How Uber Migrated Financial Data from DynamoDB to Docstore
November 10, 2021 / Global
Introduction
Each day, Uber moves millions of people around the world and delivers tens of millions of food and grocery orders. This generates a large number of financial transactions that need to be stored with provable completeness, consistency, and compliance.
LedgerStore is an immutable, ledger-style database storing business transactions. LedgerStore provides signing/sealing of data to guarantee data completeness/correctness, strongly consistent indexes, and automatic data tiering. LedgerStore uses DynamoDB as its storage backend. Running LedgerStore in production for almost 2 years at Uber scale, we’d amassed a large amount of data as trips and orders volume grew. Over this period of time we realized that operating LedgerStore with DynamoDB as a backend was becoming expensive. Also having different databases in our portfolio creates fragmentation and makes it difficult to operate.
Having first-hand experience building large scale storage systems at Uber, we decided to change the LedgerStore backend to be one of our in-house, homegrown databases. The 2 main principles we kept in mind were: 1) Efficiency, and 2) Technology consolidation. Following the first would yield us great results in the short term, while the second would put us on a solid long-term roadmap, having greater flexibility and operational ease.
In this post today we are going to talk about rearchitecting some of the core components of LedgerStore on top of Docstore, Uber’s general-purpose multi-model database.
What is LedgerStore?
LedgerStore was introduced in 2018 to support Gulfstream, Uber’s fifth-generation collection and disbursement payment platform, in order to provide the following data integrity guarantees:
- Individual records are immutable
- Corrections are trackable
- Unauthorized data changes and inconsistencies must be detected
- Queries are reproducible a bounded time after write
LedgerStore abstracts away the underlying storage technologies, in order to support switching technologies as business needs arise. Along with that it provides both consistent and time-partitioned indexes, and queries. The first version of LedgerStore was built on top of AWS DynamoDB. For ledger-style storage use cases, it is often the case that data is mostly read within a few weeks or months of being written. Given that it is fairly expensive to store data in hot databases such as DynamoDB, resources can be saved by offloading data to colder storage after a time period. LedgerStore also provides data-tiering functionality out of the box in a transparent, secure, and efficient manner.
Data Model
LedgerStore is an append-only, ledger-style database. A datastore in LedgerStore is a collection of tables and each table contains a set of records modelled as documents.
Tables can have one or many indexes and an index belongs to exactly one table. Indexes in LedgerStore are strongly consistent, meaning that when a write to the main table succeeds, all indexes are updated at the same time using a 2-phase commit.
The following is an example schema of a LedgerStore table:

Data Integrity
Since LedgerStore stores long-term business transactions, data integrity and auditability are of utmost importance. LedgerStore introduced the concepts of Sealing, Manifests, and Revisions to ensure that.
Sealing
Sealing is the process of closing a time range for changes and maintaining signatures of the data within the sealed time ranges. Any query that only reads data from sealed time ranges is guaranteed to be reproducible and any unauthorized change to the data can be detected through background validation of the signatures generated at time of sealing.
Manifests
Manifests are generated by the sealing process and build the sealed, immutable sets of immutable records for a given time range. It consists of:
- A unique identifier of the manifest, composed of: (datastore, table, time range, revision)
- The time range for the manifest: [T0, T1]
- A list of records and their checksums within the time range
- A signature of all of the above signed with a public/private key pair
Signing the manifests protects against data tampering and ensures that only LedgerStore is able to write valid manifests. With the signature and content list, LedgerStore will be able to detect if any records have been changed/added/removed through an unauthorized channel. An application querying can obtain and store signed resources for future validations.
Revisions
To support correction of data in already-closed time ranges, LedgerStore uses the notion of Revisions. A revision is a table-level entity consisting of all record corrections and associated business justifications. All records, both corrected and the original, are maintained to allow reproducible queries. Queries can be executed at a specific revision to allow for tracking corrections.
For more a more in-depth look at LedgerStore’s architecture, please refer to our 2019 AWS re:Invent presentation LedgerStore – Uber Financial Scalable Storage Gateway
With this introduction of LedgerStore, now let’s look at LedgerStore 2.0 design.
