
At Uber, we pursue fundamental research to push the frontiers of machine learning, and we endeavor to reduce the latest ML advances to practice, both of which enable us to more effectively ignite opportunity by setting the world in motion.
We publish our research results to the broader scientific community. This year, Uber is presenting 11 papers at the NeurIPS 2019 conference in Vancouver, Canada! Additionally, we’re sponsoring NeurlPS workshops including Women in Machine Learning (WiML), Black in AI, and the Symposium on Advances in Approximate Bayesian Inference.
In this article, we categorize and briefly summarize each paper, showcasing Uber’s recent work across probabilistic modeling, Bayesian optimization, AI neuroscience, and neural network modeling.
Probabilistic modeling
Parameter elimination in particle Gibbs sampling
Anna Wigren (Uppsala University) · Riccardo Sven Risuleo (Uppsala University) · Lawrence Murray (Uber AI) · Fredrik Lindsten (Linköping University)
ArXiv
December 10 at 4:50 pm, West Ballroom C, NeurIPS Oral
December 10 at 5:30 pm, East Exhibition Hall B&C, Poster #157
Automation in probabilistic programming allows us to consider complex inference methods that may be difficult or error-prone to implement by hand. Just as automatic differentiation has greatly simplified the application of optimization algorithms, automation techniques in probabilistic programming, such as delayed sampling, promise the same for probabilistic algorithms. This work looks at a variety of particle Gibbs-style samplers for state-space models, and considers the possible gains that can be had when automatically marginalizing out the parameters using delayed sampling. For some particularly intricate methods, such as particle Gibbs with ancestor sampling, this marginalization would ordinarily result in quadratic complexity in the number of observations, but we demonstrate that linear complexity is achievable using computations involving the exponential family of distributions. Furthermore, we consider some blocking strategies to handle weakly-informative priors, and demonstrate the ideas on some applications in ecology and epidemiology.

Bayesian Learning of Sum-Product Networks
Martin Trapp (Graz University of Technology) · Robert Peharz (University of Cambridge) · Hong Ge (University of Cambridge) · Franz Pernkopf (Signal Processing and Speech Communication Laboratory, Graz, Austria) · Zoubin Ghahramani (Uber and University of Cambridge)
ArXiv
December 11 at 10:45 am, East Exhibition Hall B&C, Poster #185
Sum-product networks (SPNs) are flexible density estimators and have received significant attention due to their attractive inference properties. While parameter learning in SPNs is well developed, structure learning leaves something to be desired: even though there is a plethora of SPN structure learners, most of them are somewhat ad-hoc, and based on intuition rather than a clear learning principle. In this paper, we introduce a well-principled Bayesian framework for SPN structure learning. First, we decompose the problem into i) laying out a basic computational graph, and ii) learning the so-called scope function over the graph. The first is rather unproblematic and akin to neural network architecture validation. The second characterizes the effective structure of the SPN and needs to respect the usual structural constraints in SPN, i.e., completeness and decomposability. While representing and learning the scope function is rather involved in general, in this paper, we propose a natural parametrization for an important and widely used special case of SPNs. These structural parameters are incorporated into a Bayesian model, such that simultaneous structure and parameter learning is cast into monolithic Bayesian posterior inference. In various experiments, our Bayesian SPNs often improve test likelihoods over greedy SPN learners. Further, since the Bayesian framework protects against overfitting, we are able to evaluate hyper-parameters directly on the Bayesian model score, waiving the need for a separate validation set, which is especially beneficial in low data regimes. Bayesian SPNs can be applied to heterogeneous domains and can easily be extended to nonparametric formulations. Moreover, our Bayesian approach is the first which consistently and robustly learns SPN structures under missing data.

Exact Gaussian Processes on a Million Data Points
Ke Wang (Cornell University) · Geoff Pleiss (Cornell University) · Jacob Gardner (Uber AI) · Stephen Tyree (NVIDIA) · Kilian Weinberger (Cornell University / ASAPP Research) · Andrew Gordon Wilson (New York University)
Associated research code
December 11 at 5:00 pm, East Exhibition Hall B&C, Poster #169
In our paper, we demonstrate that training exact Gaussian processes using iterative methods like conjugate gradients (Gardner et al., 2018) can be extended to allow for training on large-scale data without approximate inference techniques. Typically, it is assumed that approximate inference is required to train GPs with more than a few thousand training examples (Hensman et al. 2013). We demonstrate that it is possible to scale to millions of training examples by leveraging efficient kernel matrix multiplication routines and parallelism across multiple GPUs. This allows us to perform the first-ever comparison of exact GPs against state-of-the-art approximation methods, and we find that exact GPs demonstrate dramatically improved performance. This is joint work with authors from Cornell University and NVIDIA.

