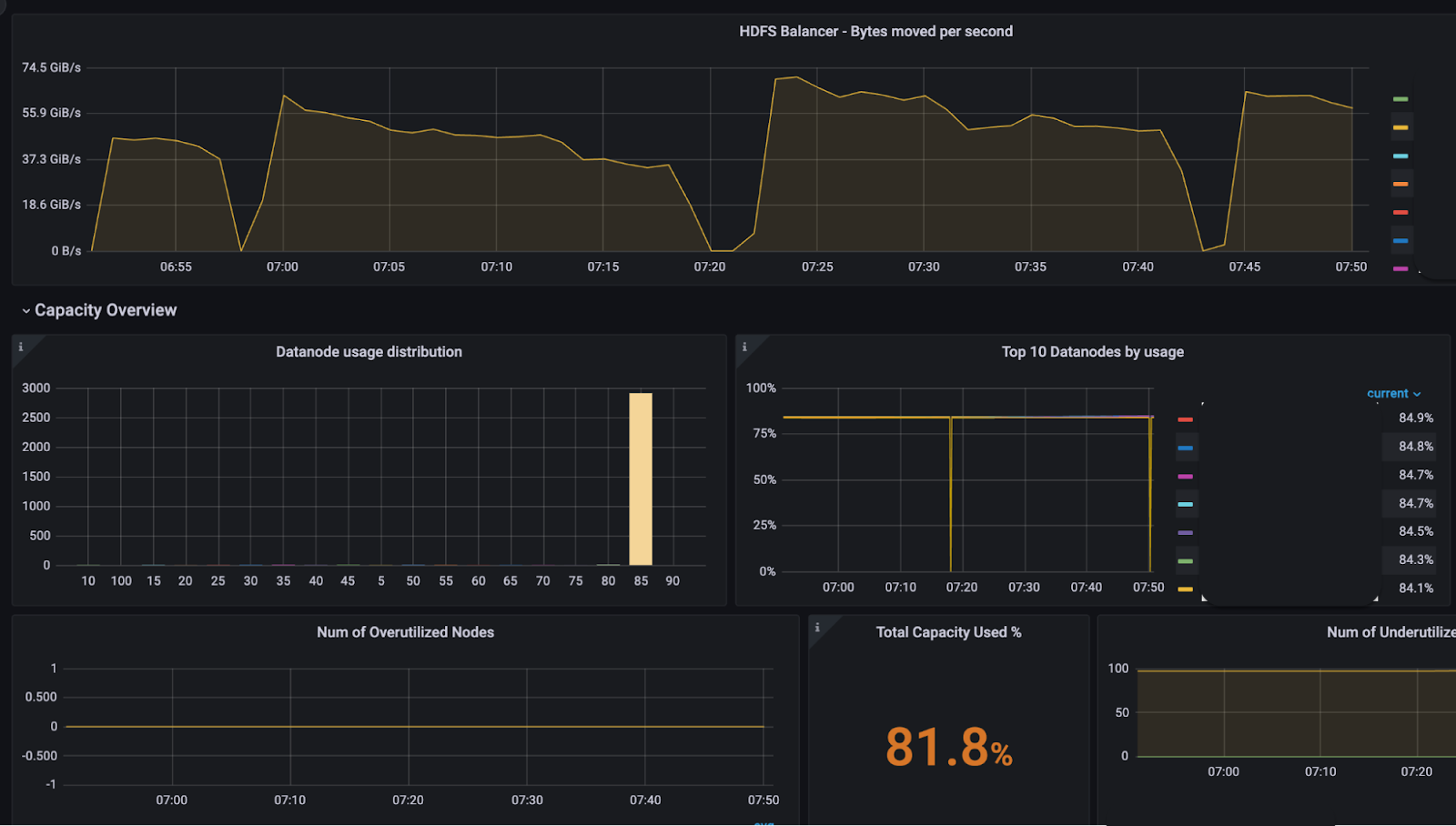
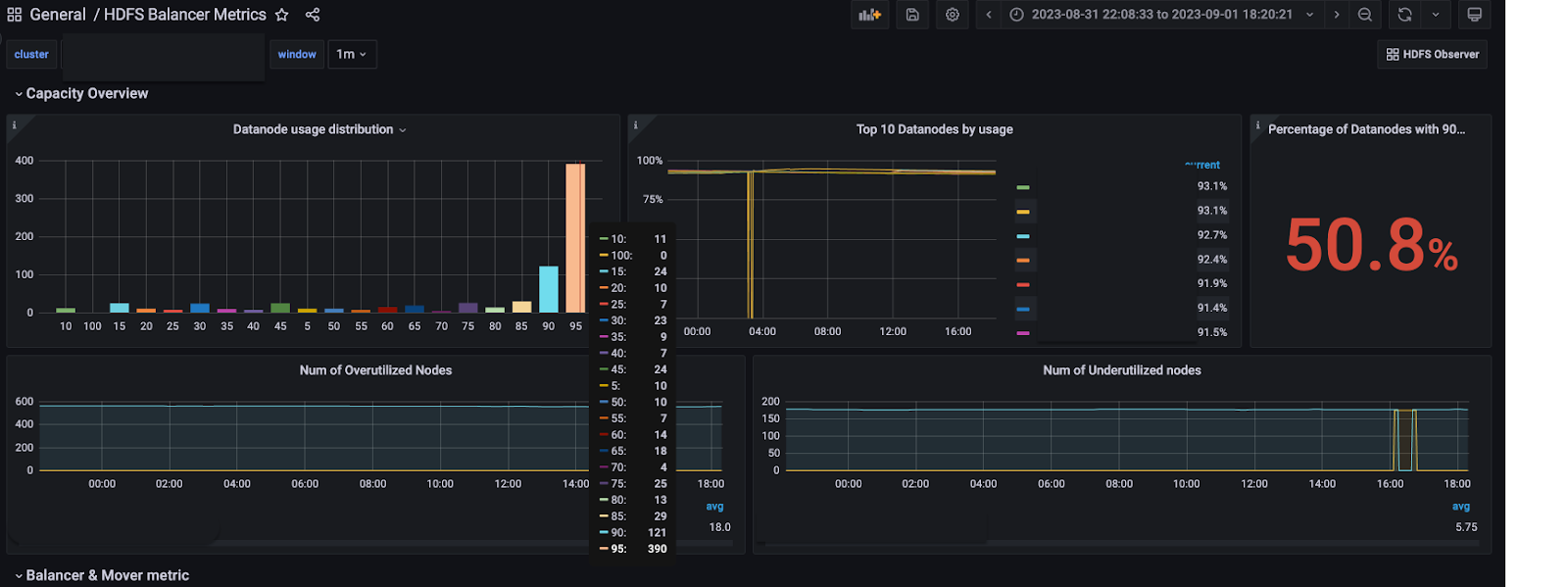
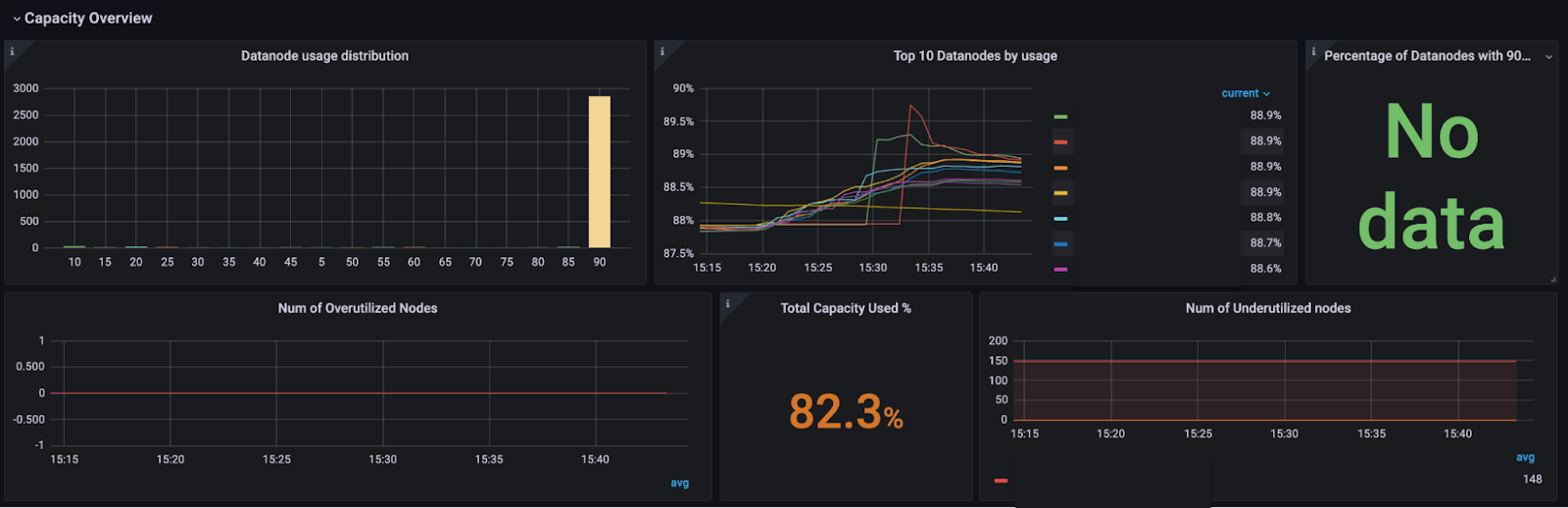
We didn’t have a metric on DataNode pairs that are formed between over-utilized and underutilized, overutilized and below-average utilized and underutilized and above average utilized between the same node group, same rack, and any other rack and other relevant metrics. Hence, we weren’t able to calibrate the traffic distribution between these pairs. In order to find out where the DataNode pairs could be increased to increase the throughput, we created a new dashboard.
In the end, we added more than 10 metrics to track the performance of our change in algorithm, which would help us calibrate custom algorithms for the balancer more.
Results
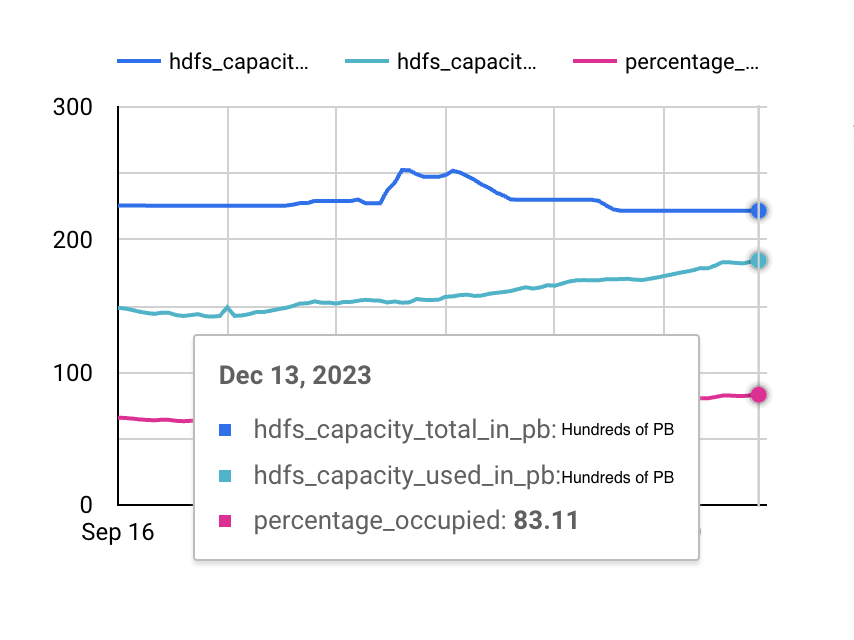
With optimizations in the balancing algorithm, we increased the throughput by more than 5x, with no DataNodes with higher utilization than 90%, as well as brought down the usage of the DataNodes overall. Also, there is now no need to deploy a manual balancer that took only certain hardcoded nodes to balance the data, as our optimization in the algorithm took care of that.
As part of our new algorithm –
- Increased throughput – We increased the throughput by more than 5x.
- Bringing down highly used datanodes – We brought down DataNodes above 90% utilization to 0.
- DataNodes around same utilization – Reduce overall usage of datanodes and bring them around the same capacity. We had all the DataNodes below 85% utilization for our biggest cluster.
- Manage the capacity better – Our cluster utilization increased from 65-66% to around 85% for HDFS clusters, with us having capacity bottlenecks. We now had no highly occupied datanode even though the cluster utilization was higher than ever.