LedgerStore 2.0 Design Considerations
The first design decision to make was the choice of database for the re-architecture. We needed our database to be:
- Reliable and operationally hardened
- Highly available—99.99% availability guarantees
- Can be easily scaled horizontally to accommodate growth in dataset size and read/write requests
- Features set: Change Data Capture (CDC) (a.k.a., streaming), secondary indexes, and flexible data model
Our homegrown Docstore was a perfect match for our database requirements, except for Change Data Capture (CDC) a.k.a., streaming functionality. LedgerStore uses streaming data for building its Manifests, which is a crucial part of ensuring end-to-end data completeness in the system. Reading data from stream as opposed to from the table directly is generally efficient, since you don’t have to perform table scans or range reads spawning a large number of rows. It is cheaper to read data from the stream, since the stream data can be stored in cheaper commodity hardware. Finally it is also faster to read data from the stream, since data can be stored in a system like Apache Kafka® optimized for stream reading. In LedgerStore we also wanted to avoid potential bugs in the write path and ensure data written to the table is the same as what we read from the stream.
We decided to build a streaming framework for Docstore (project name “Flux”) and used that for LedgerStore’s Manifest generation. Along with Flux, we were able to leverage our core in-house infrastructure components such as Kafka to be fully platform independent.
After choosing Docstore as our storage backend, the second set of design considerations were around data and traffic migration, such as:
- Zero customer involvement—our stakeholders must not be involved or exposed to the migration (e.g., changing service logic, client code, or routing)
- High Availability—no down time during migration
- Maintaining 100% Read-Your-Writes data consistency
- Maintaining pre-existing performance SLOs, such as latency
- Ability to switch back and forth between databases as an emergency measure
