
Apache Kafka at Uber
Uber has one of the largest deployments of Apache Kafka in the world, processing trillions of messages and multiple petabytes of data per day. As Figure 1 shows, today we position Apache Kafka as a cornerstone to Uber’s technology stack and build a complex ecosystem on top of it to empower a large number of different workflows. These include a pub/sub message bus to pass event data from the rider and driver apps, enabling a streaming analytics platform (e.g. Apache Samza, Apache Flink), streaming database changelogs to the downstream subscribers, and ingesting all sorts of data into Uber’s Apache Hadoop data lake.
There were many challenges that we overcame to provide a scalable, reliable, performant, and easy-to-use messaging platform on top of Apache Kafka. In this article, we highlight one challenge of recovering from disasters like cluster downtime, and describe how we build a multi–region Apache Kafka infrastructure at Uber.
Multi-region Kafka at Uber
Providing business resilience and continuity is a top priority to Uber. Disaster recovery plans are built carefully to minimize the business impact of natural and man-made disasters such as power outages, catastrophic software failures, and network outages. We employ a multi-region strategy that services are deployed with backup in geographically distributed data centers. When the physical infrastructure in one region is unavailable, the service can still stay up and running from other regions.
We architectured a multi-region Kafka setup to provide data redundancy for region-failover support. Many services in the Uber tech stack today depend on Kafka to support region-level failover. These services are downstream from the Kafka stream and assume data is available and reliable in Kafka.
Figure 2 depicts the architecture of multi-region Kafka. There are two types of clusters: producers publish messages locally to Region Clusters, and then the messages from regional clusters are replicated to Aggregate Clusters to provide a global view. For simplicity, Figure 2 shows only the clusters in two regions.

In each region, the producers always produce locally for better performance, and upon the unavailability of a Kafka cluster, the producer fails over to another region and produces to the regional cluster in that region.
A key piece in this architecture is message replication. The messages are replicated asynchronously from the regional cluster to the aggregation clusters across the regions. We built uReplicator, Uber’s open source solution for replicating Apache Kafka data in a robust and reliable manner. This system extends the original design of Kafka’s MirrorMaker to focus on extremely high reliability, a zero-data-loss guarantee, and ease of operation.
Consuming from multi-region Kafka clusters
Consuming from the multi-region is more complicated than producing. Multi-region Kafka supports two types of all-activeness.
Active/active consumption
A common type of consumption is active/active, where consumers consume the same topic in the aggregate clusters in each region independently. Today, many applications at Uber use active-active mode to consume from multi-region Kafka and do not directly communicate with their counterparts in other regions. When a region fails, they switch to the counterpart in another region if the Kafka stream is available in both regions and contains identical data.
For example, Figure 3 shows how Uber’s dynamic pricing service (i.e. surge pricing) uses active-active Kafka to build the disaster recovery plan. The price is calculated based on the trip events in recent history in the nearby area. All the trip events are sent over to the Kafka regional cluster and then aggregated into the aggregate clusters. Then in each region, a complex Flink job with a large-memory footprint computes the pricing for different areas. Next, an all-active service coordinates the update services in the regions and assigns one primary region to update. The update service from the primary region stores the pricing result in an active/active database for the quick lookup.