Bayesian optimization and experimental design
Variational Bayesian Optimal Experimental Design
Adam Foster (University of Oxford) · Martin Jankowiak (Uber AI) · Eli Bingham (Uber AI) · Paul Horsfall (Uber AI) · Yee Whye Teh (University of Oxford, DeepMind) · Tom Rainforth (University of Oxford) · Noah Goodman (Uber AI / Stanford University)
Pyro Bayesian Optimal Experimental Design Tutorial, arXiv, docs
December 10 at 4:40 pm, West Ballroom C, NeurIPS Spotlight talk
December 10 at 5:30 pm, East Exhibition Hall B&C, Poster #173
In order to learn about the world, we conduct experiments; for instance, we carry out election polls, analyze blood samples, or test airplane wings in wind tunnels. These sorts of real world experiments are expensive, and it can be difficult to design experiments that are informative. Bayesian optimal experimental design is a principled framework for designing informative experiments and making efficient use of limited experimental resources. Unfortunately, its applicability is hampered by the difficulty of obtaining accurate estimates of the expected information gain (EIG), which is a numeric score used to rank the expected efficacy of different experimental designs. In this work we introduce several classes of fast EIG estimators by building on ideas from amortized variational inference. We show theoretically and empirically that these estimators can provide significant gains in speed and accuracy over previous approaches. We further demonstrate the practicality of our approach on a number of end-to-end experiments.

Scalable Global Optimization via Local Bayesian Optimization
David Eriksson (Uber AI) · Michael Pearce (Uber AI intern / Warwick University) · Jacob Gardner (Uber AI) · Ryan Turner (Uber AI) · Matthias Poloczek (Uber AI)
ArXiv
December 10 at 4:25 pm, West Ballroom C, NeurIPS Spotlight Talk
December 10 at 5:30 pm, East Exhibition Hall B&C, Poster #9
Bayesian optimization (BO) has recently emerged as a successful technique for the global optimization of black-box functions. Popular applications include tuning the hyperparameters of machine learning models; tuning the reactants and processing conditions in materials discovery; and learning a controller in robotics. BO is typically limited to a small number of tunable parameters and a small budget of function evaluations. In this work, we propose the TuRBO algorithm, a technique that overcomes these limitations by 1) a tailored local surrogate model that achieves a good fit even for heterogeneous functions and 2) a novel approach to choosing points for evaluation that trades off exploration and exploitation better for high-dimensional functions. We provide a comprehensive experimental evaluation of TuRBO and show that it outperforms the state-of-the-art from machine learning, operations research, and evolutionary strategies. TuRBO scales to tens of thousands of evaluations and achieves better solutions on benchmarks from reinforcement learning, robotics, and the natural sciences.
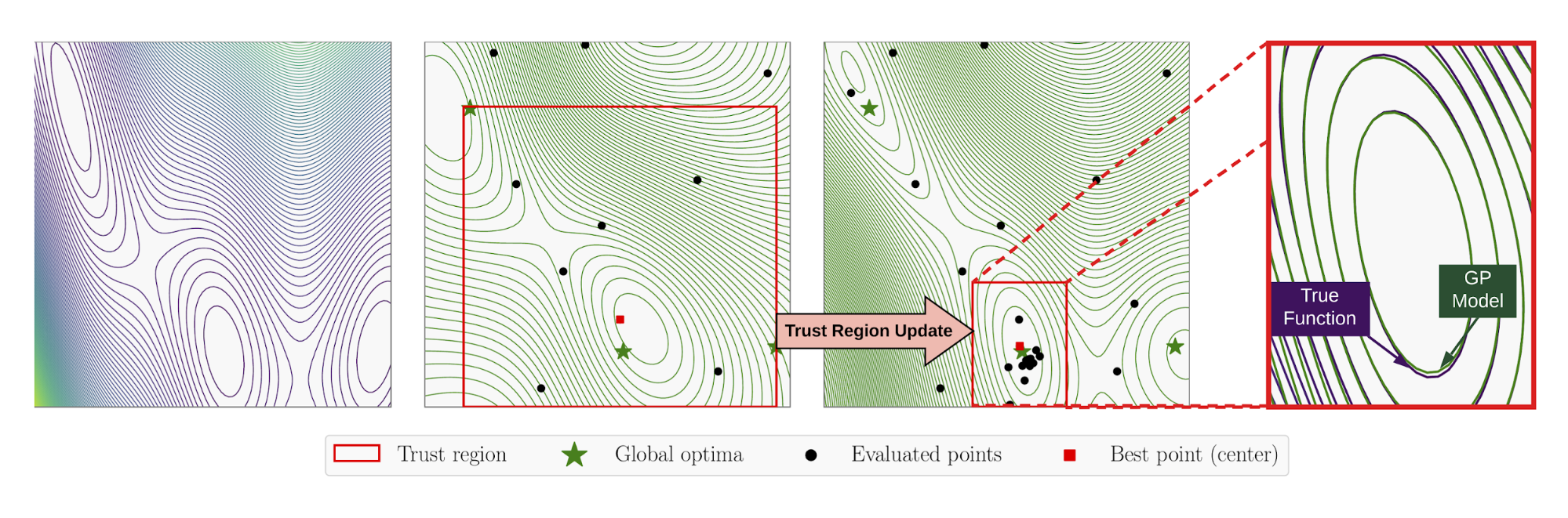
Practical Two-Step Lookahead Bayesian Optimization
Jian Wu (Cornell University) · Peter Frazier (Cornell / Uber)
December 12 at 10:45 am, East Exhibition Hall B&C, Poster #33
Bayesian optimization (BO) uses machine learning to optimize objective functions that are time-consuming to evaluate and is often used to tune hyperparameters for deep neural networks. BO decides where to evaluate the objective using a so-called “acquisition function,” which quantifies how likely an evaluation is to reveal a good solution and how useful it is toward reaching the overall optimization goal. Historically, most acquisition functions are myopic: they assume the current evaluation will be the last, even if it won’t be in practice. As a result, they may not perform as well as might be possible with a more sophisticated approach. More recent non-myopic BO methods try to perform better by looking multiple steps ahead. While promising in theory, this requires an enormous amount of computation, making these methods impractical. This paper provides a new way to look two steps ahead that is fast enough to be used in practice, providing what is arguably the first practical implementation of non-myopic Bayesian optimization.