Migration of this scale while maintaining strict SLAs around consistency, availability, and transparency is challenging. Our short-term goal was to achieve cost efficiency, so rearchitecting the entire system in one go was not an option. We decided to break down the project based on the individual component’s migration complexity and what we would gain from each. After careful consideration, we decided to divide the project into two phases: 1) Re-architect core online read/write of ledgers a.k.a records, and 2) Re-architect system metadata and indexes. Since records contributed to 75% of our storage footprint and cost, phase 1 would give us desired cost efficiency.
Architecture
Docstore Table Design
The first step for re-architecture is to design the data model for our records tables on Docstore. Docstore supports a large number of native data types, as well as documents naturally. This greatly reduced complexity in designing our data-modeling on Docstore.
Our DynamoDB data model was agnostic to the user primary key as we always used to marshal the user primary key into {pk string, sk string}. However while re-architecting on Docstore we decided to exactly map the user defined primary key to Docstore table, so that we can pass the complex conditions directly to Docstore. This further simplified our query logic in LedgerStore as depicted in Figure 1:
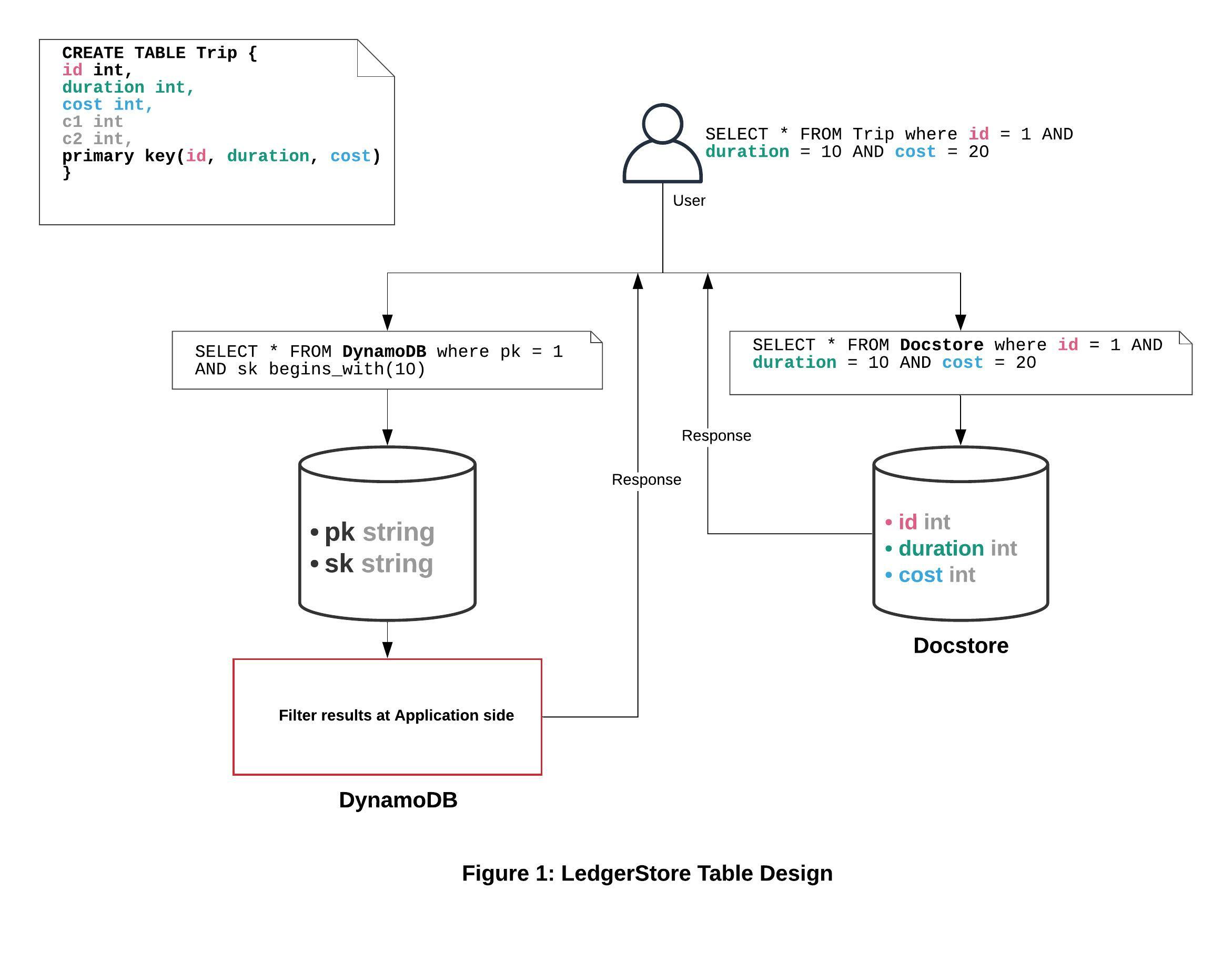
Data Sealing
To ensure data integrity, LedgerStore divides incoming writes into different time range buckets known as sealing windows. A typical sealing window spans 30 minutes (T1, T1+30 minutes). When a sealing window is closed, signed, and sealed, no further updates to it will be permitted. Any query that only reads data from a sealed window is guaranteed to be reproducible.
Furthermore, LedgerStore performs a multi-pass verification of the data to ensure integrity. The inserted data is first read from the local region (R1) and a checksum (C1) is generated. It also tails the database stream in that same region and calculates another checksum (C2). For data to be consistent within a region from LedgerStore’s point of view, C1 and C2 have to match.
Now, the same checksum matching process is repeated in the remote region (R2) by creating checksums C3 and C4, respectively. A sealing window is only considered closed if all 4 checksums (C1, C2, C3, C4) across 2 regions match. Any future addition/modification to the data in that sealing windows will be rejected.