Conclusion
In an HDFS cluster, data could get skewed among different DataNodes and could lead to high I/O on the node, leading to it being slow or going down, causing data loss. The new algorithm would help in balancing the DataNodes faster to achieve greater efficiency, service reliability, and high performance while preventing a higher probability of slowness, higher risk of node failure, and data loss.
In Uber, we deployed this change to multiple clusters to increase the balancing throughput. We are raising an open-source patch for our optimizations. Uber HDFS team continues to work on solving similar data distribution problems – given our scale, even a small improvement can result in a huge gain.
[1] Uber keeps data with different access temperatures to dedicate clusters for better reliability and cost efficiency. We apply the warm tiering to move data from hot cluster to warm cluster and adopt EC conversion to move data to cluster with erasure coding feature, which saves 50% capacity.
“Apache®, Apache Hadoop®, and Hadoop®, are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.”

Atul Kaushik
Atul Kaushik is a Software Engineer II with the Data storage team at Uber. He has been working on optimizations related to DataNode balancing and developing HDFS Quota solutions for customers at Uber.

Yangjun Zhang
Yangjun is a Staff Software Engineer with the Data storage team at Uber. He has been working on the reliability, efficiency, and modernization improvement for the HDFS dataplane.
Posted by Atul Kaushik, Yangjun Zhang
Related articles


Most popular

Enhanced Agentic-RAG: What If Chatbots Could Deliver Near-Human Precision?

From Archival to Access: Config-Driven Data Pipelines

How Uber Migrated from Hive to Spark SQL for ETL Workloads