AI neuroscience
Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask
Hattie Zhou (Uber) · Janice Lan (Uber AI) · Rosanne Liu (Uber AI) · Jason Yosinski (Uber AI)
Blog article, arXiv, associated research code
December 10 at 10:45 am, East Exhibition Hall B&C, Poster #111
Modern neural networks can contain millions or billions of parameters, and pruning is popular way of decreasing the size of these networks. The recent “Lottery Ticket Hypothesis” paper by Frankle & Carbin showed that a simple pruning procedure (setting weights with small final magnitudes to zero) creates sparse networks that are trainable from scratch, but only when starting from the same initial weights. These lottery ticket (LT) networks often exceed the performance of the non-sparse base model, but for reasons that were not well-understood. In this paper, we unearth some aspects of why LT networks perform as well as they do. We show why setting weights to zero is important, how only signs are needed to make the reinitialized network train, and why masking behaves like training. Finally, we discover the existence of Supermasks, which are masks that can be applied to an untrained, randomly initialized network to produce a model with performance far better than chance (86 percent on MNIST and 41 percent on CIFAR-10, respectively).

LCA: Loss Change Allocation for Neural Network Training
Janice Lan (Uber AI) · Rosanne Liu (Uber AI) · Hattie Zhou (Uber) · Jason Yosinski (Uber AI)
Blog post, arXiv, associated research code
December 10 at 5:30 pm, East Exhibition Hall B&C, Poster #99
Neural network training is a complex process, but the only thing we typically use to monitor this process is a single number: the scalar loss. In this paper, in order to better understand training, we measure how much each parameter of the model contributes to the decrease (or increase) of loss at each iteration. We call this measure Loss Change Allocation (LCA), which can be described as how much a parameter helps or hurts training. LCA can be summed up over neurons, layers, or time to reveal broader patterns. We provide three examples of insights that LCA can reveal. First, training is noisier than at least we expected, with (for example) only 50.7 percent of the parameters in a ResNet-50 helping decrease the loss on any given iteration. Second, sometimes entire layers move in total against the training gradient, due to momentum and layer-layer interactions. Finally, we observe directly that micro-increments to learning occur in a synchronous way across layers, with multiple layers learning concepts on exactly the same iteration as each other.