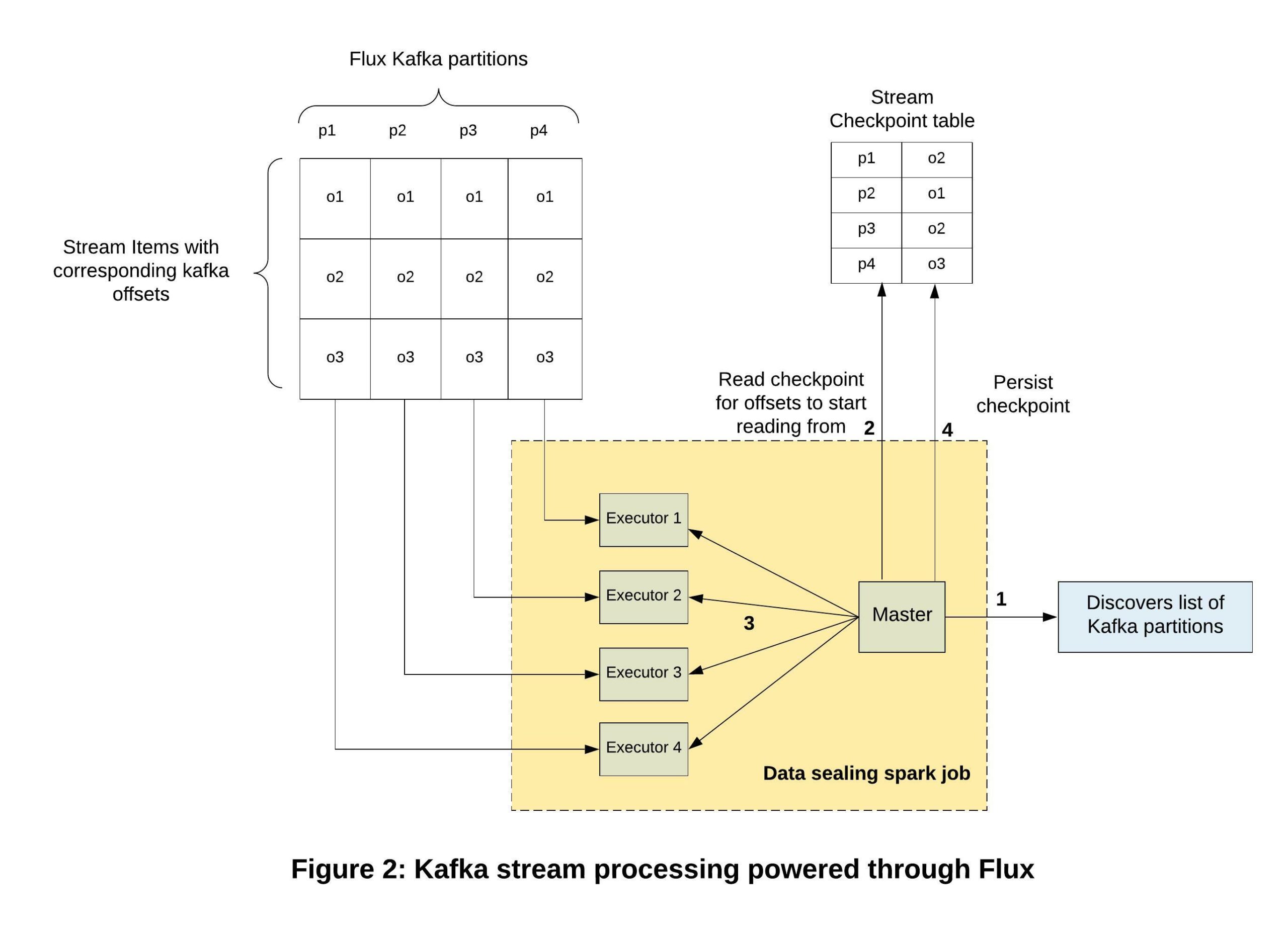
We are leveraging Kafka to tail the changelog in the Docstore to calculate checksum after data is inserted. Multiple Kafka partitions are read simultaneously in order to speed up the processing. Each worker processes the data, calculates the subset of a checksum atomically and persists the metadata along with the already-processed Kafka offset for that partition and the highest sequence number seen. The persisted Kafka offset helps to resume from the last offset, and the highest sequence number helps to ensure the exactly-once processing guarantees of stream events. This stream processing system using Spark is already capable of processing records at 50K QPS. We chose Apache Spark™ over Apache Flink®, as the sealing process need not be real-time and some bounded delay is acceptable. The batch processing helps quickly catch up in case of any potential lags, with another benefit being better database call-amortization, due to bigger batches of data that are merged in memory for manifest creation.
Our Flux and Kafka powered sealing process is depicted in Figure 2:
Data Backfill
Another challenge was to migrate all the historical data from DynamoDB—more than 250 billion unique records (~300TB of data)—to Docstore in real time. We had a couple of options:
- Process all the data in one go via a Spark job and dump it to Docstore
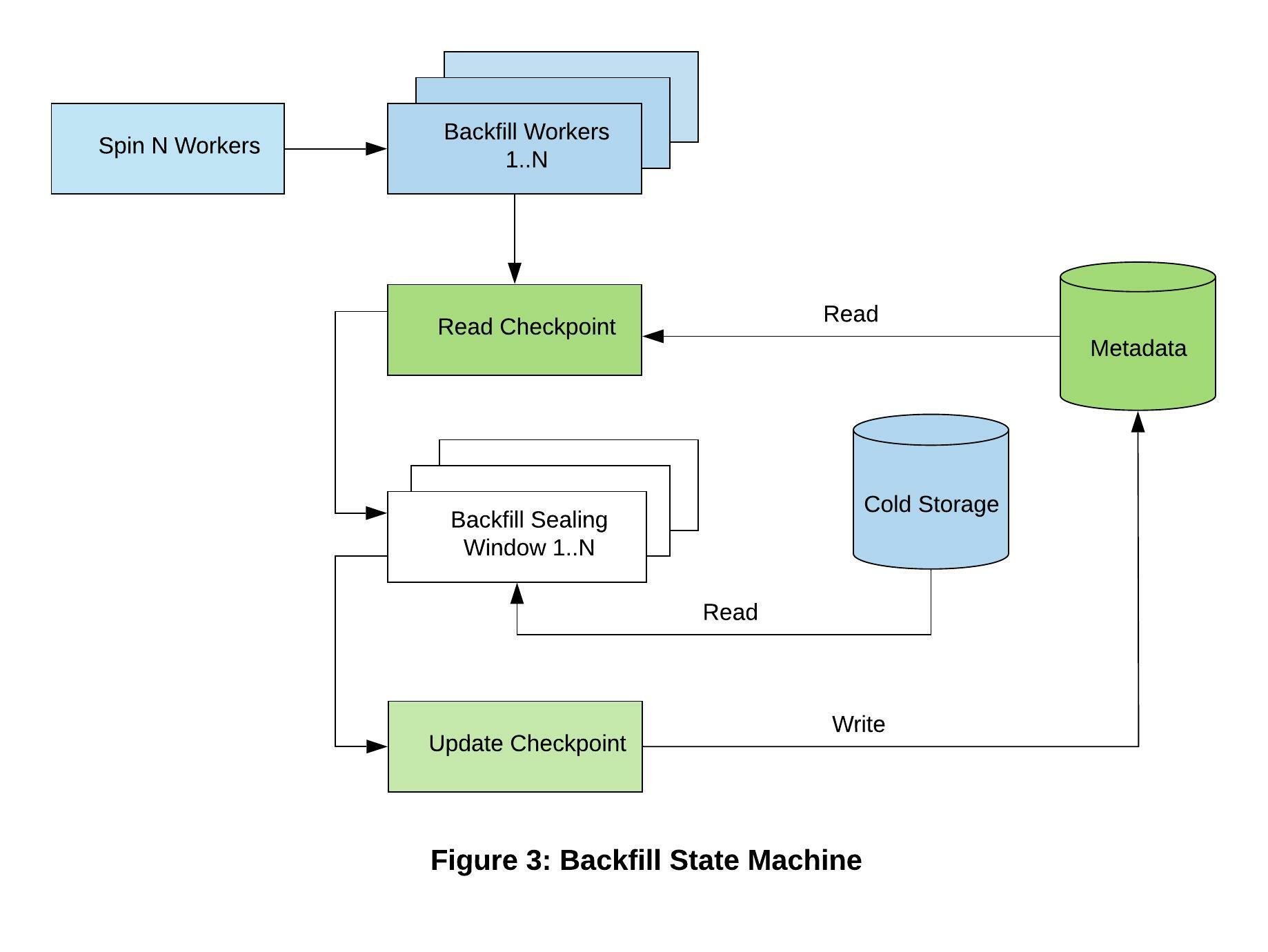
- Break down historical data into subsets and process them individually via checkpointing
With option 1, we would be processing a large amount of data and any intermittent failures would result in restarting the job. As mentioned earlier, LedgerStore supports cold storage offloading. The data to cold storage is offloaded at a sealing window granularity, meaning we already have historical data broken down into subsets that are individual sealing window and thus option 2 would be perfect for backfilling. Our backfill framework processes individual sealing windows and maintains a checkpoint of them. The framework is multi-threaded, spawning multiple workers where each worker is processing a distinct sealing window. This helps us drive higher throughput for backfilling and as a result our backfill framework is capable of processing 1 million messages per second! Also, option 2 drives our backfill cost down, since accessing data from cold storage is significantly cheaper than DynamoDB. Figure 3 describes a backfill state machine leveraging cold storage.