When disaster strikes the primary region, the active-active service assigns another region to be the primary, and the surge pricing calculation fails over to another region. It’s important to note that the computation state of the Flink job is too large to be synchronously replicated between regions, and therefore its state must be computed independently from the input messages from the aggregate clusters.
And a key insight from the practices is that offering reliable and multi-regional available infrastructure services like Kafka can greatly simplify the development of the business continuity plan for the applications. The application can store its state in the infrastructure layer and thus become stateless, leaving the complexity of state management, like synchronization and replication across regions, to the infrastructure services.
Active/passive consumers
Another multi-region consumption mode is active/passive: only one consumer (identified by a unique name) is allowed to consume from the aggregate clusters in one of the regions (i.e. the primary region) at a time. The multi-region Kafka tracks its consumption progress in the primary region, represented by the offset, and replicates the offset to other regions. So upon failure of the primary region, the active/passive mode allows the consumer to failover to another region and resume its consumption. Active/passive mode is commonly used by services that favor stronger consistency such as payment processing and auditing.
Active/passive mode poses a key challenge on offset synchronization of consumers among regions. When the consumer fails over to another region, it needs to take an offset to resume the progress. Because many services at Uber cannot accept any data loss, the consumer cannot resume from the high watermark (the latest messages), and to avoid too much backlog, neither can the consumer resume from the low watermark (the earliest messages). Moreover, messages from the aggregate clusters may become out of order after aggregating from the regional clusters. Messages are replicated from the regional cluster to the local aggregate cluster faster than the remote aggregate cluster due to the cross-region replication latency. As a result, the sequence of the messages in the aggregate clusters could be different. For example, in Figure 4a messages A1, A2, and B1, B2 are published to the regional clusters of Region A and Region B at about the same time, but after aggregation their order in the two aggregate clusters are different.
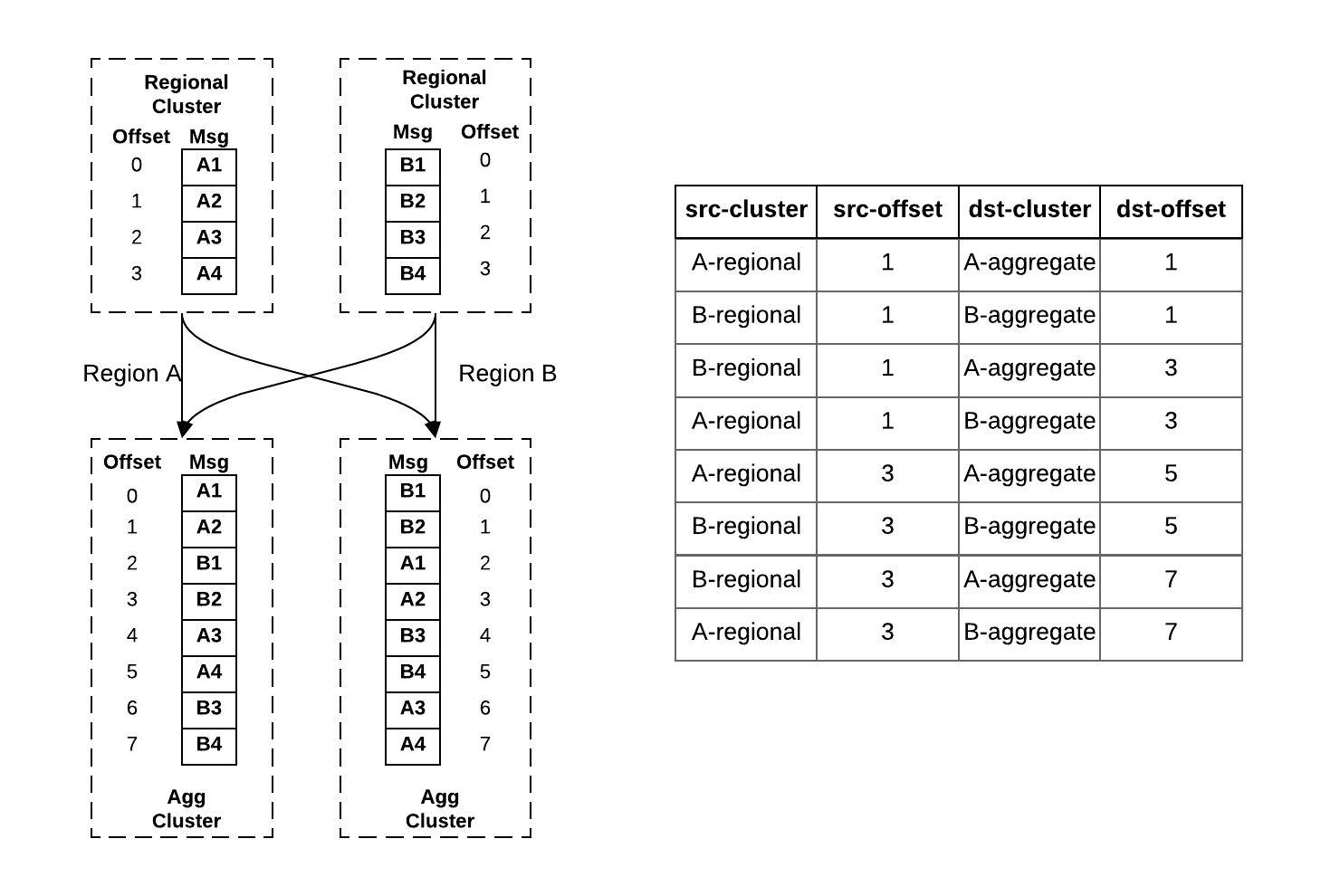
In order to manage such offset mappings across the regions, we developed a sophisticated offset management service at Uber. The architecture is shown in Figure 5. When uReplicator replicates messages from the source cluster to the destination cluster, it periodically checkpoints the offset mapping from source to destination. For example, the right side of Figure 4b shows the stored offset mappings of the message replication of the left side of Figure 4a. The first row of the table records that message A2 at offset 1 (0-indexed) in the regional cluster of Region A maps to the message A2 at offset 1 in the aggregate cluster of Region A. Similarly, the rest rows of the table record other checkpoints in the 4 replication routes.
The offset management stores these checkpoints in an active-active database, and it can use them to calculate the offset mapping of a given active-passive consumer. In the meanwhile, an offset sync job periodically synchronizes the offsets between the two regions for the active-passive consumers. When an active/passive consumer fails over from one region to another, the consumer can take the latest synced offset and resume the consumption.