Neural network modeling
Efficient Graph Generation with Graph Recurrent Attention Networks
Renjie Liao (Uber ATG / U. Toronto / Vector) · Yujia Li (Deepmind) · Yang Song (Stanford) · Shenlong Wang (Uber ATG / U. Toronto / Vector) · William L. Hamilton (McGill / MILA) · David Duvenaud (U. Toronto / Vector) · Raquel Urtasun (Uber ATG / U. Toronto / Vector) · Richard S. Zemel (U. Toronto / Vector)
December 10 at 10:45 am, East Exhibition Hall B&C, Poster #124
We propose a new family of efficient and expressive deep generative models of graphs, called Graph Recurrent Attention Networks (GRANs). Our model generates graphs one block of nodes and associated edges at a time, conditioned on the graph generated so far. The block size and sampling stride allow us to trade-off sample quality for efficiency. Compared to previous recurrent neural network (RNN)-based graph generative models, our framework better captures the auto-regressive conditioning between the already generated and to be generated parts of the graph using graph neural networks (GNNs) with attention. This not only reduces the dependency on node ordering, but also bypasses the unnecessary long-range bottleneck that comes with the sequential nature of RNNs. Moreover, we parameterize the output distribution per block of nodes and edges using a mixture model, which provides an efficient way to capture the correlations among generated edges. Finally, we propose a solution to handle node orderings in generation by marginalizing over a family of canonical orderings. On standard benchmarks, we achieve the state-of-the-art time efficiency and sample quality compared to previous models. Additionally, we show our model is capable of generating large, high quality graphs of up to 5,000 nodes. To the best of our knowledge, GRAN is the first deep graph generative model that can scale to this size.

Incremental Few-Shot Learning with Attention Attractor Networks
Mengye Ren (Uber ATG / U. Toronto / Vector) · Renjie Liao (Uber ATG / U. Toronto / Vector) · Ethan Fetaya (U. Toronto / Vector) · Richard S. Zemel (U. Toronto / Vector)
ArXiv, associated research code
December 11 at 5:00 pm, East Exhibition Hall B&C, Poster #20
Machine learning classifiers are often trained to recognize a set of predefined classes. However, in many real applications, it is often desirable to have the flexibility of learning additional concepts, without retraining on the full training set. This paper addresses this problem, which we refer to as incremental few-shot learning, where a regular classification network has already been trained to recognize a set of base classes and several extra novel classes are being considered, each with only a few labeled examples. After learning the novel classes, the model is then evaluated on the overall performance of both base and novel classes. To this end, we propose a meta-learning model, the Attention Attractor Network, which regularizes the learning of novel classes. In each episode, we train a set of new weights to recognize novel classes until they converge, and we show that the technique of recurrent back-propagation can back-propagate through the optimization process and facilitate the learning of the attractor network regularizer. We demonstrate that the learned attractor network can recognize novel classes while remembering old classes without the need to review the original training set, outperforming baselines that do not rely on an iterative optimization process.

Hamiltonian Neural Networks
Sam Greydanus (Google Brain) · Misko Dzamba (Petcube) · Jason Yosinski (Uber AI)
Blog article, arXiv, associated research code
December 12 at 5:00 pm, East Exhibition Hall B&C, Poster #67
Even though neural networks enjoy widespread use, they still struggle to learn the basic laws of physics. How might we guide them in the direction of being better at modeling physical systems? In this paper, we propose Hamiltonian Neural Networks, or HNNs, which draw inspiration from Hamiltonian mechanics to train models that learn and respect exact conservation laws in an unsupervised manner. We evaluate our models on problems where conservation of energy is important, like on a gravitational two-body problem and on pixel observations of a pendulum swinging back and forth. Our tests show that HNNs train faster and generalize better than a regular neural network in cases where quantities like energy are conserved. Since HNNs learn a notion of “total energy,” we can also easily simulate directly adding or removing total energy from the system.

Conclusions
If the research described above interests you, be sure to attend our talks, chat with us at our posters, or meet us at Booth #223 (Sunday – Wednesday) at NeurIPS 2019. For additional information about our talks and posters, check out the Uber NeurIPS 2019 site.
Interested in the ML research that Uber AI, Uber ATG, and other teams are working on? Check out other Uber research publications or apply for a machine learning role at Uber.
Acknowledgments
The authors would like to thank David Eriksson, Peter Frazier, Jacob Gardner, Zoubin Ghahramani, Sam Greydanus, Martin Jankowiak, Lawrence Murray, Renjie Liao, Mengye Ren, Raquel Urtasun, Janice Lan, Hattie Zhou, and Rosanne Liu for providing short summaries of their works. The header image background is “Vancouver city skyline at dawn” by Flickr user armenws.

Matthias Poloczek
Matthias Poloczek leads the Bayesian optimization team at Uber AI. His team focuses on fundamental research and its applications at the intersection of machine learning and optimization.
Posted by Matthias Poloczek, Molly Spaeth