With this scalable and idempotent framework in hand, we were able to backfill the production dataset in a couple of weeks.
DynamoDB to Docstore Migration
Historical Data Migration
The above module (“data backfill”) takes care of the historical data, but we also have to take care of the online data that is flowing through the system. To handle that, we have developed a shadow writes module to insert the live data to Docstore asynchronously.
Online Traffic Redirection
Perhaps the most important phase of the project was to design and perform online traffic redirection. We configured LedgerStore to talk to 2 different databases, with each database assuming either the primary or secondary role, depending on the phase of the migration. This is fully controlled by us via migration configs. The goal is to keep 2 databases consistent at any phase of the migration so that rollback and forward are possible.
After data is backfilled for respective datastores, we start the online traffic redirection which is mainly divided into 4 phases, as described below.
Shadow Writes
We introduced a new shadow writer module in LedgerStore’s write path to insert the incoming data to the secondary database along with primary. We decided to write to the secondary database asynchronously, otherwise writing to 2 databases in synchronous fashion could add extra latency and could also impact availability and disrupt online traffic. However since writes to the secondary database are asynchronous, it is possible that a write was successful and acknowledged by the client, but failed on the secondary database. To overcome this, we use a 2-phase commit (2PC) protocol to track such asynchronous write failures and introduce a timer-based data resync job called Spot Repair. When the scheduler wakes up the Spot Repair job it starts fetching missing entries in the primary database and resyncing them to the secondary. The Spot Repair is designed to be database role-agnostic between primary and secondary to make switching between the two seamless.