The offset mapping algorithm works as follows: on the aggregate cluster of the active consumer, it finds all the latest checkpoints from the regional cluster of each region. Then, for the source offset in each checkpoint, find the checkpoints to the aggregate cluster in another region. Lastly, it takes the smallest offset of the checkpointed offsets in the aggregate cluster of the passive region.
In the example of Figure 6, assume the active consumer’s current progress is at offset 6 of message A3 in the aggregate cluster of Region B. According to the checkpointing table on the right, the two most recent checkpoints on the aggregate cluster are A2 at offset 3 (blue) and B4 at offset 5 (red), with the source of offset 1 (blue) in Region A’s regional cluster and offset 3 (red) in Region B’s regional cluster respectively. These source offsets map to the other aggregate cluster in Region A at offset 1 (blue) and offset 7 (red). By the algorithm, the passive consumer (black) shall take the smaller offset of the two, which is offset 1.

Since inception, the offset management service has been valuable for managing the offset mappings, not only for the consumer’s failover from one region to another but also for several other key use cases that we will talk about in future articles.
Conclusion
At Uber, business continuity depends on the efficient, uninterrupted flow of data across the services, and Apache Kafka plays a key role in the company’s disaster recovery plan. In this article, we briefly highlighted the overall architecture of the multi-region Apache Kafka setup at Uber and different failover strategies across regions when disasters strike. But there is more challenging work ahead of us, for now, solving the finer-grained recovery strategy that can tolerate a single cluster disaster without region failover. Sounds interesting? See our real-time data infrastructure openings on the Uber Careers page if you’re interested in participating in the next chapter of this story.
Acknowledgements
We would like to thank all the engineers who took time and effort for making the Kafka multi-region resilient at Uber.

Yupeng Fu
Yupeng Fu is a Principal Software Engineer on Uber’s Storage, Search, and Data (SSD) team, building scalable, reliable, and performant Search and Real-Time Data Platforms. Yupeng is a maintainer of the OpenSearch Project and a member of the OpenSearch Software Foundation Technical Steering Committee (TSC).

Mingmin Chen
Mingmin Chen is the Director of Engineering on Uber’s Storage, Search, and Data (SSD) team, leading Search and Real-Time Data Platforms.
Posted by Yupeng Fu, Mingmin Chen
Related articles





Most popular

Migrating Uber’s Compute Platform to Kubernetes: A Technical Journey

Teens get a month of free rides when they fail their driver’s test

Fixrleak: Fixing Java Resource Leaks with GenAI
