18 results for "kafka" across all locations

Introduction to Kafka Tiered Storage at Uber
Kafka Tiered Storage, developed in collaboration with the Apache Kafka community, introduces the separation of storage and processing in brokers, significantly improving the scalability, reliability, and efficiency of Kafka clusters.

Securing Kafka® Infrastructure at Uber
Uber has one of the largest deployments of Apache Kafka® in the world. It empowers a large number of real-time workflows at Uber, including pub-sub message buses for passing event data from the rider and driver apps, as well as financial transaction events between the backend services.

Introducing uGroup: Uber’s Consumer Management Framework
Apache Kafka® is widely used across Uber’s multiple business lines.

Disaster Recovery for Multi-Region Kafka at Uber
Uber has one of the largest deployments of Apache Kafka in the world, processing trillions of messages and multiple petabytes of data per day.

Introducing Chaperone: How Uber Engineering Audits Apache Kafka End-to-End
Uber Engineering explains why and how we built Chaperone, our in-house auditing system for monitoring Kafka pipeline health.

uReplicator: Uber Engineering’s Robust Apache Kafka Replicator
Take a look into uReplicator, Uber’s open source solution for replicating Apache Kafka data in a robust and reliable manner.

Presto® on Apache Kafka® At Uber Scale
.
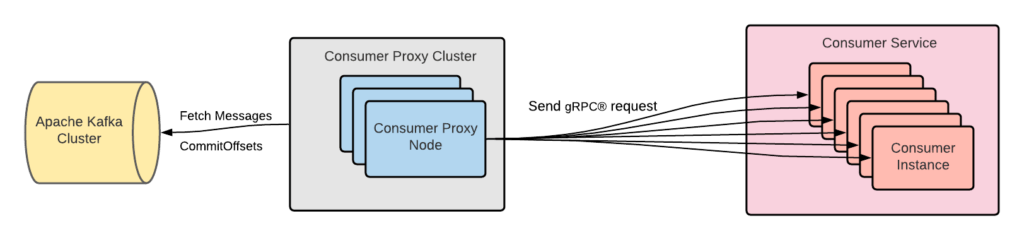
Enabling Seamless Kafka Async Queuing with Consumer Proxy

Building Reliable Reprocessing and Dead Letter Queues with Apache Kafka
The Uber Insurance Engineering team extended Kafka’s role in our existing event-driven architecture by using non-blocking request reprocessing and dead letter queues (DLQ) to achieve decoupled, observable error-handling without disrupting real-time traffic.

Avoiding CPU Throttling in a Containerized Environment
At Uber, all stateful workloads run on a common containerized platform across a large fleet of hosts. Stateful workloads include MySQL®, Apache Cassandra®, ElasticSearch®, Apache Kafka®, Apache HDFS™, Redis™, Docstore, Schemaless, etc., and in many cases these workloads are co-located on the same physical hosts.