Phase 1 in Figure 4 depicts the flow of the first phase where we perform shadow writes, with Docstore assuming a secondary role. A write is performed to DynamoDB and shadowed asynchronously to Docstore. In case of async write failures to Docstore, the Spot Repair job will be responsible for resyncing data from DynamoDB to Docstore, maintaining consistency between the 2 databases.
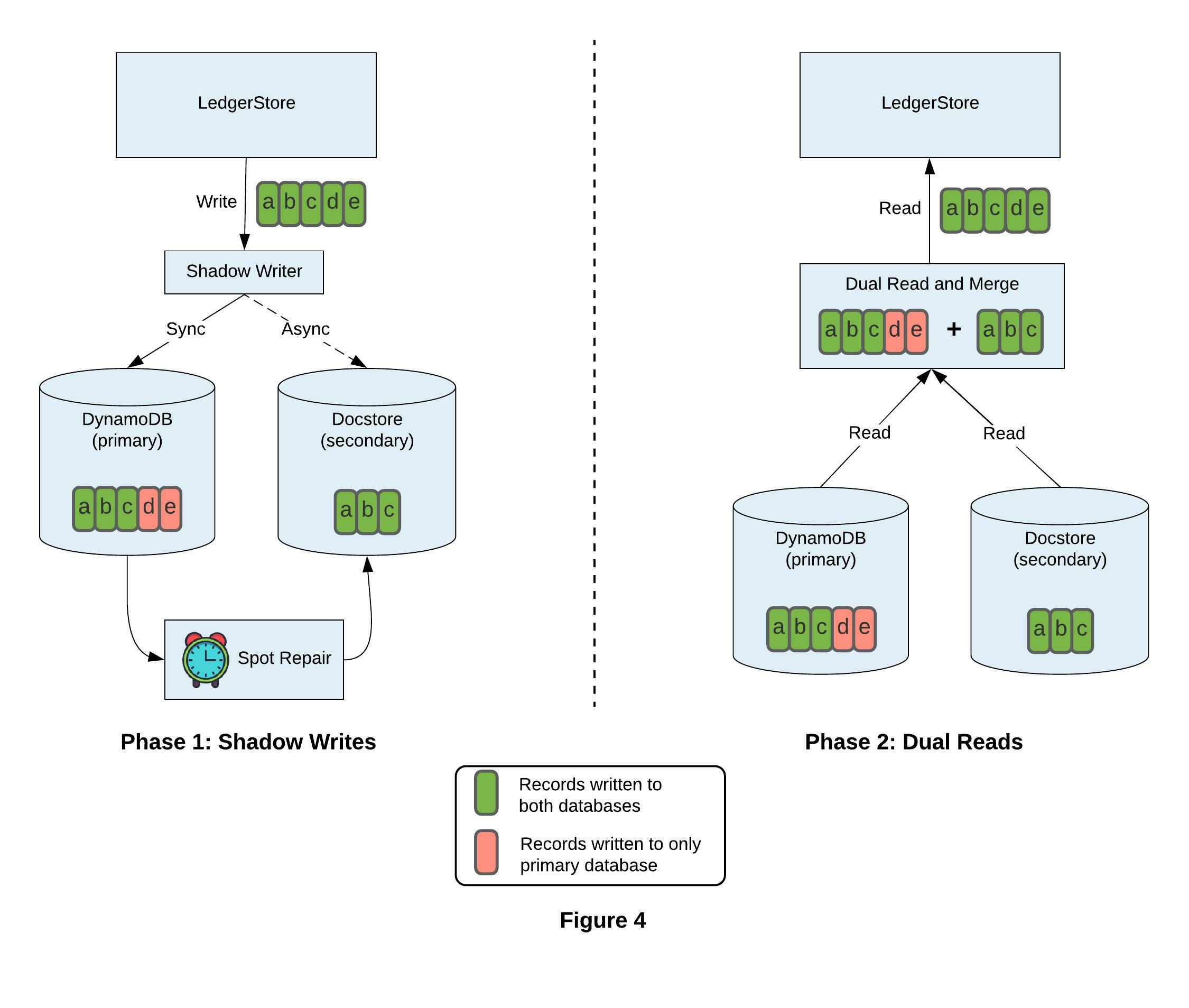
Dual Read and Merge
Even when we try to keep both databases consistent, there might be small windows during which inconsistencies could slip through (e.g., during database switch over, or due to some race condition). To guarantee 100% consistency and 99.99% availability, we introduced a new module, Dual Read and Merge, in the read path. Instead of serving read requests from a single database, this module reads from both databases concurrently, irrespective of their roles, merges the results, and then returns them to the client. By choosing this design, it gives us flexibility to switch between 2 databases without impacting correctness or availability. Phase 2 in Figure 4 shows the online read repair in action.
Swap Databases
As mentioned earlier, LedgerStore divides data in 30-minute time buckets and generates Manifests out of them for correctness and consistency guarantees. Now to ensure that all historical and online data is present in Docstore; we decided to compare the Manifest generated from historical and online data on Docstore matches with the one generated on DynamoDB at scale. If they match, we are sure that all the data has been successfully copied to Docstore. Along with this, once read and write paths are stable with Docstore as secondary, and we are satisfied with system performance and availability, it is time to swap the databases and promote Docstore as the primary.
In production, we’ve validated 250 billion unique records (~300TB data) in Docstore at scale through Spark job within a single week! Phase 3 in Figure 5 shows database roles switched where Docstore is primary and DynamoDB is secondary.
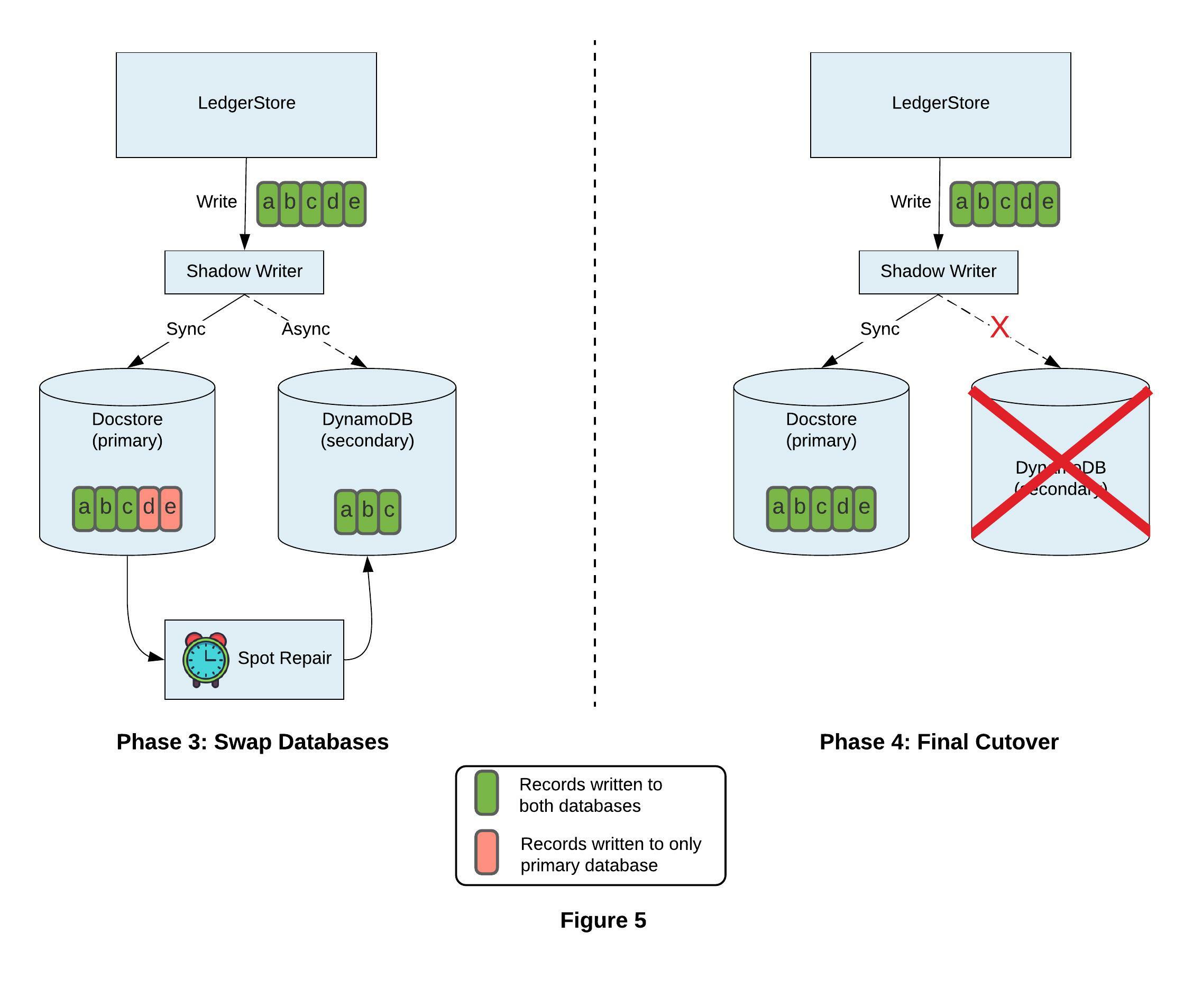
After Docstore is promoted to primary we want to slowly stop traffic to DynamoDB and decommission it. This is done in 2 phases, where first we gradually remove reads from DynamoDB and eventually only serve reads out of Docstore. Please note that we continue to shadow writes to DynamoDB as we want to drain the traffic slowly and safely. We kept the system in this state for about a week.
Final Cutover
Once reads were fully served out of Docstore it was time to stop the writes to DynamoDB. Once the writes to DynamoDB stopped, we also forced the system to now operate with a single database via config, which bypassed Shadow Writer and Dual Read and Merge modules. We could then back up the DynamoDB table and decommission it, as shown in Phase 4 in Figure 5.
Highlights
This is how we measured the success of this critical project:
- Not a single production incident, given how critical money movement is for Uber
- We didn’t have to rollback the migration for a single table
- We backfilled 250 billion unique records and not a single data inconsistency has been detected so far, with the new architecture in production for over 6 months
- Our new data model reduced complexity in the query path, and we observed latency improvements in both read and write path on Docstore
- The project also resulted in technology consolidation, reducing external dependencies
From a business impact perspective, operating LedgerStore is now very cost effective due to reduced spend on DynamoDB. The estimated yearly savings are $6 million per year, and we also laid the foundation for such other future initiatives.
Conclusion
In this article, we have covered the genesis and the motivation behind the re-architecture of LedgerStore. We have also taken a deep dive into the architecture and explained how the entire migration was designed and executed without impacting stringent SLAs and online flow. In the next part of this series, we will focus on a multi-level data tiering solution we are building in LedgerStore. In the third and concluding part of this series, we will also cover the next-generation scalable consistent indexing solution in LedgerStore.
If you enjoyed this article and want to work on systems and challenges related to globally distributed systems that power the operational storage of Uber, please explore and apply to open positions (I,II,III) on the storage team on Uber’s career portal.
DynamoDB is a trademark of Amazon.com, Inc. or its affiliates in the United States and/or other countries.
Featured Image: (John Carlin [CC0] from Wikimedia Commons)

Piyush Patel
Piyush Patel is a Sr. Engineering Manager on the Core Storage Platform team at Uber. The team provides a world-class platform that powers all the critical functions and lines of business at Uber. The Core Storage Platform serves tens of millions of QPS with an availability of 99.99% or more and stores tens of Petabytes of operational data. His interests include large scale distributed systems, data storage and retrieval, and cloud computing.

Jaydeepkumar Chovatia
Jaydeepkumar Chovatia is a Sr. Staff Software Engineer on the Storage Platform Org at Uber. He has contributed to big projects in core Cassandra as well as upstreamed patches to Open source Cassandra. His primary focus area is building distributed storage solutions and databases that scale along with Uber's hyper-growth. Prior to Uber, he worked at Oracle. Jaydeepkumar holds a master's degree in Computer Science from the Birla Institute of Technology and Science with a specialization in distributed systems.

Kaushik Devarajaiah
Kaushik Devarajaiah is the Tech Lead for LedgerStore at Uber. His primary focus is building distributed gateways and databases that scale with Uber's hyper-growth. Previously, he worked on scaling Uber's Data Infrastructure to handle over 100 petabytes of data. Kaushik holds a master's degree in Computer Science from SUNY Stony Brook University.
Posted by Piyush Patel, Jaydeepkumar Chovatia, Kaushik Devarajaiah
Related articles




{kind=link}
Most popular

Your guide to NJ TRANSIT’s Access Link Riders’ Choice Pilot 2.0

SweetTree Home Care Services simplifies client and staff transportation with Uber Health

Personalized Marketing at Scale: Uber’s Out-of-App Recommendation System
The 2024 Mother’s Day Shop and Pay with Uber Eats Gift Card Sweepstakes Official Rules
Products
Company